
- 1二叉树--C语言实现数据结构_c语言写二叉树
- 2Python OS库使用详解_pycharm os
- 3二叉树的层序遍历 + 通过层序遍历实现二叉树的操作_按照层数遍历二叉树
- 4java面试题(上)_一年java面试
- 5GNN 2021(三) Boost then Convolve: Gradient Boosting Meets Graph Neural Networks,ICLR
- 6Linux NFS服务_nfs gid uid
- 7python数据分析——用jieba和词云做知乎的数据分析_mytext=''.join(jieba.cut(mytext))
- 8FAST_LIO_SAM 融入后端优化的FASTLIO SLAM 系统 前端:FAST_LIO2 后端:LIO_SAM_fast lio sam
- 9Python——列表(list)推导式_python列表推导式
- 10Opencv cuda版本编译
TDengine 3.0:核心代码全部开源,企业版价值何在?_tdengine开源版可以商用吗
赞
踩
在 8 月 13 日的 TDengine 开发者大会上,TDengine 联合创始人侯江燚带来题为《核心代码全部开源,企业版价值何在》的主题演讲,为大家讲解了 TDengine 3.0 企业版对工业互联网边云协同的助力,同时分享了自己对于开源商业化的理解。本文根据此演讲整理而成。
点击【这里】查看完整演讲视频
在物联网海量设备数据场景下,关系型数据库、传统工业实时库、Hadoop 大数据平台、NoSQL 数据库都暴露出了不一而足的痛点问题,严重限制企业业务规模化发展。
- 关系型数据库:存在海量时序数据读写性能低、分布式支持差、数据量越大查询越慢、报表分析慢等问题
- 传统工业实时库:主备架构,不易水平扩展,且依赖 Windows 等环境,生态相对封闭
- Hadoop 大数据平台:组件多而杂、架构臃肿,支持分布式但单节点效率低,硬件及人力成本非常高
- NoSQL 数据库:实时性差,大数据量查询慢,计算时内存、CPU开销巨大,无时序针对性优化
但即使是专为物联网时序场景而生的时序数据库(Time Series Database,TSDB),也并没有完全解决掉这些数据处理难题,仍存在“系统复杂运维难度大”、“非标准 SQL 学习成本高”、“没有真正云原生化水平扩展能力有限”等难以忽视的问题。
在调研了数百个业务场景的基础上,从解决上述企业痛点问题角度出发,TDengine 完成了 3.0 版本的迭代,不仅从“云就绪”升级成为一款真正的云原生时序数据库,还是一款极简的时序数据处理平台,打造了全新的流式计算引擎,无需再集成 Kafka、Redis、Spark、Flink 等软件,大幅降低系统架构的复杂度。同时,3.0 还将存储引擎、查询引擎都进行了优化升级,进一步提升了存储和查询性能。
目前 TDengine 3.0 的代码已经在 GitHub 上开放,欢迎大家下载、体验。下面我将会就 3.0 企业级工具助力工业互联网边云协同的实现路径这一话题进行分享,同时将从开源商业化角度,让大家更加深入地了解 TDengine 企业版的价值。
工业赋能,从边到云

在工业互联网场景中,边缘设备只能处理局部数据,无法形成全局认知,在实际应用中仍然需要借助云计算平台来实现信息的融合。在此背景下,边云协同正逐渐成为支撑工业互联网发展的重要支柱。
边云协同主要是对于生产链条上的某一项或某几项数据,进行实时告警、实时大屏监测,比如车间里实时生产的数据。同时还会将这些边缘侧生产的数据及时同步到云上大数据平台。
虽然边缘侧对实时性的要求是最高的,但其数据量并不大,可能一个车间只有小到几千或大到几万个监测点需要存储。而集团侧汇聚了更多的计算资源,比如在这一侧可以搭建一个私有云,那它就会把边缘侧的数据也收集过来,专门用来做一些计算。如果我们训练好一个模型,再把这个模型下发到边缘侧,在边缘侧就能进行更多预测性的分析。因此,边云协同的整体逻辑就是,实时报警收集到边缘侧产生的数据,云上训练好模型再下发下去,如此循环反复。
而要实现这一操作,对数据库或者说对数据存储层的要求就是要确保数据能够逐级上报,以及数据有选择性的上报。在有些场景中,整体数据总量非常大,我们需要有选择地从底层往上层去汇报数据,比如对一开始一秒采一次的原始记录,可能需要降采样到一分钟采一次,这种降采样的数据仍然可以保留一定的信息,可用于跑批分析长期数据。

以 TDengine 为例,我们举一个具体的实例。在此前的老数采流程中,数据是从工业逻辑控制器 PLC 中采集,之后进入 Historian,即工业实时库,然后再支撑业务应用。这种操作存在三个缺点:主备架构,不易水平扩展;依赖 Windows 等环境;生态相对封闭。
