
- 1一个简单的jquery 事件订阅_jquery $.subscribe
- 2okHttp3的原理剖析
- 3Codeforces Round 911 (Div. 2) E题
- 4飞腾FT-2000/4处理器+复旦微FPGA+国产操作系统解决方案(2)
- 5RocketMQ教程-(5)-功能特性-消费进度管理_rocketmq 重置消费点位干嘛的
- 6PyTorch 1.0 基础教程(5):多GPU数据并行化加速_cannot import name 'load_model_on_gpus' from 'util
- 7PyTorch的ONNX结合MNIST手写数字数据集的应用(.pth和.onnx的转换与onnx运行时)_invalid_argument : invalid feed input name:input
- 8草稿solr_"startup\": \"lazy\", \"name\": \"velocity\", \"cl
- 9如何安装wsl以及安装时遇到的一些问题_适用于 linux 的 windows 子系统没有已安装的分发版。 可以通过访问 microsoft
- 10Python自学笔记6:实操案例三(十进制转换二、八、十六进制),手机充值,计算能量消耗,预测未来子女身高_python父母身高预测孩子身高代码
YOLOv5、YOLOv8改进:gnconv 门控递归卷积
赞
踩
1.简介
论文地址:https://arxiv.org/abs/2207.14284
代码地址:https://github.com/raoyongming/HorNet
视觉Transformer的最新进展表明,在基于点积自注意力的新空间建模机制驱动的各种任务中取得了巨大成功。在本文中,作者证明了视觉Transformer背后的关键成分,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。作者提出了递归门卷积(g n Conv),它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。g nConv可以作为一个即插即用模块来改进各种视觉Transformer和基于卷积的模型。基于该操作,作者构建了一个新的通用视觉主干族,名为HorNet。在ImageNet分类、COCO对象检测和ADE20K语义分割方面的大量实验表明,HorNet在总体架构和训练配置相似的情况下,优于Swin Transformers和ConvNeXt。HorNet还显示出良好的可扩展性,以获得更多的训练数据和更大的模型尺寸。除了在视觉编码器中的有效性外,作者还表明g n Conv可以应用于任务特定的解码器,并以较少的计算量持续提高密集预测性能。本文的结果表明,g n Conv可以作为一个新的视觉建模基本模块,有效地结合了视觉Transformer和CNN的优点。
(a)标准卷积运算没有明确考虑空间交互。
●
(b) 动态卷积 [27, 4] 和 SE [25] 引入了动态权重,以通过额外的空间交互来提高卷积的建模能力。
(c) 自注意力操作 通过两个连续的矩阵乘法执行二阶空间交互。
(d) gnConv 使用具有门控卷积和递归设计的高效实现来实现任意阶空间交互。在本文中,作者总结了视觉Transformers成功背后的关键因素是通过自注意力操作实现输入自适应、远程和高阶空间交互的空间建模新方法。虽然之前的工作已经成功地将元架构、输入自适应权重生成策略和视觉Transformers的大范围建模能力迁移到CNN模型,但尚未研究高阶空间交互机制。作者表明,使用基于卷积的框架可以有效地实现所有三个关键要素。作者提出了递归门卷积(g nConv),它与门卷积和递归设计进行高阶空间交互。与简单地模仿自注意力中的成功设计不同,g n Conv有几个额外的优点:1)**效率。**基于卷积的实现避免了自注意力的二次复杂度。在执行空间交互期间逐步增加通道宽度的设计也使能够实现具有有限复杂性的高阶交互;2) 可扩展。将自注意力中的二阶交互扩展到任意阶,以进一步提高建模能力。由于没有对空间卷积的类型进行假设,g n Conv与各种核大小和空间混合策略兼容;3) 平移等变性。g n Conv完全继承了标准卷积的平移等变性,这为主要视觉引入了有益的归纳偏置。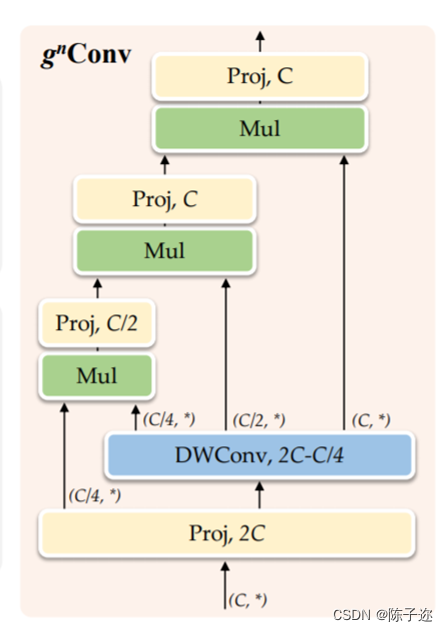
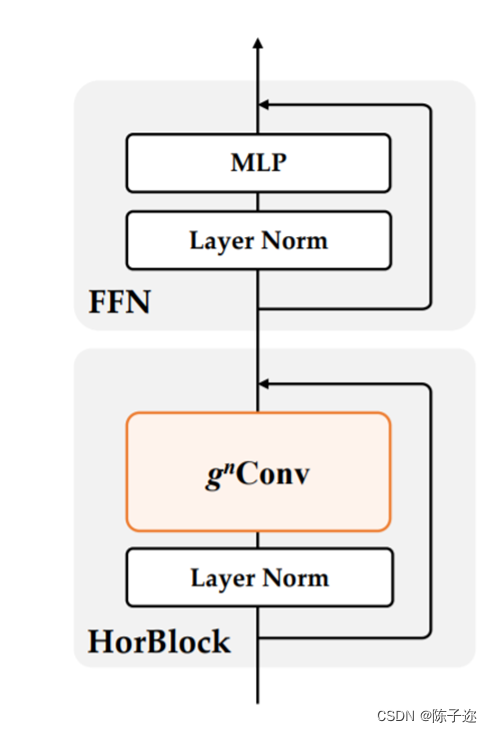
基于g n Conv,作者构建了一个新的通用视觉主干族,名为HorNet。作者在ImageNet分类、COCO对象检测和ADE20K语义分割上进行了大量实验,以验证本文模型的有效性。凭借相同的7×7卷积核/窗口和类似的整体架构和训练配置,HorNet优于Swin和ConvNeXt在不同复杂度的所有任务上都有很大的优势。通过使用全局卷积核大小,可以进一步扩大差距。HorNet还显示出良好的可扩展性,可以扩展到更多的训练数据和更大的模型尺寸,在ImageNet上达到87.7%的top-1精度,在ADE20K val上达到54.6%的mIoU,在COCO val上通过ImageNet-22K预训练达到55.8%的边界框AP。除了在视觉编码器中应用g n Conv外,作者还进一步测试了在任务特定解码器上设计的通用性。通过将g n Conv添加到广泛使用的特征融合模型FPN,作者开发了HorFPN来建模不同层次特征的高阶空间关系。作者观察到,HorFPN还可以以较低的计算成本持续改进各种密集预测模型。结果表明,g n Conv是一种很有前景的视觉建模方法,可以有效地结合视觉Transofrmer和CNN的优点。
2.YOLOv5代码修改
2.1 修改yaml文件
我这边只是提供参考,你可以修改任意位置
- # YOLOAir 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/93971推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

