
- 1去了字节跳动,才知道年薪50W的测试有这么多?_字节跳动年薪50万是什么水平
- 2一个多合一的 AI 大模型客户端,支持本地部署大模型,实现大模型自由_jan.ai 训练自己数据
- 3线性表顺序存储结构的基本实现_通过线性表结构实现电话本模拟程序。编程实现顺序存储结构中的基本操作的实现
- 4微信小程序真机调试和预览无法进入request_真机调试登录不上
- 5使用Postman创建Mock Server_postman创建服务端
- 6Pycharm连接远程服务器进行模型训练——以YOLOv8为例_pycharm autodl yolov8
- 7git干获,从安装到上传项目(详细)_git 安装并上传文件
- 8java 表单重复提交,进行幂等性控制,防止_java接口幂等性,防止重复提交
- 9M系列 Mac安装配置Homebrew_mac homebrew
- 10ChatGPT完美平替!Jan AI:属于你的本地大语言模型!_jan – 免费的 chatgpt 开源替代
数据结构C++——哈夫曼树及哈夫曼编码_6-6 哈夫曼树及哈夫曼编码 分数 10 作者 wgy 单位 浙江大学 函数selecttwomin
赞
踩
数据结构C++——哈夫曼树及哈夫曼编码
一、哈夫曼树的介绍及概念
哈夫曼(Huffman)树又称最优树,是一类带权路径长度最短的树,在实际中有广泛的用途。
(1) 路径:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
(2) 路径长度:路径上的分支数目称作路径长度。
(3)树的路径长度:从树根到每一结点的路径长度之和。
(4)权:赋予某个实体的一个量,是对实体的某个或某些属性的数值化描述。 在数据结构中,实体有结点(元素)和边(关系)两大类,所以对应有结点权和边权。 结点权或边权具体代表什么意义,由具体情况决定。如果在一棵树中的结点上带有权值,则对应的就有带权树等概念。
(5)结点的带权路径长度:从该结点到树根之间的路径长度与结点上权的乘积。
(6)树的带权路径长度:树中所有叶子结点的带权路径长度之和。
(7)哈夫曼树:假设有m个权值{w1, W2, …,匹},可以构造一棵含n个叶子结点的二叉树,每个叶子结点的权为 W; 则其中带权路径长度 WPL最小的二叉树称做最优二叉树或哈夫曼树
二、哈夫曼树的构造及打印
①哈夫曼树的存储结构
哈夫曼树的存储结构
typedef struct {
int weight;//结点的权值
int parent, lchild, rchild;//结点的双亲、左孩子、右孩子的下标
}HTNode,*HuffmanTree;//动态分配数组存储哈夫曼树
- 1
- 2
- 3
- 4
②构造哈夫曼树
构造哈夫曼树
构造哈夫曼树的算法思路:
1:定义哈夫曼树变量,申请2*n个单元(0号单元未用),HT[2*n-1]表示根结点
2:定义变量m=2*n-1(一棵有n个叶子结点的哈夫曼树共有2*n-1个结点),循环m次,将1~m号中的的双亲、左孩子、右孩子、权重的下标都初始化为0
3:输入前n个单元中叶子结点的权值
4:在前n个单元中找到权值最小且双亲结点下标为0的结点,并返回它们在HT中的序号s1和s2
5:将s1和s2的双亲域由0改为i,s1和s2分别作为HT[i]的左右孩子,并修改HT[i]的权值为左右孩子的权值之和。
- 1
- 2
- 3
- 4
- 5
- 6
void CreateHuffmanTree(HuffmanTree& HT, int n) { //构造哈夫曼树 if (n <= 1) return; int m = 2 * n - 1;//一棵有n个叶子节点的哈夫曼树共有2*n-1个结点 HT = new HTNode[m + 1];//0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点 for (int i = 1; i <= m; i++) {//将1-m号单元中的双亲、左孩子、右孩子的下标都初始化为0 HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; HT[i].weight = 0; } for (int i = 1; i <= n; i++) {//输入前n个单元中叶子结点的权值 cin >> HT[i].weight; } /*--------初始化工作结束,下面开始创建哈夫曼树------*/ for (int i = n+1; i <= m; i++) {//通过n-1次的选择、删除、合并来创建哈夫曼树 int s1=0, s2=0; Select(HT, i - 1, s1, s2);//在HT[k](1<=k<=i-1)中选择两个其双亲域为0且权值最小的结点,并返回它们在HT中的序号s1和s2 HT[s1].parent = i; HT[s2].parent = i; //得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为i HT[i].lchild = s1; HT[i].rchild = s2;//s1,s2分别作为i的左右孩子 HT[i].weight = HT[s1].weight + HT[s2].weight;//i的权值为左右孩子权值之和 } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
③Select()函数的代码实现
Select()函数的实现
此步骤参照了此文章,即本步骤并非笔者纯原创:数据结构(15)–哈夫曼树以及哈夫曼编码的实现.
