
- 1洛谷P1000 超级玛丽游戏_超级玛丽 题目描述 超级玛丽是一个非常经典的游戏。请你用字符画的形式输出超级玛
- 2探秘未来对话:GPT4Free TypeScript 版本,免费的 OpenAI GPT-4 API!
- 3蓝队应急响应-docker搭建ELK日志分析系统_蓝队kibana
- 4GCN实战_gcn代码实战
- 5设计模式笔记-概述
- 6Runway Gen-3 实测,这就是 AI 视频生成的 No.1!视频高清化EvTexture 安装配置使用!_runway gen3使用介绍
- 7风控小白必看!主流风控模型解析_风控利率敏感模型
- 8记录一次WireGuard组网中断的问题_csdn zhangzhibo921
- 9知乎好物推荐新号选品思路
- 10因为文件共享不安全,所以你不能连接到文件共享。此共享需要过时的SMB1协议,而此协议是不安全的 解决方法_因为文件共享不安全,所以你不能连接到文件共享
【视频讲解】逻辑回归原理及R语言预测心脏病、用户流失数据挖掘2实例|附代码数据...
赞
踩
全文链接:https://tecdat.cn/?p=36595
分析师:Xinyao Yi
在统计学习和机器学习的领域中,逻辑回归模型是一种广泛应用于分类问题的预测模型。特别是在预测二分类事件或情况时,如选举中某党派是否获得投票、用户是否购买某产品、个体是否感染某种疾病等,逻辑回归模型展现出了其独特的优势(点击文末“阅读原文”获取完整代码数据)。
视频
本文将通过视频讲解,展示逻辑回归模型原理,并结合一个PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像和R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病的代码数据,为读者提供一套完整的实践数据分析流程。
什么是逻辑回归模型?
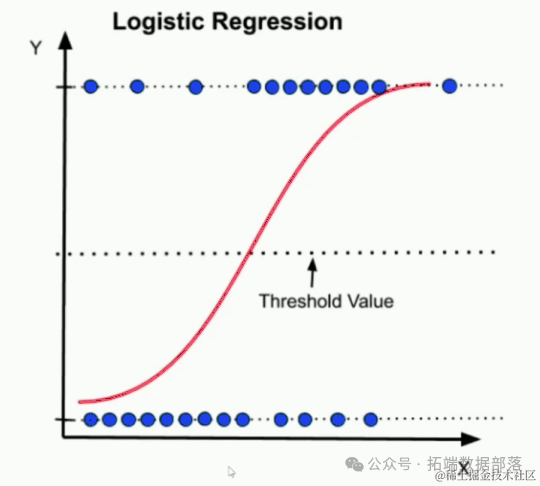
逻辑回归模型本质上是一种概率模型,用于预测某一事件或情况发生的概率。其因变量为二分变量,通常用0和1表示,其中0代表事件不发生,1代表事件发生。与线性回归不同,逻辑回归的输出被限制在0和1之间,通过逻辑函数(如Sigmoid函数)将线性回归的预测值转换为概率值。当预测的概率低于设定的阈值(通常为0.5)时,模型将事件归类为0;反之,则归类为1。
模型原理
逻辑回归模型通过训练数据学习自变量与因变量之间的关系,并构建出能够预测新数据点因变量取值的模型。该模型的核心是逻辑函数,它将线性回归的预测值转换为概率值,从而使得模型的输出符合二分变量的特性。
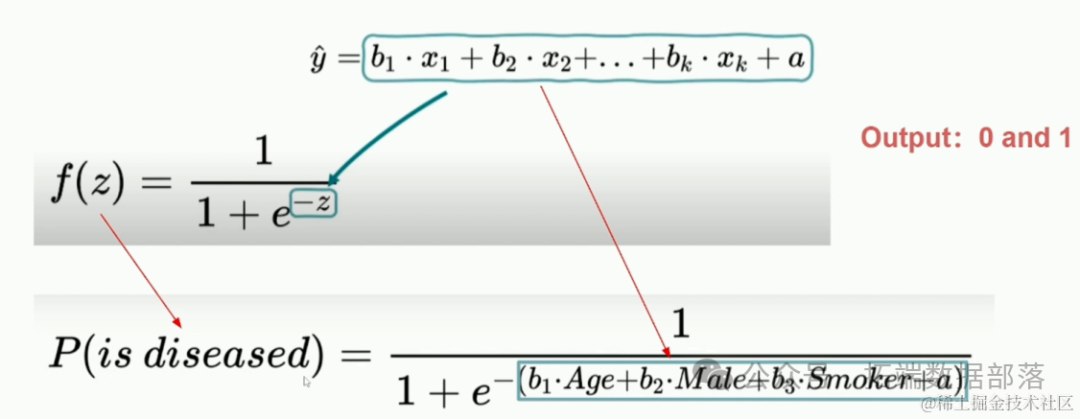
Metrics(衡量)
在评估逻辑回归模型的性能时,我们通常使用准确率、召回率、F1分数等指标。这些指标能够全面反映模型在分类任务中的表现,帮助我们更好地理解和优化模型。
重要变量
在逻辑回归模型中,自变量(或称为特征)的选择对于模型的性能至关重要。重要变量通常与因变量具有较强的相关性,能够显著提高模型的预测能力。通过特征选择和特征工程等技术,我们可以从原始数据中提取出对模型有用的信息,进一步提高模型的性能。
Linear Regression的区别
逻辑回归与线性回归在多个方面存在显著差异。首先,逻辑回归的因变量是分类变量,而线性回归的因变量是连续变量。其次,逻辑回归的输出被限制在0和1之间,而线性回归的输出则没有这样的限制。此外,逻辑回归的模型参数具有直观的解释性,可以表示自变量对因变量影响的程度和方向。 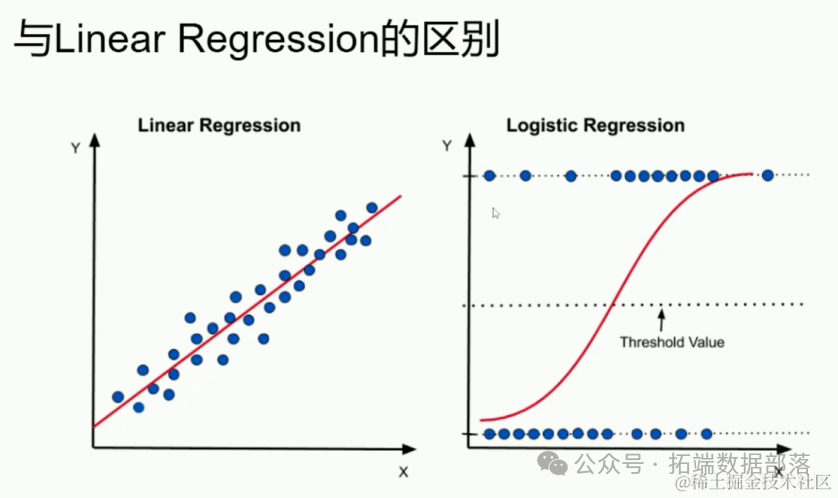
点击标题查阅往期内容

