- 1修改el-select 右侧图标样式和边框颜色_element ui选择框修改右边箭头
- 2Django实战【一】—CRM需求分析_django crm
- 3Spring Boot统计一个Bean中方法的调用次数_spring bean 监控bean 调用次数
- 4TCP 和 UDP 区别_22.简述udp和tcp的区别:
- 5【Larry】英语学习笔记语法篇——换一种方式理解词性
- 6项目中的java文件没有在WEB-INF\classes中生成class文件_web-inf下面没有对应的java文件怎么办
- 7使用yolov8进行文本行检测_yolov8文本检测
- 8Codeforces Beta Round 91 (Div. 2 Only) A. Lucky Division
- 9bat脚本输出中文为乱码怎么解决
- 102024年 前端JavaScript入门到精通 第一天
论文精读:InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
赞
踩
读前先问
- 大方向的任务是什么?Task
视觉基座模型
- 这个方向有什么问题?是什么类型的问题?Type
还没有基于CNN的大模型
- 为什么会有这个问题?Why
CNN不具有长距离依赖性和自适应空间聚合能力
- 作者是怎么解决这个问题的?How
改进了DCNv2
- 怎么验证解决方案是否有效?
一方面是模型做大之后效果怎么样,另一方面关注是否解决了长距离依赖性和自适应空间聚合能力。
- 实验结果怎么样?What(重点关注有没有解决问题,而不是效果有多好)
论文精读
引言
ViTs虽然通过大量的参数学习大量的数据在很多任务上都超过了CNNs,但是作者认为,如果基于CNN的模型,也拥有类似的操作和架构设计,同等的参数和大量的数据,也能达到类似ViTs的效果,甚至做的更好。
CNNs与ViTs的区别:
- 在算子层面,ViTs的多头自注意力拥有长距离依赖性和自适应空间聚合性,可以从海量数据中学习到比CNNs更强大和更健壮的表示;
- ViTs还包括一系列标准CNNs不包含的高级组件,如层归一化(LN)、前馈神经网络(FFN)和GELU等。
本文设计了一个基于CNN的视觉基座模型——InternImage,可以有效的拓展到大量参数和数据上,以3×3窗口的动态稀疏卷积为核心,并且结合transformers中的一系列设计。
本文的主要贡献如下:
- 提出了一种基于大规模CNN的视觉基础模型——InternImage,是第一个有效扩展到10亿参数和4亿训练图像的CNN,实现了与最先进的ViT相当甚至更好的性能;
- 通过改进3×3 DCN算子引入长距离依赖和自适应空间聚合,成功地将CNNs扩展到大模型场景;
- 在图像分类、目标检测、实例和语义分割等任务上与基于Transformer的模型进行了充分的对比。
方法
可变形卷积
传统卷积跟多头自注意力的对比:
- 长距离依赖。基于CNN的模型不能像ViTs一样获取长距离的依赖,这限制了其性能。
- 自适应空间聚合。传统卷积具有高度归纳性,虽然可以让模型收敛更快,需要的训练数据更少,但是限制了CNNs从大规模数据中学习更一般更鲁棒的模式。
DCNv2:
(这一步作者分析了DCNv2的一些性质,相比于传统卷积,DCNv2具有长距离依赖性和自适应空间聚合能力。)
