
- 1HBase 开始运行
- 2python计算机毕设【附源码】4s店汽车销售管理系统(django+mysql+论文)_汽车销售系统python课程设计
- 3python打包分发工具:setuptools_python打包setuptools
- 42023年,自动化测试会取代手工测试吗?
- 5GhostNet V2家族大放异彩:华为GhostNet,超越谷歌MobileNet的CVPR2020计算机视觉技术
- 6calc(100vh - 10px) calc(100vw - 10px) calc(100% - 10px) 简单说明_calc 100vh
- 77月最新阿里菜鸟国际Java研发岗面经分享,2024年最新spring dubbo面试题_菜鸟java面试
- 8多源BFS
- 9我国人工智能核心产业规模近6000亿元
- 10人工智能第三版|chap01|task01
PanGu-Coder2:从排序中学习,激发大模型潜力_论文浅尝 | pangu-coder2: 利用排序反馈增强代码的大型语言模型
赞
踩
本文分享自华为云社区《PanGu-Coder2:从排序中学习,激发大模型潜力》,作者: 华为云软件分析Lab 。
2022年7月,华为云PaaS技术创新Lab联合华为诺亚方舟语音语义实验室推出了代码大模型PanGu-Coder,随后发布了华为的代码智能生成助手CodeArts Snap。时隔一年之后,PanGu-Coder2终于来了。此次华为云、中国科学院和北京大学的研究者联合带来了更强大的代码大模型PanGu-Coder2,提出了一种高效且通用的方法来激发大规模预训练模型的代码生成能力,该模型在多个评测数据集上均取得了当前百亿级代码大模型中最好的效果。其技术报告《PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback》已在arXiv上公开:https://arxiv.org/abs/2307.14936。华为云CodeArts Snap插件也即将上线基于PanGu-Coder2的百亿级代码生成服务,为Snap用户提供更全面的语言支持、更智能的代码生成、更准确的补全建议。
背景
代码生成或程序合成技术,一直是软件工程(SE)和人工智能(AI)领域学术研究中的热点,并因其巨大的商业价值而备受工业界关注。近两年来,得益于人工智能研究在自然语言处理(NLP)和程序语言处理(PLP)方面取得的成果,大语言模型将代码生成从学术研究逐步推向实际落地。一方面,以Tabnine(产品:Tabnine/Codota)、硅心科技(产品:AiXCoder)等为代表的小型创业公司迅速成立并获得投资,产品敏捷迭代,用户快速增长;另一方面,以微软(产品:Copilot)、亚马逊(产品:CodeWhisperer)、华为云(产品:CodeArts Snap)为代表的大公司也开始大力投入,纷纷发挥自身优势,发布了具有各自差异化特性的代码生成产品。总之,从创业投资和头部公司的动向来看,大模型技术驱动的代码智能生成,已经成为最具高价值和可行性的人工智能落地应用之一。
大规模预训练语言模型(LLM)已经成为代码智能生成事实上的主流技术,业界的代码大模型百花齐放,如 OpenAI 的 CodeX、谷歌 DeepMind 的 AlphaCode、HuggingFace 的 StarCoder,Meta的Code LlaMa,华为的PanGu-Coder 等等。相比于前大模型时代的技术,虽然大模型的代码生成能力已有长足进步,但仍存在较大的提升和进步空间。以OpenAI提出的Benchmark HumanEval为例,在164道由人类开发者编写的简单编程任务上,大部分模型的单次生成通过率仍在50%以下。而众多开发者实际使用后的反馈也表明,在真实的业务开发中,自动生成的代码多数情况下仍需要仔细审查和修改才能使用。
