
- 1同样的APP为何在Android 8以后网络感觉变卡?
- 2史上最全!用Pandas读取CSV,看这篇就够了
- 3基础编码管理组件 Example 程序
- 4【实用党】推荐几款实用的AI工具_手绘生成图片
- 5【C语言篇】链表的基本操作-创建链表、插入节点、删除节点、打印链表_链表结构体打印链表程序
- 6【行为识别现状调研1】_多尺度时空特征和运动特征的异常行为识别
- 7QUIC:基于UDP的多路复用安全传输(部分翻译)_quic的多路复用
- 8mysql查询和修改的底层原理_数据库修改的实质是什么
- 9技术的正宗与野路子 c#, AOP动态代理实现动态权限控制(一) 探索基于.NET下实现一句话木马之asmx篇 asp.net core 系列 9 环境(Development、Staging ...
- 10中兴新支点桌面操作系统——一些小而美的功能
英伟达发布的系统级芯片orin_英伟达自动驾驶芯片orin csdn
赞
踩
本文为英伟达全面分析的第七篇文章,关注英伟达在今年会大规模交付的Orin系统级芯片。“Orin”是亚特兰蒂斯神话第一任统治者,海王Altan的儿子。Orin一经发布,便成为众多车企争抢装车的对象。
本文重点探讨Orin的硬件和软件架构,包括新一代的GPU、CPU、深度学习加速器,以及基于Orin的软件栈。

1. Orin概览
英伟达2019年推出了DRIVE AGX Orin平台,最高算力(INT8)达到2000TOPS,是一个既覆盖从L2到L5自动驾驶全场景,也包含可视化、数字仪表、车载信息娱乐及交互的高性能AI平台,且在硬软件上与上一代Xavier完全兼容,下图为基于单Orin和双Orin从L2到L5自动驾驶的系统方案。

DRIVE AGX Orin平台中,内置了Orin SoC芯片,下图为基于Jetson AGX Orin机器人计算平台,供参考。
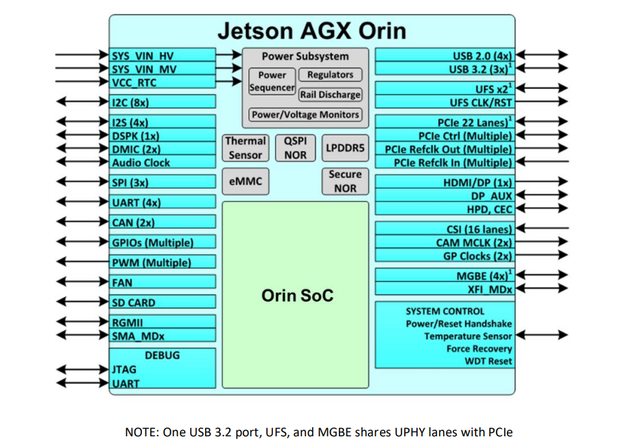
2. Orin的系统架构
Orin SoC采用7纳米工艺,由Ampere架构的GPU,ARM Hercules CPU,第二代深度学习加速器DLA、第二代视觉加速器PVA、视频编解码器、宽动态范围的ISP组成,同时引入了车规级的安全岛Safety Island设计,下图为Orin SoC的系统架构。

Orin支持204GB/s的内存带宽和最高64GB的DRAM,高速I/O接口与上一代Xavier SoC的接口兼容,可实现275TOPS的INT8算力,是Xavier的7倍,功耗55W。
3. Orin的硬件架构
3.1 Ampere GPU
Orin采用了新一代的Ampere架构GPU,由2个GPC(Graphics Processing Clusters,图形处理簇)组成。
每个GPC又包含4个TPC(Texture Processing Clusters, 纹理处理簇),每个TPC由2个SM(Streaming Multiprocesor,流处理器)组成,下图为Orin的GPU架构。