数据分享|R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据

左右滑动查看更多
01
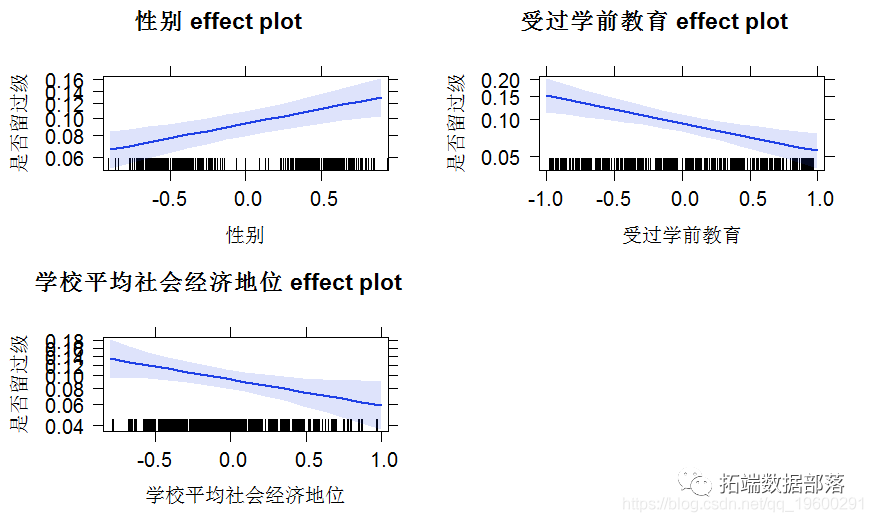
02

03
04
优缺点分析
逻辑回归模型具有以下优点:
处理分类变量:逻辑回归能够处理因变量为分类变量的问题,这是线性回归无法做到的。
直观解释:逻辑回归的模型参数具有直观的解释性,可以帮助我们理解自变量对因变量的影响。
低方差:当特征较少而数据量较大时,逻辑回归往往具有较低的方差,不易过拟合。
训练速度快:逻辑回归模型的训练过程相对简单,计算效率较高。
然而,逻辑回归也存在一些缺点:
不能处理不平衡数据:当正负样本数量差异较大时,逻辑回归的性能可能会受到影响。
分类仅限于二分:逻辑回归只能处理二分类问题,对于多分类问题需要进行额外的处理。
假设自变量间相互独立:逻辑回归假设自变量间相互独立,难以处理多重共线性问题。在实际应用中,这可能需要通过特征选择或降维等技术来避免。
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
这个数据集可以追溯到1988年,由四个数据库组成。克利夫兰、匈牙利、瑞士和长滩。"目标 "字段是指病人是否有心脏病。它的数值为整数,0=无病,1=有病
数据集信息:
目标:
主要目的是预测给定的人是否有心脏病,借助于几个因素,如年龄、胆固醇水平、胸痛类型等。
我们在这个问题上使用的算法是:
二元逻辑回归
Naive Bayes算法
决策树
随机森林
数据集的描述:
该数据有303个观察值和14个变量。每个观察值都包含关于个人的以下信息。
年龄:- 个人的年龄,以年为单位
sex:- 性别(1=男性;0=女性)
cp - 胸痛类型(1=典型心绞痛;2=非典型心绞痛;3=非心绞痛;4=无症状)。
trestbps--静息血压
chol - 血清胆固醇,单位:mg/dl
fbs - 空腹血糖水平>120 mg/dl(1=真;0=假)
restecg - 静息心电图结果(0=正常;1=有ST-T;2=肥大)
thalach - 达到的最大心率
exang - 运动诱发的心绞痛(1=是;0=否)
oldpeak - 相对于静止状态,运动诱发的ST压低
slope - 运动时ST段峰值的斜率(1=上斜;2=平坦;3=下斜)
ca - 主要血管的数量(0-4),由Flourosopy着色
地中海贫血症--地中海贫血症是一种遗传性血液疾病,会影响身体产生血红蛋白和红细胞的能力。1=正常;2=固定缺陷;3=可逆转缺陷
目标--预测属性--心脏疾病的诊断(血管造影疾病状态)(值0=<50%直径狭窄;值1=>50%直径狭窄)
在Rstudio中加载数据
heart<-read.csv("heart.csv",header = T)header = T意味着给定的数据有自己的标题,或者换句话说,第一个观测值也被考虑用于预测。
head(heart)
当我们想查看和检查数据的前六个观察点时,我们使用head函数。
tail(heart)
显示的是我们数据中最后面的六个观察点
colSums(is.na(heart))
这个函数是用来检查我们的数据是否包含任何NA值。
如果没有发现NA,我们就可以继续前进,否则我们就必须在之前删除NA。
检查我们的数据结构
str(heart)
查看我们的数据摘要
