
- 1三.ubuntu中安装RabbitMQ_ubuntu 下安装rabbitmq3.13.4
- 2大语言模型智能体(LLM Agents)入门指南
- 3总结一下:运维工程师面试的经历及面试相关问题_移动网络运维面试
- 4人工智能学习笔记(一)Agent_简单反射agent
- 5Flutter 学习步骤_flutter学习顺序
- 6java八股面试文(带答案,万字总结,精心打磨,建议收藏)堪称2024最强_java面试八股文
- 7vscode与vs for Mac有兼容问题!关于vs扩展商店无法连接且非网络端口问题的解决心得。所谓的鱼和熊掌不能兼得!_苹果电脑vscode兼容性
- 82020形式化方法复习笔记_消去是e还是i
- 9在项目如何解除idea和Git的绑定_idea项目取消git关联
- 10watchOS 2教程(一):开始吧_ios开发 iphone app 启动 watchos
GCN实战_gcn代码实战
赞
踩
参考材料:深入浅出图神经网络(李牧),教材参考源码
数据集:cora
主要工作:通过GCN实现对节点的分类
整个流程:处理数据(加载和预处理)->定义图卷积层–>定义图卷积神经网络–>训练–>测试–>可视化
主要学会掌握图卷积神经网络的定义,训练以及测试过程。
Cora数据集
1、ind.cora.x : 训练集节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为: (140, 1433)
2、ind.cora.tx : 测试集节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为: (1000, 1433) 3、ind.cora.allx : 包含有标签和无标签的训练节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为:(1708, 1433),可以理解为除测试集以外的其他节点特征集合,训练集是它的子集
4、 ind.cora.y : one-hot表示的训练节点的标签,保存对象为:numpy.ndarray
5、 ind.cora.ty : one-hot表示的测试节点的标签,保存对象为:numpy.ndarray
6、 ind.cora.ally : one-hot表示的 ind.cora.allx对应的标签,保存对象为:numpy.ndarray
7、 ind.cora.graph : 保存节点之间边的信息,保存格式为:{ index : [ index_of_neighbor_nodes ] }
8、 ind.cora.test.index : 保存测试集节点的索引,保存对象为:List,用于后面的归纳学习设置。
实战
首先我们定义类CoraData来对数据进行预处理,主要包括下载数据、规范化数据并进
行缓存以备重复使用。最终得到的数据形式包括如下几个部分:
·x:节点特征,维度为2808×1433;
·y:节点对应的标签,包括7个类别;
·adjacency:邻接矩阵,维度为2708×2708,类型为scipy.sparse.coo_matrix;
·train_mask、val_mask、test_mask:与节点数相同的掩码,用于划分训练集、验证集、测试集。
准备工作:
#导入必要的库 import itertools import os import os.path as osp import pickle import urllib from collections import namedtuple import numpy as np import scipy.sparse as sp #邻接矩阵用稀疏矩阵形式存储 节省空间 import torch import torch.nn as nn #搭建各个层的模块 import torch.nn.functional as F #实现好的函数,可以直接调用(激活函数) import torch.nn.init as init #初始化 import torch.optim as optim #优化算法 import matplotlib.pyplot as plt #可视化工具 %matplotlib inline

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Coradata类定义:(数据的导入,预处理工作)
遇到的问题:
1、 data = urllib.request.urlopen(url)
在进行数据下载时,会出现UrlloadError,原因尚不明确,可能是因为网络不稳定造成连接失败,解决方法,是将数据集下载到本地文件夹中,不使用python中的urllib.request.urlload()进行下载,这部分我还没有解决。
2、数据格式转换问题

书中代码使用的是python3.6环境,与python3.7环境有所不同。在3.7中bool类型的ndarry不能转换,因此在进行初始换定义时,要定义成uint8类型。