每个SM有192KB的L1缓存和4MB的L2缓存,包含128个CUDA Core和4个Tensor Core。
因此Orin总计2048个CUDA Core和64个Tensor Core,INT8稀疏算力为170 TOPS(Tensor Core提供),INT8稠密算力为54TOPS,FP32算力为5.3TFLOP(由Cuda Core提供)。
与上一代Volta架构的GPU相比,Tensor Core引入了对稀疏性的支持, 稀疏性Sparsity是一种细粒度的计算结构,可以使吞吐量翻倍并减少内存使用量。
3.2 第三代张量核稀疏化技术
Ampere架构中第三代Tensor Core是亮点,首次引入了细粒度结构化稀疏性技术(Fine-grained structured sparsity ,稀疏性),也是支撑英伟达对外宣传“AI算力标杆”的关键控制点。
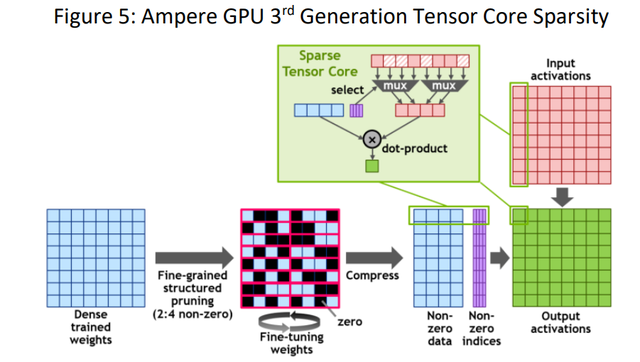
稀疏化技术主要分为两个部分:
一是对权重网络先进行密集训练(Dense trained weights),再将网络权重修剪(pruning)为2:4的稀疏矩阵,稀疏矩阵中每个4个元素中有2个非零值,最后再对非零权重进行微调(fine-tune),通过权重网络压缩,使得数据占用空间和带宽减少为原来的一半;
二是在Tensor Core中加入选择电路,称为稀疏的tensor core),根据权重的索引过滤掉0的位置,让weights不是0的部分和输入的Tensor对应的部分做内积,使矩阵乘法所需计算量大大减少,即通过跳零(skipping the zeros)将数学计算的吞吐量加倍。
3.3 第二代DLA
Orin上推出了第二代深度学习加速器DLA,相比于第一代,主要有两个变化:
第一是增加了本地缓冲,以提高效率并减少DRAM带宽;第二是引入了结构化稀疏功能(structured sparsity),增加了深度卷积处理器(depth wise convolution processor)和硬件调度器(hardware scheduler),下图为第二代DLA架构。

总体使得DLA的INT8稀疏算力为105TOPS,INT8稠密算力为11.4TOPS,而Xavier中的第一代DLA为5TOPS。
TensorRT可以在DLA上INT8或FP16运行各种网络,并支持卷积、反卷积、全连接、激活、池化、batch归一化(batch normalization)等各种层。
3.4 Arm A78 CPU
Orin系统架构中,CPU从之前自研的Carmel架构回到了到5纳米工艺的ARM Cortex-A78上,下图为CPU架构。

