
- 1python异步方法asyncio的使用3_task.print_stack()
- 2机器学习和统计学的区别?
- 3vue中文本超出显示省略号最优方案_vue text省略
- 4Mysqldump参数解析大全_mysqldump解析字段
- 5php中函数禁用绕过的原理与利用_ini_set()绕过
- 6springboot集成邮件功能_springboot集成mail
- 7quill编辑器自定义音频、视频、行内style样式(字符边框、首行缩进)_react-quill设置自定义样式
- 8前端项目上线后,浏览器缓存未刷新问题_前端静态页面缓存问题怎么解决
- 9【Unity3d】如何解决在开发中添加了新场景后,需要手工维护BuildSettings中场景列表的问题_unity创建新场景,原场景不见了
- 10【YOLOv8改进-论文笔记】SCConv :即插即用的空间和通道重建卷积
深度学习| 用global average pooling 代替最后的全连接层_resnet采用全局平均池化(global average pooling)技术替代全连接层
赞
踩
最近在看关于cifar10 的分类的识别的文章
在看all convolution network 中看到中用到一个global average pooling
下面就介绍一下global average pooling
这个概念出自于 network in network
主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量
进行softmax中进行计算。
举个例子
假如,最后的一层的数据是10个6*6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,
这样10 个特征图就会输出10个数据点,将这些数据点组成一个1*10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了
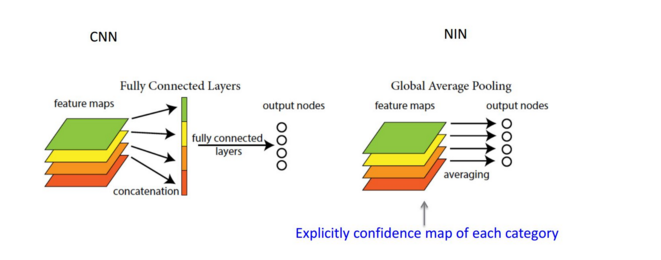
上图是从PPT中截取的对比全连接与全局均值池化的差异
原文中介绍这样做主要是进行全连接的替换,减少参数的数量,这样计算的话,global average pooling层是没有数据参数的
这也与network in network 有关,其文章中提出了一种非线性的 类似卷积核的mlpconv的感知器的方法,计算图像的分块的值
可以得到空间的效果,这样就取代了pooling的作用,但是会引入一些参数,但是为了平衡,作者提出了使用global average pooling
下面是network in network 中的摘取

下图是是一个基于MLP的局部计算,最后使用global average pooling 的network in network 的结构图
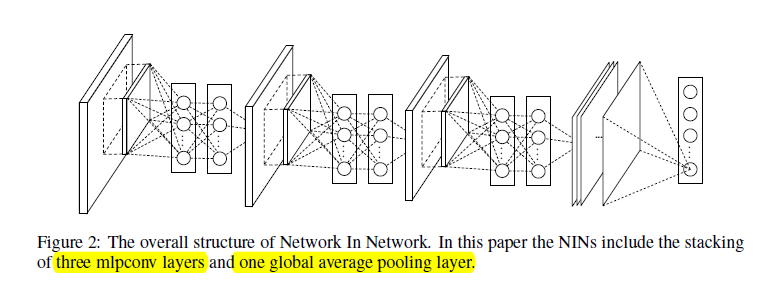
NOTE.
GAP和GMP都是将参数的数量进行缩减,这样一方面可以避免过拟合,另一方面这也更符合CNN的工作结构,把每个feature map和类别输出进行了关联,而不是feature map的unit直接和类别输出进行关联。
差别在于,GMP只取每个feature map中的最重要的region,这样会导致,一个feature map中哪怕只有一个region是和某个类相关的,这个feature map都会对最终的预测产生很大的影响。而GAP则是每个region都进行了考虑,这样可以保证不会被一两个很特殊的region干扰。这篇论文有更详细的说明。
参考:https://blog.csdn.net/oppo62258801/article/details/77930246

