
热门标签
热门文章
- 1linux 下解压 zip 文件命令_linux解压zip命令
- 2Caused by: redis.clients.jedis.exceptions.JedisDataException: ERR Client sent AUTH, but no password
- 3【神经网络】(12) MobileNetV2 代码复现,网络解析,附Tensorflow完整代码_mobilenetv2代码
- 4一文看尽 6篇 CVPR2021 伪装目标检测、旋转目标检测论文
- 5为什么u盘在mac上显示不出来_苹果电脑插上u盘后看不到u盘
- 6cmath中的pow sqrt
- 7Xilinx Zynq器件要点(3)_xilinx ps与pl之间gp通信
- 8模型结构可视化工具-Netron在线使用
- 9人工智能的发展历程与未来趋势_人工智能发展历程及发展趋势
- 10mysql数据库中存储过程的创建视图_数据库入门(MySQL):视图、存储过程、触发器...
当前位置: article > 正文
基于python实现ocr_基于模板的ocr python
作者:小小林熬夜学编程 | 2024-06-04 22:44:04
赞
踩
基于模板的ocr python
Python实现ocr
总是会需要将图片中的文字识别出来,这就需要ocr技术。已经有很多很好用的在线文字识别网站了。比如:http://www.ocrmaker.com/
但是其实我们自己就可以实现文字识别了,通过python很容易实现这一点。基于pyhton实现ocr主要是使用tesseract。
安装tesseract和pytesseract
tesseract 是一个OCR 库,是目前公认最优秀、最精确的开源OCR 系统。tesseract下载地址
pytesseract是对应的pyhton中的库。
- 安装tesseract
进入页面后,可以随意下载一个版本。其中文件名中带有dev的为开发版本,不带dev的为稳定版本。

下载完成后,从下载目录中双击应用程序安装就可以了。安装的时候一直点击next就好。(建议不要在Additional language data前打上勾,它是用来安装语言包的,这样OCR就可以识别多国语言。但是因为我们网络的原因,我们很难成功下载其他的语言包,我们可以后续在GitHub中下载语言包。GitHub语言包下载地址 ,其实GitHub上的下载也不是很快而且会失败,但网上有很多教怎么从GitHub上下载的,实在无法下载,可以问我要。但注意语言包好像要和tesseract 匹配,所以识别英文很简单,想识别中文就有些麻烦。)

- 安装pytesseract
安装 pytesseract就简单了,直接pip install pytesseract就可以了。 - 配置环境变量
tesseract和pytesseract都安装好后,在使用前还有最后一步,就是配置环境变量,这是为了在全局使用方便。配置环境变量的方法也很简单。先找到属性,然后点击高级系统设置,再点击环境变量,找到path,然后双击,再最后添加tesseract的安装路径。比如我把tesseract安装到了D:\360极速浏览器下载,就在path中添加行D:\360极速浏览器下载就可以了。


- 检验是否成功
都完成后,在cmd中输入tesseract -v,如果出现如下图所示的情况,就说明都已经成功了,可以在pyhton中使用了。
实别图片中的文字
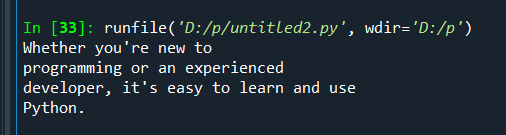
都安装好后,识别图片中的文字就很简单了,只需要几行代码既可以解决。
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'D:\360极速浏览器下载\tesseract.exe'
img = Image.open(r'D:\p\python.png')
text = pytesseract.image_to_string(img)
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
图片:

识别结果:
最后想要识别中文时,只需要一点小小的改动,就是在pytesseract.image_to_string(img)后面添加一个lang=‘chi_sim’(识别中文时,对黑白图片的效果更好,如果图片是彩色的可以先进行一些预处理。另外中文的识别效果不是很理想,不推荐使用。)
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'D:\360极速浏览器下载/tesseract.exe'
img = Image.open(r'D:\p\poem.png')
text = pytesseract.image_to_string(img,lang='chi_sim')
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
图片:

识别结果:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/673822
推荐阅读
相关标签