summary(heart)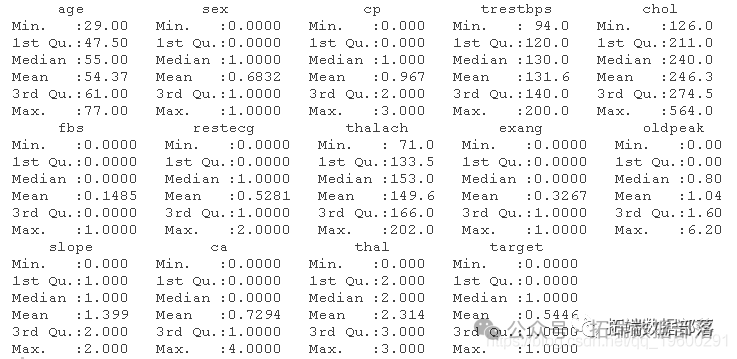
通过观察以上的总结,我们可以说以下几点
性别不是连续变量,因为根据我们的描述,它可以是男性或女性。因此,我们必须将性别这个变量名称从整数转换为因子。
cp不能成为连续变量,因为它是胸痛的类型。由于它是胸痛的类型,我们必须将变量cp转换为因子。
fbs不能是连续变量或整数,因为它显示血糖水平是否低于120mg/dl。
restecg是因子,因为它是心电图结果的类型。它不能是整数。所以,我们要把它转换为因子和标签。
根据数据集的描述,exang应该是因子。心绞痛发生或不发生。因此,将该变量转换为因子。
斜率不能是整数,因为它是在心电图中观察到的斜率类型。因此,我们将变量转换为因子。
根据数据集的描述,ca不是整数。因此,我们要将该变量转换为因子。
thal不是整数,因为它是地中海贫血的类型。因此,我们将变量转换为因子。
目标是预测变量,告诉我们这个人是否有心脏病。因此,我们将该变量转换为因子,并为其贴上标签。
根据上述考虑,我们对变量做了一些变化
- #例如
- sex<-as.factor(sex)
- levels(sex)<-c("Female","Male")
检查上述变化是否执行成功
str(heart)
summary(heart)
EDA
EDA是探索性数据分析(Exploratory Data Analysis)的缩写,它是一种数据分析的方法/哲学,采用各种技术(主要是图形技术)来深入了解数据集。
对于图形表示,我们需要库 "ggplot2"
- library(ggplot2)
- ggplot(heart,aes(x=age,fill=target,color=target)) + geom_histogram(binwidth = 1,color="black") + labs(x = "Age",y = "Frequency", title = "Heart Disease w.r.t. Age")
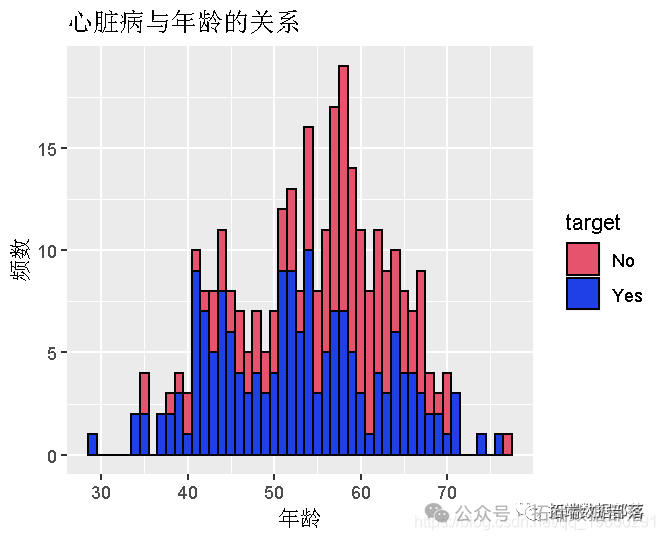
我们可以得出结论,与60岁以上的人相比,40至60岁的人患心脏病的概率最高。
- table <- table(cp)
-
- pie(table)
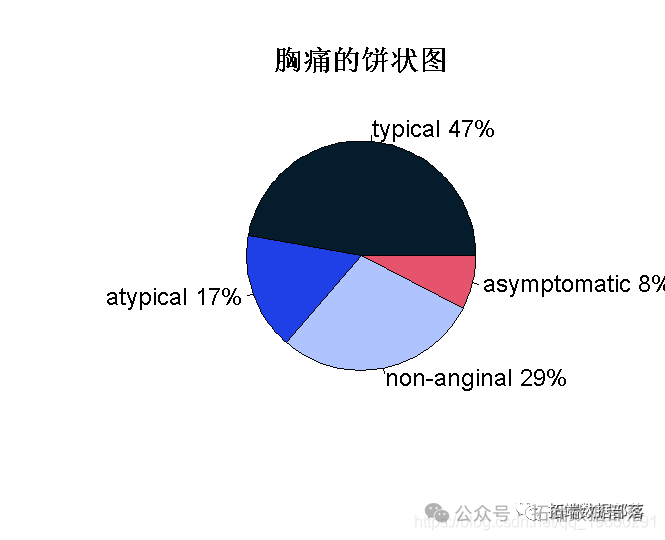
我们可以得出结论,在所有类型的胸痛中,在个人身上观察到的大多数是典型的胸痛类型,然后是非心绞痛。
执行机器学习算法
Logistic回归
首先,我们将数据集分为训练数据(75%)和测试数据(25%)。
- set.seed(100)
- #100用于控制抽样的permutation为100.
- index<-sample(nrow(heart),0.75*nrow(heart))
在训练数据上生成模型,然后用测试数据验证模型。
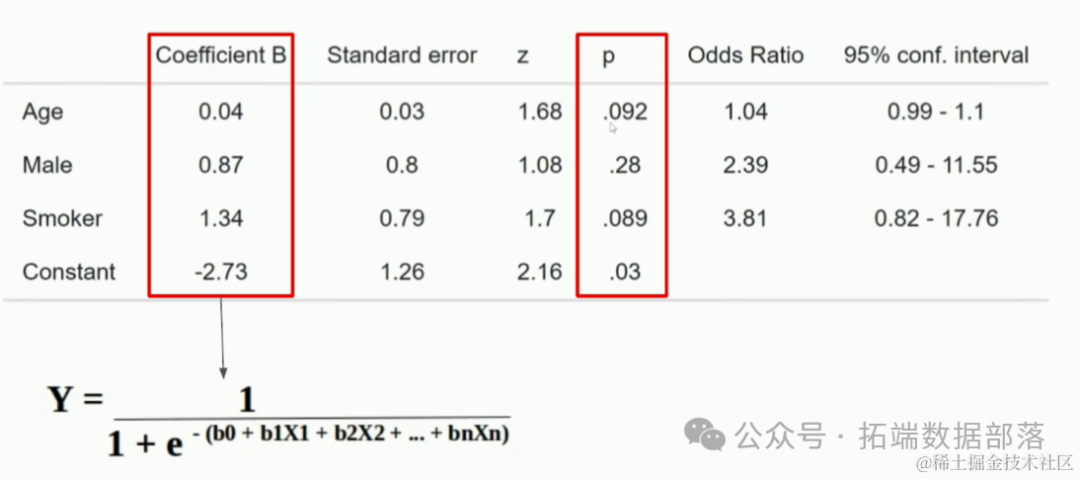
- glm(family = "binomial")
- # family = " 二项式 "意味着只包含两个结果。
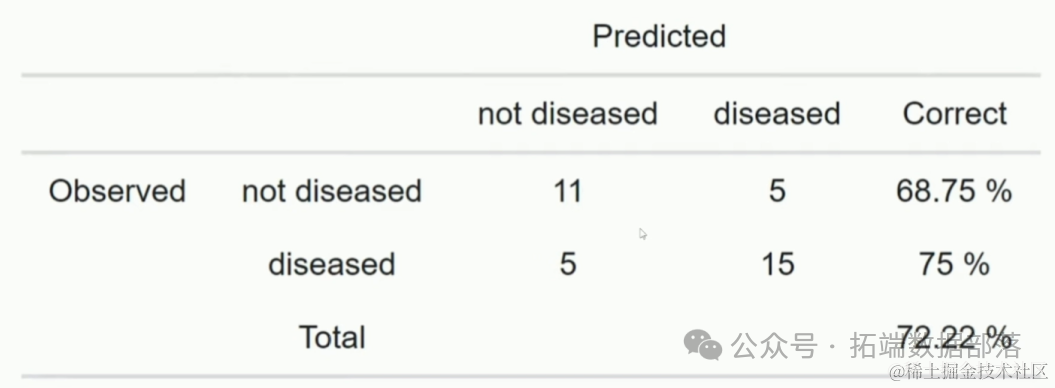
为了检查我们的模型是如何生成的,我们需要计算预测分数和建立混淆矩阵来了解模型的准确性。
- pred<-fitted(blr)
- # 拟合只能用于获得生成模型的数据的预测分数。