Orin多达12个CPU内核,每个内核包含了64KB的L1指令缓存和64KB的L1数据缓存,以及256KB的L2缓存。
每4个CPU内核组成一个CPU簇,共同使用一个2MB的L3缓存,支持的最大CPU频率达到了2.2GHz。
相比于上一代Xavier的8核Carmel CPU,Orin的12核A78 CPU性能提升1.9倍。
3.5 内存和通讯
Orin最高支持64GB的256位LPDDR5和64GB的eMMC。
DRAM支持3200MHz的最大时钟速度,每个引脚6400Gbps,支持204.8GB/s的内存带宽,是Xavier内存带宽 memory bandwidth 的1.4倍、存储storage的2倍。
下图显示了Orin各组件中,通过内存控制器结构(Fabric)和DRAM如何通讯和数据交互。
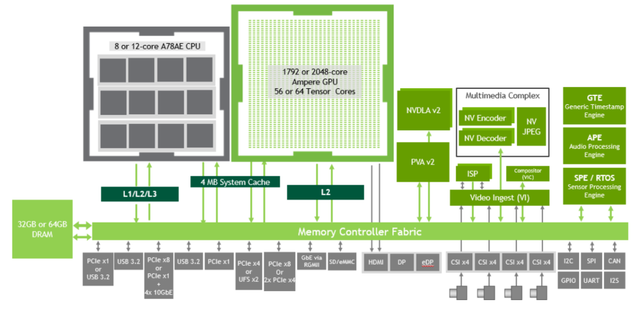
3.6 视频编解码器
Orin包含一个多标准视频编码器 (ENC)、一个多标准视频解码器 (DEC) 和JPEG处理块 (JPEG)。
ENC和DEC支持完整硬件加速的编解码标准,包括H.265、H.264 、AV1等;JPEG用于JPEG静止图像的解压缩计算、图像缩放、解码(YUV420、YUV422H/V、YUV444、YUV400)和色彩空间转换(RGB到YUV)等功能。
3.7 第二代视觉加速器PVA和VIC
Orin中对PVA进行了升级,包括双7路VLIW(超长指令字)矢量处理单元、双DMA和Cortex-R5,支持计算机视觉中过滤、变形、图像金字塔、特征检测和FFT等功能。
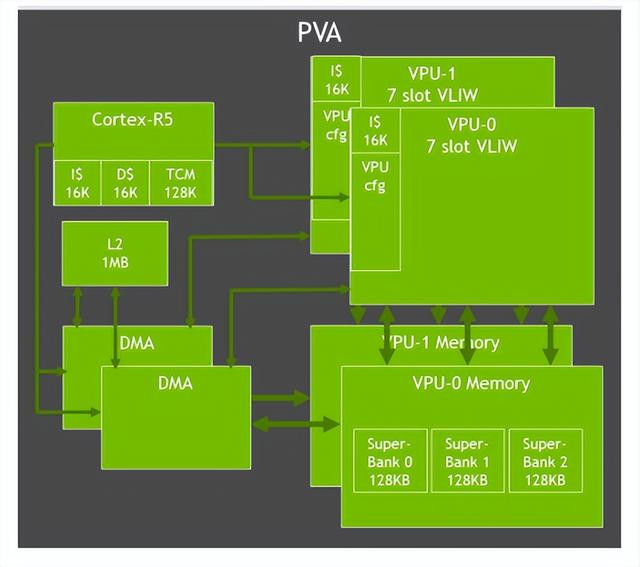
Orin还包含一个Gen 4.2视频成像合成器 (Video Imaging Compositor,VIC) 2D 引擎,支持镜头畸变校正和增强、时间降噪、视频清晰度增强、像素处理(色彩空间转换、缩放、混合和合成)等图像处理功能。
为了调用Orin SoC上的多个硬件组件(PVA、VIC、CPU、GPU、 ENC等),英伟达开发了视觉编程接口( Vision Programming Interface,VPI)。作为一个软件库,VPI附带了多种图像处理算法(如框过滤、卷积、图像重缩放和重映射)和计算机视觉算法(如哈里斯角检测、KLT 特征跟踪器、光流、背景减法等)。
3.8 I/O接口
Orin包含大量的高速 I/O,包括了22通道PCIe Gen4、以太网接口(千兆、10千兆)、显示端口、16通道MIPI CSI-2、USB3.2等。