Select()函数代码实现思路:
1:设置中间变量tmp存放最小权值结点的权值
2:循环n次,找到权值最小的结点下标,将其赋予s1
3:重复第2步,找到权值最小但下标不为s1的结点下标,将其赋予s2
- 1
- 2
- 3
- 4
/*----------选择两个权值最小的结点-----------*/ void Select(HuffmanTree HT, int k, int& s1, int& s2) { unsigned int tmp = 10000;//假设s1对应的权值大于s2 for (int i = 1; i <= k; i++) { if (!HT[i].parent) {//parent必须为0 if (tmp>HT[i].weight) { tmp = HT[i].weight;//tmp存放权值最小的结点权值 s1 = i; } } } unsigned int tmp1 = 10000;//假设s1对应的权值大于s2 for (int i = 1; i <= k; i++) { if (!HT[i].parent&&i!=s1) {//parent必须为0 if (tmp1 > HT[i].weight) { tmp1 = HT[i].weight;//tmp1存放权值最小的结点权值 s2 = i; } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
④打印哈夫曼树
打印哈夫曼树
打印哈夫曼树的算法思路:
1:将哈夫曼树以表格的形式输出更直观
2:输出表头i、weight、parent、lchild、rchild。
3:输出时注意C++函setw()的使用,注意左对齐为在setw()函数中加上std::left,右对齐则加上std::right。
4:循环2*n-1次输出构造好的哈夫曼树的每个结点的相关参数。
- 1
- 2
- 3
- 4
- 5
/*----------打印哈夫曼树---------*/
void PrintHuffmanTree(HuffmanTree HT,int m) {
cout <<std::left << setw(10) << "i" << setw(10) << "weight" << setw(10) << "parent" << setw(10) << "lchild" << setw(10) << "rchild" << endl;
for (int i = 1; i <= m; i++)
{
cout << setw(12) << i << setw(11) << HT[i].weight << setw(10) << HT[i].parent << setw(10) << HT[i].lchild << setw(10) << HT[i].rchild << endl;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
⑤测试的完整代码
完整代码
#include<iostream> #include<iomanip> using namespace std; typedef struct { int weight;//结点的权值 int parent, lchild, rchild;//结点的双亲、左孩子、右孩子的下标 }HTNode,*HuffmanTree;//动态分配数组存储哈夫曼树 /*----------选择两个权值最小的结点-----------*/ void Select(HuffmanTree HT, int k, int& s1, int& s2) { unsigned int tmp = 10000;//假设s1对应的权值大于s2 for (int i = 1; i <= k; i++) { if (!HT[i].parent) {//parent必须为0 if (tmp>HT[i].weight) { tmp = HT[i].weight;//tmp存放权值最小的结点权值 s1 = i; } } } unsigned int tmp1 = 10000;//假设s1对应的权值大于s2 for (int i = 1; i <= k; i++) { if (!HT[i].parent&&i!=s1) {//parent必须为0 if (tmp1 > HT[i].weight) { tmp1 = HT[i].weight;//tmp1存放权值最小的结点权值 s2 = i; } } } } /*-------构造哈夫曼树-------*/ void CreateHuffmanTree(HuffmanTree& HT, int n) { //构造哈夫曼树 if (n <= 1) return; int m = 2 * n - 1;//一棵有n个叶子节点的哈夫曼树共有2*n-1个结点 HT = new HTNode[m + 1];//0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点 for (int i = 1; i <= m; i++) {//将1-m号单元中的双亲、左孩子、右孩子的下标都初始化为0 HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; HT[i].weight = 0; } for (int i = 1; i <= n; i++) {//输入前n个单元中叶子结点的权值 cin >> HT[i].weight; } /*--------初始化工作结束,下面开始创建哈夫曼树------*/ for (int i = n+1; i <= m; i++) {//通过n-1次的选择、删除、合并来创建哈夫曼树 int s1=0, s2=0; Select(HT, i - 1, s1, s2);//在HT[k](1<=k<=i-1)中选择两个其双亲域为0且权值最小的结点,并返回它们在HT中的序号s1和s2 HT[s1].parent = i; HT[s2].parent = i; //得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为i HT[i].lchild = s1; HT[i].rchild = s2;//s1,s2分别作为i的左右孩子 HT[i].weight = HT[s1].weight + HT[s2].weight;//i的权值为左右孩子权值之和 } } /*----------打印哈夫曼树---------*/ void PrintHuffmanTree(HuffmanTree HT,int m) { cout <<std::left << setw(10) << "i" << setw(10) << "weight" << setw(10) << "parent" << setw(10) << "lchild" << setw(10) << "rchild" << endl; for (int i = 1; i <= m; i++) { cout << setw(12) << i << setw(11) << HT[i].weight << setw(10) << HT[i].parent << setw(10) << HT[i].lchild << setw(10) << HT[i].rchild << endl; } } /*--------主函数--------*/ int main() { HuffmanTree HT = new HTNode;//定义一个哈夫曼树变量 int n=0; cin >> n;//输入结点个数 int m = 2 * n - 1;//m为哈夫曼树的所有结点的个数 CreateHuffmanTree(HT, n);//构建一个哈夫曼树 PrintHuffmanTree(HT, m);//输出哈夫曼树 } //5 29 7 8 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
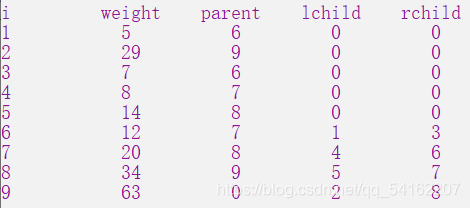
测试结果
输入:5
5 29 7 8 14
- 1
- 2
输出结果
输出:
- 1
--------------------------------一道华丽的分割线-----------------------------------
二、哈夫曼编码
①哈夫曼编码的相关概念
(l)前缀编码:如果在一个编码方案中,任一个编码都不是其他任何编码的前缀(最左子串),则称编码是前缀编码。例如:0,10,110,111是前缀编码,而0,01,010,111就不是前缀编码,前缀编码可以保证对压缩文件进行解码时不产生二义性, 确保正确解码。
(2) 哈夫曼编码:对一棵具有n个叶子的哈夫曼树,若对树中的每个左分支赋予0, 右分支赋予1’则从根到每个叶子的路径上,各分支的赋值分别构成一个二进制串, 该二进制串就称为哈夫曼编码。
②哈夫曼编码的算法实现
算法思路
在构造哈夫曼树之后,求哈夫曼编码的主要思想是:依次以叶子为出发点,向上回溯至根结
点为止。 回溯时走左分支则生成代码 0, 走右分支则生成代码l。
- 1
- 2
哈夫曼编码表的存储表示
/*----------哈夫曼编码表的存储表示------------*/
typedef char** HuffmanCode;//动态分配数组存储哈夫曼编码表
- 1
- 2
根据哈夫曼树求哈夫曼编码
根据哈夫曼树求哈夫曼编码的算法思路:
1:定义HC指针数组,数组的每一个单元存储一个指针,定义cd数组,临时存储每一个叶子结点的字符编码
2:遍历n个叶子结点,从叶子结点开始向上回溯,直到根结点
3:若c为回溯到的父结点的左子树的根结点,则生成代码0
4:若c为回溯到的父结点的右子树的根结点,则生成代码1
5:回溯一次start向前指一个位置,最后cd数组中实际存值的单元为start~n-1这段单元
6:最后将求得的编码从临时空间cd复制到HC的当前行中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
