
- 1Tesseract OCR 训练字库_tesseract训练自己的字库
- 2数组和广义表 讲义实现_数组与广义表基本操作c
- 3提升开发安全5大成熟度 跨国企业落地默安“一站式”方案_开发安全能力提升
- 4排序算法案例_郑州航空大学
- 5SpringCloud之Gateway(服务网关)_springcloud 查看 gateway 是否生效
- 6还在用HttpUtil?SpringBoot 3.0全新HTTP客户端工具来了,用起来够优雅~_spring 新版本自带的 http 客户端工具
- 7华为昇腾AI芯片加持,9.1k Star 的 Open-Sora-Plan,国产Sora要来了吗_opensora-plan
- 8深度学习(十一):YOLOv9之最新的目标检测器解读_yolov9 智慧 检测
- 9在iOS设备上演示Axure原型的方法
- 107套干货,Python常用技术学习知识图谱!!(史上最全,建议收藏(2)
新鲜出炉!ACL2024主会文章:实体关系分析助力大型语言模型攻克复杂推理挑战_era-cot: improving chain-of-thought through entity
赞
踩
DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
今天更新的是今天刚出结果,中了ACL2024 main的文章!
引言:探索LLMs在复杂实体场景中的推理挑战
在自然语言处理(NLP)的众多任务中,大型语言模型(LLMs)已经取得了令人瞩目的成就。然而,当面对涉及多个实体的复杂场景时,LLMs仍然面临着重大挑战。这些挑战源于场景中隐含的实体关系,这些关系往往不是显而易见的,需要模型进行多步推理才能理解。为了解决这一问题,研究者们提出了各种策略,如Chain-of-Thought(CoT)提示,以增强LLMs的推理能力。然而,即便如此,当场景中存在大量如人物、地点等实体以及它们之间复杂的隐含关系时,CoT策略仍面临显著挑战。本文介绍了一种新颖的框架——实体关系分析与Chain-of-Thought(ERA-CoT),旨在更好地解决复杂实体场景中的推理任务。通过提取文本中涉及的所有实体,明确实体间的直接显性关系,推断出基于这些显性关系和文本中隐藏信息的间接隐性关系,ERA-CoT显著提高了LLMs在问题回答和推理能力方面的准确性。
论文标题、机构、论文链接
论文标题: ERA-CoT: Improving Chain-of-Thought through Entity Relationship Analysis
机构: Yanming Liu1, Xinyue Peng2, Tianyu Du1, Jianwei Yin1, Weihao Liu, Xuhong Zhang1 (1Zhejiang University, 2Southeast University)