Orin中带有电源管理集成电路 (Power Management Integrated Circuit,PMIC)、稳压器和电源树,支持15W、30W 、50W、60W功率模式。
4. Orin的软件栈
Orin的软件栈是基于软件开发工具包SDK(Software Development Kit)来提供支撑的。
主要是板级支持包 (BSP),包括了引导程序Bootloader、Linux内核、驱动程序Driver、工具链Tool chain和基于Ubuntu的参考文件系统,BSP也支持各种安全功能(安全启动、可信执行环境、磁盘和内存加密等)。
在BSP之上,有多个用于加速应用程序的用户级库,包括深度学习加速库(CUDA、CuDNN、Tensor RT),加速计算库(cuBLAS、cuFTT),计算机视觉和图像处理库(VPI),多媒体和相机库(libArgus 和 v4l2)。
TensorRT是用于深度学习推理的运行时库( Runtime library)和优化器( Optimizer ),可提供更低的延迟(Latency)和更高的吞吐量( Throughput ), 即通过模型量化、融合内核节点( Fusing nodes in a kernel)和选择最佳数据层和算法(Best data layers and algorithms )来优化GPU内存和带宽(Memory and bandwidth)的使用。
cuDNN( CUDA Deep Neural Network Library,深度神经网络库),是英伟达专门为深度神经网络所开发出来的GPU加速库,针对卷积、池化等常见操作做了非常多的底层优化,比一般的GPU程序要快很多,大多数主流深度学习框架都支持 cuDNN。
此外,Orin软件栈上也支持特殊场景的SDK,包括用于智能视频分析应用程序的DeepStream、用于机器人应用程序的Isaac和用于自然语言处理应用程序的Riva,以支撑更多生态应用发展。
下图是基于Jetson AGX Orin机器人计算平台供参考。
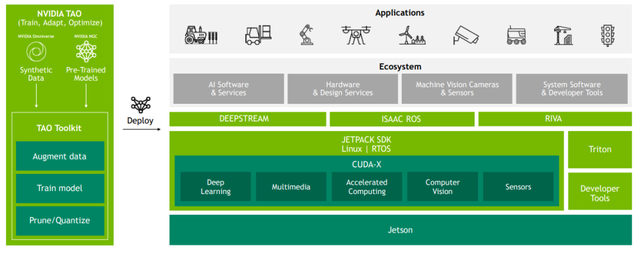
对于边缘部署场景,推出了预训练模型 (PTM) ,已经采用了数百万张图像进行了预训练,模型库中包括了人车检测、自然语言处理、姿势估计、车牌检测、人脸检测等模型,可以实现开箱即用;
此外配合TAO工具包( TAO toolkit ),使客户能够使用自己的数据集进行训练、微调和优化这些预训练模型,形成快速部署。
针对已经部署在边缘端的模型,借助云,通过容器和容器编排技术实现定期更新,包括具有Docker集成的 NVIDIA Container Runtime,以简化大规模 AI 模型的部署。
5. 地表最强,车企疯抢
目前Orin的订单火爆,已经有越来越多的车企和初创公司宣布搭载Orin平台。
上汽的R和智己,理想L9、蔚来ET7、小鹏新一代P7,威马M7、比亚迪、沃尔沃XC90,还有自动驾驶卡车公司智加科技,Robotaxi等众多明星企业Cruise、Zoox、滴滴、小马智行、AutoX、软件公司Momonta等等,都搭载Orin平台进行开发。
很多车企在拿到Orin样板都迫不及待地官宣,试图对外展示是Orin的首装,Orin的交付,可以看作是今年智能汽车里程碑事件。

6. 汽车人参考小结
燃油车向电动车和智能车过渡,高续航成为标配,拼续航为代表的电动化基本进入了下半场;到智能汽车,业界很自然共识是从“马力”到“算力”,因此从拼续航到了拼马力时代。
英伟达Orin卖点就是算力,踩得非常准,就是要用自身优势掀起算力的军备竞赛。
车企智能化还在竞争中,特别是在高端车型上,急需要有一个卖点和标签,而市面上可选的芯片只有英伟达一家,因此就出现了车企疯抢的状态。
汽车人参考认为,一方面英伟达算力是稀疏的,算力利用率、性价比需要更详细分析,车企对其算力的认知会越来越清晰;另外一方面,在主流车型上,芯片的算力也会逐步向电池续航一样开始收敛,最终会达到一个平衡,回归比性价比的真实状态。