/*---------根据哈夫曼树求哈夫曼编码------------*/ void CreatHuffmanCode(HuffmanTree HT, HuffmanCode& HC, int n) { //从叶子到根逆向求每个字符的哈夫曼编码,存储在编码表HC中 HC = new char* [n + 1];//分配存储n个字符编码的编码表空间 char* cd = new char[n];//分配临时存放每个字符编码的动态数组空间 cd[n - 1] = '\0';//编码结束符 for (int i = 1; i <= n; i++) { int start = n - 1;//start开始时指向最后,即编码结束符位置 int c = 0 , f = 0; c = i; f = HT[i].parent;//f指向结点c的双亲结点 while (f!=0)//从叶子结点开始向上回溯,直到根结点 { --start;//回溯一次start向前指一个位置 if (HT[f].lchild == c) cd[start] = '0';//结点c是f的左孩子,则生成代码0 else cd[start] = '1';//结点c是f的右孩子,则生成代码1 c = f; f = HT[f].parent;//继续向上回溯 }//求出第i个字符的编码 HC[i] = new char[n - start]; strcpy(HC[i], &cd[start]);//将求得的编码从临时空间cd复制到HC的当前行中 } delete cd;//释放临时空间 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
③输出哈夫曼编码
将哈夫曼编码的结果输出在控制台
输出哈夫曼编码的算法思路:
1:输出表头
2:循环n次将HC数组中的内容输出
- 1
- 2
- 3
/*--------输出哈夫曼编码-----------*/
void PrintfHuffmanCode(HuffmanCode& HC, int n) {
//将哈夫曼编码的结果输出在控制台
cout << std::left << setw(10) << "i" << std::left << setw(10) << "编码" << endl;
for (int i = 1; i <= n; i++) {
cout << std::left << setw(10) << i;
string str = HC[i];
cout << std::left << setw(10) << str << endl;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
④测试的完整代码
#include<iostream> #include<iomanip> #include<string> using namespace std; /*----------哈夫曼编码表的存储表示------------*/ typedef char** HuffmanCode;//动态分配数组存储哈夫曼编码表 typedef struct { int weight;//结点的权值 int parent, lchild, rchild;//结点的双亲、左孩子、右孩子的下标 }HTNode,*HuffmanTree;//动态分配数组存储哈夫曼树 /*----------选择两个权值最小的结点-----------*/ void Select(HuffmanTree HT, int k, int& s1, int& s2) { unsigned int tmp = 10000;//假设s1对应的权值大于s2 for (int i = 1; i <= k; i++) { if (!HT[i].parent) {//parent必须为0 if (tmp>HT[i].weight) { tmp = HT[i].weight;//tmp存放权值最小的结点权值 s1 = i; } } } unsigned int tmp1 = 10000;//假设s1对应的权值大于s2 for (int i = 1; i <= k; i++) { if (!HT[i].parent&&i!