
- 1第一卷清晨的帝国 第一百四十六章 你真的很美_侍奴晨起封祁渊
- 215、Linux日志审计
- 3Linux 添加Nginx 到 service 启动 (完整篇)
- 4git强推覆盖其他项目分支_git extensions怎么强推分支
- 5AI写真教程:Stable Diffusion 之 IPAdapter-FaceId
- 6GIS原理学习目录
- 7使用wind量化金融终端,碰到no moudle named “WindPy“的问题_no module named 'windpy
- 8学习 Git与GItlab_git的作用
- 9SQL Server学习笔记——函数_sql server function
- 10[算法] 优先算法(二): 双指针算法(下)
如何在本地部署使用llama3?_llama 3 本地部署
赞
踩
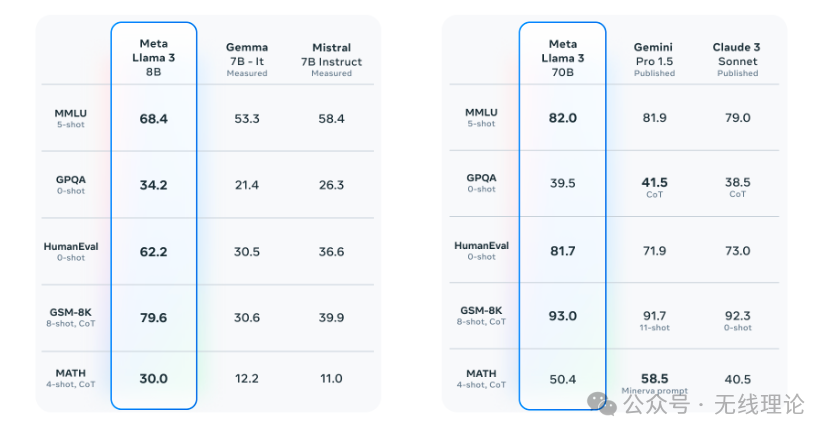