我们可以看到,预测的分数是患心脏病的概率。但我们必须找到一个适当的分界点,从这个分界点可以很容易地区分是否患有心脏病。
为此,我们需要ROC曲线,这是一个显示分类模型在所有分类阈值下的性能的图形。它将使我们能够采取适当的临界值。
- pred<-prediction(train$pred,train$target)
- perf<-performance(pred,"tpr","fpr")
- plot(perf,colorize = T,print.cutoffs.at = seq(0.1,by = 0.1))
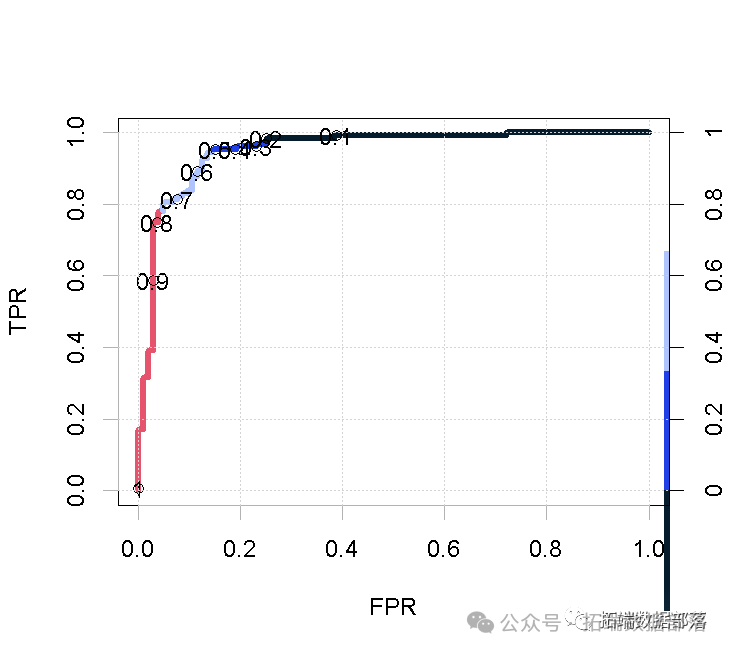
通过使用ROC曲线,我们可以观察到0.6具有更好的敏感性和特异性,因此我们选择0.6作为区分的分界点。
pred1<-ifelse(pred<0.6,"No","Yes")
- # 训练数据的准确性
- acc_tr

从训练数据的混淆矩阵中,我们知道模型有88.55%的准确性。
现在在测试数据上验证该模型
- predict(type = "response")
- ## type = "response "是用来获得患有心脏病的概率的结果。
- head(test)

我们知道,对于训练数据来说,临界点是0.6。同样地,测试数据也会有相同的临界点。
confusionMatrix((pred1),target)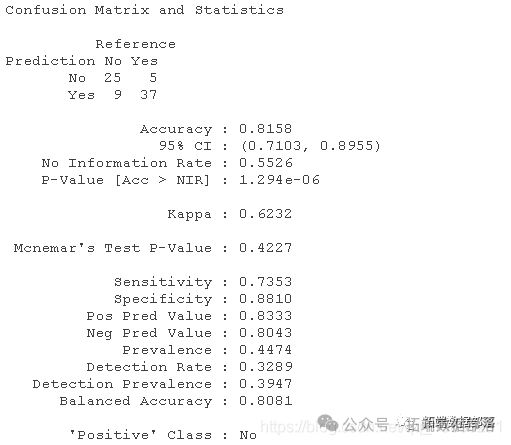
#测试数据的准确性.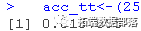
检查我们的预测值有多少位于曲线内
auc@y.values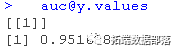
我们可以得出结论,我们的准确率为81.58%,90.26%的预测值位于曲线之下。同时,我们的错误分类率为18.42%。
Naive Bayes算法
在执行Naive Bayes算法之前,需要删除我们在执行BLR时添加的额外预测列。
- #naivebayes模型
- nB(target~.)
用训练数据检查模型,并创建其混淆矩阵,来了解模型的准确程度。
- predict(train)
- confMat(pred,target)


我们可以说,贝叶斯算法对训练数据的准确率为85.46%。
现在,通过预测和创建混淆矩阵来验证测试数据的模型。
Matrix(pred,target)

我们可以得出结论,在Naive Bayes算法的帮助下生成的模型准确率为78.95%,或者我们也可以说Naive Bayes算法的错误分类率为21.05%。
决策树
在实施决策树之前,我们需要删除我们在执行Naive Bayes算法时添加的额外列。
train$pred<-NULLrpart代表递归分区和回归树
当自变量和因变量都是连续的或分类的时候,就会用到rpart。
rpart会自动检测是否要根据因变量进行回归或分类。
实施决策树
plot(tree)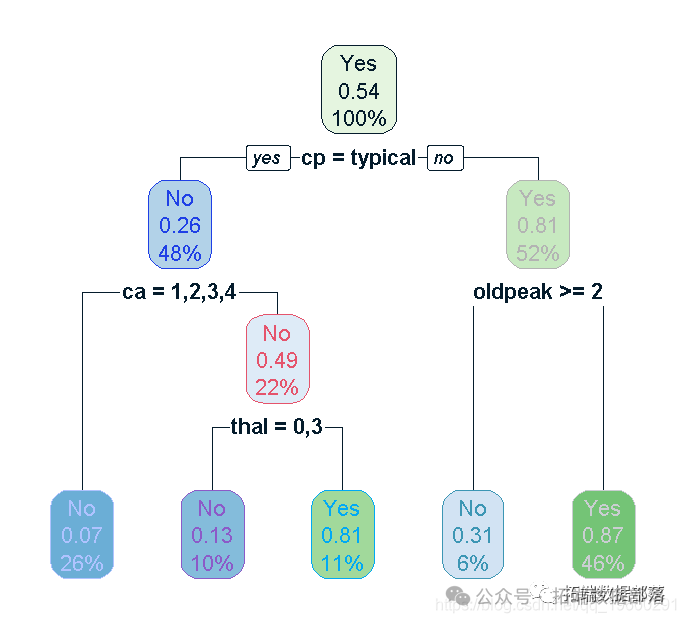
在决策树的帮助下,我们可以说所有变量中最重要的是CP、CA、THAL、Oldpeak。
让我们用测试数据来验证这个模型,并找出模型的准确性。
conMat(pred,targ)
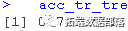
我们可以说,决策树的准确率为76.32%,或者说它的错误分类率为23.68%。
随机森林
在执行随机森林之前,我们需要删除我们在执行决策树时添加的额外预测列。
test$pred<-NULL在随机森林中,我们不需要将数据分成训练数据和测试数据,我们直接在整个数据上生成模型。为了生成模型,我们需要使用随机森林库
- # Set.seed通过限制permutation来控制随机性。
-
- set.seed(100)
- model_rf<-randomForest(target~.,data = heart)
- model_rf

