- 12024年最新数据湖Iceberg、Hudi和Paimon比较_数据湖框架对比_数据湖paimon hudi
- 2ThreadPoolExecutor的execute方法_threadpoolexecutor.execute
- 3vue2.0-axios_vue2调取引axios
- 4mysql数据库切换成kingbase(人大金仓)数据库时遇到的字段不存在问题_kingbase 字段不存在
- 5yum问题解决Cannot find a valid baseurl for repo: base/7/x86_64
- 6centos7安装nvidia 显卡驱动_--kernelsourcedir
- 7git 如何回退单个文件_git回退某一个文件
- 8程序员也需要做需求管理呀~~~
- 9Yearning 开源项目教程
- 10Centos 生产系统替换_腾讯云 centos 7.6 替换方案
【大作业-16】使用YOLOv10快速实现海上红外目标检测_yolov10 红外
赞
踩
使用YOLOv10做红外海洋目标识别
Hi,大家好!这里是肆十二!
视频教程地址:使用YOLOv10做红外海洋目标识别_哔哩哔哩
资源地址:YOLOv10海上红外目标检测+代码+模型+系统界面+教学视频.zip资源-CSDN文库
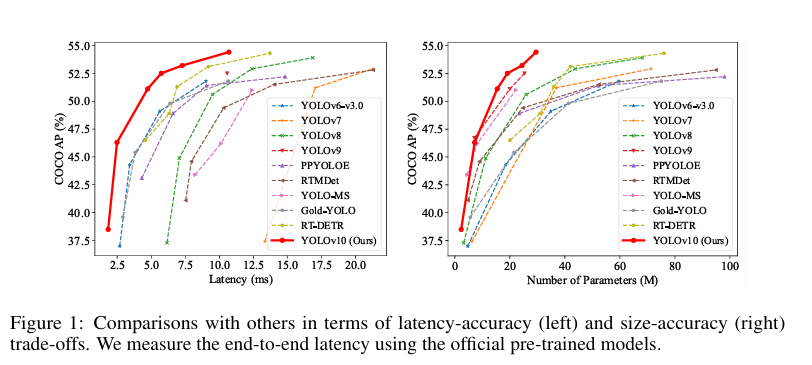
过去几年的时间中,YOLO系列的模型逐渐发展壮大,从原先的YOLOv1到YOLOv10,YOLO系列模型已经迭代了整个10个版本。YOLOv10模型于24年5月份正式提出,对过去YOLOs的结构设计、优化目标和数据增强策略进行了深入的了解和探索,并对YOLO模型中的各个组件进行了rethink,从后处理和模型结构入手进行了新的设计,在速度和精度上进行提升。根据论文中的叙述,在COCO数据集上,我们的YOLOv10-S在相似AP下比RT-DETR-R18快1.8倍,同时参数和浮点运算量(FLOPs)减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟减少了46%,参数减少了25%。
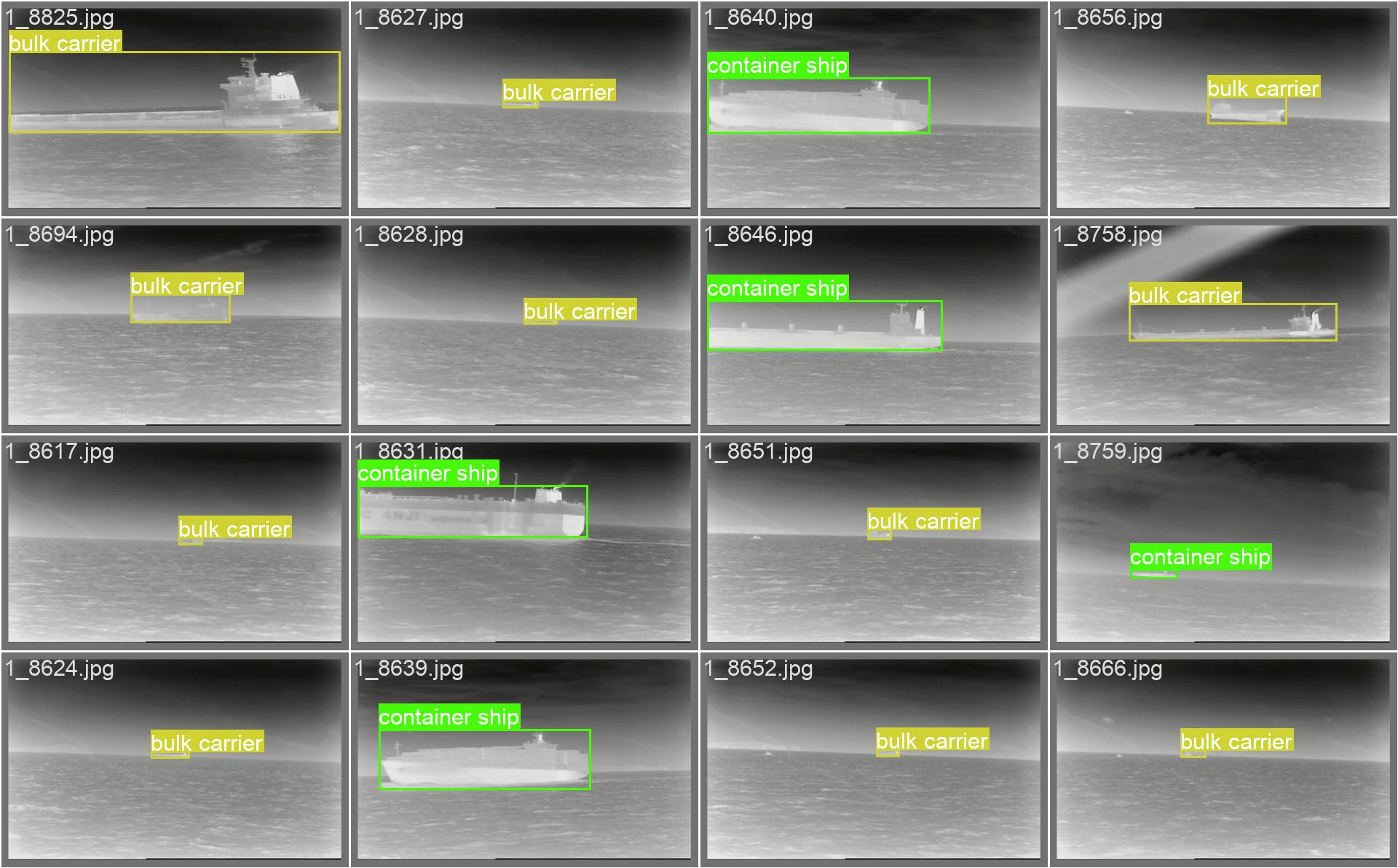
在这里,我们正好有一个红外海洋目标检测的数据集,里面包含了7类海洋目标 ['liner', 'sailboat', 'warship', 'canoe', 'bulk carrier', 'container ship', 'fishing boat'],让我们看看不同版本的YOLO模型在其他数据集上速度和精度的表现如何!
