
- 1oracle做拉链,Datastage实现拉链算法
- 2ShardingSphere读写分离
- 3地理信息系统教程(汤国安)——重点总结_双重独立编码结构
- 4NLP发展简史_nlp的发展阶段
- 5通用与垂直,谁将领跑未来?
- 6 推荐一款高效智能的校园考勤系统:Sistem Absensi Sekolah Berbasis QR Code
- 7python3.7+dlib+face_recognition+tensorflow+keras+scipy+numpy版本(已实现)_scipy对应cpu版本
- 8ARM 上的C语言开发_arm的c语言
- 9【软件工程】——开发模型_软件三大开发方法表格对比
- 10学习笔记Label自右向左滚动和父容器内左右移动方法(含代码)_lvgl文本从右到左滚动
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2_ptuning和 全量微调对比
赞
踩
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。
因此,该技术值得我们进行深入分析其背后的机理,本系列大体分七篇文章进行讲解。
-
大模型参数高效微调技术原理综述(一)-背景、参数高效微调简介 -
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning -
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2 -
大模型参数高效微调技术原理综述(四)-Adapter Tuning及其变体 -
大模型参数高效微调技术原理综述(五)-LoRA、AdaLoRA、QLoRA -
大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT -
大模型参数高效微调技术原理综述(七)-最佳实践、总结
本文为大模型参数高效微调技术原理综述的第三篇。
P-Tuning
背景
该方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。比如:GPT-3采用人工构造的模版来做上下文学习(in context learning),但人工设计的模版的变化特别敏感,加一个词或者少一个词,或者变动位置都会造成比较大的变化。

同时,近来的自动化搜索模版工作成本也比较高,以前这种离散化的token的搜索出来的结果可能并不是最优的,导致性能不稳定。
基于此,作者提出了P-Tuning,设计了一种连续可微的virtual token(同Prefix-Tuning类似)。