在图上绘制出随机森林与误差的关系。
plot(model_rf)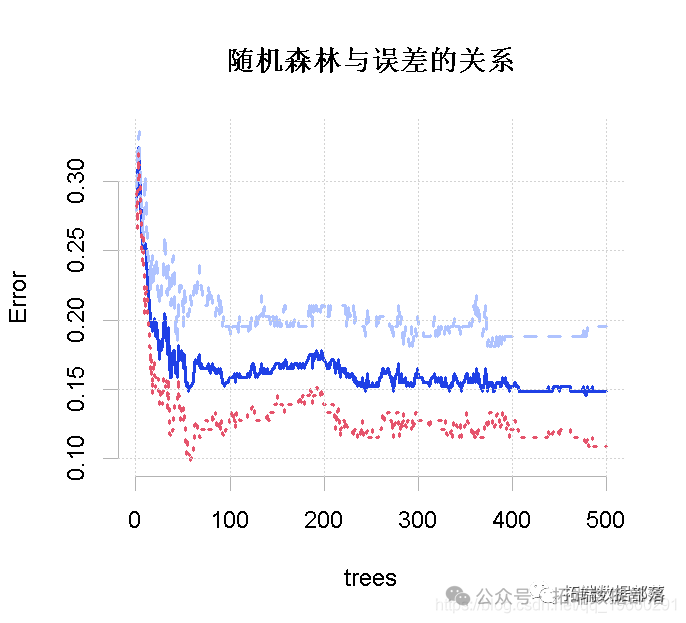
红线代表没有心脏病的MCR,绿线代表有心脏病的MCR,黑线代表总体MCR或OOB误差。总体误差率是我们感兴趣的,结果不错。
结论
在进行了各种分类技术并考虑到它们的准确性后,我们可以得出结论,所有模型的准确性都在76%到84%之间。其中,随机森林的准确率略高,为83.5%。
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像|附代码数据
在今天产品高度同质化的品牌营销阶段,企业与企业之间的竞争集中地体现在对客户的争夺上
“用户就是上帝”促使众多的企业不惜代价去争夺尽可能多的客户。但是企业在不惜代价发展新用户的过程中,往往会忽视或无暇顾及已有客户的流失情况,结果就导致出现这样一种窘况:一边是新客户在源源不断地增加,而另一方面是辛辛苦苦找来的客户却在悄然无声地流失。因此对老用户的流失进行数据分析从而挖掘出重要信息帮助企业决策者采取措施来减少用户流失的事情至关重要,迫在眉睫。

1.2 目的:
深入了解用户画像及行为偏好,挖掘出影响用户流失的关键因素,并通过算法预测客户访问的转化结果,从而更好地完善产品设计、提升用户体验。
1.3 数据说明:
此次数据是携程用户一周的访问数据,为保护客户隐私,已经将数据经过了脱敏,和实际商品的订单量、浏览量、转化率等有一些差距,不影响问题的可解性。
2 读取数据
- # 显示全部特征
- df.head()
3 切分数据
- # 划分训练集,测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
3.1 理解数据
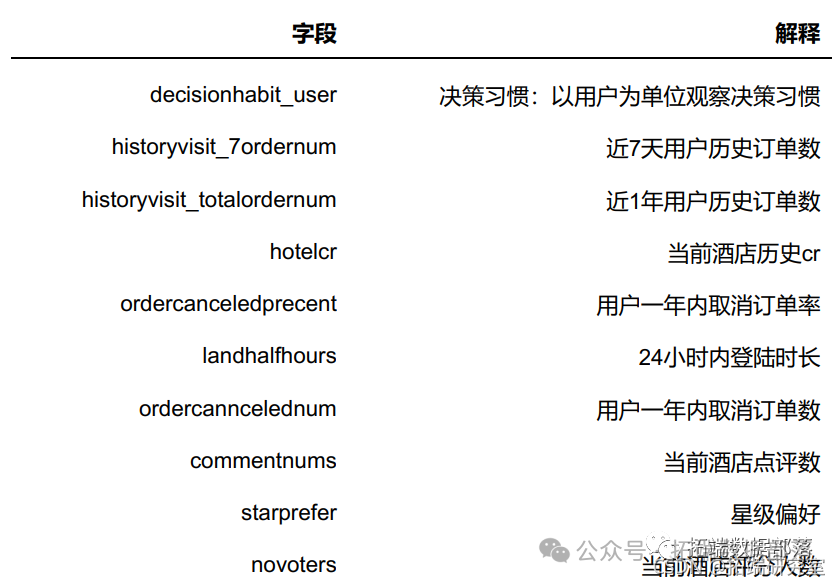
可以看到变量比较的多,先进行分类,除去目标变量label,此数据集的字段可以分成三个类别:订单相关指标、客户行为相关指标、酒店相关指标。

4 特征工程
- # 用训练集进行数据探索
- train = pd.concat([X_train,y_train],axis=1)
4.1 数据预处理


4.1.1 删除不必要的列
- X_train.pop("sampleid")
- X_test.pop("sampleid")
- train.pop("sampleid")

4.1.2 数据类型转换
字符串类型的特征需要处理成数值型才能建模,将arrival和d相减得到"提前预定的天数",作为新的特征
- # 增加列
- # 将两个日期变量由字符串转换为日期格式类型
- train["arrial"] = pd.to_datimetain["arrval"])
- X_tst["arival"] = d.to_daetime(X_est["arival"])
- # 生成提前预定时间列(衍生变量)
- X_trin["day_adanced"] = (X_rain["arival"]-Xtrain["d"]).dt.days
-
- ## 删除列
- X_tran.dro(columns="d","arrivl"],inpace=True)
4.1.3 缺失值的变量生成一个指示哑变量
zsl = tain.isnll().sum()[tain.isnll(.sum()!=0].inex4.1.4 根据业务经验填补空缺值
ordernum_oneyear 用户年订单数为0 ,lasthtlordergap 11%用600000填充 88%用600000填充 一年内距离上次下单时长,ordercanncelednum 用0填充 用户一年内取消订单数,ordercanceledprecent 用0t填充 用户一年内取消订
单率 242114 242114 -为空 有2种情况 1:新用户未下订单的空-88.42% 214097 2.老用户1年以上未消费的空 增加编码列未下订单新用户和 1年未下订单的老用户
price_sensitive -0 ,中位数填充 价格敏感指数,consuming_capacity -0 中位数填充 消费能力指数 226108 -为空情况 1.从未下过单的新用户214097 2.12011个人为空原因暂不明确
uv_pre -24小时历史浏览次数最多酒店历史uv. cr_pre -0,中位数填充 -24小时历史浏览次数最多酒店历史cr -0,中位数填充 29397 -为空 1.用户当天未登录APP 28633 2.刚上线的新酒店178 586 无uv,cr记录 编码添加 该APP刚上线的新酒店 764 29397
customereval_pre2 用0填充-24小时历史浏览酒店客户评分均值, landhalfhours -24小时内登陆时长 -用0填充28633 -为空:用户当天未登录APP 28633
hotelcr ,hoteluv -中位数填充 797
刚上新酒店 60 #未登录APP 118
avgprice 0 填充一部分价格填充为0 近一年未下过订单的人数,cr 用0填充,
- tkq = ["hstoryvsit_7ordernm","historyviit_visit_detaipagenum","frstorder_b","historyvi
- # tbkq = ["hitoryvsit_7dernum","hisryvisit_isit_detailagenum"]
- X_train[i].fillna(0,inplace=True)
- ## 一部分用0填充,一部分用中位數填充
- # 新用戶影響的相關屬性:ic_sniti,cosuing_cacity
- n_l = picesensitive","onsmng_cpacty"]
- fori in n_l
- X_trini][Xra[X_trinnew_ser==1].idex]=0
- X_est[i][X_test[X_test.nw_user==1].inex]=0
4.1.5 异常值处理
将customer_value_profit、ctrip_profits中的负值按0处理
将delta_price1、delta_price2、lowestprice中的负值按中位数处理
- for f in flter_two:
- a = X_trin[].median()
- X_tran[f][X_train[f]<0]=a
- X_test[f][X_est[]<0]=a
- tran[f][train[f]<0]=a
4.1.6 缺失值填充
趋于正态分布的字段,使用均值填充:businessrate_pre2、cancelrate_pre、businessrate_pre;偏态分布的字段,使用中位数填充.
- def na_ill(df):
- for col in df.clumns:
- mean = X_trai[col].mean()
-
- dfcol]=df[col].fillna(median)
- return
- ## 衍生变量年成交率
- X_train["onear_dalate"]=_tain["odernum_onyear"]/X_tran"visinum_onyar"]
- X_st["onyardealae"]=X_st["orernum_neyear"]/Xtest[visitumonyear"]
- X_al =pd.nca([Xtin,Xtes)
- #决策树检验
-
- dt = Decsionr(random_state=666)
-
- pre= dt.prdict(X_test)
- pre_rob = dt.preicproa(X_test)[:,1]
- pre_ob

