
- 1用cpolar内网穿透进行网页测试
- 2c++ primary chapter 20
- 3解密Prompt系列9. 模型复杂推理-思维链COT基础和进阶玩法
- 4HDFS组成架构
- 5数据结构-顺序栈的基本操作的实现(含全部代码)_顺序栈的完整代码
- 6Android Studio中Gradle使用实例_androidstudio gradle命令使用
- 7Agent四大范式 | 综述:全面理解Agent工作原理_agent推理 io cot tot react
- 8Charles怎么修改参数
- 9书生大模型-入门岛3-Git 基础知识
- 10codeforces 985A Chess Placing_a. chess placing
Stable Diffusion从小白玩法到商业变现_stable diffusion变现
赞
踩

上篇我们讲到Midjourney这个AI出图神器,这期我们来继续聊聊另一款——Stable Diffusion。这项技术属于开源项目,更新快,安装免费,玩法多,也是目前AIGC用到的主要技术。具体的安装步骤这里就不讲了,网上资源很多,大家自行搜索,今天主要讲讲它的基础玩法以及商业变现的一些思路。文章稍长,大家可按需跳跃式阅读。
一、基本玩法
1、文生图及注意事项
这个比较简单,就是在tex2img这个选项卡这里,输入正反提示词,设置参数,点击Generate按钮后就能得到图片,下图是Stable Diffusion的生图界面。

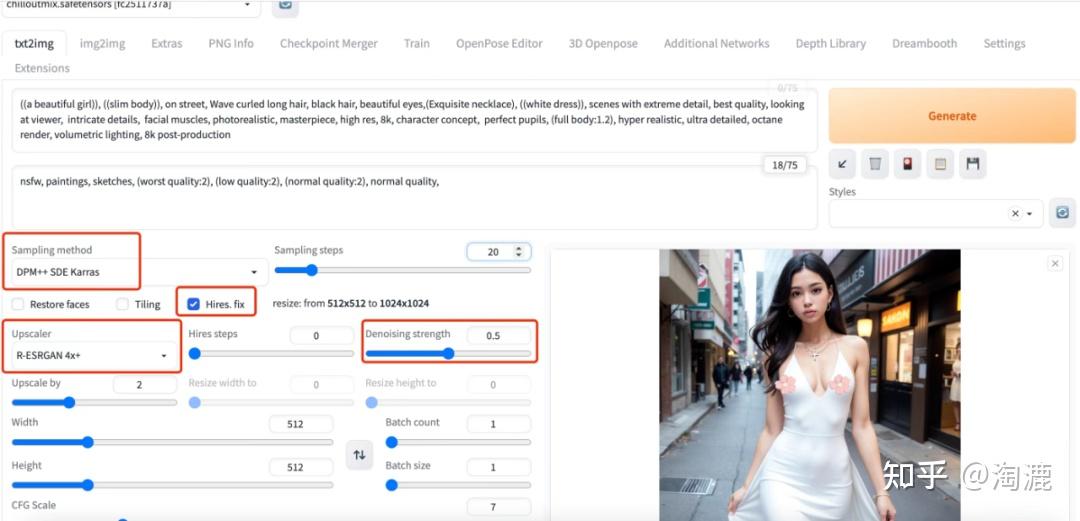
这里重点提示一下如何通过某几个参数的设置得到画质清晰的图片。第一次玩大家可能有这种体验,一般我们在选择基础模型,设置以上需要设置的内容后,生成的人物的脸总是模糊不清,或者直接崩掉,反正生成的效果跟Midjourney差得远。怎么解决这个问题呢?大家可能会想到调整采样步数,比如20调整到30步,步数越高画面调整的越精细嘛;Sampling method从默认的Eular a调整到DPM++ SDE Karras,但其实最终的效果依然不好。怎么办呢?