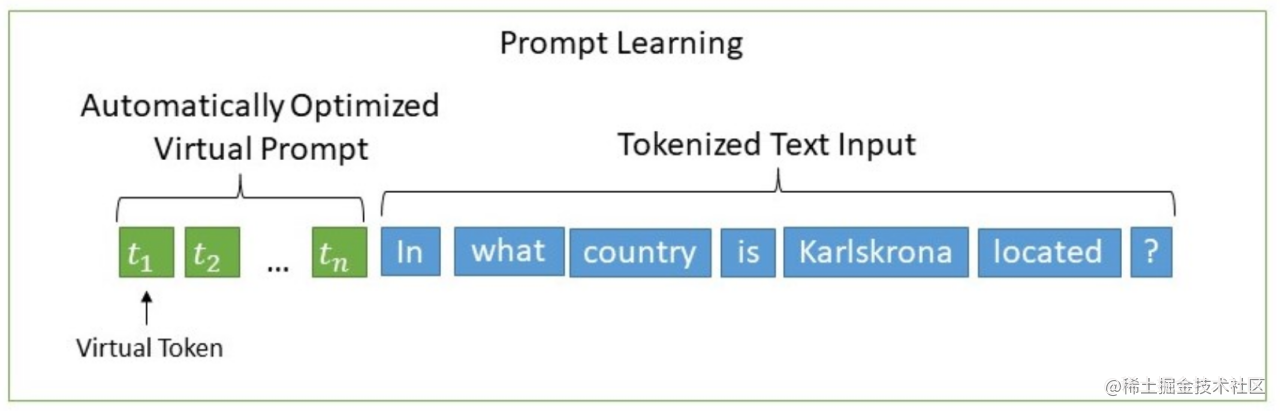
技术原理
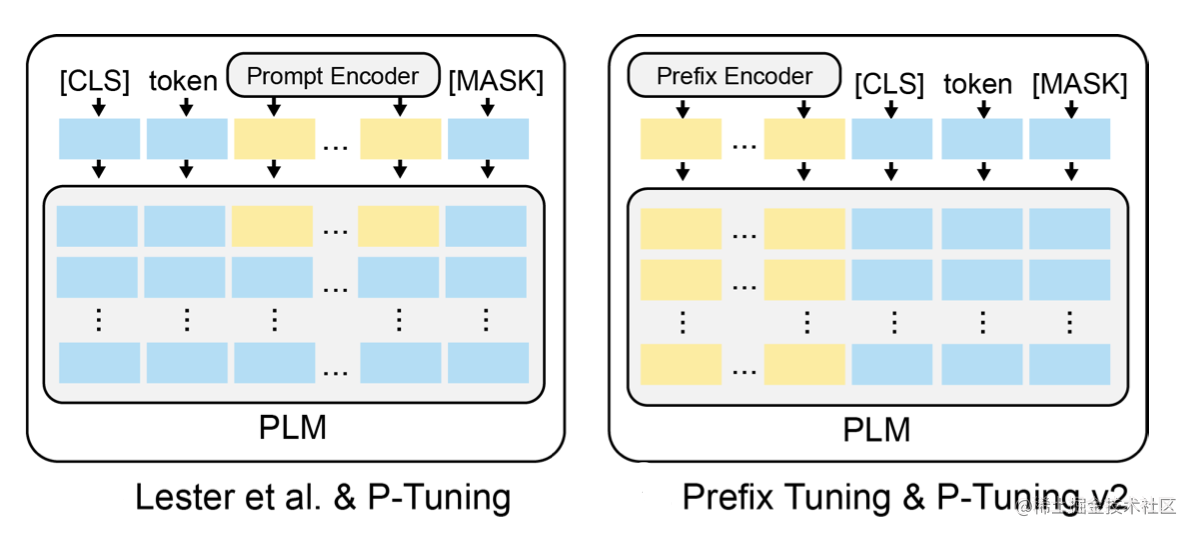
P-Tuning(论文:GPT Understands, Too),该方法将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
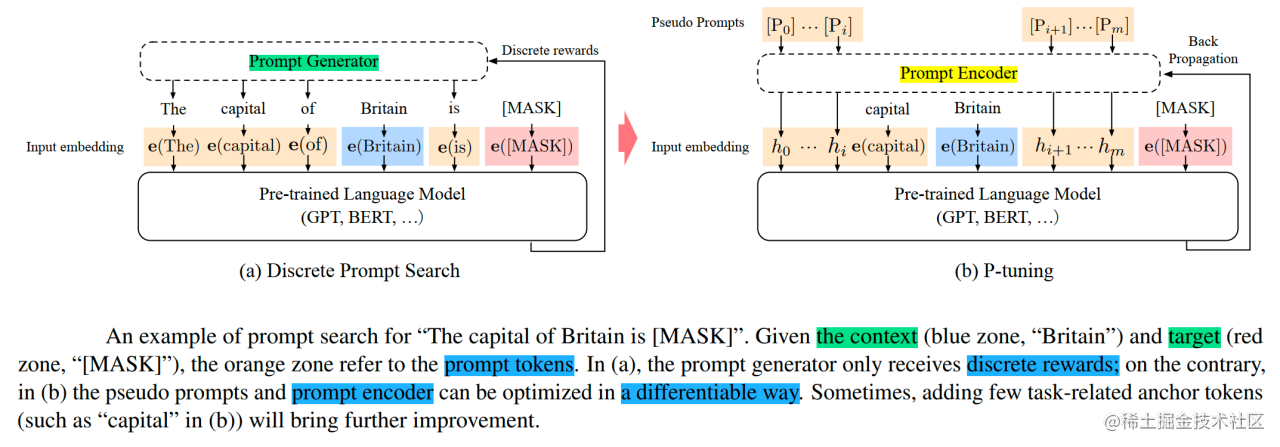
相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。
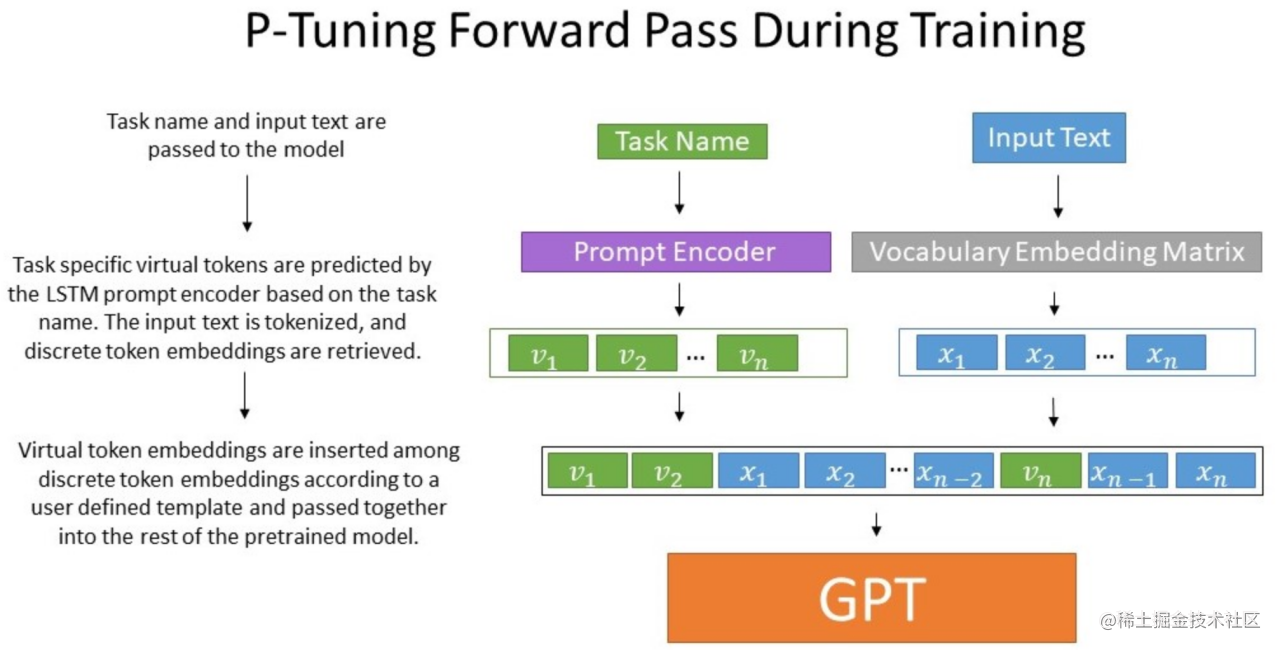
经过预训练的LM的词嵌入已经变得高度离散,如果随机初始化virtual token,容易优化到局部最优值,而这些virtual token理论是应该有相关关联的。因此,作者通过实验发现用一个prompt encoder来编码会收敛更快,效果更好。即用一个LSTM+MLP去编码这些virtual token以后,再输入到模型。
从对比实验证实看出,P-Tuning获得了与全参数一致的效果。甚至在某些任务上优于全参数微调。
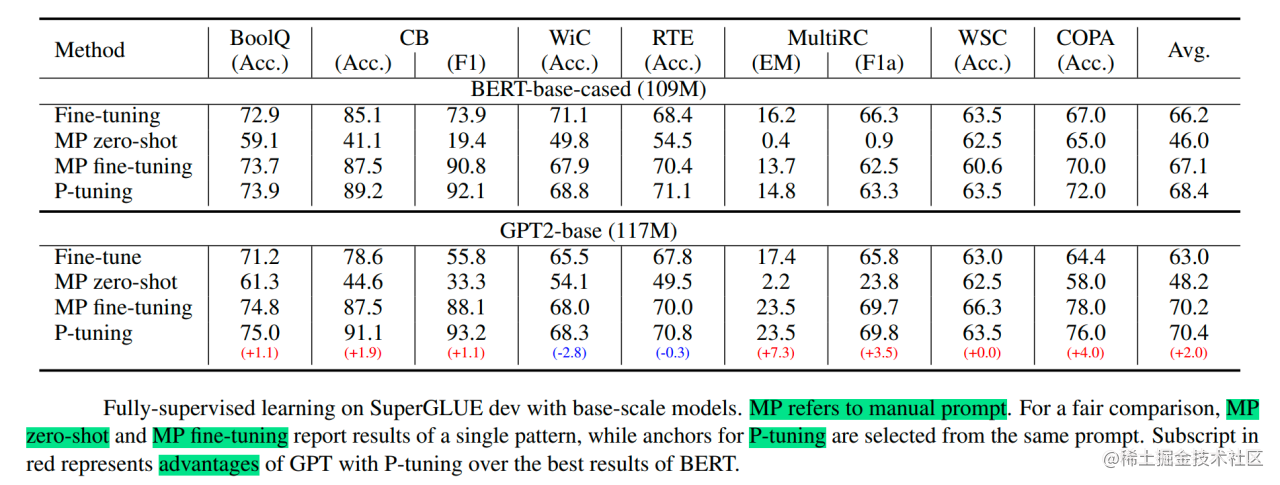