论文概述
背景
实时物体检测旨在以较低的延迟准确预测图像中的物体类别和位置。YOLO 系列在性能和效率之间取得了平衡,因此一直处于这项研究的前沿。然而,对 NMS 的依赖和架构上的低效阻碍了最佳性能的实现。YOLOv10 通过为无 NMS 训练引入一致的双重分配和以效率-准确性为导向的整体模型设计策略,解决了这些问题。
结构设计
YOLOv10 是清华大学研究人员在 UltralyticsPython 清华大学的研究人员在 YOLOv10软件包的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10 在显著降低计算开销的同时实现了最先进的性能。大量实验证明,YOLOv10 在多个模型尺度上实现了卓越的精度-延迟权衡,下面是YOLOV10论文中的结构图。
主干网络的模型构成主要如下。
- 主干网YOLOv10 中的主干网负责特征提取,它使用了增强版的 CSPNet(跨阶段部分网络),以改善梯度流并减少计算冗余。
- 颈部颈部设计用于汇聚不同尺度的特征,并将其传递到头部。它包括 PAN(路径聚合网络)层,可实现有效的多尺度特征融合。
- 一对多头(训练时使用):在训练过程中为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
- 一对一头(推理时使用):在推理过程中为每个对象生成一个最佳预测,无需 NMS,从而减少延迟并提高效率。
主要优势
- 无 NMS 训练:利用一致的双重分配来消除对 NMS 的需求,从而减少推理延迟。
- 整体模型设计:从效率和准确性的角度全面优化各种组件,包括轻量级分类头、空间通道去耦向下采样和等级引导块设计。
- 增强的模型功能:纳入大核卷积和部分自注意模块,在不增加大量计算成本的情况下提高性能。
主要方法
YOLOv10 采用双重标签分配,在训练过程中将一对多和一对一策略结合起来,以确保丰富的监督和高效的端到端部署。一致匹配度量使两种策略之间的监督保持一致,从而提高了推理过程中的预测质量。
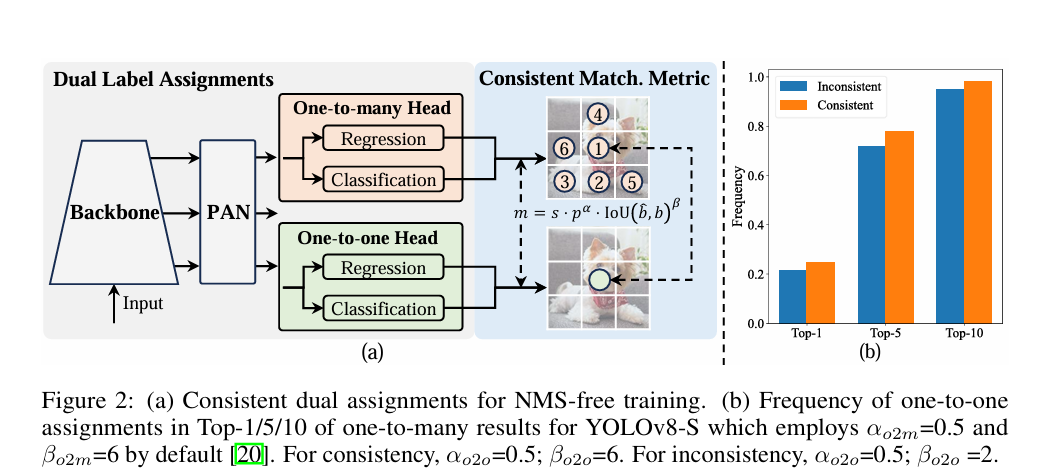
首先作者指出YOLO系列的模型为每个实例分配了多个阳性的样本,在一对多的匹配策略中会产生非常多的丰富的监督信号,但是他比较依赖NMS后处理,这会导致部署推理效率的不理想。作者在这里提出了具有双标签分配和一致性匹配度量的无NMS训练策略,可以提高效率和性能。
首先是双标签的分配策略,采用一对一匹配的时候只对一个实例分配一个预测结果,可以避免NMS的后处理,但是这会导致弱监督,但是这个缺点可以通过一对多的分配来进行弥补。那这样,方法就来了,就和在语义分割任务重,通过都会添加一个辅助头来提升模型对低尺度特征的捕捉,这里将两个分配方式结合起来一起使用。在原先的模型基础上,引入一个一对一的头部,训练的时候两个头部共同优化,但是在检测的过程中呢,抛弃掉一对多的头部,只保留一对一的头部进行预测。如下图所示,是NMS的示意图,首先先通过网络生成一堆候选框,然后通过分类网络为每个候选框附上类别,最终通过NMS算法,保留概率最大的那个锚点框,这个过程在物体比较多的时候计算时间会非常长,那通过一对一的头部,相当省略掉了中间的两个步骤,直接进行一对一的匹配,训练的时候两个策略同时存在,推理的时候去掉一对多的过程。

这里我也给出NMS的处理过程,感兴趣的小伙伴可以了解一下。
NMS(非极大值抑制,Non-Maximum Suppression)是目标检测算法中的一个重要步骤,用于抑制重叠度较高的检测框,以确保每个目标只被检测一次。以下是NMS的详细过程:
- 排序检测框:
- 根据所有检测框的置信度(或分类概率)进行排序,从高到低。
- 选择最高置信度的检测框:
- 从排序后的检测框列表中,选择置信度最高的检测框作为当前处理的检测框。
- 计算IoU并抑制重叠检测框:
- 计算当前处理检测框与其他所有检测框的交并比(IoU,Intersection over Union)。
- 如果某个检测框与当前处理检测框的IoU超过预设的阈值(如0.5),则将该检测框从列表中移除或抑制,因为它与当前处理检测框重叠度较高,可能是检测到的同一个目标。
- 重复处理直至结束:
- 重复步骤2和3,每次从未被抑制的检测框中选择置信度最高的一个,并抑制与其重叠度高的其他检测框。
- 这个过程一直持续到没有更多的检测框需要处理为止。