#用于保存处理好的数据 Data = namedtuple('Data', ['x', 'y', 'adjacency', 'train_mask', 'val_mask', 'test_mask']) def tensor_from_numpy(x, device): #将数据从数组格式转换为tensor格式 并转移到相关设备上 return torch.from_numpy(x).to(device) class CoraData(object): #数据集下载链接 download_url = "https://github.com/kimiyoung/planetoid/raw/master/data" #数据集中包含的文件名 filenames = ["ind.cora.{}".format(name) for name in ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']] def __init__(self, data_root="cora", rebuild=False): """Cora数据,包括数据下载,处理,加载等功能 当数据的缓存文件存在时,将使用缓存文件,否则将下载、进行处理,并缓存到磁盘 处理之后的数据可以通过属性 .data 获得,它将返回一个数据对象,包括如下几部分: * x: 节点的特征,维度为 2708 * 1433,类型为 np.ndarray * y: 节点的标签,总共包括7个类别,类型为 np.ndarray * adjacency: 邻接矩阵,维度为 2708 * 2708,类型为 scipy.sparse.coo.coo_matrix * train_mask: 训练集掩码向量,维度为 2708,当节点属于训练集时,相应位置为True,否则False * val_mask: 验证集掩码向量,维度为 2708,当节点属于验证集时,相应位置为True,否则False * test_mask: 测试集掩码向量,维度为 2708,当节点属于测试集时,相应位置为True,否则False Args: ------- data_root: string, optional 存放数据的目录,原始数据路径: {data_root}/raw 缓存数据路径: {data_root}/processed_cora.pkl rebuild: boolean, optional 是否需要重新构建数据集,当设为True时,如果存在缓存数据也会重建数据 """ self.data_root = data_root save_file = osp.join(self.data_root, "processed_cora.pkl")#拼接,即将数据集保存到.cora/processed_cora.pkl if osp.exists(save_file) and not rebuild: #使用缓存数据 print("Using Cached file: {}".format(save_file)) self._data = pickle.load(open(save_file, "rb")) else: self.maybe_download() #下载或使用原始数据集 self._data = self.process_data() #数据预处理 with open(save_file, "wb") as f: #把处理好的数据保存为缓存文件.pkl 下次直接使用 pickle.dump(self.data, f) print("Cached file: {}".format(save_file)) @property def data(self): """返回Data数据对象,包括x, y, adjacency, train_mask, val_mask, test_mask""" return self._data def process_data(self): """ 处理数据,得到节点特征和标签,邻接矩阵,训练集、验证集以及测试集 引用自:https://github.com/rusty1s/pytorch_geometric """ print("Process data ...") #读取下载的数据文件 _, tx, allx, y, ty, ally, graph, test_index = [self.read_data( osp.join(self.data_root, "raw", name)) for name in self.filenames] train_index = np.arange(y.shape[0]) #训练集索引(训练节点数) val_index = np.arange(y.shape[0], y.shape[0] + 500)#验证集索引(选择500个验证集) sorted_test_index = sorted(test_index) #测试集索引 #np.concatenate表示拼接成一个新的array,axis=0,行的增加或减少 #axis=0,对行进行操作,axis=1对列进行操作 x = np.concatenate((allx, tx), axis=0) #节点特征 N*D 2708*1433, y = np.concatenate((ally, ty), axis=0).argmax(axis=1)#节点对应的标签 2708,按列找出最大值的标签 x[test_index] = x[sorted_test_index] y[test_index] = y[sorted_test_index] num_nodes = x.shape[0] #节点数/数据量 2708 #训练、验证、测试集掩码 #初始化为0 train_mask = np.zeros(num_nodes, dtype=np.uint8) val_mask = np.zeros(num_nodes, dtype=np.uint8) test_mask = np.zeros(num_nodes, dtype=np.uint8) #划分训练集测试集以及验证集 train_mask[train_index] = True val_mask[val_index] = True test_mask[test_index] = True #构建邻接矩阵 adjacency = self.build_adjacency(graph) print("Node's feature shape: ", x.shape) #(N*D) print("Node's label shape: ", y.shape)#(N,) print("Adjacency's shape: ", adjacency.shape) #(N,N) #训练、验证、测试集各自的大小 