4.2 数据标准化
- scaler = MinMacaer()
-
- #决策树检验
- dt = DeonTreasifi(random_state=666)
5 特征筛选
5.1 特征选择-删除30%列
- X_test = X_test.iloc[:,sp.get_spport()]
- #决策树检验
- dt = DecisonreeClssifie(random_state=666)
- dt.fit(X_trin,y_tain)
- dt.score(X_tst,y_est)
- pre = dt.pdict(X_test)
- pe_rob = dt.redicproba(X_test)[:,1]
- pr_rob
-
- uc(pr,tpr)

5.2 共线性/数据相关性
- #共线性--严重共线性0.9以上,合并或删除
- d = Xtrai.crr()
- d[d<0.9]=0 #赋值显示高相关的变量
- pl.fufsiz=15,15,dpi200)
- ssheatp(d)
6 建模与模型评估
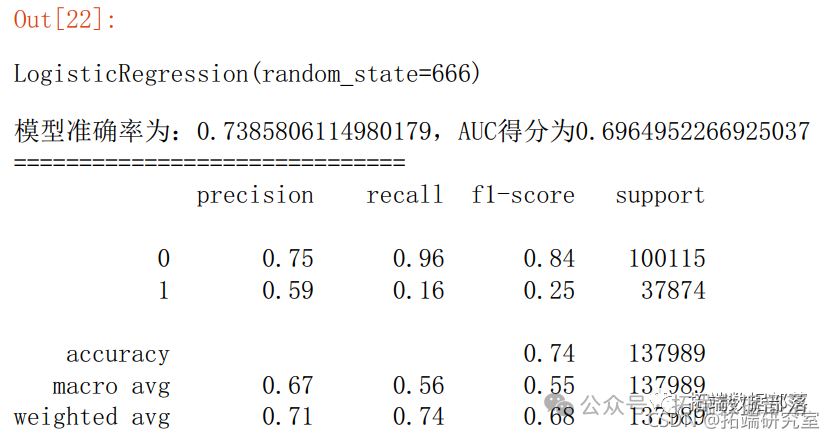
6.1 逻辑回归
- y_prob = lr.preictproba(X_test)[:,1]
- y_pred = lr.predict(X_test
- fpr_lr,pr_lr,teshold_lr = metris.roc_curve(y_test,y_prob)
- ac_lr = metrcs.aucfpr_lr,tpr_lr)
- score_lr = metrics.accuracy_score(y_est,y_pred)
- prnt("模准确率为:{0},AUC得分为{1}".fomat(score_lr,auc_lr))
- prit("="*30
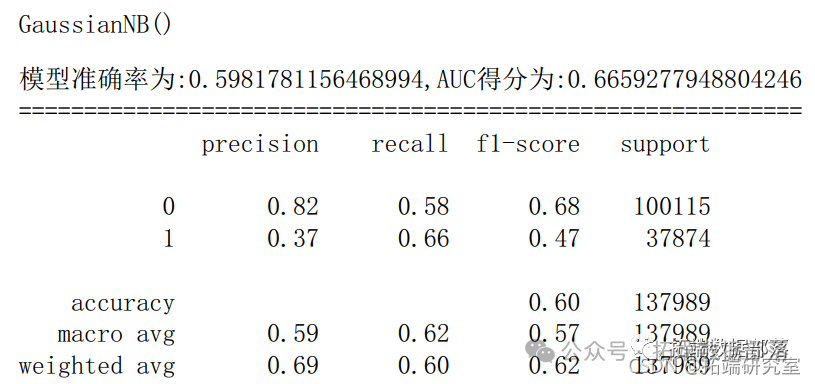
6.2 朴素贝叶斯
- gnb = GasinNB() # 实例化一个LR模型
- gnb.fi(trai,ytran) # 训练模型
- y_prob = gn.pic_proba(X_test)[:,1] # 预测1类的概率
- y_pred = gnb.preict(X_est) # 模型对测试集的预测结果
- fpr_gnb,tprgnbtreshold_gb = metrics.roc_crve(ytesty_pob) # 获取真阳率、伪阳率、阈值
- aucgnb = meic.aucf_gnb,tr_gnb) # AUC得分
- scoe_gnb = merics.acuray_score(y_tes,y_pred) # 模型准确率
6.3 支持向量机
- s =SVkernel='f',C=,max_ter=10,randomstate=66).fit(Xtrain,ytrain)
- y_rob = sc.decsion_untio(X_st) # 决策边界距离
- y_ed =vc.redit(X_test) # 模型对测试集的预测结果
- fpr_sv,tpr_vc,theshld_sv = mtris.rc_urv(y_esty_pob) # 获取真阳率、伪阳率、阈值
- au_vc = etics.ac(fpr_sc,tpr_sv) # 模型准确率
- scre_sv = metrics.ccuracy_sore(_tst,ypre)
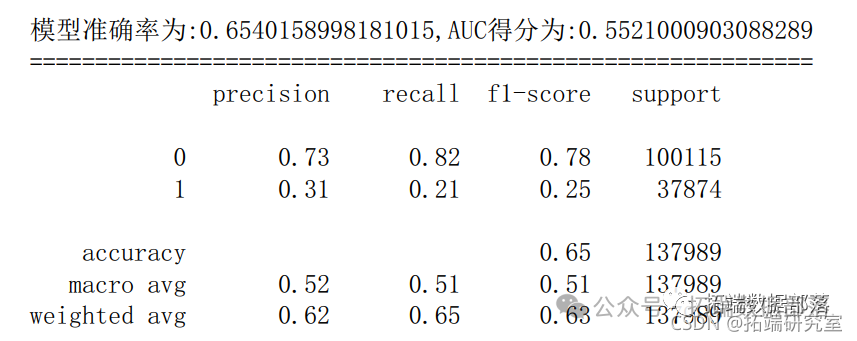
6.4 决策树
- dtc.fit(X_tran,_raiproba(X_test)[:,1] # 预测1类的概率
- y_pred = dtc.predct(X_test # 模型对测试集的预测结果
- fpr_dtc,pr_dtc,thresod_dtc= metrcs.roc_curvey_test,yprob) # 获取真阳率、伪阳率、阈值
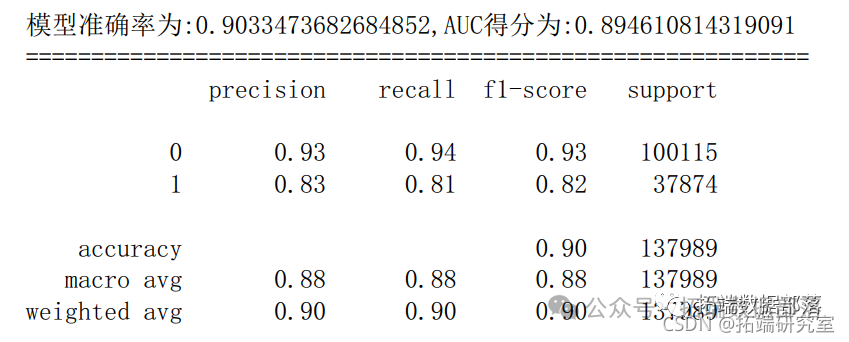
6.5 随机森林
- c = RndoForetlassiir(rand_stat=666) # 建立随机森
- rfc.it(X_tain,ytrain) # 训练随机森林模型
- y_rob = rfc.redict_poa(X_test)[:,1] # 预测1类的概率
- y_pedf.pedic(_test) # 模型对测试集的预测结果
- fpr_rfc,tp_rfc,hreshol_rfc = metrcs.roc_curve(y_test,_prob) # 获取真阳率、伪阳率、阈值
- au_fc = meris.auc(pr_rfctpr_fc) # AUC得分
- scre_rf = metrcs.accurac_scor(y_tes,y_ped) # 模型准确率
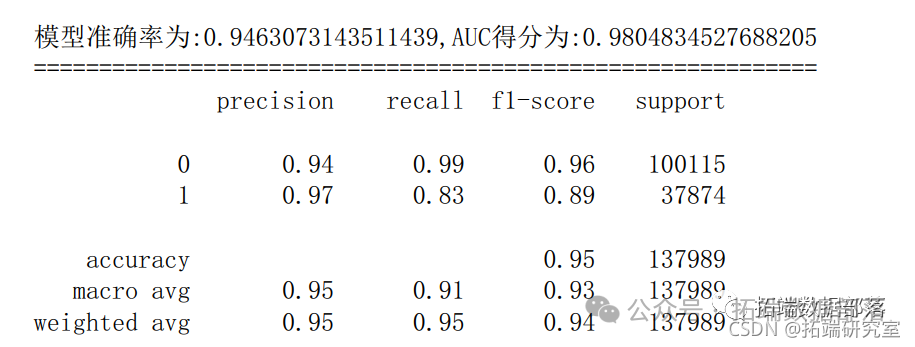
6.6 XGboost
- # 读训练数据集和测试集
- dtainxgbatrx(X_rai,yrain)
- dtest=g.DMrx(Xtest
- # 设置xgboost建模参数
- paras{'booser':'gbtee','objective': 'binay:ogistic','evlmetric': 'auc'
-
- # 训练模型
- watchlst = (dtain,'trai)
- bs=xgb.ran(arams,dtain,n_boost_round=500eva=watchlst)
- # 输入预测为正类的概率值
- y_prob=bst.redict(dtet)
- # 设置阈值为0.5,得到测试集的预测结果
- y_pred = (y_prob >= 0.5)*1
- # 获取真阳率、伪阳率、阈值
- fpr_xg,tpr_xgb,heshold_xgb = metricsroc_curv(test,y_prob)
- aucxgb= metics.uc(fpr_gb,tpr_xgb # AUC得分
- score_gb = metricsaccurac_sore(y_test,y_pred) # 模型准确率
- print('模型准确率为:{0},AUC得分为:{1}'.format(score_xgb,auc_xgb))