后面 TDengine 在边缘侧替换了原有单机版的 Historian 数据库。现在的一个设计思路就是采集数据从 PLC 通过 OPC Server,接入到 TDengine 当中,而 TDengine 本身在车间侧就可以支撑实时的业务,同时包括一些实时报警、实时大屏等需求。企业可以利用 TDengine 提供的边云协同能力,把数据发送到云上的大数据平台中。
边云协同实现的关键,TDengine 3.0 企业级工具 taosX
让 TDengine 实现边云协同能力的一个关键就是 TDengine 3.0 发布的企业级工具 taosX,它具有以下五点特性:
- 百万条/秒同步效率
- 可配置的同步规则
- 实时流计算结果同步
- 支持重新订阅,断点续传
- 历史数据迁移
在 2.0 版本中,数据订阅的实现路径是在数据写入后,通过轮询方式将数据订阅出来,本质上可以解决大部分问题,但仍然还有优化的空间。因为 WAL 本身就是支持订阅的,在 3.0 中,我们把 WAL 重新进行了升级,可以订阅所有的写入、更新甚至删除操作,只要是对数据库的操作都可以订阅。
通过 TDengine 订阅方式,企业可以实现边到云的实时同步数据,订阅方式允许设置筛选条件,可以有选择性地同步数据,同时,订阅发起方还能够主动配置订阅对象和数据过滤规则。这样就很好地保证了所有数据都可以从一个集群同步到第二个集群,包括离线乱序数据,这也是 taosX 做的最重要的一个事情,它可以支持实时的数据同步,包括离线的增量备份、边端到云端的数据协同。
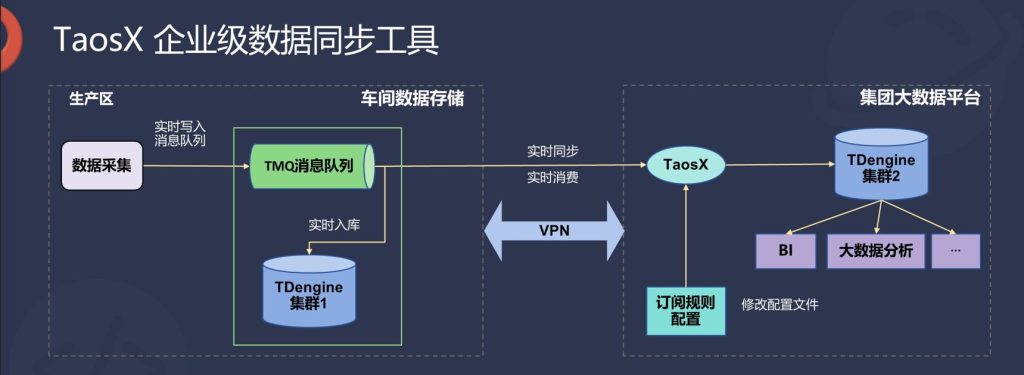
TDengine 3.0 利用 taosX 实现边云协同的思路如下:在车间侧,数据采集完成之后会进入 TDengine,首先经过 TMQ 消息队列,其中一部分数据有选择性地并入到本地的 TDengine 集群 1 中。之后我们可以在集团侧部署 taosX ,它会去订阅车间侧 TMQ 消息队列中的数据,为了达成业务需求,可能这里需要由数据分析工程师设置一些订阅规则,比如数据需要经过降采样再进来或者只关心阈值超过定值的数据。之后 taosX 会把数据同步到 TDengine 集群 2,集群 2 可以支持报表分析等更大维度的分析工作。
该实现思路主要有以下四点优势:
- 数据跨区同步自动化程度大大提高、错误率降为零
- 数据无需缓存,减少批量发送,避免流量高峰阻塞带宽
- 通过订阅方式同步数据,集团不再依赖下级单位配置同步规则
- 边云均采用 TDengine,数据模型完全统一,降低数据治理难度
要知道,制造业企业通常面临的一个痛点问题就是数据同步的问题,业内通常都是离线传输数据,比如积攒一个星期,一下传一个 T 的数据,要么人拿着移动硬盘去现场拷,浪费人力成本;要么开 VPN 专线定期同步,将数据导出成压缩文件进行传输,但这种情况 VPN 都会出现一些短暂带宽的阻塞,对其他业务生产产生一定冲击。TDengine 3.0 的企业级工具 taosX 实现了数据的实时同步,并且是可配置的,而自动化数据同步是实现边云协同的最好思路,避免了定期传输大数据量,导致的资源浪费和带宽阻塞风险。

此外,由于边端和云端都是通过 TDengine 去存储数据,它的数据模型相对来说比较统一。之前我们遇到一些客户反馈痛点问题,他们在边缘侧搭建的工业实时库种类繁多,数据需要统一收集到平台侧,这时就需要把各个实时数据库里的数据模型进行归一化,比如平台侧通过单侧点抑或用多侧点方式去描述设备数据,这就需要投入很大的人力财力去做数据治理。
但是如果从 TDengine 到 TDengine,它的表结构和数据的设计模型完全不用变,因为边缘侧和云上进行数据操作的方式都是一致的。从车间侧到集控中心,再从集控中心到整个集团的云平台,TDengine 3.0 实现了数据的多级同步。
从企业级工具聊聊开源的商业模式
When we call software “free,” we mean that it respects the users’ essential freedoms: the freedom to run it, to study and change it, and to redistribute copies with or without changes. This is a matter of freedom, not price, so think of “free speech,” not “free beer.”