论文链接: https://arxiv.org/pdf/2403.06932.pdf
ERA-CoT方法概述:提升LLMs的实体关系理解与推理
1. 实体关系分析的重要性
在自然语言处理任务中,大型语言模型(LLMs)虽然取得了显著的成就,但在涉及多个实体的复杂场景中,它们仍面临着显著的挑战。这些挑战源于场景中存在的隐含关系,这些关系需要多步推理来理解。为了解决这一问题,我们提出了一种新颖的方法——实体关系分析与思维链(ERA-CoT),它通过捕捉实体之间的关系来帮助LLMs理解上下文,并通过思维链(CoT)支持多样化任务的推理。
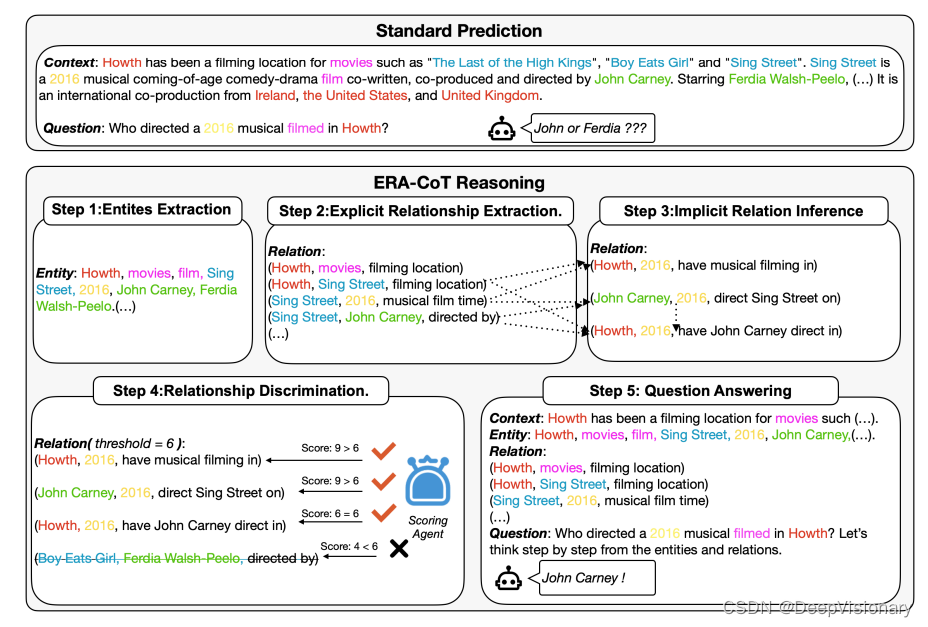
2. ERA-CoT框架的五个步骤
ERA-CoT框架包括五个阶段,每个阶段都涉及对实体关系理解的不同程度的增强。这些步骤包括:
- 实体提取:利用LLMs的信息提取能力,从文本中提取所有实体,并将它们表示为实体类型和跨度的配对关系。
- 显式关系提取:在零样本设置中探索不同实体之间的相关关系,生成文本中直接陈述的实体对关系。
- 隐式关系推断:基于前述步骤中发现的显式关系,进行多步推理以发现隐式关系。
- 关系鉴别:依赖于LLMs的自我修正能力,为每个关系三元组打分,并设定阈值来评估模型推断关系的正确性。
- 问题回答:基于上述关系,将它们与原始上下文结合到提示中,以预测问题的答案。
实验设计:评估ERA-CoT的有效性
1. 数据集与模型选择
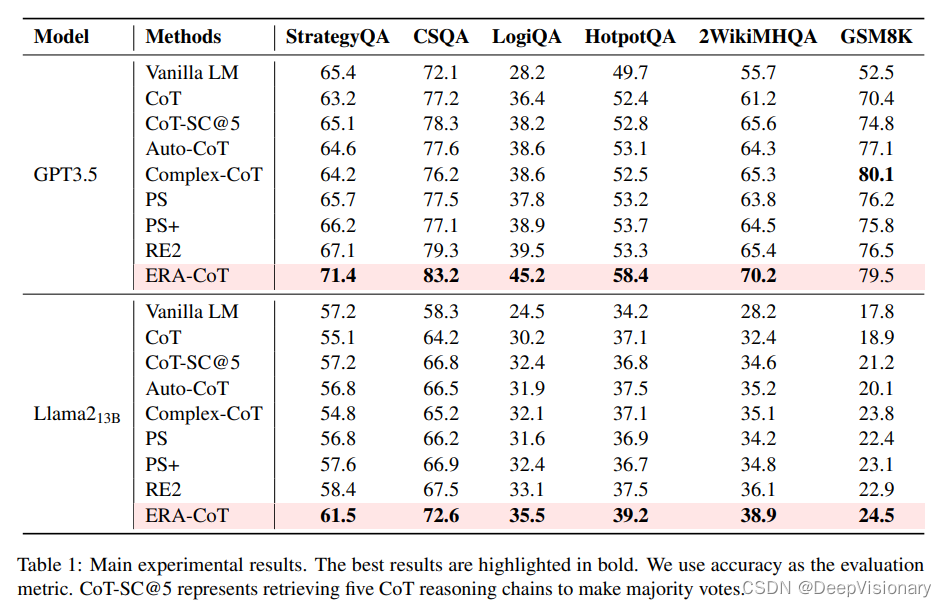
我们考虑了三种推理场景:常识推理、逻辑推理和数学推理。对于常识推理,我们使用StrategyQA和CSQA数据集;对于逻辑推理,我们使用LogiQA、HotpotQA和2WikiMultiHopQA数据集;对于数学推理,我们使用GSM8K数据集。在模型方面,我们使用了GPT3.5(拥有1750亿参数)和Llama213B。
2. 基线方法与比较
为了全面评估我们的方法,我们将ERA-CoT与领先的CoT方法基线进行了比较,包括:
- Vanilla LM:直接提出任务和相应问题,通过上下文学习预测问题的结果。
- CoT:通过生成解释和步骤来预测答案。
- CoT-SC:生成多条思维链并投票选择得票最高的结果作为最终结果。
- Auto-CoT:自动生成多步推理的自然语言。
- Complex-CoT:采用基于复杂性的多步推理策略。
- PS和PS+:将问题分解为计划和解决步骤,以生成思维链的答案。
- RE2:在推理过程中重新阅读问题以提高模型对问题的理解。
我们通过OpenAI API访问GPT模型,并使用gpt-3.5-turbo-0301作为我们的关系鉴别评分代理。为了确保结果的可靠性,我们对每个数据集进行了五轮实验,并将它们的平均分数作为评估结果。评估指标采用精确匹配(EM)。
主要结果:ERA-CoT在各类推理任务中的表现
1. 常识推理
ERA-CoT在常识推理任务中表现出色,特别是在StrategyQA和CommonsenseQA数据集上,与传统的CoT方法相比,平均提升了约6.1%。ERA-CoT通过控制基于实体关系的推理过程,减少了不相关文本的影响,从而提高了推理的准确性。在Llama13B模型上应用实体关系作为提示,也显示了类似的改进效果。
2. 逻辑推理
逻辑推理任务中,ERA-CoT在LogiQA、HotpotQA和2WikiMHQA三个数据集上平均提升了5.1%,这一结果凸显了该方法相较于其他基线方法的有效性。ERA-CoT在涉及关系推理的任务中表现更佳,这表明该方法可能更适合处理涉及关系推理的任务。在小型LLM上,ERA-CoT Llama13B也取得了类似的性能,表明ERA-CoT在长文本理解和实体逻辑推理方面可能具有更好的能力。
3. 数学推理
在GSM8K数据集上评估ERA-CoT的数学推理能力时,ERA-CoT在大多数基线方法中表现最佳,仅略逊于Complex-CoT。ERA-CoT主要依赖于分析上下文中的实体关系来帮助模型理解问题,这可能解决了CoT在分析关系链时的一些错误。
消融研究:评估不同组件对模型性能的影响
1. 实体提取与显式关系提取的组合
实体提取与显式关系提取的组合(EE+ERE)表明,在完成ERA-CoT的前两个步骤后,该过程直接进行问题预测。这种设置对于任务推理有积极影响,与ERA-CoT相比,仅进行实体提取的性能在多个数据集上有所下降。基于我们的提示进行实体提取后,任务预测显示出显著的改善。
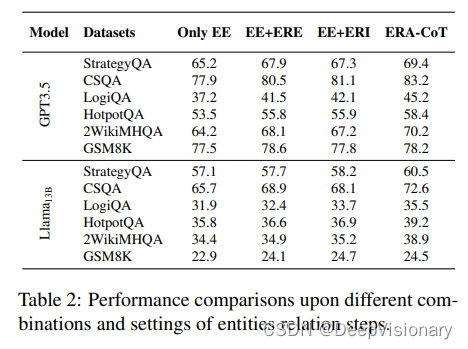
2. 实体提取与隐式关系推理的组合
实体提取与隐式关系推理的组合(EE+ERI)表明,在实体提取之后,我们直接推断实体之间的关系,并基于实体提取和关系推理的结果进行答案预测。直接关系推理增强了模型的答案预测性能。然而,由于没有经过关系提取,推断出的关系缺乏实体的基础关系,导致评估性能不如ERA-CoT。
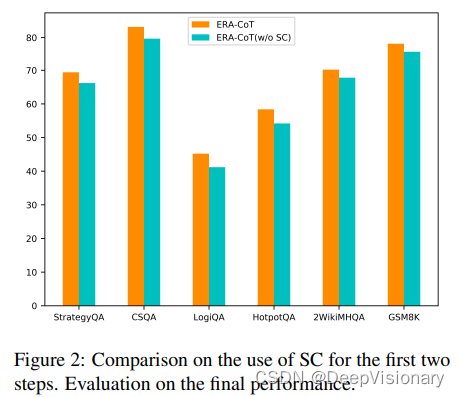
3. 自洽性(Self-Consistency)的有效性
自洽性(SC)的有效性在ERA-CoT方法中非常重要。去除SC后,ERA-CoT方法在GPT3.5上的平均性能下降了约3.2%,这一结果突出了在该过程的前两个步骤中整合自洽性的必要性。
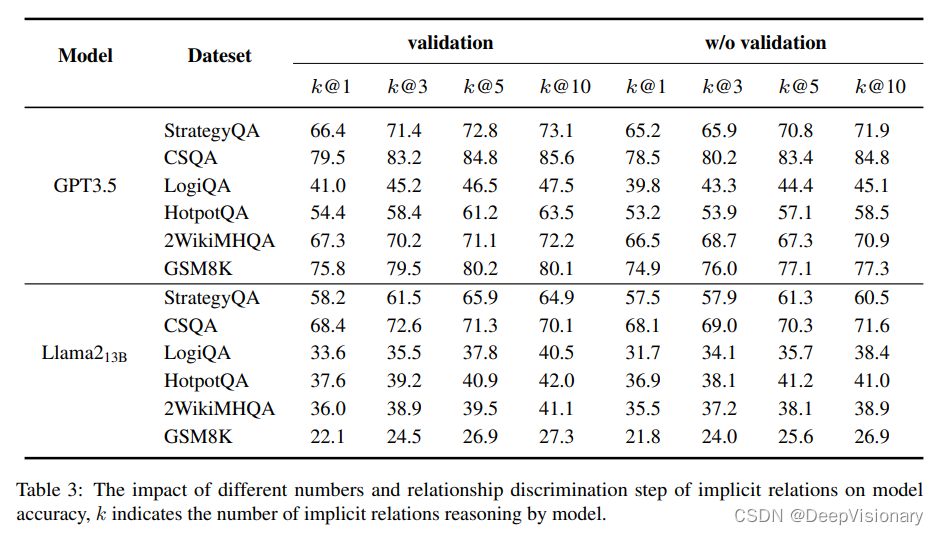
隐式关系推理分析:k值对模型性能的影响
1. 隐式关系推理的重要性