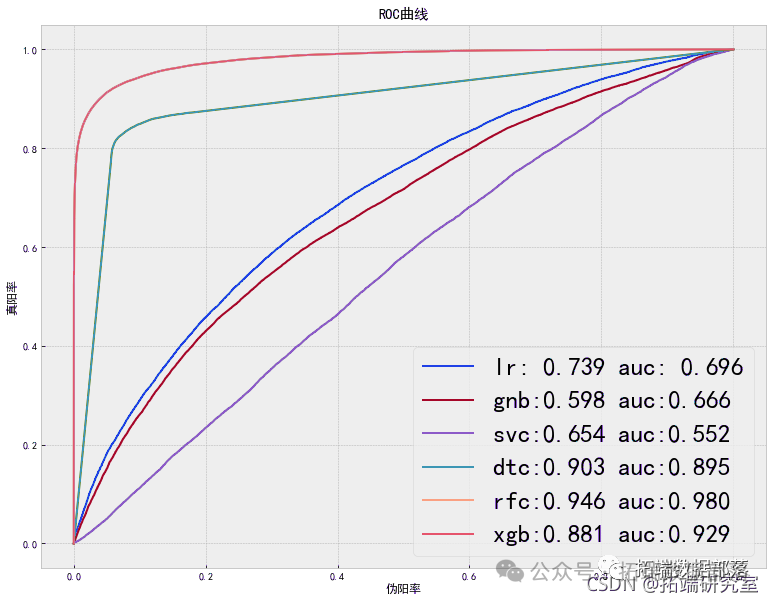
6.7 模型比较
- plt.xlabel('伪阳率')
- plt.ylabel('真阳率')
- plt.title('ROC曲线')
- plt.savefig('模型比较图.jpg',dpi=400, bbox_inches='tight')
- plt.show()
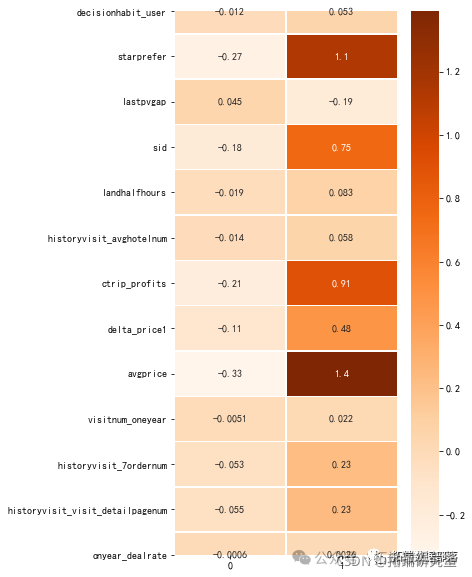
6.8 重要特征
- ea = pd.Sries(dct(list((X_trclumsfc.eatre_imortancs_))))
- ea.srt_vlues(acedig=False
- fea_s = (fa.srt_vauesacnding=alse)).idex