最近这几天,许多网友都在各大平台上分享如何使用llama3的方法。这个开源大模型几天前刚刚才由Meta发布。本次发布Metat共提供了两个版本的Llama 3 ,8B 版本适合在消费级 GPU 上高效部署和开发;70B 版本则专为大规模 AI 应用设计。每个版本都包括基础和指令调优两种形式。所有版本均可在各种消费级硬件上运行,并具有 8000 Token 的上下文长度。
下面介绍llama3的几种部署使用方式!
首先是第一种部署llama3的方法,您可以直接采用在GitHub网站上提供的llama3部署方法。具体步骤如下:第一步,从GitHub上下载llama3的源代码到您的本地电脑。
git clone https://github.com/meta-llama/llama3``cd ./llama3
- 1
第二步,在本地电脑上建立一个python虚拟环境并将其激活,
python -m venv venv #建立虚拟环境``./venv/Scripts/activate #激活虚拟环境
- 1
第三步,安装项目依赖
pip install -e .``pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
- 1
第四步,获取meta提供的llama3的大模型。

第五步,为llama3配置运行环境;首先找到并打开下图所示的文件,
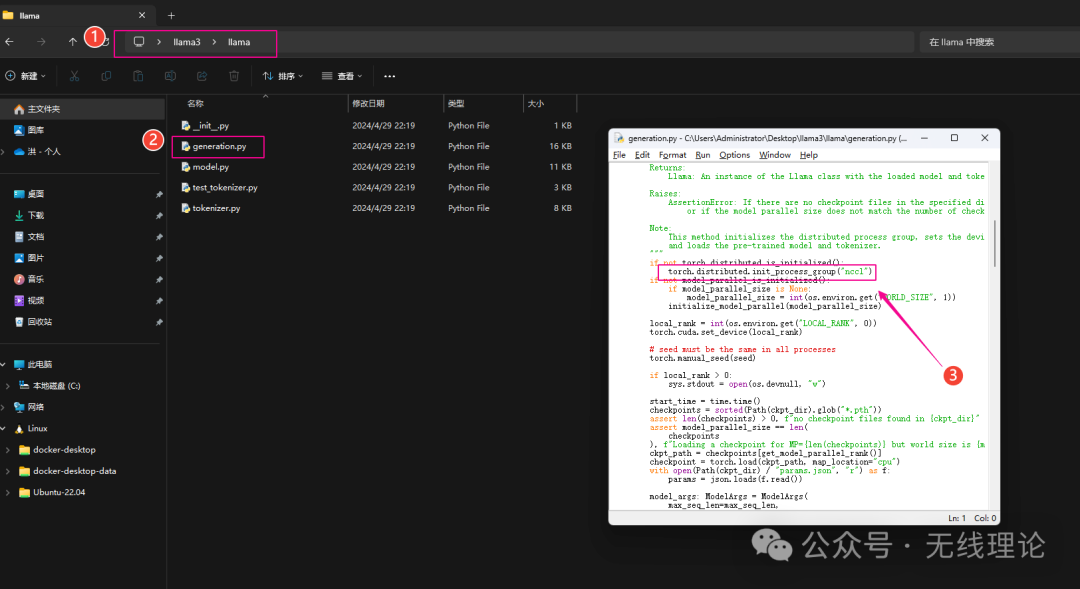
在文件内搜索下面的程序段:
torch.distributed.init_process_group("nccl")
- 1
并将其修改为:
torch.distributed.init_process_group("gloo")
- 1
保存后退出文件,随后在windows终端依次输入下面的指令来配置几个临时的环境变量:
set MASTER_ADDR=localhost``set MASTER_PORT=12355``set RANK=0``set WORLD_SIZE=1
- 1

第六步,新建一个名为chat的py文件,并在该文件内粘贴下图所示的程序代码

第七步,输入下面的指令来运行llama3项目
python chat.py --ckpt_dir Meta-Llama-3-8B-Instruct/ --tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model --max_seq_len 512 --max_batch_size 6
- 1

第二种方式,使用Jan来运行llama3项目,
Jan是一款开源、自托管的聊天GPT替代品,可以100%离线在您的计算机上运行。Jan提供可定制的AI助手、全局热键和内联AI等功能,可以提高您的生产力。Jan支持在本地主机上提供OpenAI等价API服务器,可以与兼容的应用程序一起使用。Jan的对话、偏好和模型使用等数据都保留在您的计算机上,安全、可导出,并可随时删除。

第一步,为确保llama3在jan上正常运行,请首先通过以下链接将jan下载到您的本地电脑上:
https://github.com/janhq/jan/releases/download/v0.4.12/jan-win-x64-0.4.12.exe
- 1
随后在本地电脑上完成jan的安装,
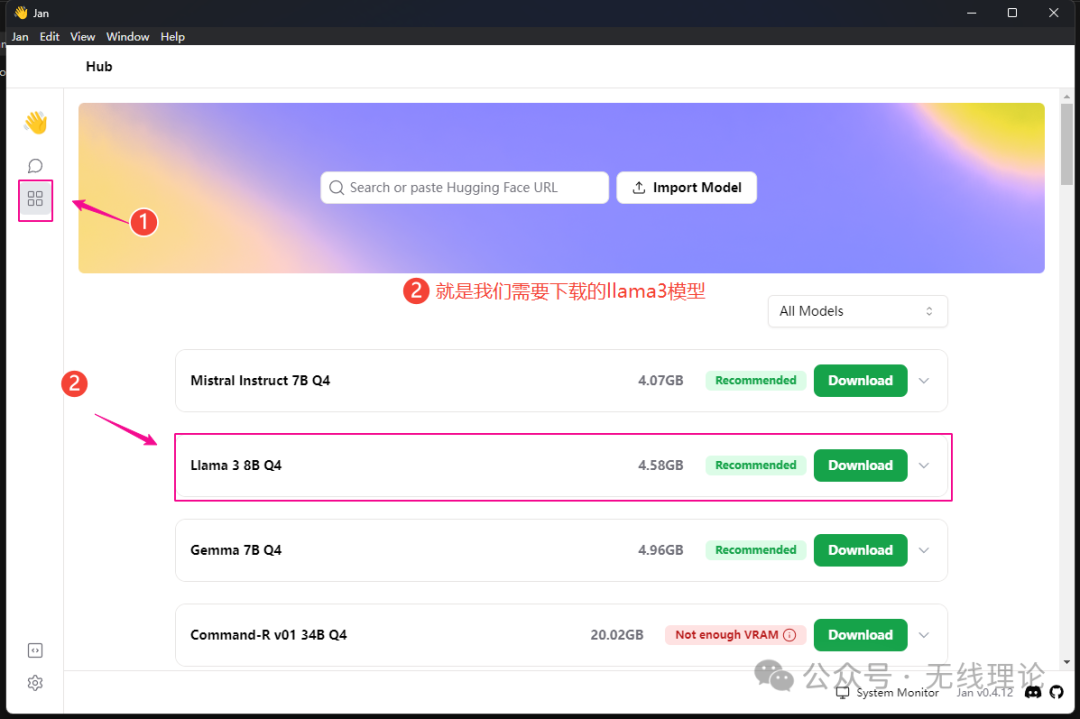
第二步,下载llama3模型。在jan平台上运行的llama3模型需要是GGUF文件格式。实际上,jan平台我们不仅可以下载llama3模型,我们还可以下载其他类型的模型;
如果因网络问题无法成功下载模型,本文末尾将提供一个直接下载llama3模型的替代方法。下载模型后,您需要将其存放在以下路径中。【请注意,路径中的‘Administrator’代表计算机名;您应将其替换为自己的计算机名。】