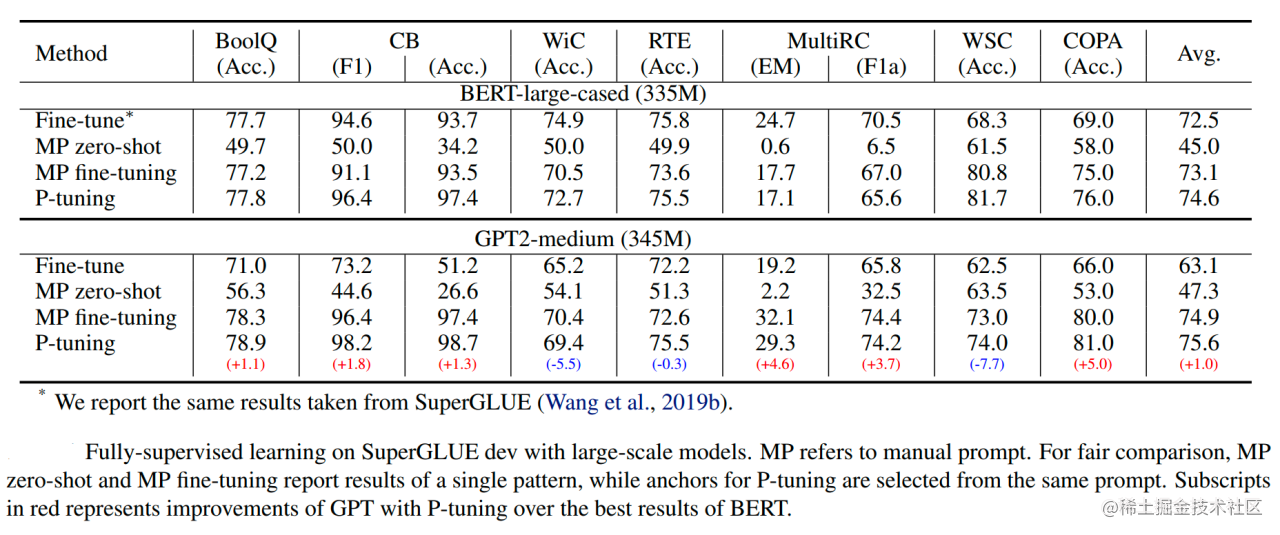
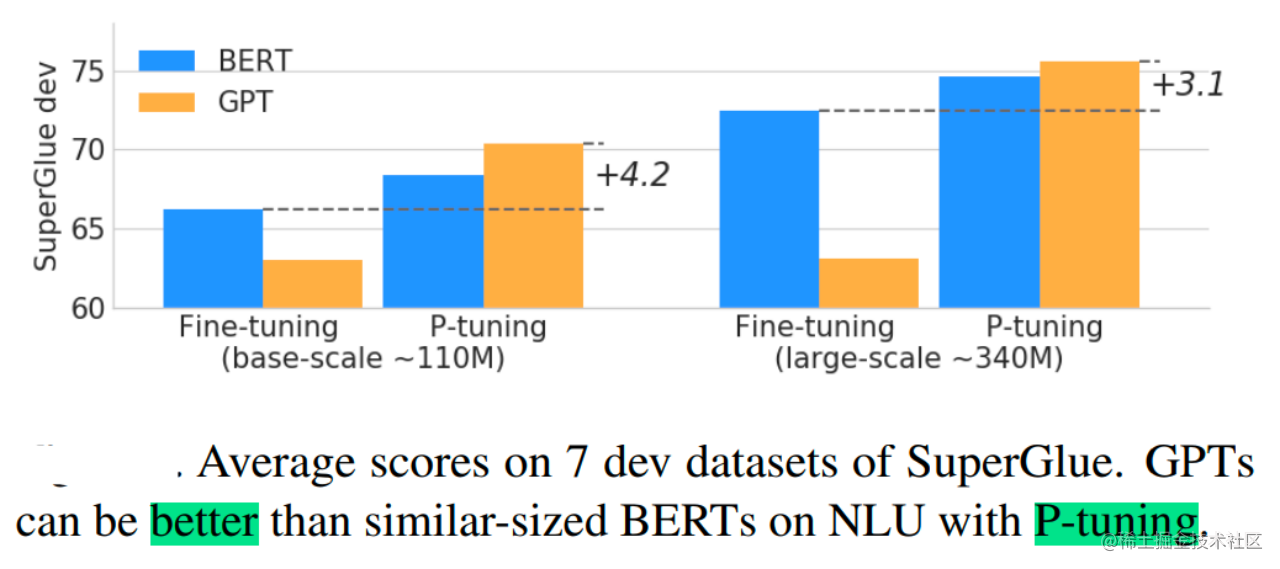
并且在实验中还发现,相同参数规模,如果进行全参数微调,Bert的在NLU任务上的效果,超过GPT很多;但是在P-Tuning下,GPT可以取得超越Bert的效果。
P-Tuning v2
背景
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
第一,缺乏模型参数规模和任务通用性。
-
缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。 -
缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
-
由于序列长度的限制,可调参数的数量是有限的。 -
输入embedding对模型预测只有相对间接的影响。
考虑到这些问题,作者提出了Ptuning v2,它利用深度提示优化(如:Prefix Tuning),对Prompt Tuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
技术原理