print("Number of training nodes: ", train_mask.sum()) print("Number of validation nodes: ", val_mask.sum()) print("Number of test nodes: ", test_mask.sum()) return Data(x=x, y=y, adjacency=adjacency, train_mask=train_mask, val_mask=val_mask, test_mask=test_mask) def maybe_download(self): #原始数据保存路径 save_path = os.path.join(self.data_root, "raw")#cora\raw #下载相应的文件 for name in self.filenames: if not osp.exists(osp.join(save_path, name)):#如果cora\raw\name文件不存在,则保存 self.download_data( "{}/{}".format(self.download_url, name), save_path) @staticmethod def build_adjacency(adj_dict): """根据下载的邻接表创建邻接矩阵""" edge_index = [] num_nodes = len(adj_dict) for src, dst in adj_dict.items(): edge_index.extend([src, v] for v in dst) edge_index.extend([v, src] for v in dst) # 去除重复的边 edge_index = list(k for k, _ in itertools.groupby(sorted(edge_index))) edge_index = np.asarray(edge_index) #稀疏矩阵 存储非0值 节省空间 adjacency = sp.coo_matrix((np.ones(len(edge_index)), (edge_index[:, 0], edge_index[:, 1])), shape=(num_nodes, num_nodes), dtype="float32") return adjacency @staticmethod def read_data(path): """使用不同的方式读取原始数据以进一步处理""" name = osp.basename(path)#等同于os.path.split(url)[-1] if name == "ind.cora.test.index":#文件形式为List out = np.genfromtxt(path, dtype="int64")#从path中加载数据 return out else: out = pickle.load(open(path, "rb"), encoding="latin1") out = out.toarray() if hasattr(out, "toarray") else out return out @staticmethod def download_data(url, save_path): """数据下载工具,当原始数据不存在时将会进行下载""" if not os.path.exists(save_path):#不存在路径,则新建路径cora\raw os.makedirs(save_path) data = urllib.request.urlopen(url)# filename = os.path.split(url)[-1]#取最后一个name with open(os.path.join(save_path, filename), 'wb') as f:#读入文件cora\raw\name f.write(data.read()) return True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
图卷积层的建立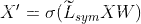
遇到的问题:
1、初始化问题:

- nn.Parameter继承自torch.Tensor的子类,用于定义一个可训练数据,自动认为是module的可训练参数。会被加入到parameter迭代器中进行更新。可以将其看作是一个类型转换函数,将数据从不可训练的tensor,转换到可训练的Parameter
- init.kaiming_uniform_(self.weight)#使用正态分布初始化权重参
init.zeros_(self.bias)#初始化为0
class GraphConvolution(nn.Module): def __init__(self, input_dim, output_dim, use_bias=True): """图卷积:L*X*\theta Args: ---------- input_dim: int 节点输入特征的维度 D output_dim: int 输出特征维度 D‘ use_bias : bool, optional 是否使用偏置 """ super(GraphConvolution, self).