我们可以通过高清修复(Hires. fix)这个选项可以很好解决这个问题,并且把Denoising strength调整到0.5-0.7之间,Upscaler选择R-ESRGAN 4x+,最终的效果就好多了。以下是同一个大模型、同样的正反提示词,调整不同参数生成的图片对比,可以看出高清修复确实对模特的脸效果十分明显。顺便提一句,脸部修复的选项似乎对模特面部没什么用,没有高清修复好用。

左边是直接生成的,右边是高清修复的
以下是右边图片参数设置的截图,大家可以自己参照玩一玩。
2、图生图及注意事项
图生图,也就是说Stable Diffusion可以根据你上传的图片调整大模型或者参数后再次生成图片。例如,我想给一张写实的图片换一个二次元风格,调整基础大模型为二次元风格,输入正反提示词就可以得到以下效果。

另外图生图的高清修复需要在settings-upscaling这里设置,具体如下图:
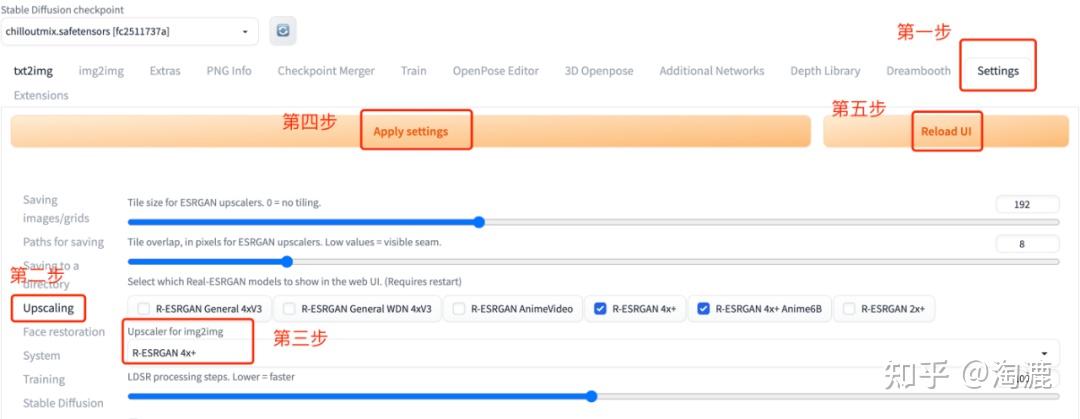
心细的小伙伴可能会问,大模型是什么,图片是怎么从写实风变成二次元或者漫画风的?别急,接着往下看⬇️
二、基础大模型及微调模型
1、基础大模型
一般我们下载完Stable Diffusion WebUI后都只有一个基础的大模型,偏写实风,也就是下面我截图的这个。

但是这个大模型比较单一,生成图片的风格也就一种,就像刚刚我们想要一个二次元,或者动漫、国风等等这些风格,就需要再去下载其他的大模型进行图片训练。
基础大模型我们可以去到C站,C站链接如下:https://civitai.com/。每个模型都有图片示例,大家可以选择自己喜欢的模型进行下载。