6.9 流失原因分析
cityuvs和cityorders值较小时用户流失显著高于平均水平,说明携程平台小城市的酒店信息缺乏,用户转向使用小城市酒店信息较全的竞品导致用户流失
访问时间点在7点-19点用户流失比例高与平均水平:工作日推送应该避开这些时间点
酒店商务属性指数在0.3-0.9区间内用户流失大于平均水平,且呈现递增趋势,说明平台商务指数高的酒店和用户期望有差距(价格太高或其他原因?), 商务属性低的用户流失较少
一年内距离上次下单时长越短流失越严重,受携程2015年5月-2016年1月爆出的负面新闻影响较大,企业应该更加加强自身管理,树立良好社会形象
消费能力指数偏低(10-40)的用户流失较严重,这部分用户占比50%应该引起重视
价格敏感指数(5-25)的人群流失高于平均水平,注重酒店品质
用户转化率,用户年订单数,近1年用户历史订单数越高,24小时内否访问订单填写页的人群比例越大流失越严重,需要做好用户下单后的追踪体验, 邀请填写入住体验,整理意见作出改进
提前预定天数越短流失越严重用户一年内取消订单数越高流失越严重
6.10 建议:
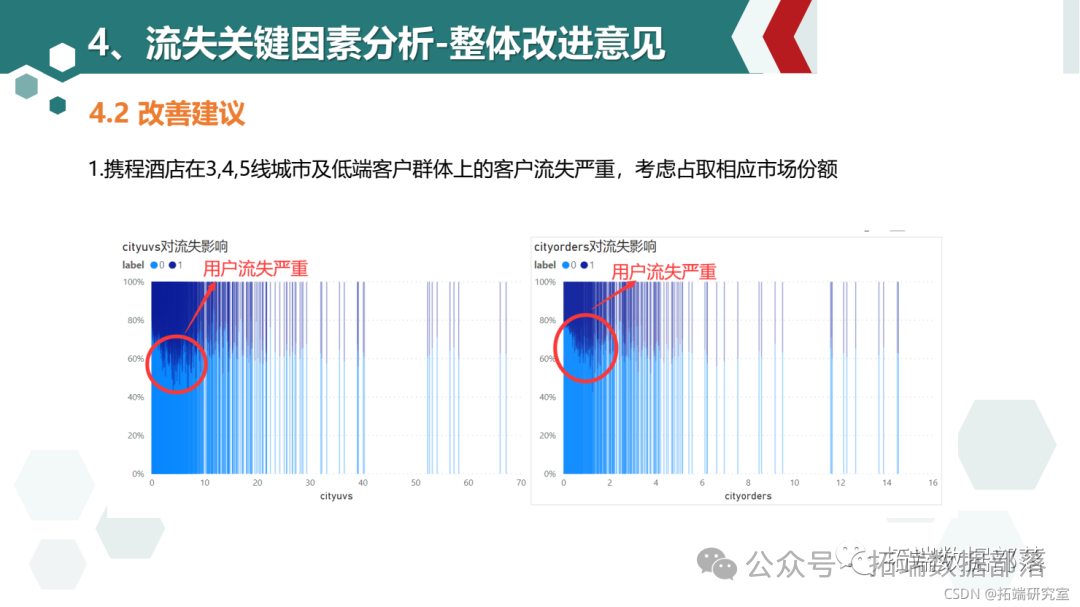
考虑占取三四线城市和低端酒店范围的市场份额
用户易受企业负面新闻影响,建议企业勇于承担社会责任,加强自身管理,提高公关新闻处理时效性,树立品牌良好形像
在节假日前2-3周开始热门景点酒店推送
做好酒店下单后的追踪体验,邀请填写入住体验,并整理用户意见作出改进
7 客户画像
7.1 建模用户分类
- # 用户画像特征
- user_feature = ["decisiohabit_user,'starprefer','lastpvgap','sid',
- 'lernum",'historyvisit_visit_detaipagenum',
- "onyear_dealrat
- ]
- # 流失影响特征
- fea_lis = ["cityuvs",
- "cityorders",
- "h",
- "businessrate_pre2"
- # 数据标准化 Kmeans方法对正态分布数据处理效果更好
- scaler = StanardScalr()
- lo_atribues = pdDatarame(scr.fittransfrm(all_cte),columns=all_ce.coluns)
- # 建模分类
- Kmens=Means(n_cluste=2,rndom_state=0) #333
- Keans.fi(lot_attributes # 训练模型
- k_char=Kmenscluster_centers_ # 得到每个分类
- plt.figure(figsize=(5,10))

7.2 用户类型占比
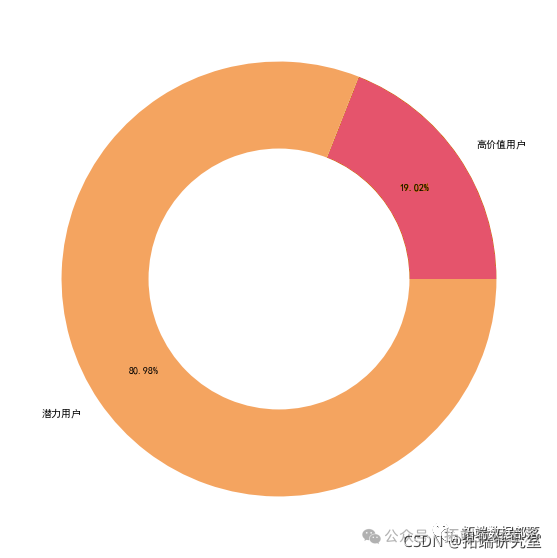
- types=['高价值用户','潜力用户']
- ax.pie[1], raius=0.,colors='w')
- plt.savefig(用户画像.jpg'dpi=400, box_inchs='tigh')
7.3 高价值用户分析
占比19.02,访问频率和预定频率都较高,消费水平高,客户价值大,追求高品质,对酒店星级要求高,客户群体多集中在老客户中,
建议:
多推荐口碑好、性价比高的商务酒店连锁酒店房源吸引用户;
在非工作日的11点、17点等日间流量小高峰时段进行消息推送。
为客户提供更多差旅地酒店信息;
增加客户流失成本:会员积分制,推出会员打折卡
7.4 潜力用户分析
占比:80.98% 访问频率和预定频率都较低,消费水平较低,对酒店星级要求不高,客户群体多集中在新客户中,客户价值待挖掘 建议:
因为新用户居多,属于潜在客户,建议把握用户初期体验(如初期消费有优惠、打卡活动等),还可以定期推送实惠的酒店给此类用户,以培养用户消费惯性为主;
推送的内容应多为大减价、大酬宾、跳楼价之类的;
由于这部分用户占比较多,可结合该群体流失情况分析流失客户因素,进行该群体市场的开拓,进一步进行下沉分析,开拓新的时长。
关于分析师

Xinyao Yi是拓端研究室(TRL) 的研究员。在此对她对本文所作的贡献表示诚挚感谢,她在UC San Diego完成了 计算机社会科学专业的硕士学位,专注数据处理、统计建模、机器学习领域。擅长R语言、Python、SQL、SPSS、Stata。
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《【视频讲解】逻辑回归原理及R语言预测心脏病、用户流失数据挖掘2实例》。
点击标题查阅往期内容
R语言线性混合效应模型(固定效应&随机效应)和交互可视化3案例
生态学模拟对广义线性混合模型GLMM进行功率(功效、效能、效力)分析power analysis环境监测数据
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
如何用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据



![]()