__init__() self.input_dim = input_dim self.output_dim = output_dim self.use_bias = use_bias #定义GCN层的权重矩阵 self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim)) if self.use_bias: self.bias = nn.Parameter(torch.Tensor(output_dim)) else: self.register_parameter('bias', None) #使用自定义的参数初始化方式 self.reset_parameters() def reset_parameters(self): #自定义参数初始化方式 #权重参数初始化方式 init.kaiming_uniform_(self.weight)#使用正态分布初始化权重参数 if self.use_bias: #偏置参数初始化为0 init.zeros_(self.bias) def forward(self, adjacency, input_feature): """邻接矩阵是稀疏矩阵,因此在计算时使用稀疏矩阵乘法 Args: ------- adjacency: torch.sparse.FloatTensor 邻接矩阵 input_feature: torch.Tensor 输入特征 """ support = torch.mm(input_feature, self.weight) #XW (N,D');X (N,D);W (D,D') output = torch.sparse.mm(adjacency, support) # A(N,N),s(N,D')->(N,D') if self.use_bias: output += self.bias return output def __repr__(self): return self.__class__.__name__ + ' (' \ + str(self.input_dim) + ' -> ' \ + str(self.output_dim) + ')'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
模型定义(两层图卷积)
class GcnNet(nn.Module):
#定义一个两层的模型
def __init__(self, input_dim=1433):
super(GcnNet, self).__init__()#父类初始化
self.gcn1 = GraphConvolution(input_dim, 16)
self.gcn2 = GraphConvolution(16, 7)
def forward(self, adjacency, feature):
h = F.relu(self.gcn1(adjacency, feature))
logits = self.gcn2(adjacency, h)
return logits
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
模型训练
# 超参数定义
LEARNING_RATE = 0.1 #学习率
WEIGHT_DACAY = 5e-4 #正则化系数
EPOCHS = 200 #完整遍历训练集的次数
DEVICE = "cuda" if torch.cuda.is_available() else "cpu" #设备
- 1
- 2
- 3
- 4
- 5
# 加载数据,并转换为torch.Tensor dataset = CoraData().data node_feature = dataset.x / dataset.x.sum(1, keepdims=True) # 归一化数据,使得每一行和为1 tensor_x = tensor_from_numpy(node_feature, DEVICE) tensor_y = tensor_from_numpy(dataset.y, DEVICE) tensor_train_mask = tensor_from_numpy(dataset.train_mask, DEVICE) tensor_val_mask = tensor_from_numpy(dataset.val_mask, DEVICE) tensor_test_mask = tensor_from_numpy(dataset.test_mask, DEVICE) normalize_adjacency = CoraData.normalization(dataset.adjacency) # 规范化邻接矩阵L num_nodes, input_dim = node_feature.shape #(N,D) #转换为稀疏表示 加速运算 节省空间 indices = torch.from_numpy(np.asarray([normalize_adjacency.row, normalize_adjacency.col]).astype('int64')).long() values = torch.from_numpy(normalize_adjacency.data.astype(np.float32)) tensor_adjacency = torch.sparse.FloatTensor(indices, values, (num_nodes, num_nodes)).to(DEVICE)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
# 模型定义:Model, Loss, Optimizer
model = GcnNet(input_dim).to(DEVICE) #如果gpu>1 用DataParallel()包裹 单机多卡 数据并行
criterion = nn.CrossEntropyLoss().to(DEVICE) #多分类交叉熵损失
optimizer = optim.Adam(model.parameters(),
lr=LEARNING_RATE,
weight_decay=WEIGHT_DACAY) #Adam优化器
- 1
- 2
- 3
- 4
- 5
- 6