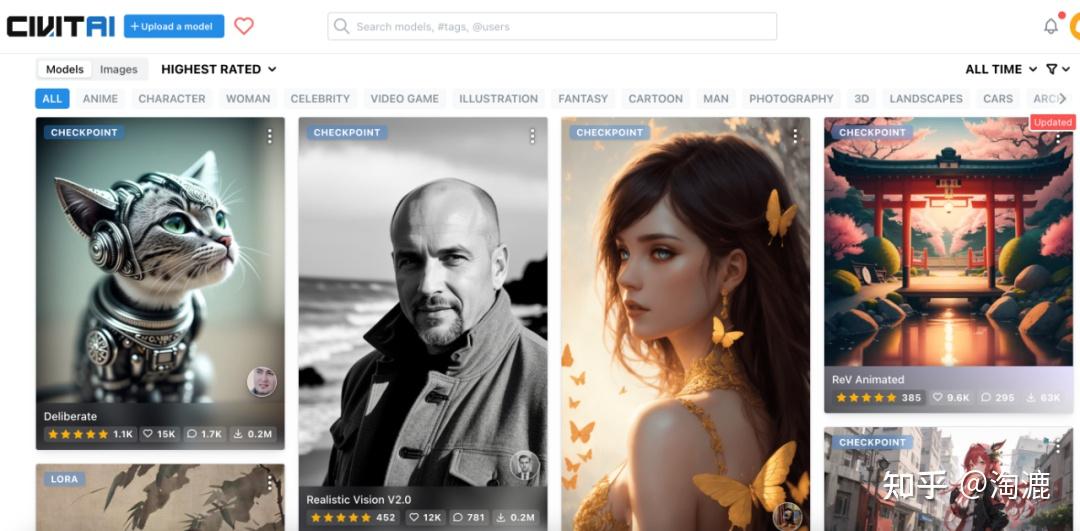
下载后的模型将其放在stable-diffusion-webui/models/Stable-diffusion/这个目录下,刷新模型这里就可以显示已经下载的模型了。
2、微调模型——Lora
除了基础大模型,还有比较火的微调模型可以下载使用,Lora可以理解为是基础大模型下的又一个小模型。比如一个写实风的模型,我想要小姐姐的脸各式各样,那就需要在写实风格大模型下有不同脸蛋的模型,最终才能生成不同的脸来。
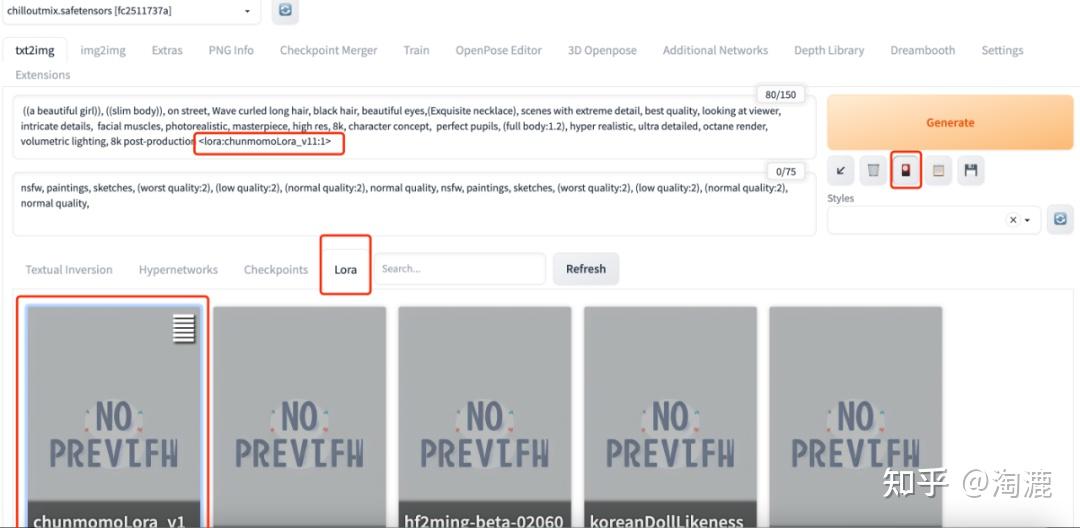
Lora模型可以在网上下载(还是上面提到的C站,带Lora标签的模型),或者是自己炼(此处不展开讲,可开篇另讲)。下载的模型安装在/stable-diffusion-webui/models/Lora路径下,然后重启Stable Diffusion WebUI,在文生图或图生图界面的生成按钮下,可以看到一个又红又白又黑的图标,该图标名为show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Lora选项卡,在这里可以看到已经安装的Lora模型,点击模型名称将会自动该角色名称加载到prompt文本框中。
以上是单个Lora模型的应用,如果我们想要多个Lora模型混合使用怎么办呢(比如多个明星的脸混合生成)?就需要额外下载一个插件——Additional Networks。
