
- 1看完这些在HW面试官面前横着走 HW面试常见问题大合集(适合第一次参加)_hw项目
- 2git合并两个不同仓库的方法_git不同仓库合并
- 309 Confluent_Kafka权威指南 第九章:管理kafka集群_confluent.kafka producerconfig
- 4目标检测开源数据集——道路裂缝_道路检测数据集
- 5Rdrop技术(Regularized Dropout)
- 6C++左值与右值以及std::move详解_cpp 左值及右值 std::move
- 75.RabbitMQ消息队列类型(7个)详细使用_rabbitmq消息类型
- 8Git 命令_git exec
- 9Mysql find_in_set()函数_findinset走索引吗
- 10朋友问他是否该跳槽了?我是这么跟他说的
大数据框架:Spark 生态实时流计算_spark的两大流计算组件
赞
踩
在Spark框架当中,提起流计算,那么主要就是Spark Streaming组件来负责。在大数据的发展历程当中,流计算正在成为越来越受到重视的趋势,而Spark Streaming流计算也在基于实际需求不断调整。今天的大数据学习分享,我们就主要来讲讲Spark 实时流计算。
Spark流计算简介
Spark的Spark Streaming是早期的流计算框代表,同时还有Storm,也是针对于流计算,但是随着技术发展的趋势,Storm被逐渐抛弃。近几年,又有了Flink成为了流计算领域新的热门。

而Spark Streaming依靠着Spark生态,在流计算领域还有着不错的市场占有率。Spark Streaming也在发展当中,对自身的不足也进行改善。
从Spark 2.3开始,Structured Streaming引入了低延迟的持续流处理模式,不再采用批处理引擎,而是一种类似Flink机制的持续处理引擎,可以达到端到端最低1ms的延迟。
Spark Streaming
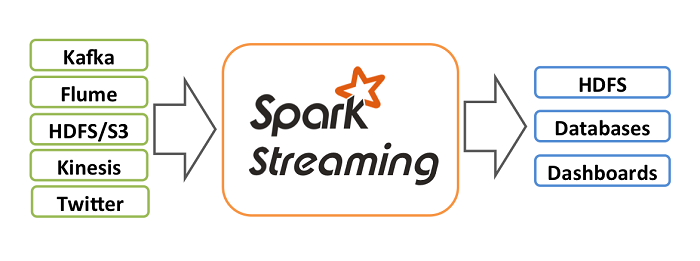
Spark Streaming,本质上来说,是一个基于批的流式计算框架,支持Kafka、Flume及简单的TCP套接字等多种数据输入源,输入流接收器(Reciever)负责接入数据。
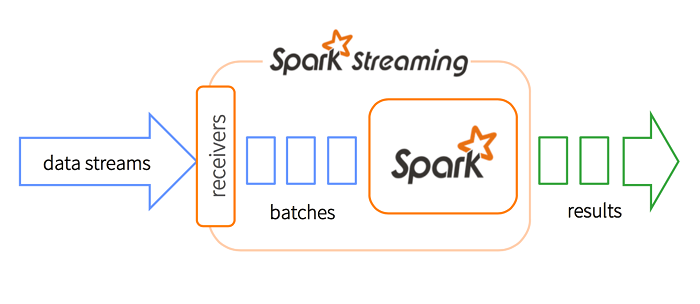
Spark Streaming在处理数据流之前,会按照时间间隔对数据流进行分段切分。Spark针对连续数据流的抽象,我们称为DStream(Discretized Stream)。DStream也可以被组织为DStreamGraph。Dstream本质上由一系列连续的RDD组成。
DStream是小批处理的RDD(弹性分布式数据集),RDD则是分布式数据集,可以通过任意函数和滑动数据窗口(窗口计算)进行转换,实现并行操作。
Structured Streaming
Spark 2.0之后,开始引入了Structured Streaming,将微批次处理从高级API中解耦出去。它简化了API的使用,API不再负责进行微批次处理;开发者可以将流看成是一个没有边界的表,并基于这些“表”运行查询。
Structured Streaming的默认引擎基于微批处理引擎,并且可以达到最低100ms的延迟和数据处理的exactly-once保证。采用何种处理模式只需要进行简单的模式配置即可。
Structured Streaming定义了无界表的概念,即每个流的数据源从逻辑上来说看做一个不断增长的动态表(无界表),从数据源不断流入的每个数据项可以看作为新的一行数据追加到动态表中。用户可以通过静态结构化数据的批处理查询方式(SQL查询),对数据进行实时查询。
Spark Streaming VS Structured Streaming
总结来说,这两种模式,从底层原理上就是完全不同的。
Spark Streaming采用微批的处理方法。每一个批处理间隔的为一个批,也就是一个RDD,我们对RDD进行操作就可以源源不断的接收、处理数据。
Structured Streaming将实时数据当做被连续追加的表,流上的每一条数据都类似于将一行新数据添加到表中。
在Spark 3.0之后,全新的Structured Streaming UI诞生,可见Spark生态在流处理上还有不断进步的目标和空间。
关于大数据学习,Spark生态实时流计算,以上就为大家做了简单的介绍了。流计算正在成为大数据技术越来越普及的趋势,而基于Spark生态的流计算一直提供着重要的技术支持。