– Richard Stallman
最后回归一下本次演讲的主题,和大家一起聊聊开源的商业模式。目前,TDengine 3.0 也已经在 GitHub 上开放了代码,从 2019 年 TDengine 宣布开源,到现在已经 3 年的时间了。开源的模式真正拉近了 TDengine 和一众开发者的距离,也让 TDengine 的每一次迭代创新都伴随着用户的声音。
我特别喜欢上面展示的自由软件 Free Software Foundation 的创始人 Richard Stallman 所说的那段话,“Open Source Is FREE”,但“FREE”并非代表着免费,而是自由。
以 TDengine 为例,任何人都可以以自己想要表现的形式,在遵守开源协议的前提下,可以复制改写 TDengine 的代码,但这并不代表它是一个“free beer”。开源的核心逻辑是向大家展示这个项目是自由的,只要你有兴趣你就可以参与进来,尽可能把自己的聪明才智融入到开源社区的建设中,而非简单地指“使用”。
做开源项目是一个既需要勇气也需要努力的事情,说实话我们也遇到过很多困境,比如在支持社区用户时遭遇的一些误解,个别用户可能会觉得你们团队是不是反应有点慢,但是其实真不是,我们真的已经投入很多了。TDengine 作为一个开源项目,不应该只有涛思数据一个团队在奋战,我们希望通过各种形式,让全球更多的开发者了解 TDengine,参与到 TDengine 的使用和开发之中,共建 TDengine 开源社区,这才是开源“free”的表现。
说回到主题,我认为开源的商业模式是必须且有理由存在的,因为公司要活下去,而公司本身就是一个以盈利为目的的团体。从过去到现在,开源的商业模式大致可以划分为以下 5 种路径:
- Donations 捐赠
- Hosted Service 托管服务
- Paid Support or Courses 付费支持或培训
- Open Core 开源核心,提供付费增强功能/工具
- Dual Licensing 双协议
TDengine 目前走的开源商业化道路就是“Open Core 开源核心,提供付费增强功能/工具”。我们的核心代码保证全部开源,用户可以去感受产品的价值,但同时我们会提供很多增强功能,比如一些能够升级数据备份、安全保障的工具。这些工具也需要投入很多精力和努力去进行研发,会作为一种增值方式提供给用户。
在对商业化不断探索的过程中,TDengine 也开发出了很多强大的辅助功能去服务用户,除了上文中提到的边云数据协同,还包括冷热数据自动分级存储、企业级可视化运维管理工具、支持快速删除(Delete)、支持多列输入用户自定义函数(UDF)、提供异地容灾、备份解决方案。
在保证系统稳定性和透明性上,TDengine 企业版也做了很多工作,通过设计更优的内存分配器、更稳健的版本迭代策略、更多的运维支持服务实现了更加优秀的稳定性,同时为了让用户用的放心,我们配套了监控 taosKeeper,能够对可观测性进行更详细的统计,它还可以无缝集成到 Prometheus 的监控系统中。
针对 TDengine 企业版,我们还提供了“保姆级”的专家技术服务,服务方式分为以下三类:
- 开发支持服务:包括产品使用培训、数据建模咨询、架构设计咨询、代码开发支持,比如说从 Kafka 接数据到 TDengine,如何做才是最高效的、如何去配置 Kafka 的参数,如何保证数据的有效性、时序性。这些支持能够帮助客户把 TDengine 的能力最大化发挥出来。
- 运维支持服务:不管是 TDengine 还是 Oracle,任何一款数据库到后期都需要一个强保护,在业务安全性要求下,数据的备份、迁移,系统的性能调优、高可用保障、7*24 故障恢复等等都需要一个强有力的支持。如果因手动迁移导致数据文件损坏,或者是因为一个错误导致数据难以恢复,给整个集团造成的损失可能不可估量。也因此,集团需要专业级的厂商去提供这些服务,这也是我们对企业级客户提供的价值。
- 定制化服务:包括定制化 PoC 测试服务、OEM 版本发行、定制化 UDF 开发、其他定制化开发服务。对一些用户而言,他可能想要让 TDengine 跑在自己开发的硬件上,那就需要我们协助他做一些 PoC 测试来适配这一硬件,而对于一些业务的复杂查询,我们也可以通过 UDF 方式去做定制化。通过定制化服务来赋能用户,支持他们将 TDengine 更加深入地融合到自身业务当中。
最后,给大家做一个预告,TDengine 的云服务升级版也将很快与大家正式见面。新的云服务基于 TDengine 3.0 云原生架构,不仅最大限度地实现了弹性扩容,还可以让用户按需去付费,不再因数据的增量或缩容频繁变动而受阻。同时这也是一个完全零管理、完全将后台托管给涛思业务团队的服务,支持多云且绝对保证数据备份和安全。
今天我的演讲就到这里,感谢大家。希望未来有越来越多的用户支持 TDengine 企业版,也能有越来越多的开发者加入 TDengine 的开源社区中来。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。