下载地址:https://github.com/kohya-ss/sd-webui-additional-networks。安装步骤:打开Extensions——点击install from URL——输入上面的下载地址——最后点击Install,最后重启WebUI就可以看到Additional Networks这个入口了。
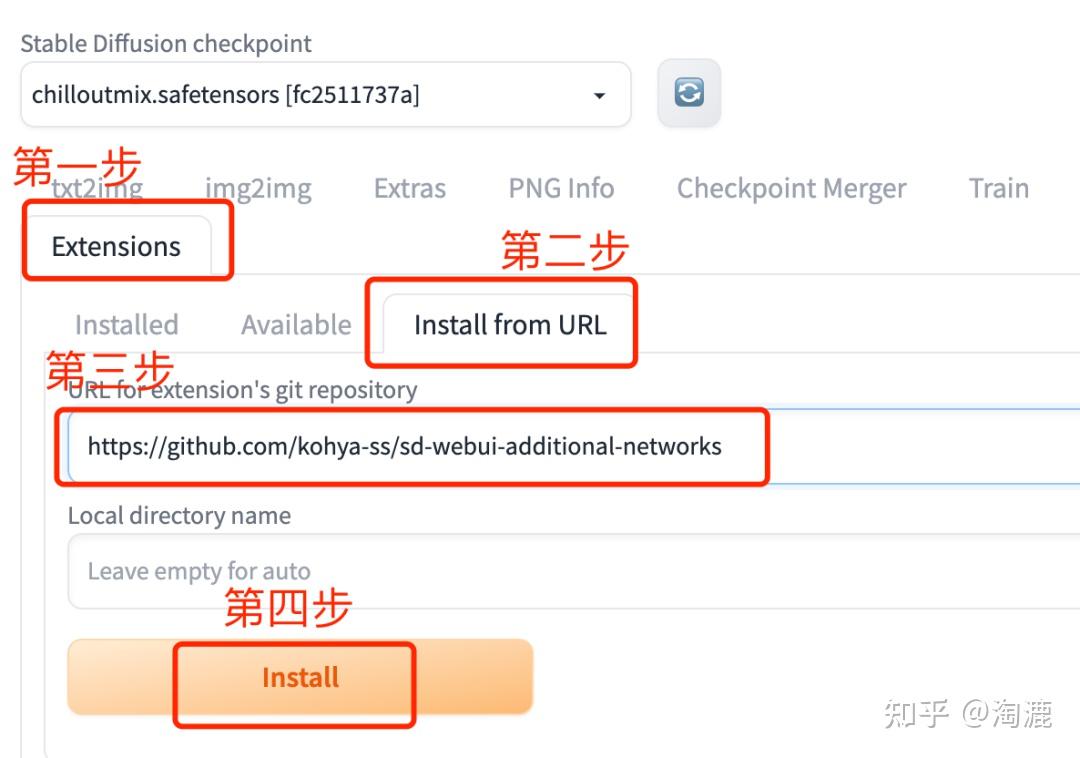
点击Additional Networks小三角可以设置不同的Lora模型的权重占比,下载的Lora模型记得放到/stable-diffusion-webui/sd-webui-additional-networks/models/LoRA这个目录下,这样在Model这里才能选到我们下载的Lora模型。
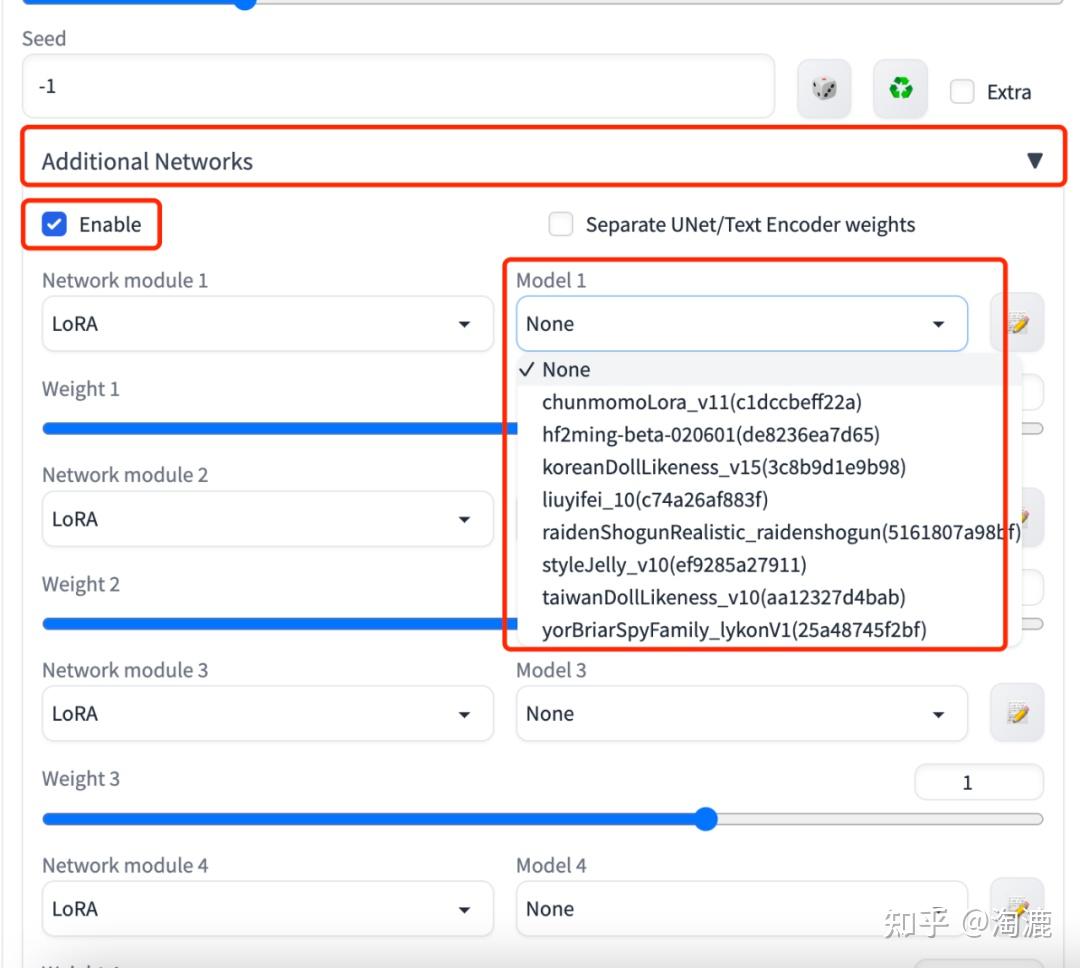
三、AI精准可控
相信大家玩了一段时间后也会发现,AI出图是能出,但是很多时候想象力太丰富,画面会跑飞,得不到自己想要的内容,怎么办呢?这里就必须讲到AI的精准可控,让AI更懂我们的需求。
1、控制AI动作
讲动作就必须讲到controlnet的openpose功能,有了这个功能我们就能让AI做出任何我们想要它做的动作啦~首先我们需要安装这个controlnet插件,下载和安装方法同Additional Networks,只是下载链接换成https://jihulab.com/hunter0725/sd-webui-controlnet,安装成功后就能在Additional Networks选项卡下面看到ControlNet这个选项卡了。
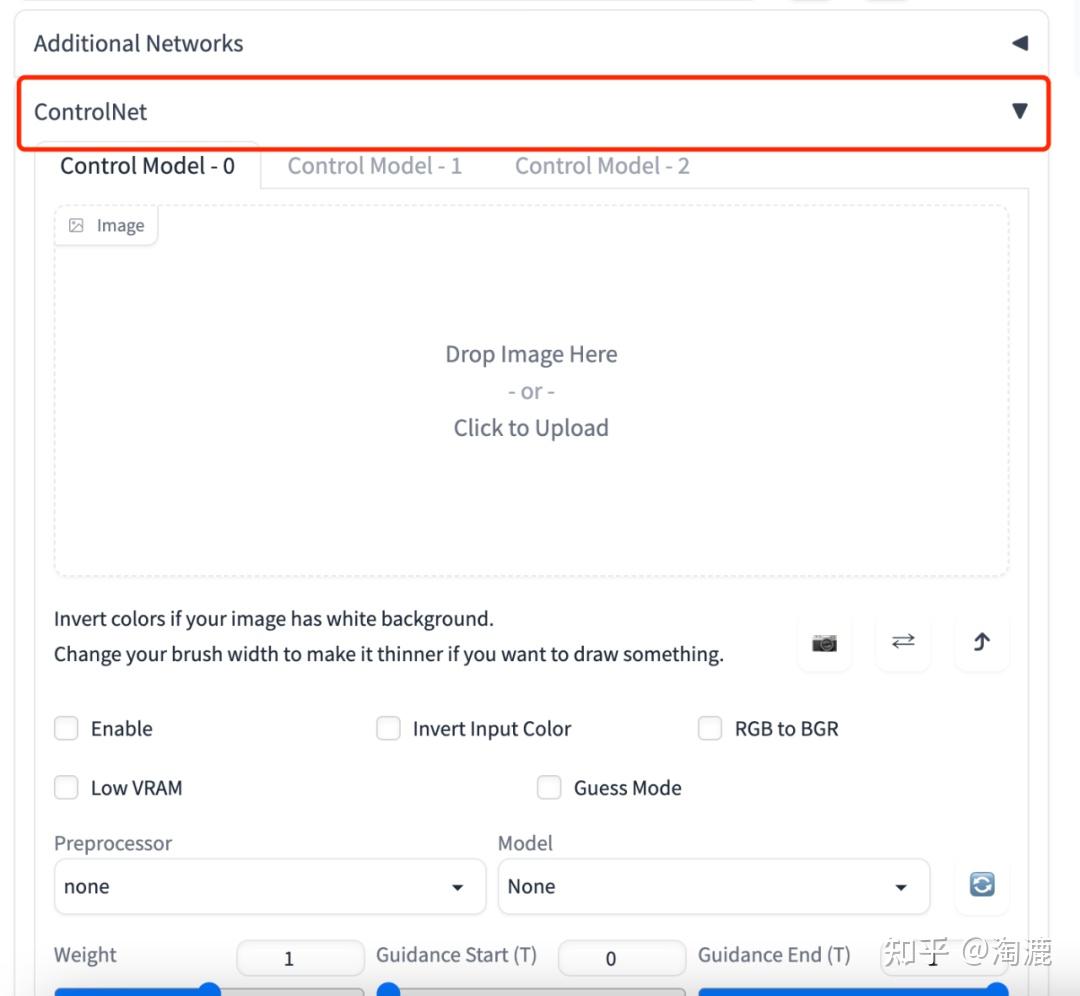
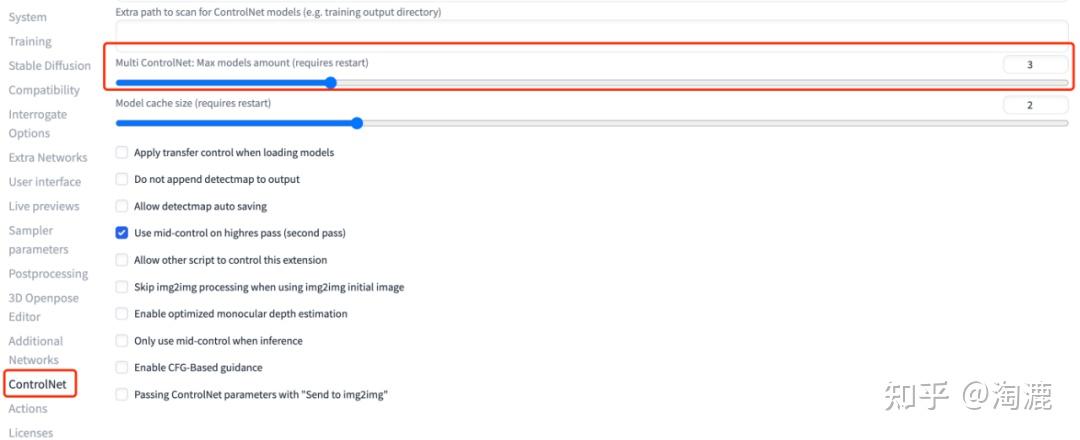
大家可能也看到了,我这里不止一个ControlNet,这是在setting——ControlNet这里设置的,需要几个就设置几个,一般3个够用,然后应用设置,重启UI。
当然有了ControlNet没有图形的构造方式,也到不到我们刚刚想要模特摆不同pose的目的,这个构造方式也就是我们说到的openpose之类的模型了。
下载地址:https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main。下载后的模型放在/stable-diffusion-webui/extensions/sd-webui-controlnet/models目录下。

处理好安装的工作后,我们就能看到我们想要的姿势控制模型了,按照下图提示设置好。
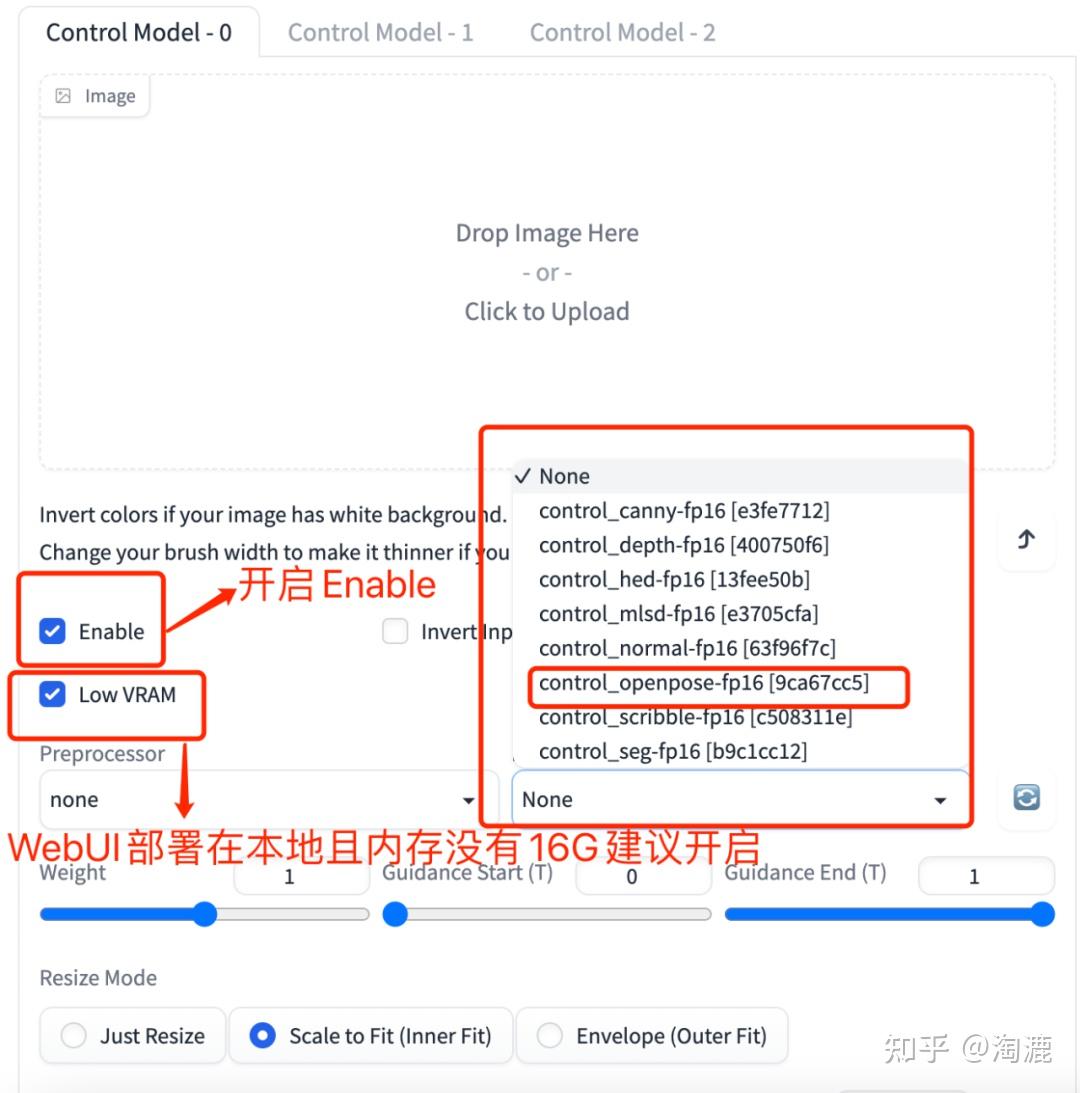
然后我们就可以上传openpose的骨骼图,或者直接上传某张图片,用这张图片的人物姿势。如果想要自己设置人物的骨骼图,可以下载openpose editor插件。
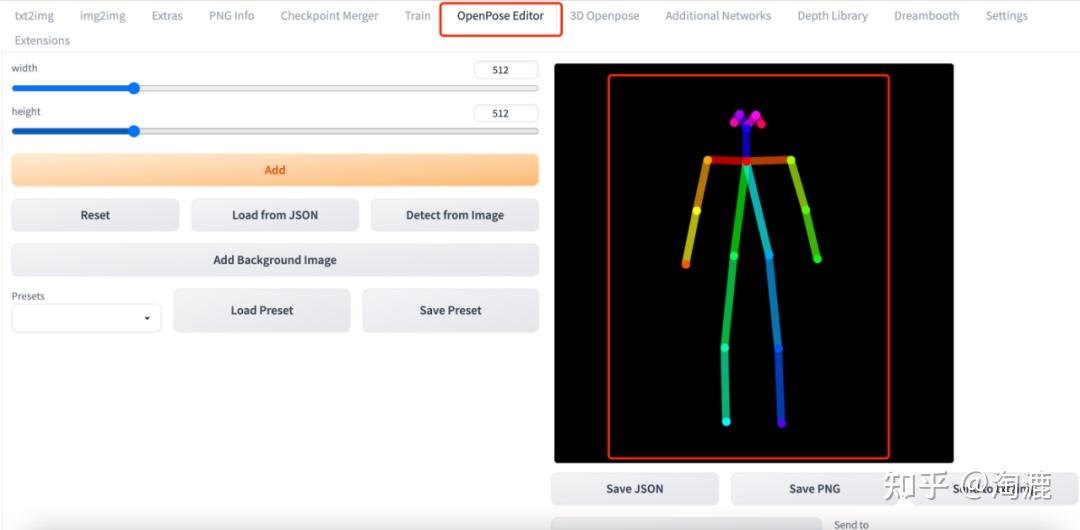
下载地址及安装方法参见:https://github.com/fkunn1326/openpose-editor 。安装成功后就能看到openpose editor这个标签页,在右边有骨骼图,可以用鼠标移动或改变它的姿势。也可以添加背景图片,比如一件衣服,让那个骨骼图的姿势跟衣服大致匹配(AI模特试衣),最后将骨骼图发送到图生图或是文生图就可以使用,或者自己保存图片也可以。
2、优化手部
我们知道,不管是人画还是AI画,手都是千古难题。诶嘿,现在我们可以通过controlnet的depth功能解决手的问题啦!下面这几张图片就是结合了上面讲到的openpose和depth模型出来的图。

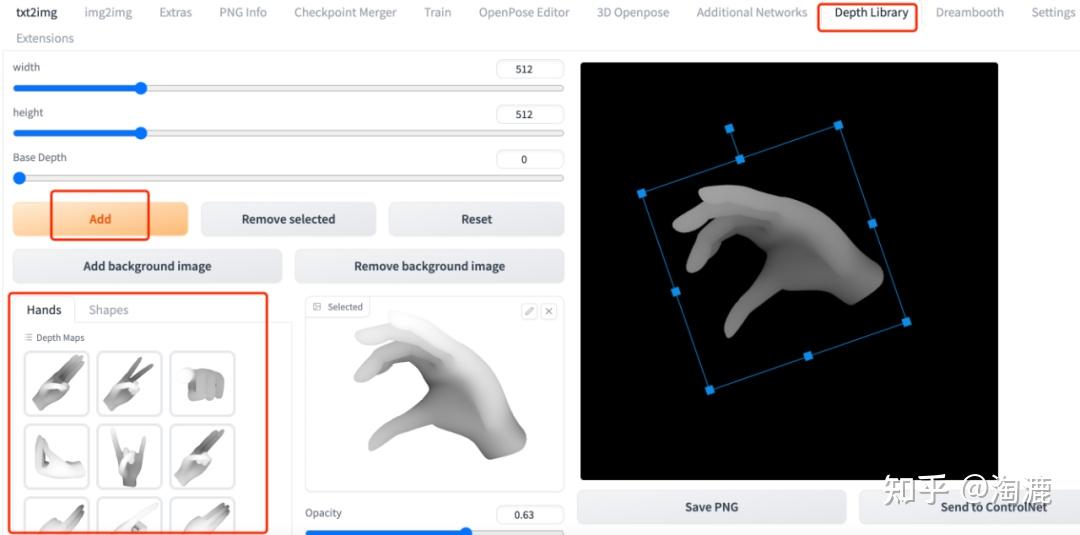
如何得到这个深度图呢?也就是depth,一个是可以拍自己的手,在WebUI这里跑一张手部的深度图,然后在PS里将手的深度图与openpose的骨骼图自然拼接在一起,然后分别利用图层将手和骨骼图存为两张图片,再去WebUI里上传这两张图片,进行controlnet控制就可以了。另一种是可以直接借助depth library这个插件,这里有很多手部的动作,可以直接生成深度图并发送到controlnet使用。安装地址及方法详见链接:https://github.com/jexom/sd-webui-depth-lib 。
当然controlnet除了openpose和depty外还有其他的构造方式,例如canny等,这里就不细讲了,大家可以自行探索一下。
到目前为止,我们可以通过正反咒语以及人物姿势控制生成各种风格、画质较为清晰、动作可控的作品了,那么Stable Diffusion有哪些潜在的商用价值?又是如何实现的呢?接着往下看⬇️
四、商业应用
1、电商领域AI模特
大家都知道电商领域模特的费用相对于店铺经营来说是比较高的,不管是服装,还是饰品,亦或是鞋包,但是模特的展示确实是在一定程度上能激发人们的购买欲。如何用Stable Diffusion生成免费的模特呢?目前市面上有两种思路供大家参考:
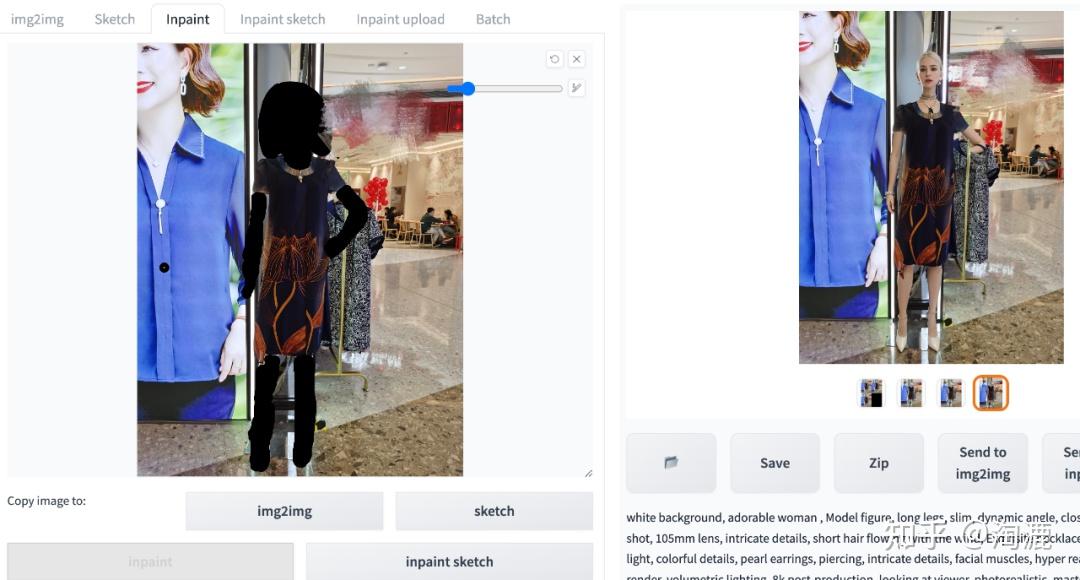
(1)给石膏模特换脸
用到的是stable diffusion的inpaint功能,如下图就是现场实拍的石膏模特,然后利用inpaint功能生成模特的对比图。


因为具体操作比较简单,就是将需要生成的地方用inpaint涂抹,让Stable Diffusion生成就行,这里就不啰嗦了,详见截图吧。另外手部可以用openpose处理,这里就不做演示了。
(2)将平铺或白底的服装穿在AI模特身上
这种稍微复杂一点,但是没有前期石膏模特的准备工作,动作也不用石膏模特的,用插件想怎么摆就怎么摆,也不用PS来回处理,而且衣服边缘的细节也会处理地更好,说一下具体操作步骤:
①利用图生图的inpaint upload,inpaint upload处上传要给模特穿的衣服以及蒙版的处理图(遮罩)。注意upload处蒙版的处理图白色是遮罩范围,如果我们把衣服处理成白色(此处用PS简单处理得到蒙版图即可),那么mask mode要选择“重绘没有遮住的地方”。反之亦然,如果衣服是黑色,其他部分是白色,那么mask mode就要选择“重绘遮住的地方”。
②在controlnet这里上传要给模特穿的衣服的图片,预训练和训练模型选择canny,画布尺寸与原图片保持一致。此处是第一个controlnet。