P-Tuning v2(论文: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks),该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
-
更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。 -
加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
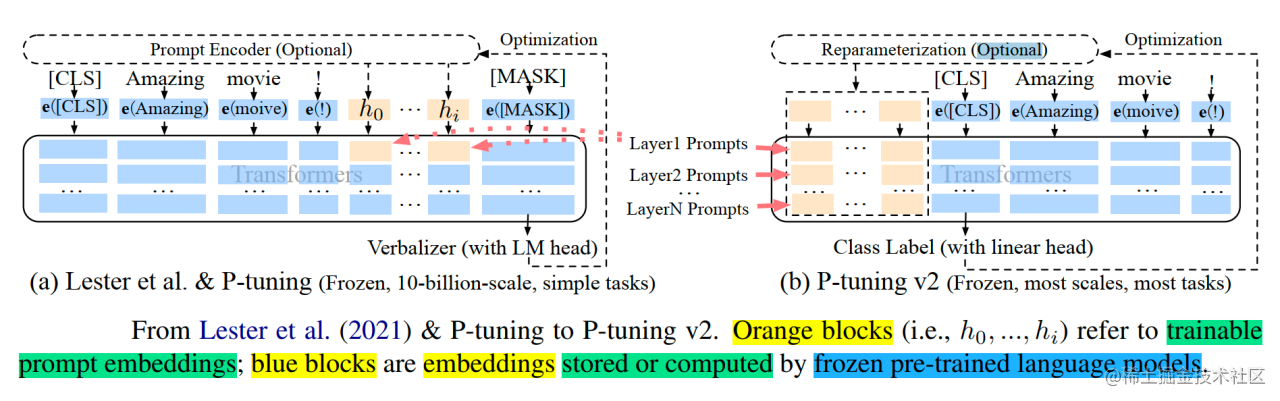
具体做法基本同Prefix Tuning,可以看作是将文本生成的Prefix Tuning技术适配到NLU任务中,然后做了一些改进:
-
移除重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning中的MLP、P-Tuning中的LSTM))。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。 -
针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。 -
引入多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充。