DCNv2的公式: y ( p 0 ) = ∑ k = 1 K w k m k x ( p 0 + p k + Δ p k ) \mathbf{y}\left(p_{0}\right)=\sum_{k=1}^{K} \mathbf{w}_{k} \mathbf{m}_{k} \mathbf{x}\left(p_{0}+p_{k}+\Delta p_{k}\right) y(p0)=∑k=1Kwkmkx(p0+pk+Δpk),其中 x ∈ R C × H × W \mathbf{x} \in \mathbb{R}^{C \times H \times W} x∈RC×H×W代表输入, p 0 p_0 p0代表当前像素, K K K表示采样点的总数, k k k则用于遍历所有采样点。 w k ∈ R C × C \mathbf{w_k} \in \mathbb{R}^{C \times C} wk∈RC×C表示对第k个采样点的投影权重, m k ∈ R \mathbf{m_k} \in \mathbb{R} mk∈R表示对第k个采样点的调制标量,通过Sigmoid函数进行标准化。 p k p_{k} pk表示从预定义网格采样( { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 0 , + 1 ) , … , ( + 1 , + 1 ) } \{(-1,-1),(-1,0), \ldots,(0,+1), \ldots,(+1,+1)\} {(−1,−1),(−1,0),…,(0,+1),…,(+1,+1)})中的第k个位置, Δ p k \Delta p_k Δpk是第k个网格采样位置对应的偏移量。
针对长距离依赖问题,DCNv2的采样偏移 Δ p k \Delta p_k Δpk可以灵活获得长/短距离特征。对于自适应空间聚合问题, ∗ ∗ Δ p k **\Delta p_k ∗∗Δpk和 m k \mathbf{m}_k mk都是可学习的,并且并且受输入 x x x的限制**。
改进DCNv2:
(这一步主要是作者怎么基于DCNv2进行改进,集成了MHSA的一些组件,提出了DCNv3。)
- 共享权重。传统的DCNv2拥有独立的线性映射权重,因此其参数和内存复杂度与采样点总数呈线性关系,这在大模型中大大限制了其效率。为了解决这个问题,作者借鉴了可分离卷积的思想,将原始卷积权重 w k \mathbf{w_k} wk拆分为深度和点方向两部分,其中深度部分由原始位置感知调制标量 m k \mathbf{m_k} mk负责,而点方向部分为采样点之间共享权重 w \mathbf{w} w。
- mulit-group机制。将空间聚合过程拆分为G个组,每个组具有单独的采样偏移 Δ p g k \Delta p_{gk} Δpgk和 m g k \mathbf{m_{gk}} mgk,因此单个卷积层上的不同组可以具有不同的空间聚合模式,从达到类似多头的效果。
- 沿采样点归一化。原始DCNv2中的调制标量采用Sigmoid函数进行逐元素归一化。每个调制标量都在[0、1]范围内,所有样本点的调制标量之和并不稳定,在0~K之间变化。在使用大规模参数和数据进行训练时,会导致DCNv2层出现不稳定的梯度。为了缓解不稳定问题,我们将沿样本点的逐元素Sigmoid归一化改为Softmax归一化。通过这种方式,将调制标量之和约束为1,使得不同尺度下模型的训练过程更加稳定。