③利用openpose editor或者3D openpose给衣服调整一个合适的模特姿势,调整好模特的姿势后将骨骼图和手部的深度图发到第二、三个controlnet,详见下图。

④调整好controlnet这里的模型参数及画布大小,点击生成就可以了。


不管是那种方法,思路都是不炼衣服炼模特,因为衣服是实物,必须是实拍的,要不然想直接通过图生图的方式生成,那最终出来的衣服就会是严重的“货不对板”。
2、绘画辅助
听说最近一段时间不少原画师失业了,估计跟AI辅助绘画有丢丢关系吧。例如一些动漫的画面、小说的封面、插画等,基本上就可以用AI辅助出图了,效率可以得到较大提升。
3、创意灵感激发
比如服装设计、饰品、鞋子等,也都可以从AI中寻求设计灵感,毕竟AI有时候不是人的脑子,各种奇怪的组合也许能出什么新东西。
4、头像壁纸
直接生成壁纸或者头像挂到第三方网站卖,利用AI快速生图的便利性,批量生图。
Stable Diffusion在各行各业的应用大家可以自行探索,关于商业变现部分就到这啦~
这期简单给大家讲了讲Stable Diffusion的小白玩法以及其初步展现的商业用法,该技术更新太快,三天一小更,一周一大更,若是有哪些对不上、或是不全的地方,以最新版本为准,也欢迎大家留言讨论,不吝赐教!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小桥流水78/article/detail/924336
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