=s1) {//parent必须为0 if (tmp1 > HT[i].weight) { tmp1 = HT[i].weight;//tmp1存放权值最小的结点权值 s2 = i; } } } } /*-------构造哈夫曼树-------*/ void CreateHuffmanTree(HuffmanTree& HT, int n) { //构造哈夫曼树 if (n <= 1) return; int m = 2 * n - 1;//一棵有n个叶子节点的哈夫曼树共有2*n-1个结点 HT = new HTNode[m + 1];//0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点 for (int i = 1; i <= m; i++) {//将1-m号单元中的双亲、左孩子、右孩子的下标都初始化为0 HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; HT[i].weight = 0; } for (int i = 1; i <= n; i++) {//输入前n个单元中叶子结点的权值 cin >> HT[i].weight; } /*--------初始化工作结束,下面开始创建哈夫曼树------*/ for (int i = n+1; i <= m; i++) {//通过n-1次的选择、删除、合并来创建哈夫曼树 int s1=0, s2=0; Select(HT, i - 1, s1, s2);//在HT[k](1<=k<=i-1)中选择两个其双亲域为0且权值最小的结点,并返回它们在HT中的序号s1和s2 HT[s1].parent = i; HT[s2].parent = i; //得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为i HT[i].lchild = s1; HT[i].rchild = s2;//s1,s2分别作为i的左右孩子 HT[i].weight = HT[s1].weight + HT[s2].weight;//i的权值为左右孩子权值之和 } } /*---------根据哈夫曼树求哈夫曼编码------------*/ void CreatHuffmanCode(HuffmanTree HT, HuffmanCode& HC, int n) { //从叶子到根逆向求每个字符的哈夫曼编码,存储在编码表HC中 HC = new char* [n + 1];//分配存储n个字符编码的编码表空间 char* cd = new char[n];//分配临时存放每个字符编码的动态数组空间 cd[n - 1] = '\0';//编码结束符 for (int i = 1; i <= n; i++) { int start = n - 1;//start开始时指向最后,即编码结束符位置 int c = 0 , f = 0; c = i; f = HT[i].parent;//f指向结点c的双亲结点 while (f!=0)//从叶子结点开始向上回溯,直到根结点 { --start;//回溯一次start向前指一个位置 if (HT[f].lchild == c) cd[start] = '0';//结点c是f的左孩子,则生成代码0 else cd[start] = '1';//结点c是f的右孩子,则生成代码1 c = f; f = HT[f].parent;//继续向上回溯 }//求出第i个字符的编码 HC[i] = new char[n - start]; strcpy(HC[i], &cd[start]);//将求得的编码从临时空间cd复制到HC的当前行中 } delete cd;//释放临时空间 } /*--------将哈夫曼编码的结果输出在控制台-----------*/ void PrintfHuffmanCode(HuffmanCode& HC, int n) { //将哈夫曼编码的结果输出在控制台 //char* cd = new char[n]; cout << std::left << setw(10) << "i" << std::left << setw(10) << "编码" << endl; for (int i = 1; i <= n; i++) { cout << std::left << setw(10) << i; string str = HC[i]; cout << std::left << setw(10) << str << endl; } } /*--------主函数--------*/ int main() { HuffmanTree HT = new HTNode;//定义一个哈夫曼树变量 int n=0; cin >> n;//输入结点个数 int m = 2 * n - 1;//m为哈夫曼树的所有结点的个数 CreateHuffmanTree(HT, n);//构建一个哈夫曼树 //PrintHuffmanTree(HT, m);//输出哈夫曼树 HuffmanCode HC; CreatHuffmanCode(HT, HC, n); PrintfHuffmanCode(HC, n); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
输出结果
输入:
8
5 29 7 8 14 23 3 11
- 1
- 2
- 3
输出:
- 1

三、总结
以上为笔者对于哈夫曼树及哈夫曼编码的一些见解,希望初学者都能有所收获,有技术不到位的地方,还望各位大佬指正。
同时,笔者的个人主页还有数据结构中其他部分的一些见解与分析,后续数据结构的相关知识还将陆续更新,欢迎大家访问且共同学习!