# 训练主体函数 def train(): #记录损失函数和准确率 loss_history = [] val_acc_history = [] model.train() #训练模式 train_y = tensor_y[tensor_train_mask] #训练节点的标签 for epoch in range(EPOCHS): #完整遍历一遍训练集 一个epoch做一次更新 logits = model(tensor_adjacency, tensor_x) # 所有数据前向传播 train_mask_logits = logits[tensor_train_mask] # 只选择训练节点进行监督 loss = criterion(train_mask_logits, train_y) # 计算损失值 #优化 optimizer.zero_grad() #清空梯度 loss.backward() # 反向传播计算参数的梯度 optimizer.step() # 使用优化方法进行梯度更新 train_acc, _, _ = test(tensor_train_mask) # 计算当前模型训练集上的准确率 val_acc, _, _ = test(tensor_val_mask) # 计算当前模型在验证集上的准确率 # 记录训练过程中损失值和准确率的变化,用于画图 loss_history.append(loss.item()) val_acc_history.append(val_acc.item()) print("Epoch {:03d}: Loss {:.4f}, TrainAcc {:.4}, ValAcc {:.4f}".format( epoch, loss.item(), train_acc.item(), val_acc.item())) return loss_history, val_acc_history
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
# 测试函数
def test(mask):
model.eval() #测试模式
with torch.no_grad(): #关闭求导
logits = model(tensor_adjacency, tensor_x) #所有数据作前向传播
test_mask_logits = logits[mask] #取出相应数据集对应的部分
predict_y = test_mask_logits.max(1)[1] #按行取argmax 得到预测的标签
accuarcy = torch.eq(predict_y, tensor_y[mask]).float().mean() #计算准确率
return accuarcy, test_mask_logits.cpu().numpy(), tensor_y[mask].cpu().numpy() #numpy(),该方法主要用于将cpu上的tensor转为numpy数据。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
#可视化训练集损失和验证集准确率变化 def plot_loss_with_acc(loss_history, val_acc_history): fig = plt.figure() ax1 = fig.add_subplot(111) ax1.plot(range(len(loss_history)), loss_history, c=np.array([255, 71, 90]) / 255.) plt.ylabel('Loss') ax2 = fig.add_subplot(111, sharex=ax1, frameon=False) ax2.plot(range(len(val_acc_history)), val_acc_history, c=np.array([79, 179, 255]) / 255.) ax2.yaxis.tick_right() ax2.yaxis.set_label_position("right") plt.ylabel('ValAcc') plt.xlabel('Epoch') plt.title('Training Loss & Validation Accuracy') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
主函数
训练
loss, val_acc = train()#每个epoch 模型在训练集上的loss 和验证集上的准确率
- 1
- 2
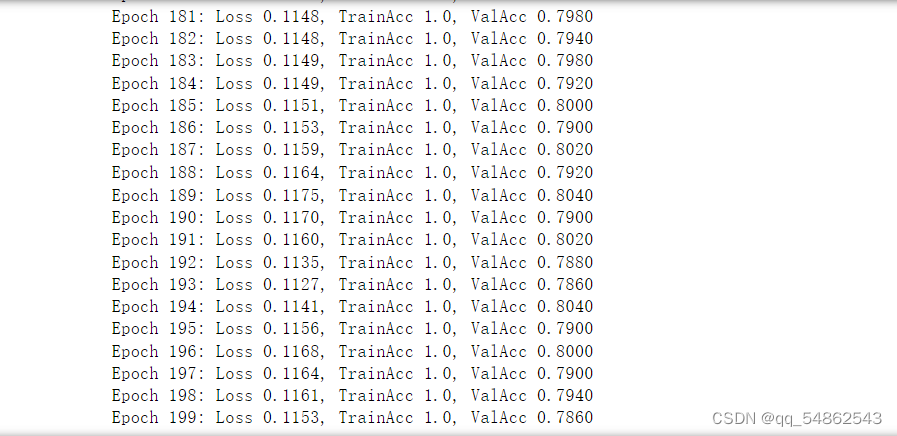
测试
test_acc, test_logits, test_label = test(tensor_test_mask)
print("Test accuarcy: ", test_acc.item())
- 1
- 2
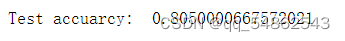
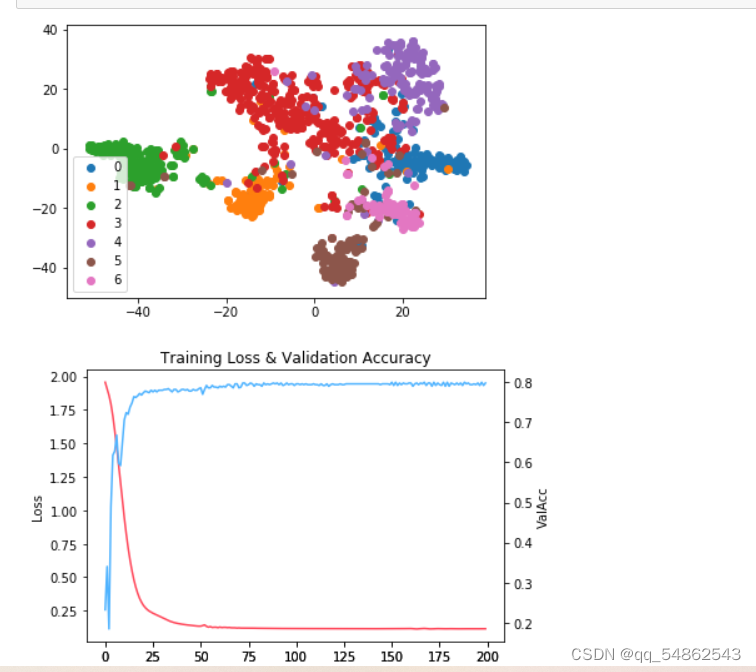
可视化
# 绘制测试数据的TSNE降维图
from sklearn.manifold import TSNE
tsne = TSNE()
out = tsne.fit_transform(test_logits)
fig = plt.figure()
for i in range(7):
indices = test_label == i
x, y = out[indices].T
plt.scatter(x, y, label=str(i))
plt.legend()
plot_loss_with_acc(loss, val_acc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- HTML代码[详细] -->
赞
踩