-
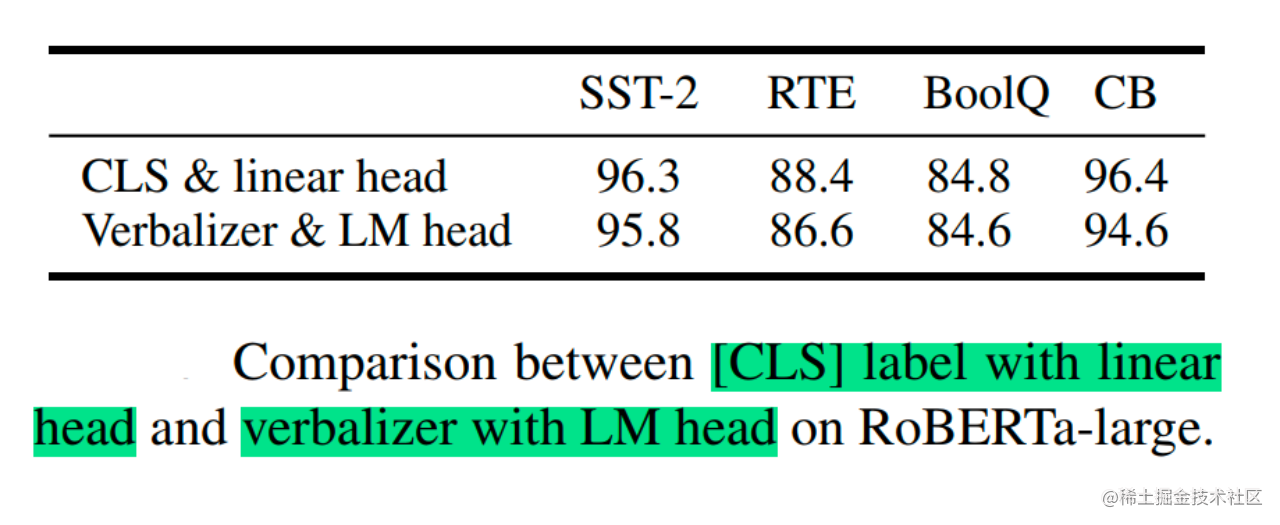
回归传统的分类标签范式,而不是映射器。标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的。它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
论文中展示了P-tuning v2在不同模型规模下的表现。对于简单的NLU任务,如SST-2(单句分类),Prompt Tuning和P-Tuning在较小的规模下没有显示出明显的劣势。但是当涉及到复杂的挑战时,如:自然语言推理(RTE)和多选题回答(BoolQ),它们的性能会非常差。相反,P-Tuning v2在较小规模的所有任务中都与微调的性能相匹配。并且,P-tuning v2在RTE中的表现明显优于微调,特别是在BERT中。
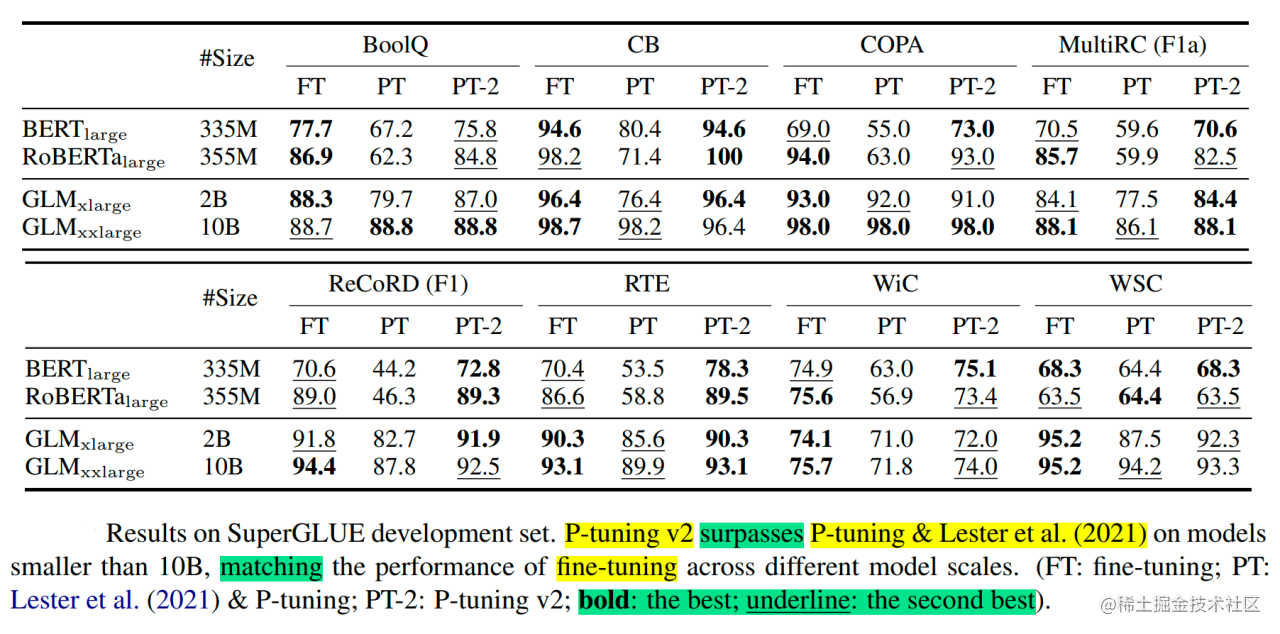
上面讨论了P-Tuning v2无论何种规模都可以与微调相媲美。然而,GLUE和SuperGLUE的大多数任务都是相对简单的NLU问题。
为了评估P-Tuning v2在一些困难的NLU挑战中的能力,作者选择了三个典型的序列标注任务(名称实体识别、抽取式问答(QA)和语义角色标签(SRL)),共八个数据集。我们观察到P-Tuning v2在所有任务上都能与全量微调相媲美。