- 输出结果:
- 最终留下的未被抑制的检测框,就是NMS算法的输出结果,这些检测框代表了算法认为在图像中检测到的不同目标。
为了更好的实现上面的策略,作者还为两个头部提出了统一的匹配度量,定义如下。
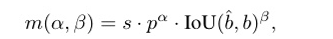
其中alpha和beta是两个重要的超参数,分别表示分类任务和位置的回归任务,b_hat和b表示的是预测和实例的边界框,那p表示的就是分类的分数,s表示预测的锚点是否在实例中。也就是你的IOU越大,你的分类分数越高,你的匹配程度就越高。
其中o2o表示的是one to one也就是一对一,o2m表示的是one2many表示的是一对多,两个分支之间的差距则可以表示为下面的公式,前面是一对一,后面是一对多。其中 t表示的是一对一和一对多的匹配分数。作者在论文的附录部分给出了这里的数学证明,有兴趣的小伙伴可以看论文最后的数学证明。
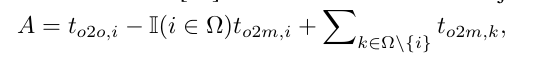
-
速度方面
-
轻量级分类头:通过使用深度可分离卷积,减少分类头的计算开销。
分类的头部中使用了可分离的卷积,简单滴减少了分类头部的开销,在分类头部使用进行可分离卷积的使用主要是考虑到分类的头部参数量是回归鬼头的2.5倍。
-
空间通道解耦向下采样:将空间缩减与信道调制解耦,最大限度地减少信息损失和计算成本。
这里的设计就是细节上设计了,传统的YOLO为了减少下采样的过程呢,通常使用步长为2的3×3的卷积,同时时间空间和通道上的下采样,这样就计算复杂度比较高。这里,作者将两个操作分开来做,先使用点装卷积完成通道的减少,然后使用深度卷积完成空间的下采样,可以保证参数量的减少。
-
梯级引导程序块设计:根据固有阶段冗余调整模块设计,确保参数的最佳利用。
接着作者认为YOLO在所有的阶段都使用的相同的基本快,这种同质设计将会带来比较多的冗余,这里作者同样使用数学证明了每个阶段的冗余度为2。所以作者提出了CIB的模块,也就是DW卷积构成的模块,可以实现自适应的经凑块的设计,不影响性能的情况下实现更高的效率。
-
-
精度方面
-
大核卷积扩大感受野,增强特征提取能力。
大的卷积核可以扩大模型的感受野并且可以增强模型的能力,但是对于小物体的检测和IO的开销不利。所以作者为了避开大卷积的劣势,在深度的阶段给CIB使用大的卷积核,将3×3的卷积核增加到7×7,并且采用结构重参数化的技术引入DW卷积缓解优化的问题。并且作者提到,模型越大,感受野越大,所以只在小模型,比如n或者s模型中使用了大的卷积核。
-
部分自我关注(PSA):纳入自我关注模块,以最小的开销改进全局表征学习。
这里就是使用Transformer的模块了,Transformer的模块具有卓越的全局建模能力,但是会有带来比较高的内存占用,为了解决这个问题,作者还是非常善用1×1卷积,通过1×1的卷积分为两个部分,将其中的一部分输入多头的自注意力中,另一部分输入到前馈网络FFn中,最后使用1×1的卷积将其进行连接和融合,增强模型能力的同时,提高性能。
-
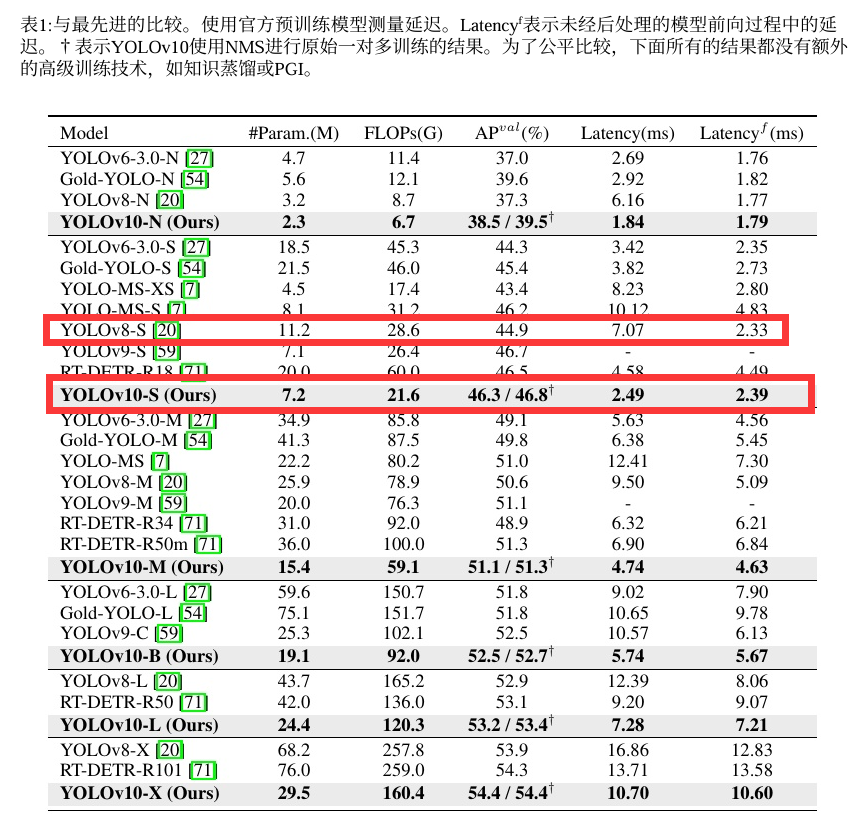
最后放一下论文中给出的对比图,从图中可以看出,在coco数据集中,精度和速度yolov10均是最优。
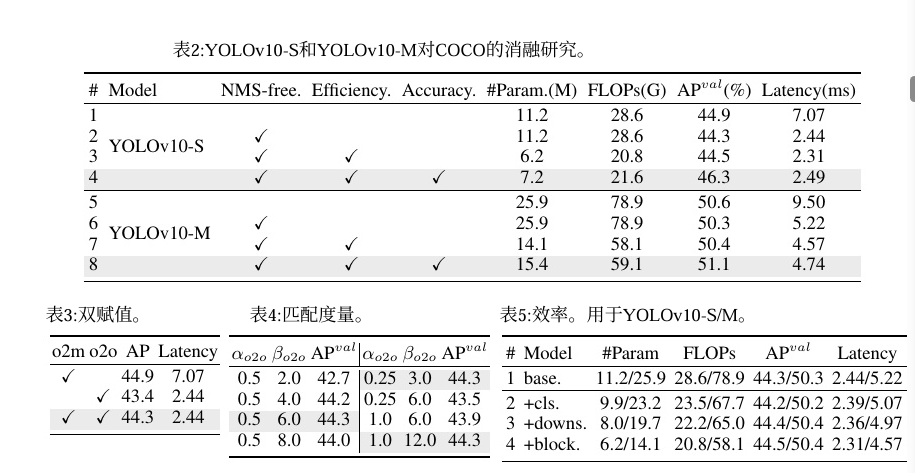
最后还有一些消融实验的结果供大家进行参考。
核心代码
这里面放一些关键的代码,包括损失函数的实现和论文中提到的几个模块的实现。
-
CIB模块和PSA模块
class CIB(nn.Module): """Standard bottleneck.""" def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False): """Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and expansion. """ super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = nn.Sequential( Conv(c1, c1, 3, g=c1), Conv(c1, 2 * c_, 1), Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_), Conv(2 * c_, c2, 1), Conv(c2, c2, 3, g=c2), ) self.add = shortcut and c1 == c2 def forward(self, x): """'forward()' applies the YOLO FPN to input data.""" return x + self.cv1(x) if self.add else self.cv1(x) class C2fCIB(C2f): """Faster Implementation of CSP Bottleneck with 2 convolutions.""" def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5): """Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups, expansion. """ super().__init__(c1, c2, n, shortcut, g, e) self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n)) class Attention(nn.Module): def __init__(self, dim, num_heads=8, attn_ratio=0.5): super().__init__() self.num_heads = num_heads self.head_dim = dim // num_heads self.key_dim = int(self.head_dim * attn_ratio) self.scale = self.key_dim ** -0.5 nh_kd = nh_kd = self.key_dim * num_heads h = dim + nh_kd * 2 self.qkv = Conv(dim, h, 1, act=False) self.proj = Conv(dim, dim, 1, act=False) self.pe = Conv(dim, dim, 3, 1, g=dim, act=False) def forward(self, x): B, _, H, W = x.shape N = H * W qkv = self.qkv(x) q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2) attn = ( (q.transpose(-2, -1) @ k) * self.scale ) attn = attn.softmax(dim=-1) x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W)) x = self.proj(x) return x class PSA(nn.Module): def __init__(self, c1, c2, e=0.5): super().__init__() assert(c1 == c2) self.c = int(c1 * e) self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv(2 * self.c, c1, 1) self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64) self.ffn = nn.Sequential( Conv(self.c, self.c*2, 1), Conv(self.c*2, self.c, 1, act=False) ) def forward(self, x): a, b = self.cv1(x).split((self.c, self.c), dim=1) b = b + self.attn(b) b = b + self.ffn(b) return self.cv2(torch.cat((a, b), 1)) class SCDown(nn.Module): def __init__(self, c1, c2, k, s): super().__init__() self.cv1 = Conv(c1, c2, 1, 1) self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False) def forward(self, x): return self.cv2(self.cv1(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
