
- 1java学习路线图分享_java学习路线图千峰
- 2MongoDB默认_id字段_mongodb的id是什么类型的
- 3ModStartBlog v9.4.0 后台安全升级,已知问题修复
- 4读取AndroidManifest文件的meta-data数据_androidmanifest 读取 配置
- 5Linux -- 磁盘存储管理 分区类型(MBR,GPT)_linux mbr gpt
- 6CFAR原理详解及其matlab代码实现_cfar检测原理
- 7ZYNQ之嵌入式开发01——HelloWorld实验
- 8Android-->AndroidManifest.xml 文件
_androidmanifest meta-data - 9Dify快速接入微信
- 10刚刚,我们和ChatGPT聊了聊边缘计算
分布式云计算_集中式计算原理图
赞
踩
云计算(持续更新中…)
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
一、分布式计算概述
1.1 集中式计算
集中式计算完全依赖于一台大型的中心计算机的处理能力,这台中心计算机称为主机(Host或mainframe),与中心计算机相连的终端设备具有各不相同非常低的计算能力。实际上大多数终端完全不具有处理能力,仅作为输入输出设备使用
1.2 分布式计算
与集中式计算相反,分布式计算中,多个通过网络互联的计算机都具有一定的计算能力,它们之间互相传递数据,实现信息共享,协作共同完成一个处理任务。
中国科学院对分布式计算有一个定义:
分布式计算就是在两个或多个软件互相共享信息,这些软件既可以在同一台计算机上运行,也可以在通过网络连接起来的多台计算机上运行。
- 1
二、分布式计算优点
稀有资源可以共享;
通过分布式计算可以在多台计算机上平衡计算负载;
可以把程序放在最适合运行它的计算机上。
三、分布式计算原理
分布式计算就是将计算任务分摊到大量的计算节点上,一起完成海量的计算任务。而分布式计算的原理和并行计算类似,就是将一个复杂庞大的计算任务适当划分为一个个小任务,任务并行执行,只不过分布式计算会将这些任务分配到不同的计算节点上,每个计算节点只需要完成自己的计算任务即可,可以有效分担海量的计算任务。而每个计算节点也可以并行处理自身的任务,更加充分利用机器的CPU资源。最后再将每个节点的计算结果汇总,得到最后的计算结果。
提示:并不是所有的计算任务都可以分布式计算,必须是可以并行计算,前后没有逻辑连接,把没有逻辑相关的任务才可以拆开,否则效率和串行计算一样:
四、分布式计算的步骤
4.1.设计分布式计算模型
首先要规定分布式系统的计算模型。计算模型决定了系统中各个组件应该如何运行,组件之间应该如何进行消息通信,组件和节点应该如何管理等。
4.2.分布式任务分配
分布式算法不同于普通算法。普通算法通常是按部就班,一步接一步完成任务。而分布式计算中计算任务是分摊到各个节点上的。该算法着重解决的是能否分配任务,或如何分配任务的问题。
4.3.编写并执行分布式程序##
使用特定的分布式计算框架与计算模型,将分布式算法转化为实现,并尽量保证整个集群的高效运行,难点:
(1)计算任务的划分
(2)多节点之间的通信方式
五、分布式计算的理论基础
5.1.ACID原则
ACID是数据库事务正常执行的四个原则,分别指原子性、一致性、独立性及持久性。
5.1.1 A(Atomicity)—原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
例如银行转账,从A账户转100元至B账户,分为两个步骤:①从A账户取100元;②存入100元至B账户。
这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
5.1.2C(Consistency)—一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a + b = 10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a + b = 10,否则事务失败。
5.1.3I(Isolation)—独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
例如交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
5.1.4D(Durability)—持久性
持久性是指一旦事务提交后,它所做的修改将会永久保存在数据库上,即使出现宕机也不会丢失。
这些原则解决了数据的一致性、系统的可靠性等关键问题,为关系数据库技术的成熟以及在不同领域的大规模应用创造了必要的条件。
六、CAP理论定义
2000年7月,加州大学伯克利分校的埃里克·布鲁尔(Eric Brewer)教授在ACM PODC会议上提出CAP猜想。2年后,麻省理工学院的塞思·吉尔伯符(Seth Gilbert)和南希·林奇(Nancy Lynch)从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。 一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- 1
6.1一致性
一致性指“All nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。对于一致性,可以分为从客户端和服务端两个不同的视角来看。
从客户端来看,一致性主要指多并发访问时更新过的数据如何获取的问题。
从服务端来看,则是如何将更新复制分布到整个系统,以保证数据的最终一致性问题。
6.2可用性
可用性是指“Reads and writes always succeed”,即服务一直可用,而且是在正常的响应时间内。对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是该系统使用的任何算法必须最终终止。
当同时要求分区容错性时,这是一个很强的定义:即使是严重的网络错误,每个请求也必须终止。好的可用性主要是指系统能够很好地为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。通常情况下可用性和分布式数据冗余、负载均衡等有着很大的关联。
6.3分区严重性
分区容错性指“The system continues to operate despite arbitrary message loss or failure of part of the system”,也就是指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求应用虽然是一个分布式系统,但看上去却好像是一个可以运转正常的整体。例如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,或者是机器之间有网络异常,将分布式系统分隔为独立的几个部分,各个部分还能维持分布式系统的运作,这样就具有好的分区容错性。
6.4CAP权衡
通过CAP理论,知道无法同时满足一致性、可用性和分区容错性这三个特性,那应该如何取舍呢?