C:\Users\Administrator\jan\models
- 1
如下所示:

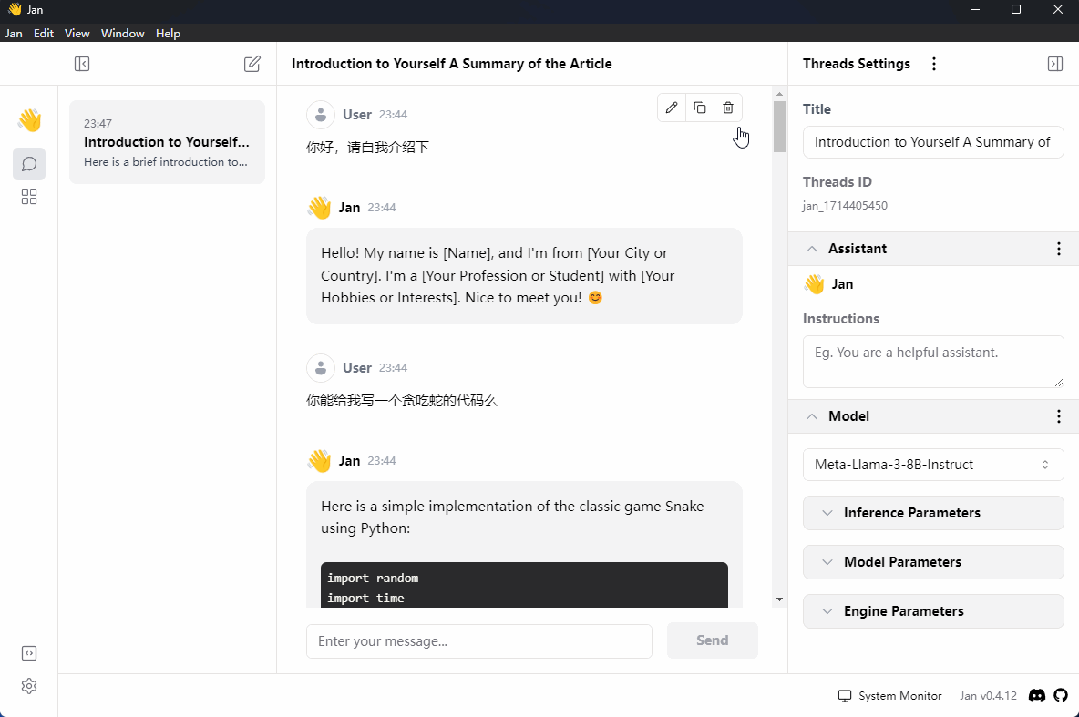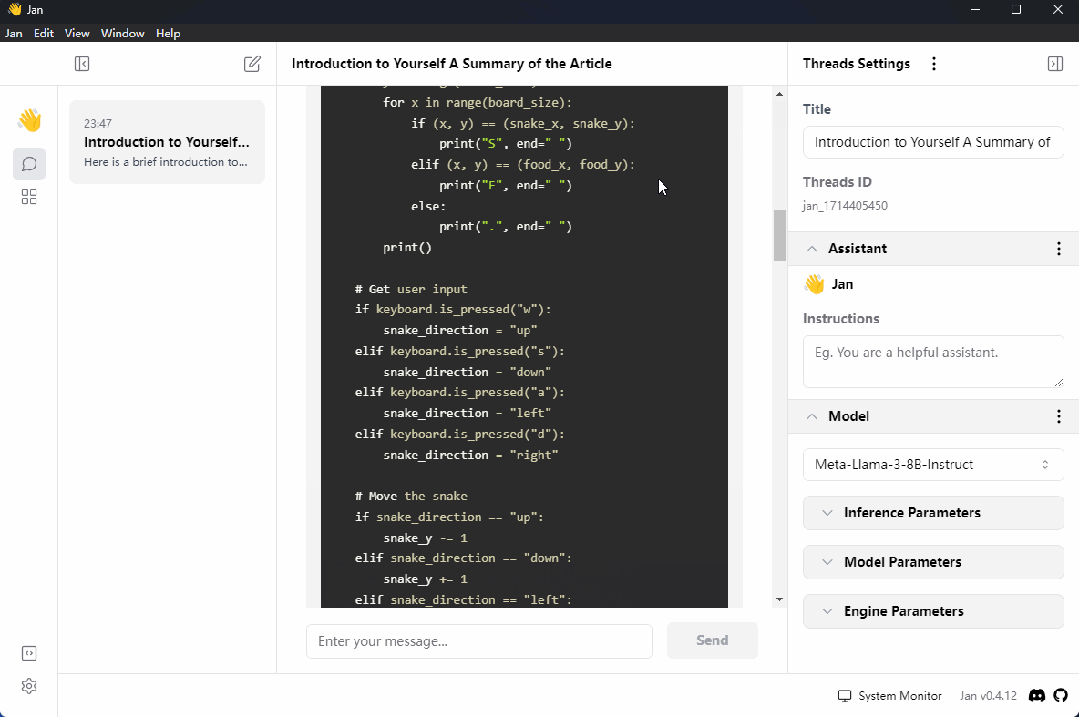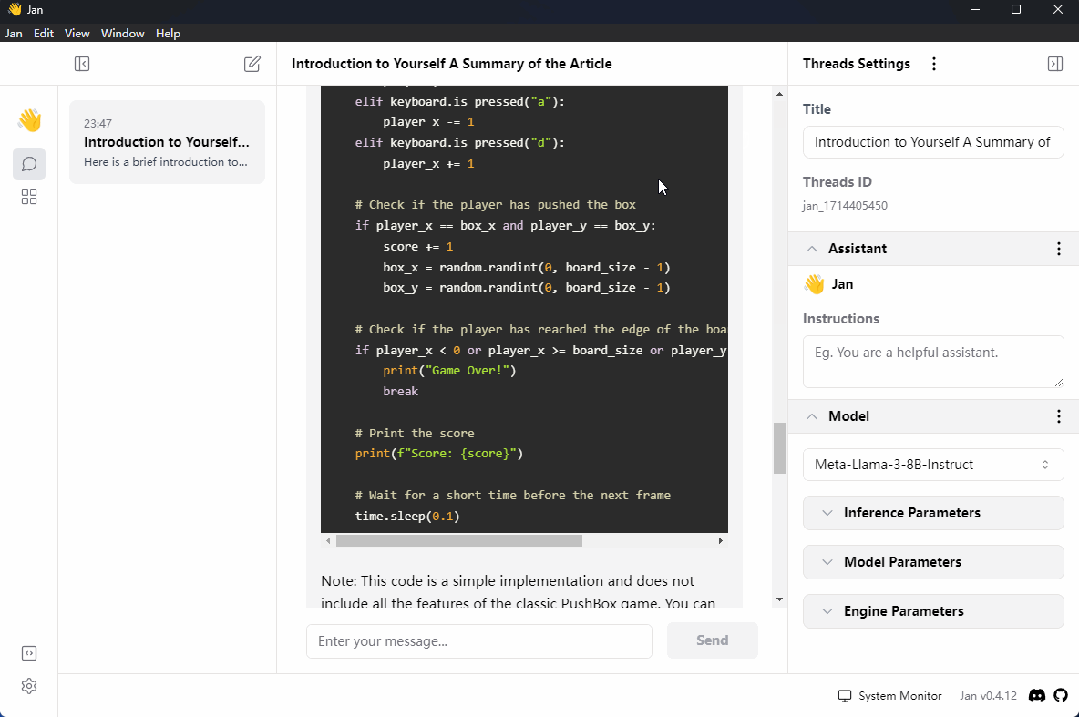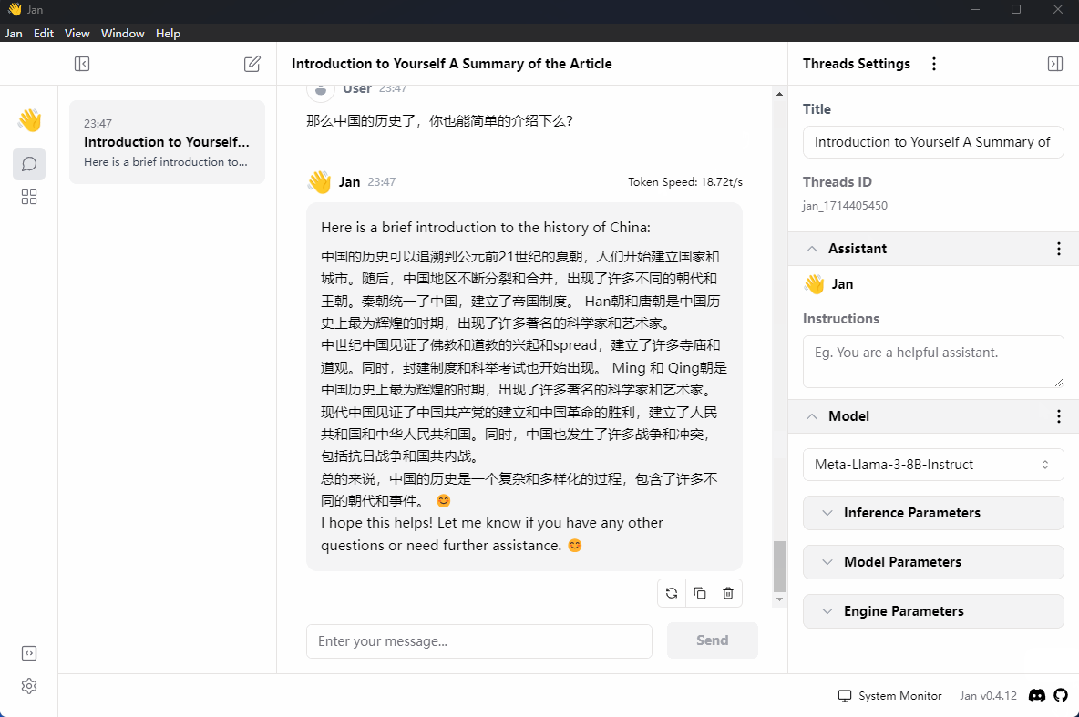
第三步,使用jan提供的平台与llama3大模型展开正常聊天,
首先将你的llama3模型加载进来,按照下图演示的步骤依次完成模型的载入,
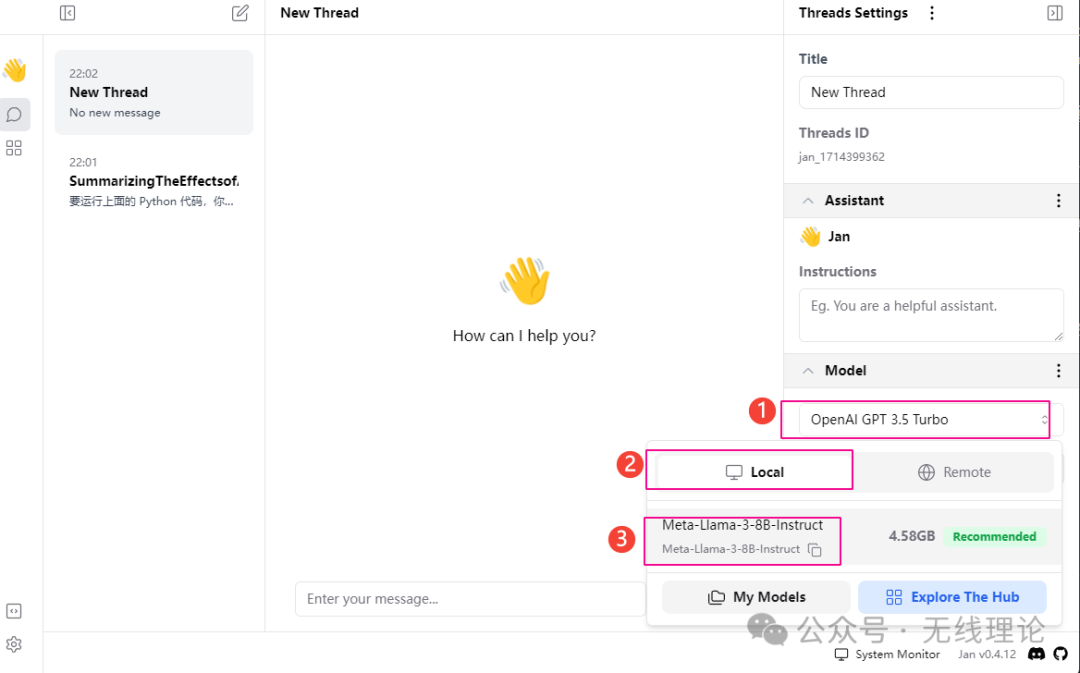
最后就是与大模型的正常聊天了
第三种方式,使用GPT4All来部署运行llama3