为了进一步提升代码大模型的生成性能,各种各样的方法被提出,如多阶段预训练、监督精调、指令微调、强化学习等。其中,我们认为强化学习是提升模型代码生成能力最有潜力的方向之一。考虑到软件会随着需求不断演进和变化,编写程序的过程本质上就是不断试错和迭代的过程,人类编写的程序会经历多轮修改,在此过程中不断从代码调试、执行、测试、验收的过程中获取反馈来确定下一步改进方向。将强化学习用于代码生成的直观动机和基本假设是:这些反馈既然可以帮助人类开发者改进已有代码并提升其编程能力,那么理论上也应该可以帮助人工智能。
在本研究中,针对现有基于强化学习的方法(如CodeRL,PPOCoder,RLTF等)所存在的问题(如反馈信号稀疏、算法实现复杂、训练过程不稳定等),我们提出了一种新的代码大模型强化框架RRTF,其全称为 Rank Responses to align Test&Teacher Feedback,意为通过对模型不同的响应进行排序来使模型输出概率同时与测试结果和人类偏好对齐。该方法的思想最初受RLHF启发(Reinforcement Learning from Human Feedback,即基于人类反馈的强化学习,是ChatGPT/InstructGPT背后的核心技术),但采取了类似RRHF(Rank Responses to Align Language Models with Human Feedback)的实现,不同之处是将RLHF中奖励模型的训练简化为对不同响应的相对排序,使用排序响应(代替奖励模型的绝对值)作为反馈,通过排序损失函数将模型输出的概率与奖励分数对齐,避免了复杂的强化学习实现和训练过程,对训练数据和训练资源的要求显著降低,从而可以高效地实现类似RLHF的效果。
为了验证该方法的效果,我们在Huggingface开源的代码大模型StarCoder-15B上进行了一系列实验。测试结果表明,通过该方法训练出的模型在HumanEval、CoderEval、LeetCode三个基准测试集上分别达到了62.20%、38.26%、32/30/10(容易/中等/困难)的单次生成通过率,在HumanEval上的提升接近30%(绝对值,32.93%->62.20%)。超越了当前所有的同参数规模模型。进一步的多语言和多任务测试表明,PanGu-Coder2的代码生成能力接近OpenAI GPT-3.5的表现,同时在代码错误修复、代码解释等多任务上都处于业界领先水平。
RRTF 框架
RRTF框架的核心理念是:利用预定义的偏好函数和实际执行的测试结果共同作为反馈信号,对针对同一编程任务的多个响应进行排序,通过排序损失函数优化目标模型的生成概率,从而逐步引导目标模型模型生成质量更高、有更大概率通过测试的代码。作为一种简单而有效的框架,RRTF实际上吸收了多种前沿的技术或思想,包括指令调优(Instruction Tuning)、指令演化(Evol-Instruct)、强化学习(Reinforcement Learning)等。“基于自动化反馈”这一点是代码生成上进行RRTF与自然语言上进行RRHF最大的不同:人类是自然语言的直接消费者,因此需要参与反馈过程才能更好地对齐模型与用户期望;而人类是代码的间接消费者,代码(特别是高级编程语言写的代码)的直接消费者是计算机中的其他软件(如编译器、解释器、操作系统等),而这部分反馈可以/应该一定程度上自动化或半自动化,从而可以降低对人类反馈的依赖和因此带来的效率瓶颈。
RRTF框架的概览如图1所示。总体而言,RRTF 包括以下三个步骤:采样、排序和训练。
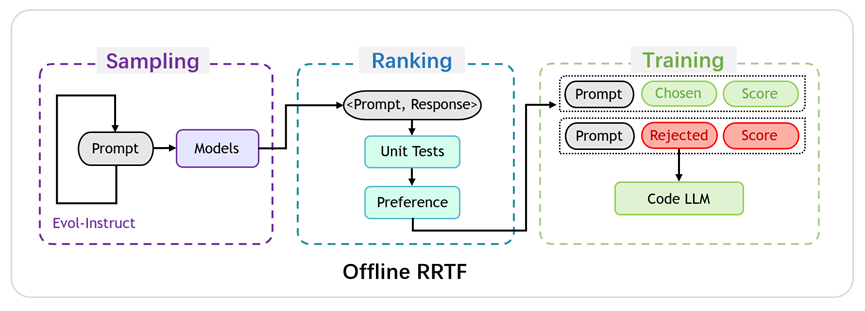
图1:RRTF 框架概览
- 采样阶段:基于某个包含了目标任务(如代码生成)的种子数据集(如CodeAlpaca),通过Evol-Instruct逐步增加难度并扩展题目要求,生成一系列既有关联又循序渐进的编程任务。将这些任务描述作为Prompt输入模型,让不同的模型进行回答,即对不同的模型进行采样。
- 排序阶段:根据预定义的偏好规则以及单元测试的结果(若存在配套单元测试)对不同来源的响应进行排序。其中,预定义偏好则代表人类开发者对不同响应的主观评判,可以定义为对某一类来源(如Ground Truth)或具有某些特征(如更加符合编码规范、圈复杂度更低、同样正确的程序中行数较少)的响应的偏好。单元测试结果泛指程序处理工具链(如代码编译器、解释器、执行器等)对所生成代码的客观评判,从可编译性、可执行性、与期望行为的一致性等角度区分正负样本。预定义偏好和单元测试形成了互补和交叉验证的关系,共同定义了理想代码的特征。