(1)CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。
(2)CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
(3)AP without C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
常用CP、AP(CA网络要求高,现阶段很难做到)
- 1
6.5CAP理论的阐述与证明
[外链图片转存中…(img-pHAjaYCG-1648268172528)]
| 图1 CAP的基本场景 |
|---|
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D0DzOpac-1648268172529)(https://s2.loli.net/2022/03/26/uLfMdkzJgUbFhtQ.png)]
| 图2 分布式系统正常运转的流程 |
|---|
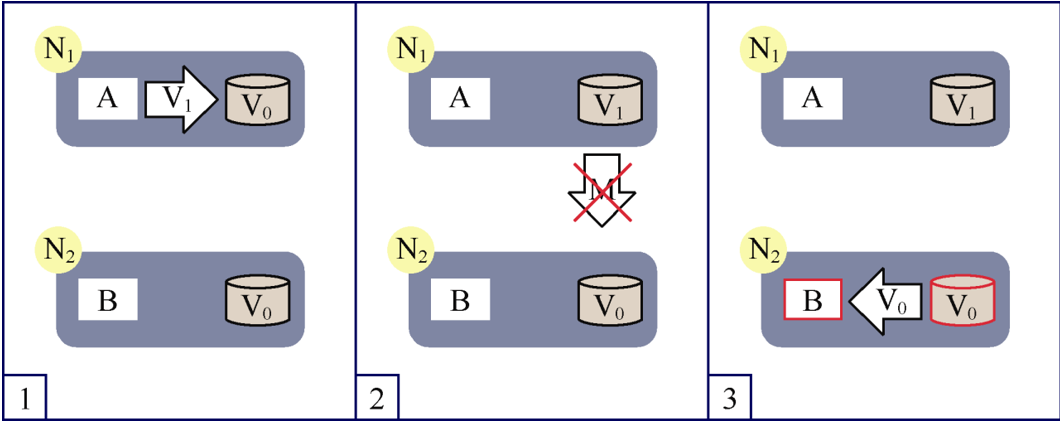
| 图3 断开N1和N2之间的网络 |
|---|
七、BASE理论
丹·普里切特(Dan Pritchett)在对大规模分布式系统的实践总结过程中,提出了BASE理论,BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consistency)。
- 1
BASE是指基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency)。
7.1基本可用
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
7.2软状态
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。例如MySQL replication的异步复制就是这种体现。
7.3最终一致性
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
BASE和ACID的区别与联系是什么呢?ACID是传统数据库常用的设计理念,追求强一致性模型。BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。ACID和BASE代表了两种截然相反的设计哲学。在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此ACID和BASE又会结合使用。
下面以上面的场景来描述下不同程度的一致性:
- 1
7.3.1强一致性(即时一致性
假如A先写入了一个值到存储系统,存储系统保证后续A、B、C的读取操作都将返回最新值。
7.3.2弱一致性
假如A先写入了一个值到存储系统,存储系统不能保证后续A、B、C的读取操作能读取到最新值。此种情况下有一个“时间窗口”的概念,它特指从A写入值,到后续操作A、B、C读取到最新值这一段时间。“时间窗口”类似时空穿梭门,不过穿梭门是可以穿越到过去的,而一致性窗口只能穿越到未来,方法很简单,就是“等会儿”。
7.3.3最终一致性
是弱一致性的一种特例。假如A首先“写”了一个值到存储系统,存储系统保证如果在A、B、C后续读取之前没有其他写操作更新同样的值的话,最终所有的读取操作都会读取到A写入的最新值。此种情况下,如果没有失败发生的话,“不一致性窗口”的大小依赖于以下的几个因素:交互延迟,系统的负载,以及复制技术中复本的个数。最终一致性方面最出名的系统可以说是DNS系统,当更新一个域名的IP以后,根据配置策略以及缓存控制策略的不同,最终所有的客户都会看到最新的值。
八、分布式存储的算法
如何将网络数据“均匀”地存储到多个服务器中?
