
- 1同时使用github和gitlab_guthub和gitlab通用吗
- 2(超详细,全图)VMware kali安装教程_vmware安装kali
- 3手动安装jar包到本地仓库(mvn install)_手动install jar包
- 4Python机器学习、深度学习技术提升气象、海洋、水文领域实践应用_批量处理台风cma数据
- 5猫头虎推荐:LibreChat,免费的开源 ChatGPT 克隆版!_librechat安装
- 6俄罗斯方块 --基于pygame_俄罗斯方块pyqt pygame
- 7SqlServer CDC 变更数据捕获_sql server cdc无法捕获数据
- 8使用Pycharm 连接内网服务器_pycharm不使用密码连接服务器
- 9【原理】也就一个简单的jquery收缩菜单而已_jquery控制面板左右伸缩
- 10android dumpsys 命令,Android Shell命令dumpsys
PaddleOCR 自制模型训练_paddleocr模型训练
赞
踩
一、前言
拿文字识别场景举例:文字识别也是图像领域一个常见问题。然而,对于自然场景图像,首先要定位图像中的文字位置,然后才能进行识别。 所以一般来说,从自然场景图片中进行文字识别,需要包括2个步骤:
- 文字检测:解决的问题是哪里有文字,文字的范围有多少
- 文字识别:对定位好的文字区域进行识别,主要解决的问题是每个文字是什么,将图像中的文字区域进转化为字符信息。
二、训练检测模型
2.1 数据准备
数据集的制作可以通过PPOCRLabel工具完成。 关于PPOCRLabel的使用,可以参考文章《PaddleOCR 标注工具PPOCRLabel的使用》
本节以icdar15数据集为例,介绍如何完成PaddleOCR中文字检测模型的训练、评估与测试。
来到官网:https://rrc.cvc.uab.es/?ch=4&com=downloads可以看到有各个年份比赛的数据集。我们下载的是2015版数据集。
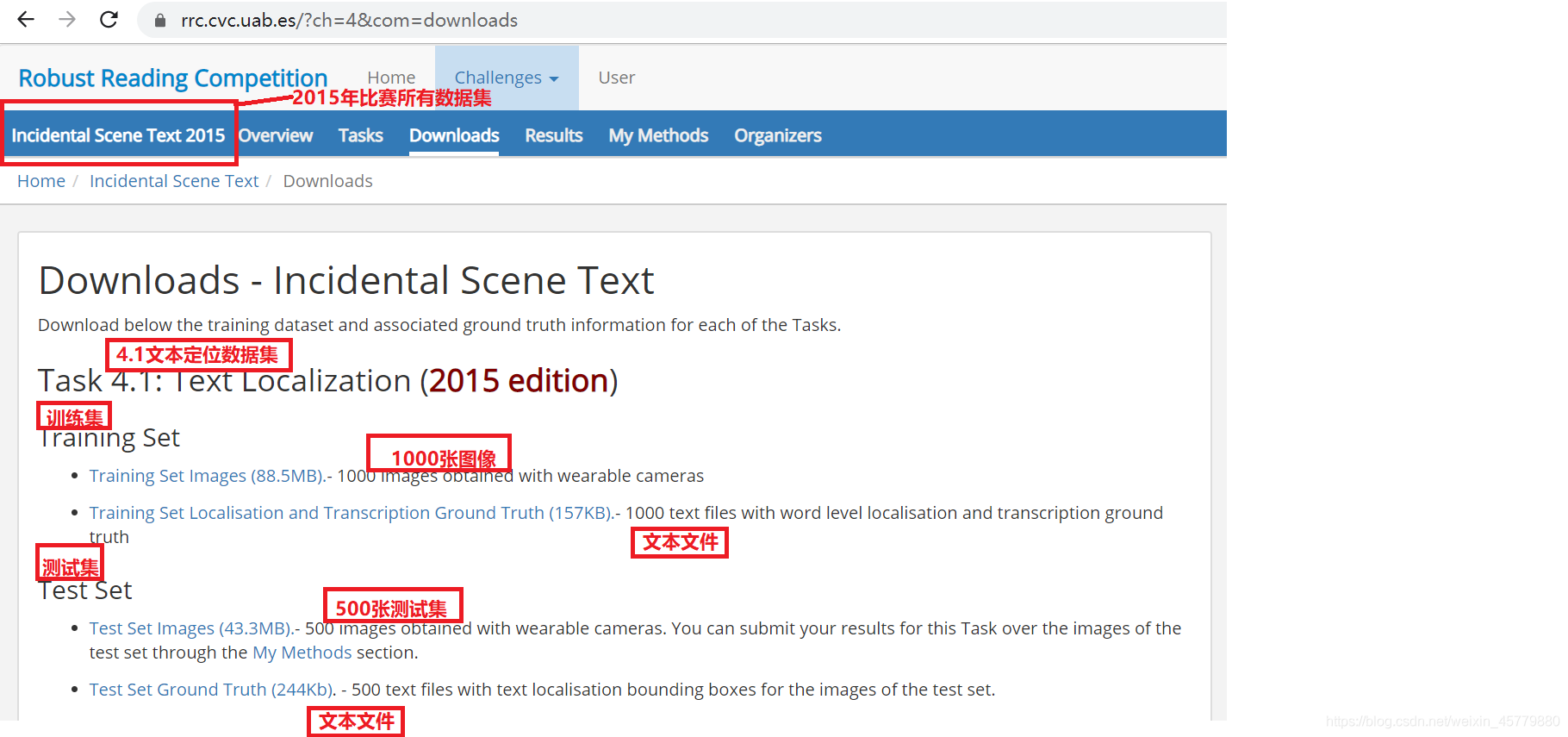
我们已经为您准备好了icdar15的数据集,存放在 ~/data/data34815/icdar2015.tar 中,可以运行如下指令完成数据集解压。
cd ~/data/data34815/ && tar xf icdar2015.tar && mv icdar2015 ~/PaddleOCR/train_data/
- 1
运行上述指令后 ~/train_data/icdar2015/text_localization 有两个文件夹和两个文件,分别是:
~/train_data/icdar2015/text_localization
└─ icdar_c4_train_imgs/ icdar数据集的训练数据
└─ ch4_test_images/ icdar数据集的测试数据
└─ train_icdar2015_label.txt icdar数据集的训练标注
└─ test_icdar2015_label.txt icdar数据集的测试标注
- 1
- 2
- 3
- 4
- 5
2.2 快速启动训练
首先下载pretrain model (预训练模型),PaddleOCR的检测模型目前支持两种backbone,分别是MobileNetV3、ResNet50_vd, 您可以根据需求使用PaddleClas中的模型更换backbone。
- 下载预训练模型
# 下载MobileNetV3的预训练模型
!wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV3_large_x0_5_pretrained.tar
! cd pretrain_models/ && tar xf MobileNetV3_large_x0_5_pretrained.tar
# 下载ResNet50的预训练模型
!wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_vd_ssld_pretrained.tar
! cd pretrain_models/ && tar xf ResNet50_vd_ssld_pretrained.tar
- 1
- 2
- 3
- 4
- 5
- 6
- 训练backbone为MobileNetV3的db算法的检测模型
# 训练backbone为MobileNetV3的db算法的检测模型
!python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.eval_batch_step="[0,2000]"
- 1
- 2
上述指令中,通过
-c选择训练使用configs/det/det_db_mv3.yml配置文件。 有关配置文件的详细解释,请参考/doc目录下的config.md。
您也可以通过-o参数在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001python3 tools/train.py -c configs/det/det_db_mv3.yml -o Optimizer.base_lr=0.0001
- 1
det_mv3_db.yml 文件内容参考:
Global: algorithm: DB use_gpu: true epoch_num: 1200 log_smooth_window: 20 print_batch_step: 2 save_model_dir: ./output/det_db/ save_epoch_step: 200 # evaluation is run every 5000 iterations after the 4000th iteration eval_batch_step: [4000, 5000] train_batch_size_per_card: 16 test_batch_size_per_card: 16 image_shape: [3, 640, 640] reader_yml: ./configs/det/det_db_icdar15_reader.yml pretrain_weights: ./pretrain_models/MobileNetV3_large_x0_5_pretrained/ checkpoints: save_res_path: ./output/det_db/predicts_db.txt save_inference_dir: Architecture: function: ppocr.modeling.architectures.det_model,DetModel Backbone: function: ppocr.modeling.backbones.det_mobilenet_v3,MobileNetV3 scale: 0.5 model_name: large Head: function: ppocr.modeling.heads.det_db_head,DBHead model_name: large k: 50 inner_channels: 96 out_channels: 2 Loss: function: ppocr.modeling.losses.det_db_loss,DBLoss balance_loss: true main_loss_type: DiceLoss alpha: 5 beta: 10 ohem_ratio: 3 Optimizer: function: ppocr.optimizer,AdamDecay base_lr: 0.001 beta1: 0.9 beta2: 0.999 PostProcess: function: ppocr.postprocess.db_postprocess,DBPostProcess thresh: 0.3 box_thresh: 0.7 max_candidates: 1000 unclip_ratio: 2.0

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
2.3 测试检测效果
训练过程中的检测模型保存在./output/det_db/中 ,模型保存的位置通过det_mv3_db.yml配置文件的Global.save_model_dir参数设置。
- 使用训练好的模型测试
单张图像的检测效果:
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o TestReader.infer_img="./doc/imgs_en/img_10.jpg" Global.checkpoints="./output/det_db/best_accuracy"
- 1
- 使用训练好的模型,测试文件夹下
所有图像的检测效果
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o TestReader.infer_img="./doc/imgs_en/" Global.checkpoints="./output/det_db/best_accuracy"
- 1
三、训练识别模型
3.1 数据准备
- 使用自己数据集:
若您希望使用自己的数据进行训练,请参考下文组织您的数据。 - 训练集:
首先请将训练图片放入同一个文件夹(train_images),并用一个txt文件(rec_gt_train.txt)记录图片路径和标签。 - 注意: 默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错
" 图像文件名 图像标注信息 "
train_images/train_0001.jpg 简单可依赖
train_images/train_0002.jpg 用科技让复杂的世界更简单
- 1
- 2
- 3
- 4
最终训练集应有如下文件结构:
|-train_data
|-ic15_data
|- rec_gt_train.txt
|- train
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 测试集
同训练集类似,测试集也需要提供一个包含所有图片的文件夹(test)和一个rec_gt_test.txt,测试集的结构如下所示:
|-train_data
|-ic15_data
|- rec_gt_test.txt
|- test
|- word_001.jpg
|- word_002.jpg
|- word_003.jpg
| ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2 快速启动训练
首先下载pretrain model,PaddleOCR的检测模型目前支持两种backbone,分别是MobileNetV3、ResNet50_vd, 您可以根据需求使用PaddleClas中的模型更换backbone。 本节将以 CRNN 识别模型为例:
- CRNN 识别模型下载
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_mv3_none_bilstm_ctc.tar
cd pretrain_models && tar -xf rec_mv3_none_bilstm_ctc.tar && rm -rf rec_mv3_none_bilstm_ctc.tar
- 1
- 2
- 开始训练
python3 tools/train.py -c configs/rec/rec_icdar15_train.yml
- 1
3.3 测试识别效果
- 测试单张图像的识别结果
python3 tools/infer_rec.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./output/rec_CRNN/best_accuracy Global.infer_img=./doc/imgs_words_en/word_10.png
- 1
- 测试文件夹下所有图像的文字识别效果
python3 tools/infer_rec.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./output/rec_CRNN/best_accuracy Global.infer_img=./doc/imgs_words_en/
- 1