GPT4All是一个免费开源的大型语言模型项目,用户可以在本地部署,不仅支持GPU,也可以在CPU上运行,支持离线使用。这使得更多的用户能够接触和使用LLM模型,从而推动人工智能技术的发展。

GPT4All的下载地址如下
windows电脑下载链接:``https://github.com/nomic-ai/gpt4all/releases/download/v2.7.4/gpt4all-installer-win64-v2.7.4.exe``Mac电脑下载链接:``https://github.com/nomic-ai/gpt4all/releases/download/v2.7.4/gpt4all-installer-darwin-v2.7.4.dmg
- 1
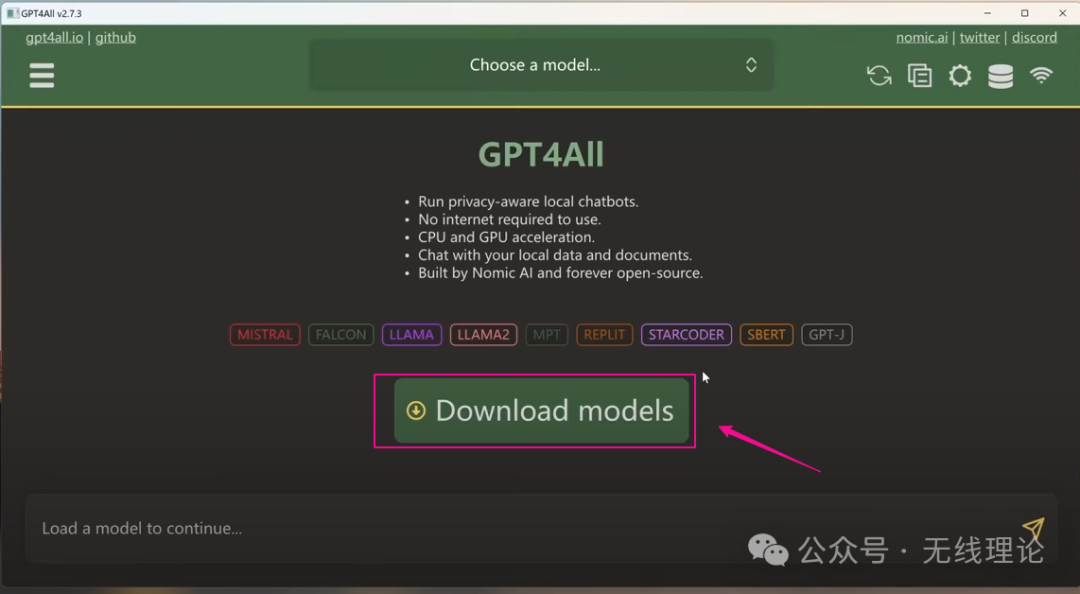
在完成GPT4All应用的安装后,点击Download按钮,进入下载页面:
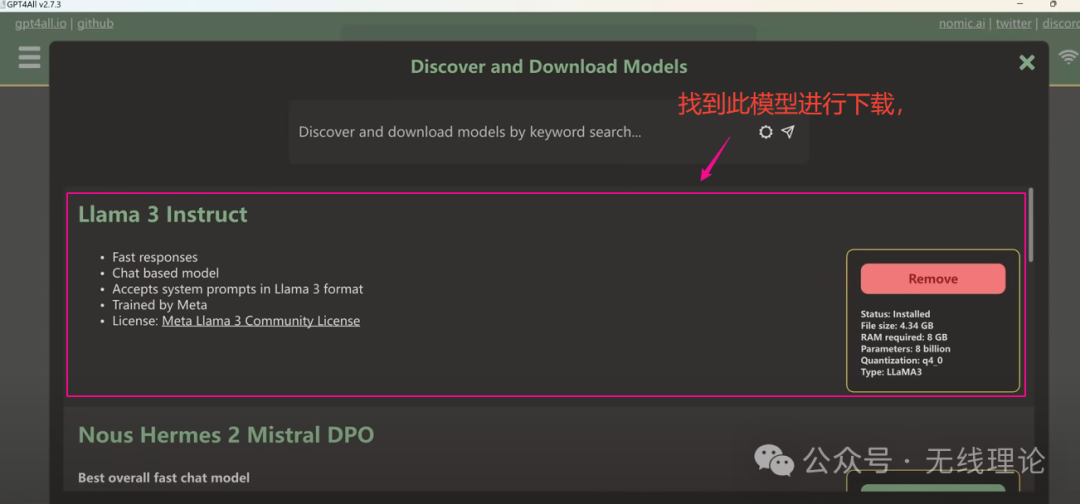
找到Llama3模型并将其下载到本地
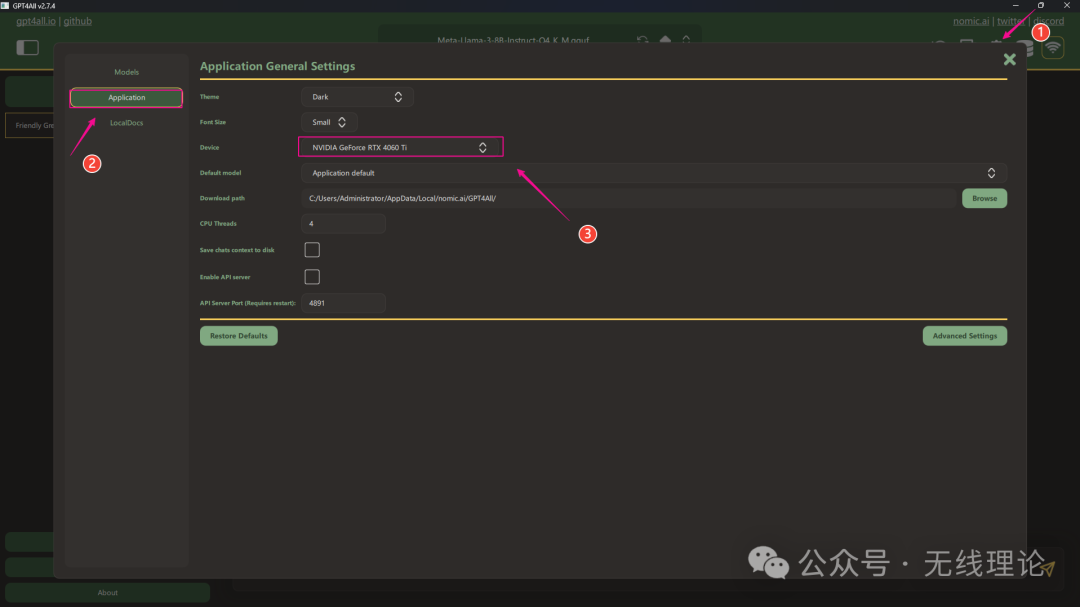
同样,如果在下载过程中因为网络问题而无法下载成功,那么方式2中用到的llama3模型在这里同样可以适用,因为jan和GPT4All都用的是同一种类型的模型。如果你的设备拥有GPU,那么你可以设置GPU为运行项目的首选项,这样以后你就能更加高效的运行大模型了,具体做法如下所示:
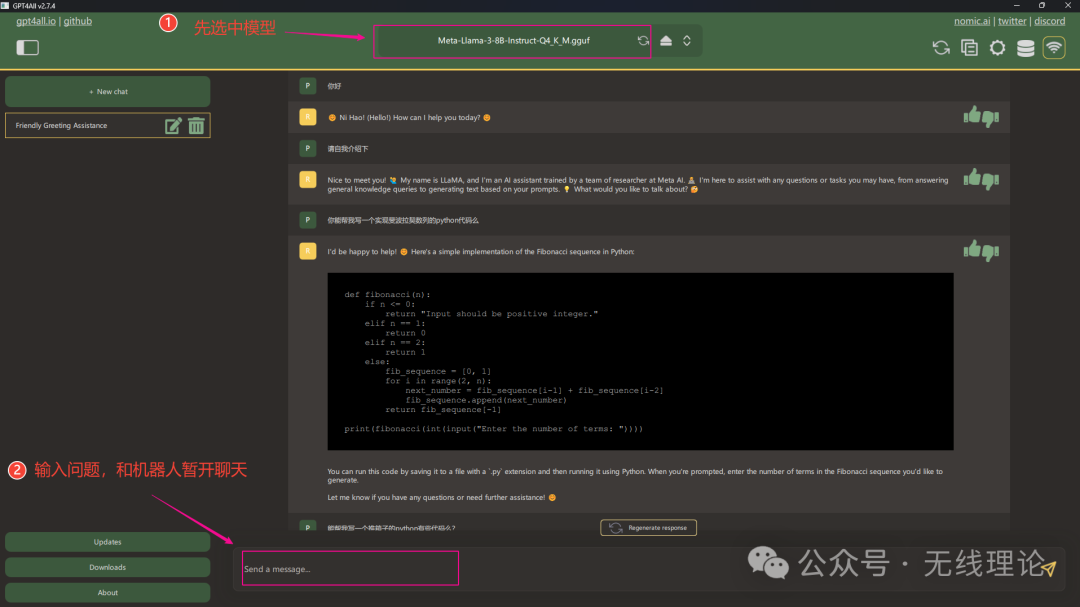
最后就是选中聊天模型,并展开聊天了,
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/732333
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