可将数据的键“key”进行Hash计算,得到值,再对服务器数量取模
- 1
- 2
8.1一致性散列算法
一致性散列算法(Consistent Hashing)最早在论文Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web中被提出。简单来说,一致性散列将整个散列值空间组织成一个虚拟的圆环。假设某散列函数H的值空间为0~232-1(即散列值是一个32位无符号整形),整个散列空间环如图4所示。
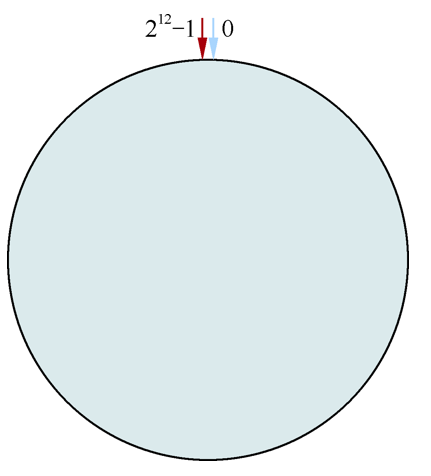
| 图4 |
|---|
8.1.1容错性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般来说,在一致性散列算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间的数据,其他不会受到影响,如图5所示。
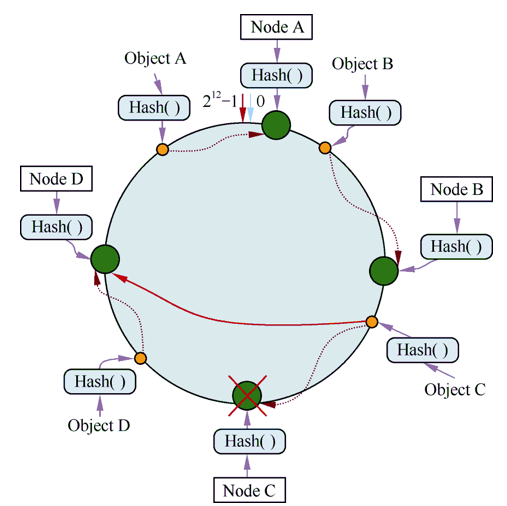
| 图5 |
|---|
8.1.2拓展性
如果在系统中增加一台服务器Node X,如图6所示。
此时对象A、B、D不受影响,只有对象C需要重定位到新的Node X。一般来说,在一致性散列算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其他数据也不会受到影响。
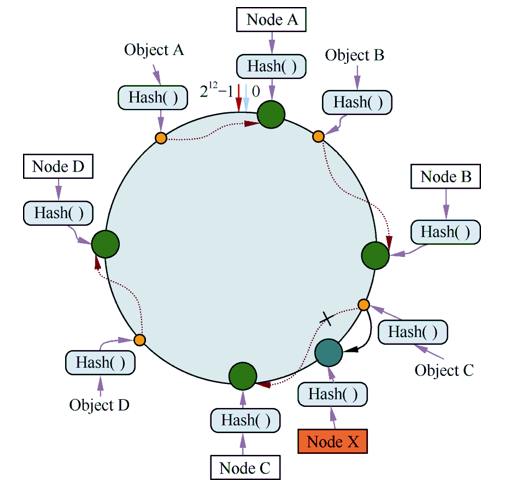
| 图6 |
|---|
8.1.3虚拟节点
一致性散列算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如图7所示。
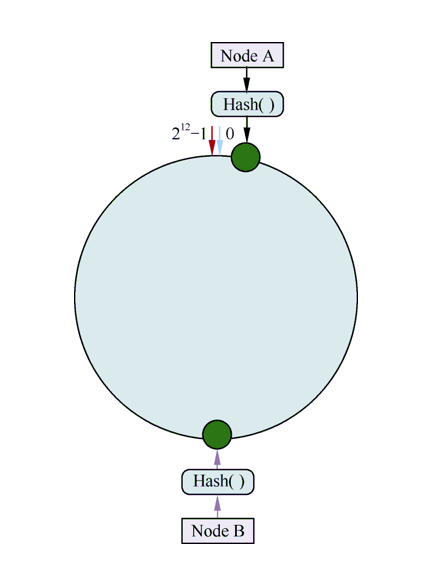
| 图7 |
|---|
总结
提示:这里对文章进行总结:


