
- 1《RepViT Revisiting Mobile CNN From ViT Perspective》
- 2微信小程序开发学习笔记《12》下拉刷新事件、上拉触底事件_微信小程序 下拉刷新
- 3Python程序设计基础(一)_python语言程序设计基础
- 4给刚入职场的年轻人八条建议_不恋旧功
- 5解决Adobe系软件弹窗报错的问题:This non-genuine Adobe app has been disabled soon
- 6C语言入门:C语言基础知识
- 7前端性能提升之 - electorn 结合 vue3 使用webworker 调用go打包的wasm_go打包vue
- 8C语言--vs使用调试技巧
- 9Python 小白从零开始 PyQt5 项目实战(3)信号与槽的连接_pyqt5 信号与槽的连接
- 10数据结构 C 代码 2.3: 双向链表_数据结构c语言版2.3按例代码
ocr之opencv配合paddleocr提高识别率_paddleocr 提高识别率训练
赞
踩
背景1:在这篇文章编写之前使用到的工具并不是opencv,而是java原有的工具BufferedImage。但因为在使用过程中会频繁切图,放大,模糊,所以导致的jvm内存使用量巨大,分秒中都在以百兆的速度累加内存空间。这种情况会让程序卡顿,频繁的发生full gc。增加了jvm宕机的不确定性,也给自己埋下了定时炸弹。在不断摸索后一直不能解决这个高内存使用率的问题。而这又关乎到程序的稳定,于是在近日发现并决定使用opencv试一试。
背景2:使用BufferedImage的这段时间里虽然通过不断调整jvm①达到了没有明显卡顿的效果,但是这个坑迟早还是会害人的。
注①:怎样调整的jvm可以看这篇博文。调整参数不复杂,只是通过较小堆大小来做的,但这不是最佳解决方案》》
注:只是通过paddleocr识别,准确度不如人意。但是经过矫正,使用放大模糊图片,就像给paddleocr带上了一副眼睛,成功的提高了识别率。美哉。应上了一首名句(不识庐山这面目,只缘身在此山中),让paddle能看到山就好。
一、识别思路
1. 切割图片
切割的位置以及尺寸大小是通过提前测量好的,也就是可以通过系统内的操作。
2. 放大图片①
放大的尺寸大小非常需要测试。首先放大倍数过小会导致图片不够清除。倍数过大导致图片的文件大小过量,这会导致各种的不方便,尤其是在通过后面要讲的paddleocr识别起来效率降低(识别时间过长)。
注①:测试后计划使用的放大倍数选择8
3. 模糊图片
模糊图片的操作会带使得paddleocr在现有模型下提高识别率。据观测,棱角分明的像素体,识别率是很低的(感觉paddleocr被训练的更容易看懂抽象一般)
4. paddleocr识别
这是最后一步。我在实际使用的场景下应用的是打包的exe程序。exe打包的具体内容可以查看我的这篇博文 》》
二、具体实现介绍
注:如何使用opencv呢?我咨询的大模型【文心一言】。说实话在变成使用方面他还是很在行的。在使用大模型方面我还解除了【抖音】的【豆包】,豆包的效果不是很好,文心还是不错。
opencv如何使用
1. 下载opencv4.6.0版本并进行配置
注:我使用的是460版本, 是在官网进行的下载,直接下载网速会特别慢,于是使用的【迅雷】(通过看广告获取快下的资格)
opencv官网下载页面》》
注:双击解压到你指定的目录

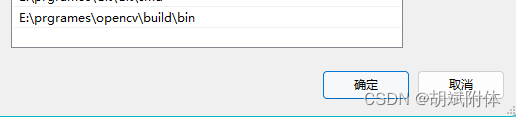
注:将你的下方路径配置到环境变量
E:\prgrames\opencv\build
- 1


注:我配置的位置为根目录的/lib/下
<dependency>
<groupId>opencv</groupId>
<artifactId>opencv</artifactId>
<version>460</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/opencv-460.jar</systemPath>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
}
- 1
- 2
- 3
由此就可以开始使用了
2. 编写放大模糊裁剪方法
import cn.hutool.core.util.StrUtil; import org.opencv.core.Core; import org.opencv.core.Mat; import org.opencv.core.Rect; import org.opencv.core.Size; import org.opencv.imgcodecs.Imgcodecs; import org.opencv.imgproc.Imgproc; import java.io.File; import java.io.IOException; /** * opencv图片处理 */ public class OpencvPicHanldle { static { System.loadLibrary(Core.NATIVE_LIBRARY_NAME); } /** 裁剪图片 */ static String CLIP_NAME = "tmp_cp"; /** 放大图片 */ static String ZOOM_NAME = "tmp_zm"; /** 模糊图片 */ static String BLUR_NAME = "tmp_br"; public static File blurPic(String inputFilePath, String picFormat, String tmpDir, int redius) { // 读取图片 Mat src = Imgcodecs.imread(inputFilePath); // 创建输出Mat对象 Mat dst = new Mat(); // 定义高斯滤波器的大小,这里使用5x5的核 Size ksize = new Size(redius, redius); // 定义高斯滤波器的标准差,这里使用0,意味着OpenCV会根据核大小自己计算 double sigmaX = 0; double sigmaY = 0; // 应用高斯模糊 Imgproc.GaussianBlur(src, dst, ksize, sigmaX, sigmaY); File file; try { file = File.createTempFile(BLUR_NAME, StrUtil.DOT+picFormat.toLowerCase(), mkdir(tmpDir)); } catch (IOException e) { throw new RuntimeException(e); } // 保存模糊处理后的图片 Imgcodecs.imwrite(file.getAbsolutePath(), dst); // 显示模糊处理后的图片(如果需要的话) // HighGui.imshow("Blurred Image", dst); // HighGui.waitKey(0); // 释放资源 src.release(); dst.release(); return file; } public static File clipPic(String filePath, String picFormat, String tmpDir, int x, int y, int w, int h) { Mat src = Imgcodecs.imread(filePath); // 定义切割区域 Rect roi = new Rect(x, y, w, h); // x, y 是起始点坐标,width, height 是切割区域的宽和高 // 获取切割后的图片(子矩阵) Mat cropped = new Mat(src, roi); File file; try { file = File.createTempFile(CLIP_NAME, StrUtil.DOT+picFormat.toLowerCase(), mkdir(tmpDir)); } catch (IOException e) { throw new RuntimeException(e); } // 保存切割后的图片 Imgcodecs.imwrite(file.getAbsolutePath(), cropped); // 释放资源 src.release(); cropped.release(); return file; } public static File zoomPic(String inputFilePath, String picFormat, String tmpDir, double scale) { // 读取图片 Mat src = Imgcodecs.imread(inputFilePath); // 定义放大后的尺寸,这里假设放大两倍 double scaleFactor = scale; // 放大倍数 Size newSize = new Size(src.width() * scaleFactor, src.height() * scaleFactor); // 创建放大后的Mat对象 Mat dst = new Mat(); // 使用Imgproc.resize()函数放大图片 Imgproc.resize(src, dst, newSize); File file; try { file = File.createTempFile(ZOOM_NAME, StrUtil.DOT+picFormat.toLowerCase(), mkdir(tmpDir)); } catch (IOException e) { throw new RuntimeException(e); } // 保存放大后的图片 Imgcodecs.imwrite(file.getAbsolutePath(), dst); // 释放资源 src.release(); dst.release(); return file; } public static File mkdir(String dirPath) { File dirFile = new File(dirPath); if(!dirFile.exists()) { dirFile.mkdir(); } return dirFile; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
3. 对接paddleocr识别
python脚本识别
使用python脚本识别只是为了测试, 实际我在java中使用时用到的为打包后的exe
注:paddleocr的安装详情可查看这篇文章 》》
注:安装后可使用脚本进行测试识别图片 如下是python的识别脚本
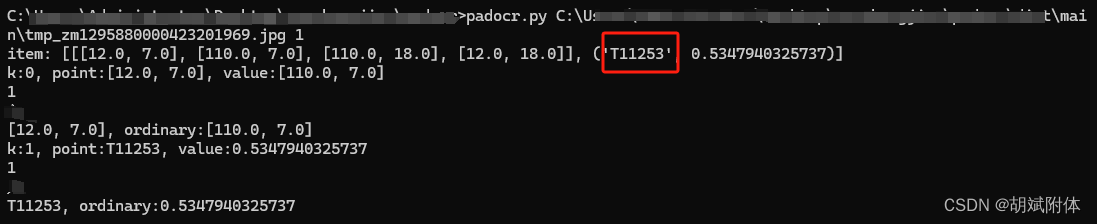
注:使用时命令如: 标红处为识别出的内容。
# 参数1为打印识别到的内容
padocr.py C:\main\tmp_zm1295880000423201969.jpg 1
- 1
- 2
from paddleocr import PaddleOCR import sys def recognize(imgPath,printx): # 模型路径下必须含有model和params文件 ocr = PaddleOCR( use_angle_cls = True, # 是否加载分类模型 use_gpu = False# 是否使用gpu ,show_log=False ) #img_path = 'C:/Users/Administrator/Desktop/zuoshangjiao/20240129162437.jpg' result = ocr.ocr(imgPath, cls = True) #print(f"result:{result}") for i,line in enumerate(result): #print(f"i:{i}, line:{line}") for j,item in enumerate(line): print(f"item: {item}") for k, body in enumerate(item): #if k == 1: print(f"k:{k}, point:{body[0]}, value:{body[1]}") print(printx) if printx == "1": print(f"{body[0]}, ordinary:{body[1]}") else: print(f"{body[0]}") if __name__ == "__main__": recognize(sys.argv[1],sys.argv[2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
java程序
import cn.hutool.core.date.DatePattern; import cn.hutool.core.date.DateUtil; import cn.hutool.core.io.FileUtil; import cn.hutool.core.util.StrUtil; import lombok.extern.slf4j.Slf4j; import org.opencv.core.Mat; import org.opencv.core.Rect; import org.opencv.core.Size; import org.opencv.imgcodecs.Imgcodecs; import org.opencv.imgproc.Imgproc; import javax.imageio.ImageIO; import java.awt.*; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; import java.util.Date; /** * paddleocr识别工具类 */ @Slf4j public class PaddleOcrUtil { /** 临时文件路径 */ public static String tmpPath = System.getProperty("user.dir") + StrUtil.SLASH + "tmpFile" + StrUtil.SLASH + DateUtil.format(new Date(), DatePattern.PURE_DATETIME_MS_FORMAT); /** * 创建图片路径 */ static { File tmpFile = new File(tmpPath); if(!tmpFile.exists()) { if(FileUtil.mkParentDirs(tmpPath).exists()) { if(tmpFile.mkdir()) {} } } } /** * 测试使用, 勿删除 */ public static void testRec() { String cutPic = "D:\\...\\tmp_cp8579718493577844855.jpg"; String abs = "D:\\...\\tmpFile\\20240328104742415\\acc3"; File a = OpencvPicHanldle.zoomPic(cutPic, "jpg", abs, 8); File b = OpencvPicHanldle.blurPic(a.getAbsolutePath(), "jpg", abs, 5); System.out.println(b.getAbsolutePath()); } /** * 识别图片 * @param filePath 整图 * @param picFormat 整图类型 * @param x 需要切割的坐标x * @param y 需要切割的坐标y * @param w 需要切割的坐标w * @param h 需要切割的坐标h * @return */ public static String rec(String filePath, String picFormat, int x, int y, int w, int h) { File outputfile; try{ outputfile = OpencvPicHanldle.clipPic(filePath, picFormat, tmpPath, x, y, w, h); }catch (Throwable e) { log.error("rec.err: ", e); return StrUtil.EMPTY; } return rec(outputfile, picFormat); } /** * 识别图片具体方法 * @param outputfile 切割后的图片路径 * @param formatName 图片类型 * @return */ private static String rec(File outputfile, String formatName) { File zoomFile = null; File blurFile = null; try { // 放大 zoomFile = OpencvPicHanldle.zoomPic(outputfile.getAbsolutePath(), formatName, tmpPath, 8); // 模糊化 blurFile = OpencvPicHanldle.blurPic(zoomFile.getAbsolutePath(), formatName, tmpPath, 5); String console; try { console = ShellUtils.exec(OcrServiceRegistry.execPath, blurFile.getAbsolutePath()); } catch (Exception e) { throw new RuntimeException(e); } if(StrUtil.isEmpty(console)) return StrUtil.EMPTY; return console.replaceAll("[\\s\\t\\n\\r]+", ""); }catch (Throwable e) { e.printStackTrace(); return ""; }finally { if(outputfile != null) { if(!OcrServiceRegistry.saveClipImage) { outputfile.delete(); } } if(zoomFile != null) { if(!OcrServiceRegistry.saveBlurImage) { zoomFile.delete(); } } if(blurFile != null) { if(!OcrServiceRegistry.saveBlurImage) { blurFile.delete(); } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
三、使用opencv注意事项
注:不要有中文路径,否则会报错
- 不要有中文路径(java程序如jar包所在路径)
- 不要有中文路径(要处理的图片所在路径)
总结
1. 持之以恒
对不满意的事情想办法让他变得更好。
注:心里一直装着的事终于能够落地了。因为一直装着,也就是放在心上,终归有了解决方案。
2. 换种思路
注:避免死心眼钻牛角尖。就比如死磕jvm调优,但还是于事无补。
注:多尝试新的东西,会带来不小的收获