论文还通过消融实验研究了不同任务上Prompt Length的影响:
-
针对简单任务:如情感分析,较短的Prompt(~20)即可取得不错的效果。 -
针对复杂任务:如阅读理解,需要更长的Prompt(~100)。
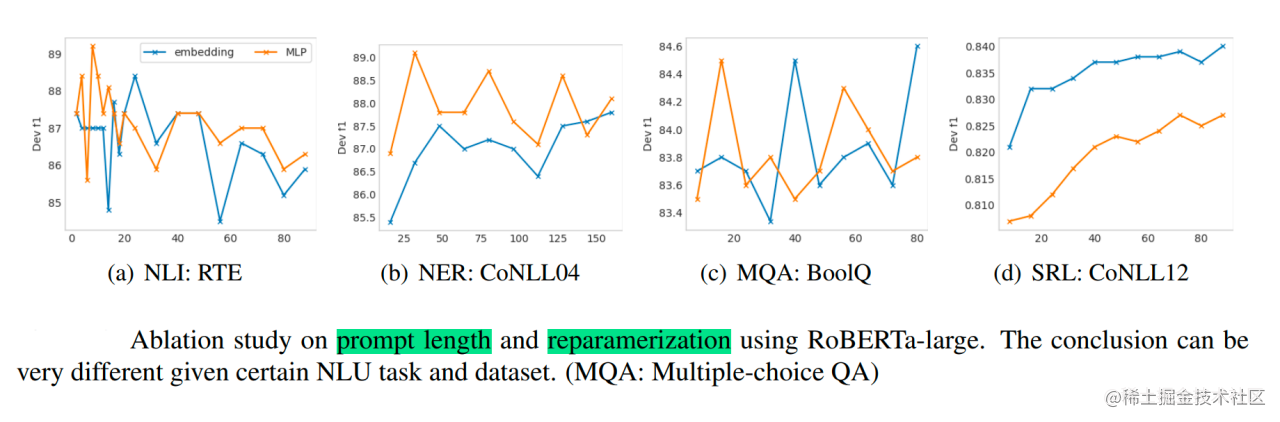
总之,P-Tuning v2是一种在不同规模和任务中都可与微调相媲美的提示方法。P-Tuning v2对从330M到10B的模型显示出一致的改进,并在序列标注等困难的序列任务上以很大的幅度超过了Prompt Tuning和P-Tuning。P-Tuning v2可以成为微调的综合替代方案和未来工作的基线(Baseline)。
结语
本文针对讲述了来自清华大学的团队发布的两种参数高效Prompt微调方法P-Tuning、P-Tuning v2,可以简单的将P-Tuning认为是针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix Tuning的改进。
下文将对高效微调方法Adapter Tuning及其变体进行讲解。如果觉得我的文章能够能够给你带来帮助,欢迎点赞收藏加关注~~