隐式关系推理是指在文本中未直接提及的实体关系的推断过程。这些关系通常需要多步推理来发现,因此比直接从文本中提取的显式关系更具挑战性。在ERA-CoT框架中,隐式关系推理是基于先前发现的显式关系进行的。模型需要生成k个最相关的关系,并对这些关系进行评分,以确定它们的可靠性。
2. k值的影响
k值代表模型在推理过程中考虑的隐式关系的数量。实验结果表明,隐式关系的数量对模型的准确性有显著影响。当k值较小时,模型的准确性显著提高。然而,如果k值过大,可能会导致模型产生幻觉效应,从而影响最终的推理判断。因此,选择一个合理的k值对于平衡模型的有效性和复杂性至关重要。实验发现,将k值设置为3可以为模型带来更好的准确性,同时在复杂关系场景中不会显著增加方法的复杂性。
3. 关系评分步骤
关系评分步骤涉及对所有隐式关系进行评分,并过滤掉低于预定义阈值vth的关系。这一步骤有助于消除模型推理过程中可能产生的错误关系,从而提高其一致性和准确性。实验表明,执行关系歧视步骤的模型比没有执行该步骤的模型具有更高的准确性。
4. 小型LLM的隐式关系识别能力
在Llama213B模型上的实验表明,随着k值从1增加到5,模型的平均性能提高了+4.4%。然而,小型模型对文本的理解较弱,随着推断的隐式关系数量的增加,它们更容易生成错误的关系,导致性能不稳定。
错误分析:对模型错误的分类与讨论
1. 错误分类
在对100个错误样本进行手动分析后,将错误分为以下四类:
- (i) 实体提取错误(En.):未能识别文本中的所有实体。
- (ii) 显式关系提取错误(Ex.):正确提取了实体,但未能提取文本中的所有显式关系或提取了不存在的显式关系。
- (iii) 隐式关系推理错误(Im.):正确提取了实体和显式关系,但推断了不存在的隐式关系。
- (iv) 答案错误(An.):ERI正确推断了关系,但提供了错误的答案。
2. 隐式关系推理的错误倾向
从错误分类结果来看,隐式关系推理错误(Im.)的概率一致最高,而实体提取错误(En.)的概率相对较低。这表明隐式关系推理对模型准确性的影响最大。
3. 数据集特性对错误率的影响
对于常识推理数据集,显式关系提取错误(Ex.)和隐式关系推理错误(Im.)的错误率接近。这可能是因为模型由于对常识知识理解不完整,可能错误判断实体之间的关系。对于涉及较长文本和更多关系的数据集,显式关系提取错误(Ex.)的错误率较高。然而,与其他错误相比,答案错误(An.)的错误率相对较小。这表明如果实体之间的关系正确推断,模型很可能正确回答问题。这表明准确的关系推断对于正确回答此类数据集中的问题非常有益。
4. 数学推理数据集
在数学推理数据集中,隐式推理有助于提高数据集的准确性,但不应忽视答案错误(An.)。这是因为即使关系推断正确,计算错误也可能导致错误的答案。
结论与未来工作:ERA-CoT的贡献与局限性
1. ERA-CoT的贡献
ERA-CoT(Entity Relationship Analysis with Chain-of-Thought)是一种新颖的框架,旨在通过实体关系分析来增强大型语言模型(LLMs)在处理复杂实体场景中的推理任务。通过五个阶段的推理过程,ERA-CoT不仅提取文本中的实体,还分析实体间的显式和隐式关系,进而提高问题回答的准确性。实验结果显示,ERA-CoT在多个基准测试中均优于现有的CoT方法,平均提高了5.1%的性能,尤其在涉及复杂关系推理的任务中表现突出。
2. ERA-CoT的局限性
尽管ERA-CoT在多个推理任务中取得了显著的性能提升,但它在某些场景中仍存在局限性。首先,ERA-CoT依赖于对文本中实体关系的分析,因此在实体关系较少的任务中,如符号推理任务,性能提升不明显。其次,由于实体间的关系多样,即使经过关系提取和推理,模型仍可能无法正确推断或提取所有关系,这可能导致在预测结果时遗漏关系,影响预测的准确性。
3. 未来工作
未来的工作将致力于解决上述局限性。我们计划探索模型是否能有效理解实体的内部结构,并对实体关系进行更深入的分析,以增强LLMs提示的有效性。此外,我们还将探索如何将ERA-CoT与其他方法结合,以进一步提高模型在不同领域中的性能。
附录:实验细节、数据集统计与案例分析
1. 实验细节
实验使用了GPT3.5和Llama213B两种模型,并在commonsense reasoning、logical reasoning和mathematical reasoning三种推理场景中进行了评估。ERA-CoT与多种基线方法进行了对比,包括Vanilla LM、CoT、CoT-SC、Auto-CoT、Complex-CoT、PS和PS+、RE2等。实验中采用了准确率(accuracy)和精确匹配(exact match)作为评价指标,并通过OpenAI API访问GPT模型,对于Llama213B模型则使用了原始代码提供的模型参数。
2. 数据集统计
数据集包括StrategyQA、CSQA、LogiQA、HotpotQA、2WikiMultiHopQA和GSM8K等,涵盖了不同类型的推理问题。数据集的统计信息(如样本数量和平均令牌数)见附表5。
3. 案例分析
ERA-CoT的五个步骤包括实体提取、显式关系提取、隐式关系推断、关系判别和问题回答。案例分析展示了ERA-CoT如何在处理一个StrategyQA数据集的问题时,通过这些步骤来提高问题回答的准确性。具体案例见附表6。
4. 错误分析
对100个错误样本进行了手动分析,将错误归类为实体提取错误、显式关系提取错误、隐式关系推断错误和回答错误四种类型。隐式关系推断错误的概率最高,而实体提取错误的概率相对较低。这表明隐式关系推断对模型准确性的影响最大。错误分析的详细结果见附表4。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!