- 训练阶段:排序后的数据被组织为三元组<prompt, chosen/rejected, score>形式的样本,所有样本构成了训练数据集。将产生chosen响应的来源看做teacher角色,将被训练模型看做student角色,训练过程可以理解为student模型通过不断更新自身参数拟合teacher行为的概率分布的过程。对于同一任务的一对不同响应,定义模型π下响应yi的条件对数概率(使用响应长度标准化)为:
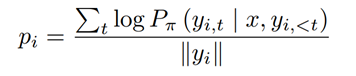
排序损失函数定义为:
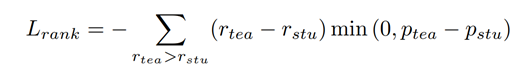
其中,r代表排序过程中赋予正负样本的不同分数。
最终的损失函数由排序损失和监督性微调的损失函数共同组成:
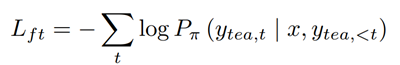
实验及评估
我们进行了一系列的实验来评估 PanGu-Coder2 的性能,并与业界的其他具有代码生成能力的模型进行了对比。我们选取了以下三个基准测试集进行评估:
- HumanEval:OpenAI随Codex模型发布的测试集,由164道手工编写的简单编程任务、对应的参考实现和单元测试构成。主要测试从自然语言描述到代码的生成能力,是目前最广泛被采用的基准测试集。
- CoderEval:华为和北京大学推出的测试集,由230道来自真实开源项目的编程任务、所在的项目上下文和单元测试构成。主要评估依据代码上下文和自然语言任务描述到代码的生成能力,相比HumanEval更贴近开发者的实际使用环境。
- LeetCode:考虑到StarCoder的训练数据截止2022年6月,我们选取了300道LeetCode上2022年7月1日之后发布的题目构成测试集。主要测试模型在竞赛类算法方面的生成能力和严谨性。
表1为PanGu-Coder2与现有的代码大模型在HumanEval-Python上的性能比较:
表1:业界知名模型在HumanEval上的结果,以生成200次的pass@1/10/100为指标衡量。对于PanGu-Coder2/WizardCoder/StartCoder,推理参数为:temperature=0.2/1.2/1.2, top_p=0.95;对于其他模型,指标取自原始论文
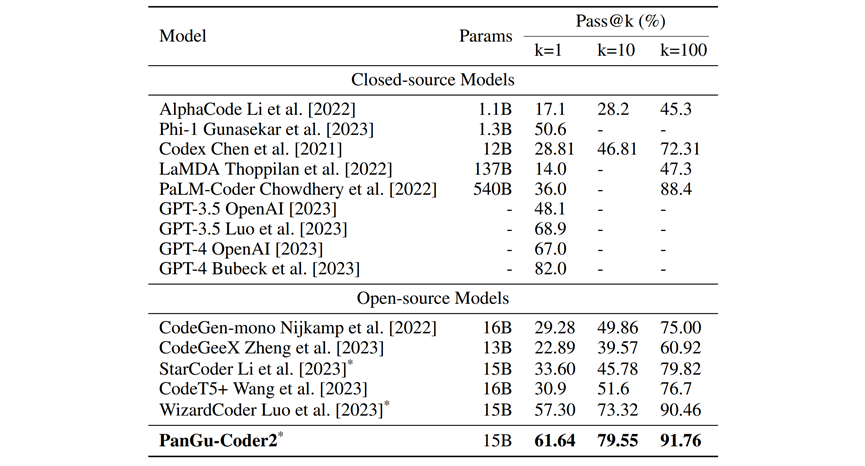
从表1可以看出:在所有被测百亿模型中,PanGu-Coder排名第一;在所有模型中,PanGu-Coder2 排名第二。与 PaLM-Coder 和 LaMDA 等千亿级大模型相比,PanGu-Coder2 虽然规模只有百亿,但性能却更好。值得注意的是,PanGu-Coder2 的表现接近或优于 OpenAI 的 GPT-3.5(不同报告中给出的结果有所差异),但与据称万亿规模的GPT-4 仍有差距。
表2展示了各代码生成模型在三个基准测试集上采用贪婪解码的单次生成通过率及其比较结果。可以看出,在所有测试集上,PanGu-Coder2 都取得了最好的成绩。值得注意的是,与基础模型StarCoder,以及在StarCoder上采用指令微调的WizardCoder 相比,采用RRTF方法的PanGu-Coder2在HumanEval、CoderEval 和 LeetCode 上均效果更佳。
表2:各代码生成模型在HumanEval、CoderEval、LeetCode上的Pass@1对比

为了进一步检验PanGu-Coder2的泛化能力,我们在其他编程语言和其他代码强相关任务上对PanGu-Coder2进行了评估。我们选取了以下两个公开的基准测试集:
- HumanEval-X:清华大学基于HumanEval推出的多语言代码生成评测基准,包含820个高质量手写样本,覆盖Python、C++、Java、JavaScript、Go等语言,我们扩展了C和TypeScript语言的部分。
- HumanEvalPack:Huggingface上著名的代码大模型社区Big Code推出的多任务评测基准,包含HumanEval-Synthesize(代码生成,自然语言->代码)、HumanEval-Fix (代码修复,自然语言+代码->代码)、HumanEval-Explain (代码解释,自然语言+代码->自然语言)等任务。
表3展示了PanGu-Coder2最新版本代码生成测试集HumanEval-X上的结果以及与业界其他的对比:
表3:各多语言代码生成模型在HumanEval-X上的Pass@1对比
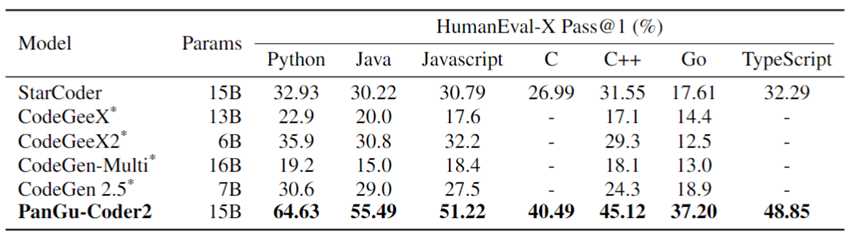
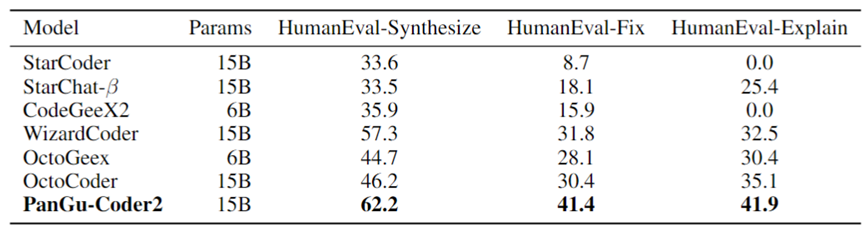
表4展示了PanGu-Coder2在多任务测试集HumanEvalPack上的结果以及与业界其他模型的对比(其他模型的数据主要来自OctoPack论文):
表4:各支持多任务的模型在HumanEvalPack-Python上的效果对比
综合以上实验结果,可以得出以下结论:
- 在所有具有代码生成能力的大模型中,PanGu-Coder2 的综合代码生成能力处于业界第一梯队
- 在多语言和多任务的基准测试中,PanGu-Coder2处于业界相近规模模型的最高水平
- 在代码生成任务上,尽管 PanGu-Coder2 的规模较小,但其性能却优于 PaLM-Coder 和 LaMDA 等更大规模的模型
- PanGu-Coder2 是被测模型中唯一同时在HumanEval、HumanEval-X、HumanEvalPack、CoderEval、LeetCode等测试集上都达到最佳性能的模型。
总结与展望
在本文中,我们介绍了PanGu-Coder2背后的创新性训练框架RRTF,并通过充分的实验证明了其在激发大模型代码生成潜力方面的效果。RRTF背后的核心动机和思想是基于自动化反馈的强化学习,即在语言模型的自回归优化目标之外,引入代码特有的自动反馈信号,即通过解释器、编译器、执行器、单元测试等代码处理工具链依次对所生成代码进行检查,其结果通过相对排序后作为目标函数的一部分,从而在训练和优化过程中引导模型生成有更大概率能顺利编译运行并通过测试的代码。作为一种与模型无关的训练方法,RRTF可无缝迁移到其他具有一定编程能力的预训练模型上,或同一模型的不同规模上。
PanGu-Coder2百亿级模型即将上线到华为云CodeArts Snap智能开发助手中,将带来三倍的代码生成准确率提高以及对所有主流编程语言的逐步支持,从而全面提升Snap用户的开发效率和代码质量。在JetBrains或VSCode插件市场上提前下载安装CodeArts Snap,并扫描下方二维码关注CodeArts Snap即将到来的重大更新吧!

文章来自 PaaS技术创新Lab;PaaS技术创新Lab隶属于华为云,致力于综合利用人工智能和软件分析技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
号外!

华为将于2023年9月20-22日,在上海世博展览馆和上海世博中心举办第八届华为全联接大会(HUAWEICONNECT 2023)。本次大会以“加速行业智能化”为主题,邀请思想领袖、商业精英、技术专家、合作伙伴、开发者等业界同仁,从商业、产业、生态等方面探讨如何加速行业智能化。
我们诚邀您莅临现场,分享智能化的机遇和挑战,共商智能化的关键举措,体验智能化技术的创新和应用。您可以:
- 在100+场主题演讲、峰会、论坛中,碰撞加速行业智能化的观点
- 参观17000平米展区,近距离感受智能化技术在行业中的创新和应用
- 与技术专家面对面交流,了解最新的解决方案、开发工具并动手实践
- 与客户和伙伴共寻商机
感谢您一如既往的支持和信赖,我们热忱期待与您在上海见面。
大会官网:华为全联接大会 2023 | HUAWEI CONNECT 2023
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。