-
损失函数
class v10DetectLoss: def __init__(self, model): self.one2many = v8DetectionLoss(model, tal_topk=10) self.one2one = v8DetectionLoss(model, tal_topk=1) def __call__(self, preds, batch): one2many = preds["one2many"] loss_one2many = self.one2many(one2many, batch) one2one = preds["one2one"] loss_one2one = self.one2one(one2one, batch) return loss_one2many[0] + loss_one2one[0], torch.cat((loss_one2many[1], loss_one2one[1]))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
环境配置
老规矩,环境配置之前请先自行熟悉Anaconda和Pycharm的使用:【2024毕设系列】Anaconda和Pycharm如何使用_哔哩哔哩
-
配置国内镜像
conda config --remove-key channels conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --set show_channel_urls yes pip config set global.index-url https://mirror.baidu.com/pypi/simple- 1
- 2
- 3
- 4
- 5
- 6
-
创建和激活虚拟环境
conda create -n yolov10 python==3.8.5 conda acctivate yolov10- 1
- 2

-
安装Pytorch
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本 conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令 conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可- 1
- 2
- 3
-
安装项目所需要的其他依赖库
激活环境之后直接执行下列这个一个指令就完成所有依赖库的安装了,非常之方便
pip install -v -e .- 1
-
执行42-demo.py查看效果
# -*-coding:utf-8 -*- """ #------------------------------- # @Author : 肆十二 # @QQ : 3045834499 可定制毕设 #------------------------------- # @File : 42-demo.py # @Description: 文件描述 # @Software : PyCharm # @Time : 2024/5/26 20:31 #------------------------------- """ from ultralytics import YOLOv10 # Load a pretrained YOLOv10n model model = YOLOv10("../pretrained/yolov10n.pt") # Perform object detection on an image results = model("bus.jpg") # Display the results results[0].show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23


-
配置Pycharm享用代码