
- 1手把手教你使用微软Graphrag(调用openai的apikey)(Windows适用)_graphrag.config.errors.apikeymissingerror
- 2微服务应用安全——Security
- 3数据结构——哈夫曼树_哈夫曼树是否唯一
- 42024年最全【python】爬取4K壁纸保存到本地文件夹【附源码】(2),GitHub重磅官宣_4k源代码
- 5使用HBuilderX高效搭建Uni-App微信小程序开发环境_hbuilderx小程序开发
- 6深度学习基础笔记 (6) :注意力机制、Transformer_评分函数sf (scoring function)的作用
- 7【漏洞复现-jupyter_notebook-命令执行】vulfocus/jupyter_notebook-cve_2019_9644_jupyter执行命令行
- 8一篇掌握Elasticsearch7.10集群搭建到实战_org.elasticsearch.client7.10版本
- 9生成Elasticsearch xpack安全认证证书_elasticsearch 生成 客户端访问证书
- 10Redis基础-笔记_redis启动命令
Python车牌识别:从基础到高级的全方位指南_python 车牌识别
赞
踩
车牌识别是计算机视觉领域的一个重要应用,广泛应用于智能交通、停车场管理等领域。本文将从四个部分详细介绍Python车牌识别的基础知识、常用库、实战案例及注意事项,帮助读者从入门到精通Python车牌识别。
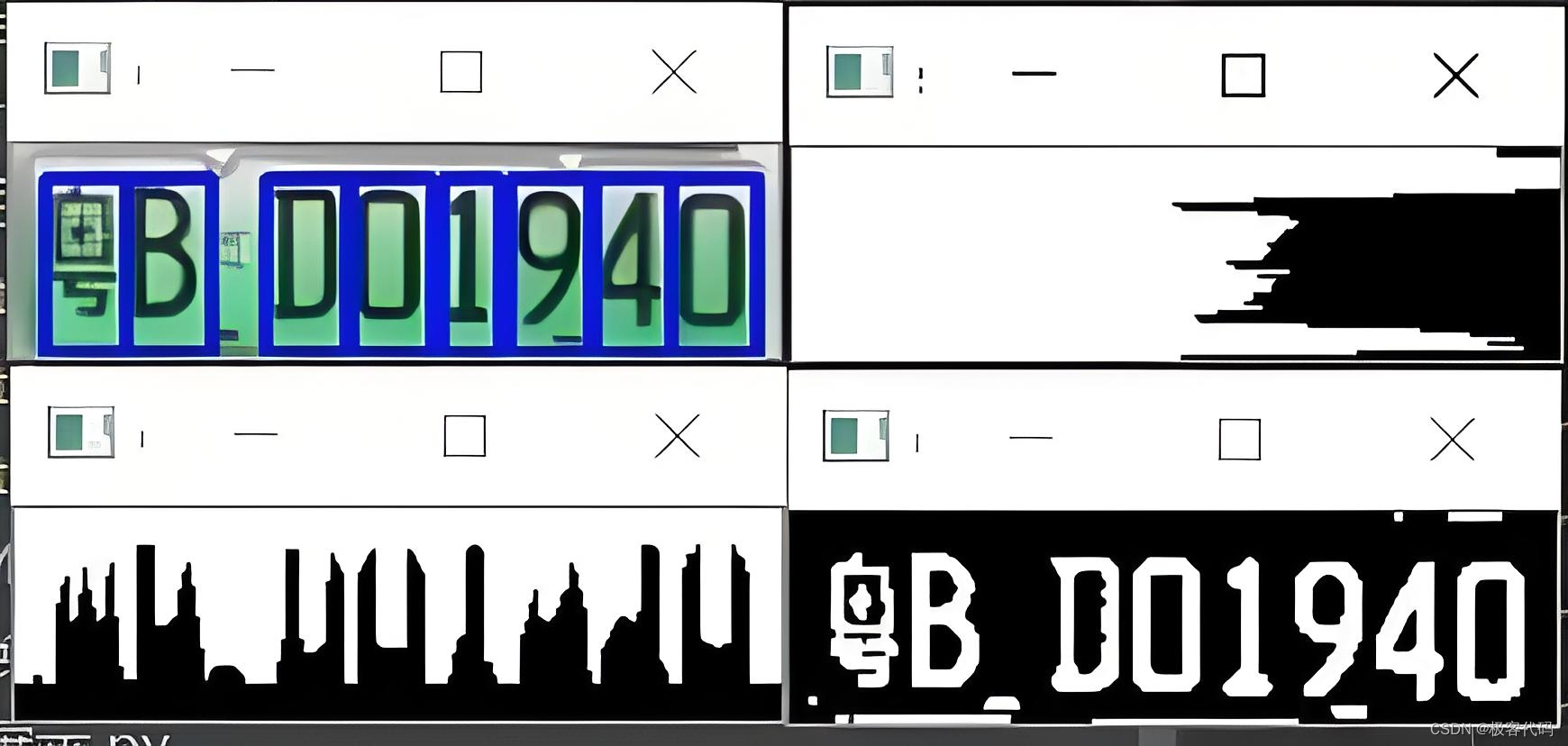
第一部分:Python车牌识别基础
1.1 车牌识别简介
车牌识别是指计算机系统通过分析车牌图像来识别车牌号码的过程。它主要包括以下几个步骤:
- 图像预处理:对输入的图像进行必要的处理,如调整大小、裁剪、去噪等。
- 车牌定位:在图像中定位车牌的位置。
- 车牌分割:将车牌从背景中分割出来。
- 字符识别:识别车牌上的字符,并将其转换为数字或字母。
- 结果输出:输出识别到的车牌号码。
1.2 Python车牌识别常用库
Python有许多用于车牌识别的第三方库,以下是一些常用的库:
- OpenCV:一个开源的计算机视觉库,提供了丰富的图像处理算法和功能。
- Tesseract:一个开源的OCR(光学字符识别)引擎,用于车牌字符识别。
- Plate Recognition:一个用于车牌识别的Python库,基于OpenCV和Tesseract。
1.3 实战案例:车牌识别基础
下面通过一个简单的例子来演示如何使用OpenCV和Tesseract进行车牌识别。
- import cv2
- import pytesseract
-
- # 设置Tesseract的安装路径
- pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
-
- # 加载图像
- image = cv2.imread('car_plate.jpg')
-
- # 转换图像为灰度图像
- gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
-
- # 应用Canny边缘检测
- edges = cv2.Canny(gray_image, 100, 200)
-
- # 显示边缘检测后的图像
- cv2.imshow('Edges', edges)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
-
- # 使用Tesseract进行字符识别
- text = pytesseract.image_to_string(edges, lang='chi_sim')
-
- print(text)

在这个例子中,我们首先使用OpenCV库加载了一个车牌图像,然后将其转换为灰度图像。接着,我们应用了Canny边缘检测来提取车牌的边缘特征。最后,我们使用Tesseract进行字符识别,并打印出识别到的字符。
1.4 注意事项
在进行车牌识别时,需要注意以下原则:
- 图像质量:确保输入的图像质量高,避免噪声和模糊。
- 车牌定位:选择合适的车牌定位方法,如基于颜色、形状等。
- 车牌分割:选择合适的车牌分割方法,如基于边缘检测、形态学操作等。
- 字符识别:选择合适的字符识别方法,如基于OCR、神经网络等。
- 结果输出:将识别到的车牌号码输出到指定格式,如文本文件、数据库等。
通过学习本部分内容,读者应该已经了解了Python车牌识别的基础知识、常用库以及注意事项。在接下来的部分,我们将深入学习Python车牌识别的高级技巧,包括深度学习、卷积神经网络等。我们将通过具体的案例来演示如何使用OpenCV、Tesseract等库进行车牌识别,并介绍一些常用的车牌识别算法和技巧。
第二部分:Python车牌识别高级技巧
2.1 深度学习
深度学习是一种模拟人脑神经网络结构的机器学习方法,可以用于图像识别、语音识别、自然语言处理等领域。在车牌识别中,深度学习通过卷积神经网络(CNN)提取车牌特征,并使用全连接层进行字符识别。
实战案例:使用TensorFlow进行车牌识别
在这个项目中,我们将使用TensorFlow库构建一个简单的卷积神经网络(CNN)来识别车牌中的字符。
- import tensorflow as tf
- from tensorflow.keras.models import Sequential
- from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
- from tensorflow.keras.preprocessing.image import ImageDataGenerator
-
- # 加载数据集
- train_datagen = ImageDataGenerator(rescale=1./255)
- test_datagen = ImageDataGenerator(rescale=1./255)
-
- train_generator = train_datagen.flow_from_directory(
- 'train_data',
- target_size=(64, 64),
- batch_size=32,
- class_mode='categorical')
-
- test_generator = test_datagen.flow_from_directory(
- 'test_data',
- target_size=(64, 64),
- batch_size=32,
- class_mode='categorical')
-
- # 构建模型
- model = Sequential([
- Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
- MaxPooling2D((2, 2)),
- Conv2D(64, (3, 3), activation='relu'),
- MaxPooling2D((2, 2)),
- Conv2D(128, (3, 3), activation='relu'),
- MaxPooling2D((2, 2)),
- Flatten(),
- Dense(512, activation='relu'),
- Dense(10, activation='softmax')
- ])
-
- # 编译模型
- model.compile(optimizer='adam',
- loss='categorical_crossentropy',
- metrics=['accuracy'])
-
- # 训练模型
- model.fit(train_generator, epochs=50, validation_data=test_generator)
-
- # 评估模型
- model.evaluate(test_generator)
在这个例子中,我们首先加载了训练和测试数据集,并对数据进行了预处理。然后,我们构建了一个简单的CNN模型,并使用交叉熵损失函数和Adam优化器对其进行训练。最后,我们评估了模型的性能。
2.2 卷积神经网络(CNN)
卷积神经网络(CNN)是深度学习中的一个重要模型,广泛应用于图像识别、物体检测等。CNN通过卷积层、池化层、全连接层等结构提取车牌特征,并使用softmax层进行字符识别。
代码示例:CNN结构
- from tensorflow.keras.models import Sequential
- from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
-
- # 构建CNN模型
- model = Sequential([
- Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
- MaxPooling2D((2, 2)),
- Conv2D(64, (3, 3), activation='relu'),
- MaxPooling2D((2, 2)),
- Conv2D(128, (3, 3), activation='relu'),
- MaxPooling2D((2, 2)),
- Flatten(),
- Dense(512, activation='relu'),
- Dense(10, activation='softmax')
- ])
在这个例子中,我们构建了一个简单的CNN模型,包括三个卷积层和两个池化层。最后,我们使用全连接层进行字符识别。
通过学习本部分内容,读者应该已经了解了Python车牌识别的高级技巧,包括深度学习和卷积神经网络。
第三部分:Python车牌识别实战项目
在这一部分,我们将通过一些具体的实战项目来应用前面所学到的Python车牌识别知识。这些项目将帮助读者更好地理解如何在实际场景中使用车牌识别技术。
3.1 车牌定位
车牌定位是车牌识别过程中的一个重要步骤,用于在图像中准确地定位车牌的位置。
实战项目:使用OpenCV进行车牌定位
在这个项目中,我们将使用OpenCV库和Haar级联分类器进行车牌定位。
- import cv2
-
- # 加载车牌定位器
- plate_cascade = cv2.CascadeClassifier('haarcascade_russian_plate_number.xml')
-
- # 加载摄像头
- cap = cv2.VideoCapture(0)
-
- while True:
- # 读取摄像头帧
- ret, frame = cap.read()
-
- # 转换帧为灰度图像
- gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
-
- # 检测车牌
- plates = plate_cascade.detectMultiScale(gray, 1.3, 5)
-
- # 在帧上绘制车牌边界框
- for (x, y, w, h) in plates:
- cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
-
- # 显示帧
- cv2.imshow('frame', frame)
-
- # 按'q'退出循环
- if cv2.waitKey(20) & 0xFF == ord('q'):
- break
-
- # 释放摄像头并关闭所有窗口
- cap.release()
- cv2.destroyAllWindows()
在这个项目中,我们首先加载了Haar级联分类器,然后使用摄像头捕获实时帧。接着,我们检测帧中可能的车牌区域,并在帧上绘制车牌边界框。最后,我们显示处理后的帧。
3.2 车牌分割
车牌分割是将车牌从背景中分割出来的过程,以便进行后续的字符识别。
实战项目:使用OpenCV进行车牌分割
在这个项目中,我们将使用OpenCV库和形态学操作进行车牌分割。
- import cv2
- import numpy as np
-
- # 加载摄像头
- cap = cv2.VideoCapture(0)
-
- while True:
- # 读取摄像头帧
- ret, frame = cap.read()
-
- # 转换帧为灰度图像
- gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
-
- # 检测车牌
- plates = plate_cascade.detectMultiScale(gray, 1.3, 5)
-
- # 在帧上绘制车牌边界框
- for (x, y, w, h) in plates:
- # 裁剪车牌区域
- plate_roi = frame[y:y+h, x:x+w]
-
- # 应用形态学操作进行车牌分割
- kernel = np.ones((5, 5), np.uint8)
- opening = cv2.morphologyEx(plate_roi, cv2.MORPH_OPEN, kernel)
-
- # 显示分割后的车牌
- cv2.imshow('plate', opening)
-
- # 按'q'退出循环
- if cv2.waitKey(20) & 0xFF == ord('q'):
- break
-
- # 释放摄像头并关闭所有窗口
- cap.release()
- cv2.destroyAllWindows()
在这个项目中,我们首先使用摄像头捕获实时帧,并使用Haar级联分类器检测车牌区域。然后,我们裁剪车牌区域,并应用形态学操作进行车牌分割。最后,我们显示分割后的车牌。
3.3 字符识别
字符识别是车牌识别过程中的最后一个步骤,用于识别车牌上的字符,并将其转换为数字或字母。这一步骤通常使用光学字符识别(OCR)技术来实现。
实战项目:使用Tesseract进行字符识别
在这个项目中,我们将使用Tesseract库进行字符识别。Tesseract是一个开源的OCR引擎,支持多种语言和字符集。
- import cv2
- import pytesseract
-
- # 设置Tesseract的安装路径
- pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
-
- # 加载摄像头
- cap = cv2.VideoCapture(0)
-
- while True:
- # 读取摄像头帧
- ret, frame = cap.read()
-
- # 转换帧为灰度图像
- gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
-
- # 检测车牌
- plates = plate_cascade.detectMultiScale(gray, 1.3, 5)
-
- # 在帧上绘制车牌边界框
- for (x, y, w, h) in plates:
- # 裁剪车牌区域
- plate_roi = frame[y:y+h, x:x+w]
-
- # 使用Tesseract进行字符识别
- plate_text = pytesseract.image_to_string(plate_roi, lang='chi_sim')
-
- # 显示识别到的字符
- cv2.putText(frame, plate_text, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
-
- # 显示帧
- cv2.imshow('frame', frame)
-
- # 按'q'退出循环
- if cv2.waitKey(20) & 0xFF == ord('q'):
- break
-
- # 释放摄像头并关闭所有窗口
- cap.release()
- cv2.destroyAllWindows()
在这个项目中,我们首先使用摄像头捕获实时帧,并使用Haar级联分类器检测车牌区域。然后,我们裁剪车牌区域,并使用Tesseract进行字符识别。最后,我们在原帧上显示识别到的字符。
通过学习本部分内容,读者应该已经了解了如何将Python车牌识别技术应用于实际项目。在接下来的部分,我们将讨论车牌识别中的注意事项和优化策略,包括数据预处理、特征选择、模型评估等。
第四部分:Python车牌识别注意事项与优化策略
在这一部分,我们将讨论Python车牌识别在实际应用中需要注意的事项和优化策略,以确保车牌识别的稳定运行和高效性。
4.1 数据预处理
数据预处理是车牌识别过程中的一个重要环节,它直接影响模型的性能。以下是一些数据预处理的关键步骤:
- 图像预处理:对输入的图像进行必要的处理,如调整大小、裁剪、去噪等。
- 车牌定位:在图像中定位车牌的位置。
- 车牌分割:将车牌从背景中分割出来。
- 数据增强:通过旋转、缩放、裁剪等方式增加训练数据的多样性。
- 数据标准化:将特征值缩放到一个固定范围内,如0到1或-1到1。
代码示例:数据预处理
- from sklearn.preprocessing import StandardScaler
-
- # 加载数据集
- X = ...
- y = ...
-
- # 划分数据集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
-
- # 数据预处理
- scaler = StandardScaler()
- X_train_scaled = scaler.fit_transform(X_train)
- X_test_scaled = scaler.transform(X_test)
-
- # 训练模型
- model.fit(X_train_scaled, y_train)
-
- # 评估模型
- model.evaluate(X_test_scaled, y_test)
在这个例子中,我们首先加载了数据集,并使用StandardScaler进行了数据预处理。然后,我们训练了一个模型并评估了其性能。
4.2 特征选择
特征选择是减少特征数量的过程,以避免过拟合和提高模型的效率。以下是一些常用的特征选择方法:
- 基于统计的方法:如方差选择、相关性分析等。
- 基于模型的方法:如递归特征消除(RFE)、L1正则化等。
- 基于启发式的方法:如信息增益、卡方检验等。
4.3 模型评估
模型评估是评估模型性能的过程,以确定模型是否适合特定任务。以下是一些常用的模型评估指标:
- 准确率:正确预测的样本数与总样本数的比例。
- 混淆矩阵:显示模型预测结果与实际结果的矩阵。
- ROC曲线和AUC值:用于评估二分类模型的性能。
- 交叉验证:通过多次分割数据集来评估模型的泛化能力。
4.4 模型部署
模型部署是将训练好的模型应用于实际生产环境的过程。以下是一些模型部署的关键步骤:
- 选择合适的模型:根据实际需求选择最合适的模型。
- 模型优化:对模型进行优化,以提高其在实际环境中的性能。
- 编写部署脚本:将模型部署到生产环境,并编写监控和维护脚本。
通过学习本部分内容,读者应该已经了解了Python车牌识别在实际应用中需要注意的事项和优化策略。这些策略将帮助我们在实际项目中更好地使用车牌识别技术,提高模型的稳定性和效率。
总结
本文从Python车牌识别的基础知识出发,详细介绍了车牌识别的基本概念、常用库、实战案例及注意事项。通过学习本文,读者应该能够全面掌握Python车牌识别的基本原理和实践技巧,为智能交通、停车场管理等领域提供有力支持。在实际应用中,我们需要根据具体情况选择合适的车牌识别技术和策略,以达到高效、稳定地处理车牌的目的。
- b站视频下载 ...
赞
踩