DCNv3公式: y ( p 0 ) = ∑ g = 1 G ∑ k = 1 K w g m g k x g ( p 0 + p k + Δ p g k ) \mathbf{y}\left(p_{0}\right)=\sum_{g=1}^{G} \sum_{k=1}^{K} \mathbf{w}_{g} \mathbf{m}_{g k} \mathbf{x}_{g}\left(p_{0}+p_{k}+\Delta p_{g k}\right) y(p0)=∑g=1G∑k=1Kwgmgkxg(p0+pk+Δpgk),其中G表示分组聚合的数量,对于第g个组, w g ∈ R C × C ′ \mathbf{w}_{g} \in \mathbb{R}^{C \times C'} wg∈RC×C′表示该组的位置无关映射权重,其中 C ′ = C G C'=\frac{C}{G} C′=GC表示组维度。 m g k ∈ R \mathbf{m_{gk}}\in \mathbb{R} mgk∈R表示第g组第k个采样点的调制标量,用沿维度K的Softmax函数归一化。 x g ∈ R C ′ × H × W \mathbf{x}_{g} \in \mathbb{R}^{C^{\prime} \times H \times W} xg∈RC′×H×W表示切片的输入特征图。 Δ p g k \Delta p_{g k} Δpgk为第g组网格采样位置 p k p_{k} pk对应的偏移量。
DCNv3有以下3个优点:
- 弥补了传统卷积的长距离依赖和自适应空间聚合能力;
- 与MHSA和可变形注意力相比,还具有传统卷积的归纳偏向性;
- 基于稀疏采样,只需要一个3×3的核来学习长距离依赖,具有更高的计算和内存效率。
InternImage 模型
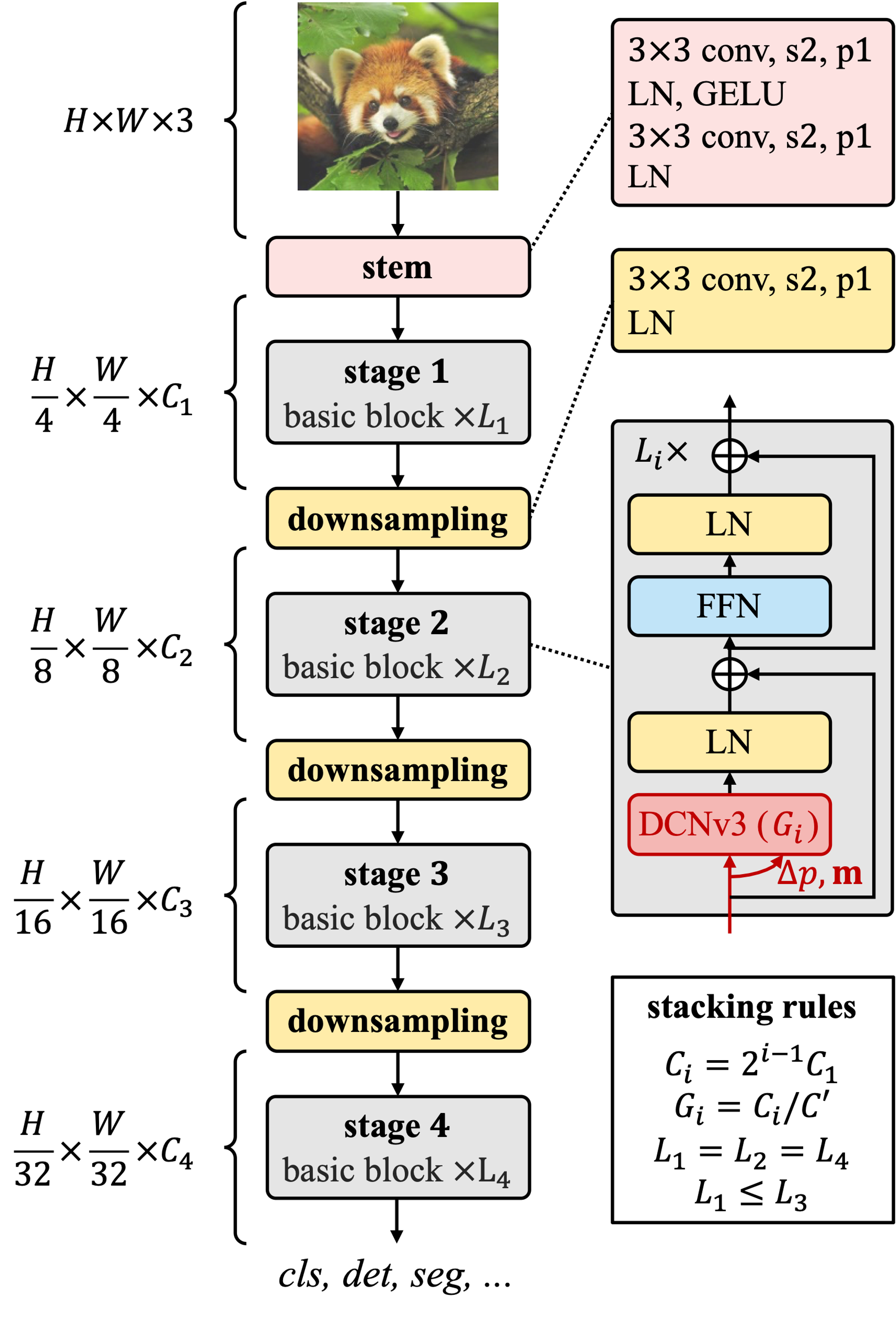
基础块。核心算子为DCNv3,通过一个可分离卷积(一个3×3的深度卷积后接一个线性投影)传递输入特征x来预测采样偏移量和调制标量。采用post-normalization,并遵循跟Transformer相同的设计。
Stem和下采样层。为了获得层次化的特征图,使用Stem层和下采样层将特征图调整到不同的尺度。Stem层放在了第一阶段之前,由2个卷积层、2个LN层和1个GELU层组成,可以让输入分辨率降低4倍。下采样层由步长为2,填充为1的3×3卷积层构成,后接一个LN层。
堆叠规则。InternImage包含以下超参数:
- C i C_i Ci:第i个阶段的通道数;
- G i G_i Gi:第i个阶段的DCNv3的分组数;
- L i L_i Li:第i个阶段的基础块数。
4个阶段的话,就有12个超参数要搜索。为了压缩搜索空间,作者又设计了几条规则: C i = 2 i − 1 C 1 G i = C i / C ′ L 1 = L 2 = L 4 ≤ L 3 Ci=2i−1C1Gi=Ci/C′L1=L2=L4≤L3
缩放规则。考虑两个缩放维度:深度 D ( i . e . , 3 L 1 + L 3 ) D (i.e., 3L_1+L_3) D(i.e.,3L1+L3)和宽度 C 1 C_1 C1,用 α \alpha α、 β \beta β和一个复合因子 ϕ \phi ϕ对这两个维度进行缩放。缩放规则: D ′ = α ϕ D D^{\prime}=\alpha^{\phi} D D′=αϕD和 C 1 ′ = β ϕ C 1 C_{1}^{\prime}=\beta^{\phi} C_{1} C1′=βϕC1,其中 α ≥ 1 , β ≥ 1 , α β 1.99 ≈ 2 \alpha \geq 1, \beta \geq 1 , \alpha \beta^{1.99} \approx 2 α≥1,β≥1,αβ1.99≈2,1.99是InternImage特有的,通过将模型宽度加倍并保持深度不变来计算。通过实验,最优参数是 α = 1.09 \alpha = 1.09 α=1.09和 β = 1.36 \beta = 1.36 β=1.36。
实验
(就简单看了一下图像分类任务)