
- 1过去5年最受欢迎机器学习论文+代码速查_caffe是一个深度学习框架,在()下开源)
- 2抛java.lang.NoClassDefFoundError: org.slf4j.LoggerFactory错误_sofa-middleware-log slf4j error : build iloggerfac
- 3【AI大模型】Transformers大模型库(四):AutoTokenizer_transformers autotokenizer
- 4一个基于C#开发的Excel转Json工具_excel2json jsonc %jsonout%
- 5十大经典排序算法总结(Java实现+动画)_十大排序算法实现
- 6面试官:如果要存 IP 地址,用什么数据类型比较好?,2024年最新大厂Java面试笔试题目
- 7selenium简介、使用selenium爬取百度案例、selenium窗口设置、
- 8超好用的图床-生成图片在线链接_图床链接生成器
- 9CrossOver软件2024汉化版下载安装步骤教程_crossmanager 2024
- 10Java基于web的用户画像管理系统(开题+源码)_用户画像tags-web源码
Llama3 本地web Demo部署_llama 本地部署秘钥
赞
踩
这里感谢【机制流】的指导,完整版本地部署教程连接:机智流Llama3-Tutorial本地部署教程
一、VSCode 远程链接开发机
1.1 先下载安装VSCode
1.2 搜索并安装如下插件:
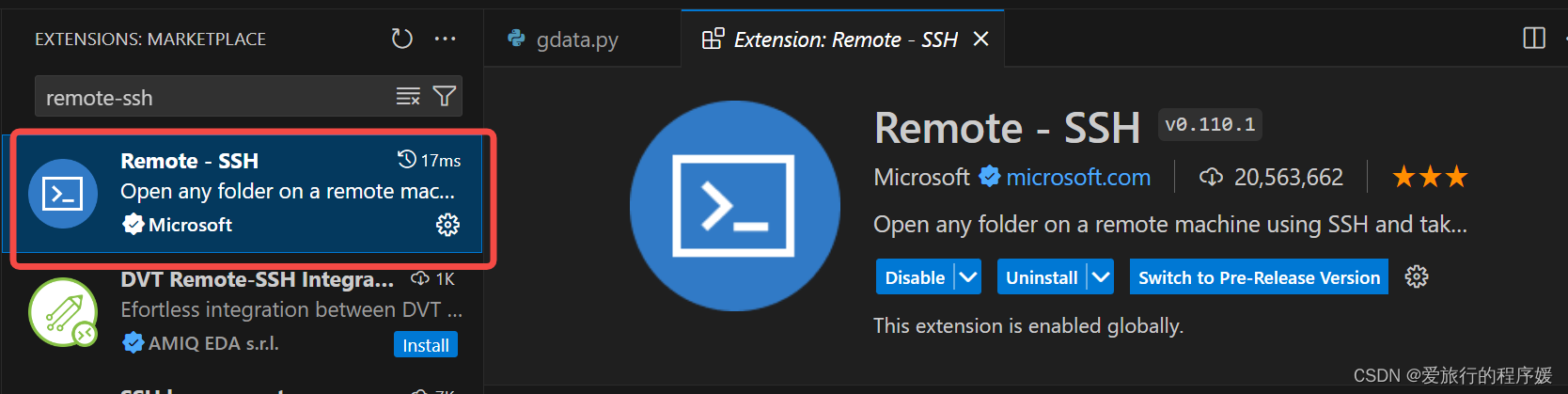
点击 Install ,安装 Remote SSH 的同时也会安装
- Remote - SSH: Editing Configurat
- Remote Explorer
1.3 配置VSCode远程链接开发机
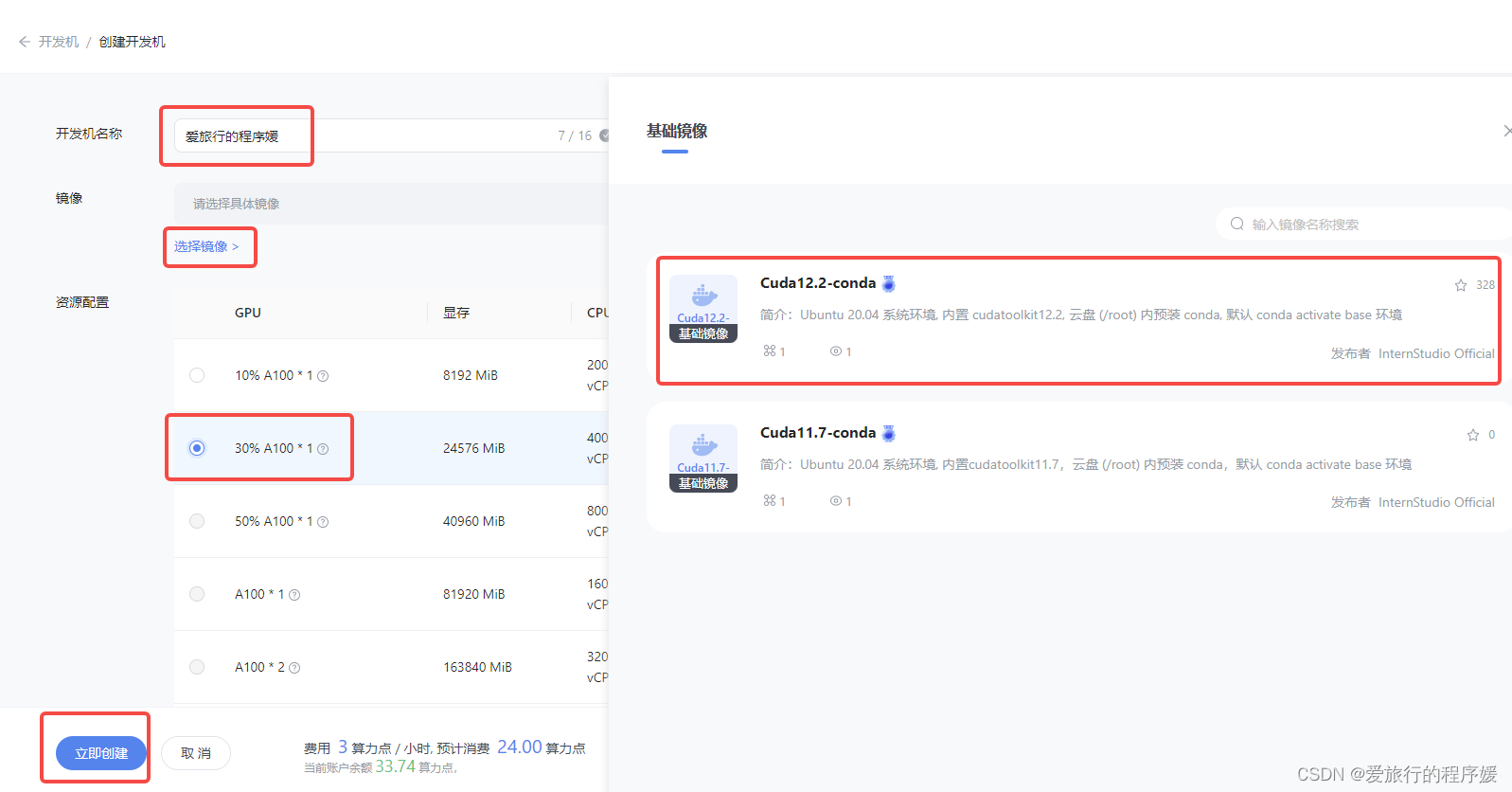
安装完插件之后,我们来到InternStudio,可以看到以下界面,然后我们点击"创建开发机"

接着我们配置开发机的名称,镜像以及GPU资源
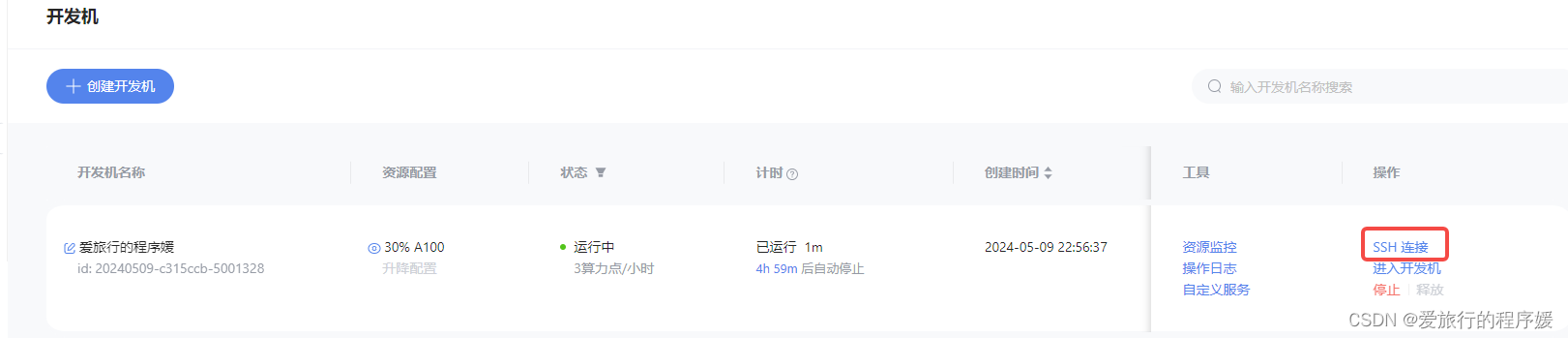
完成开发机创建以后,我们启动开发机,点击 SSH 连接。
复制登录命令
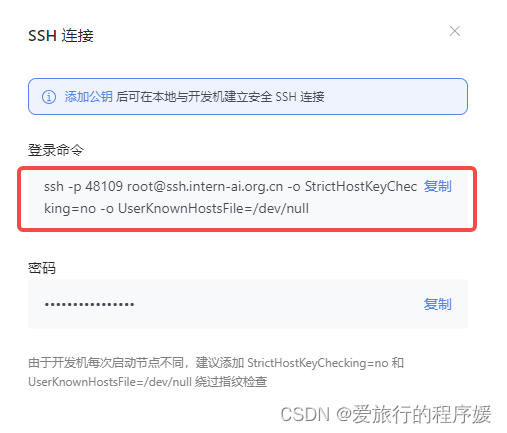
然后回到 VSCode 点击左侧的远程按钮,点击 SSH 的 + 号,在弹出的窗口中输入开发机的登录命令。
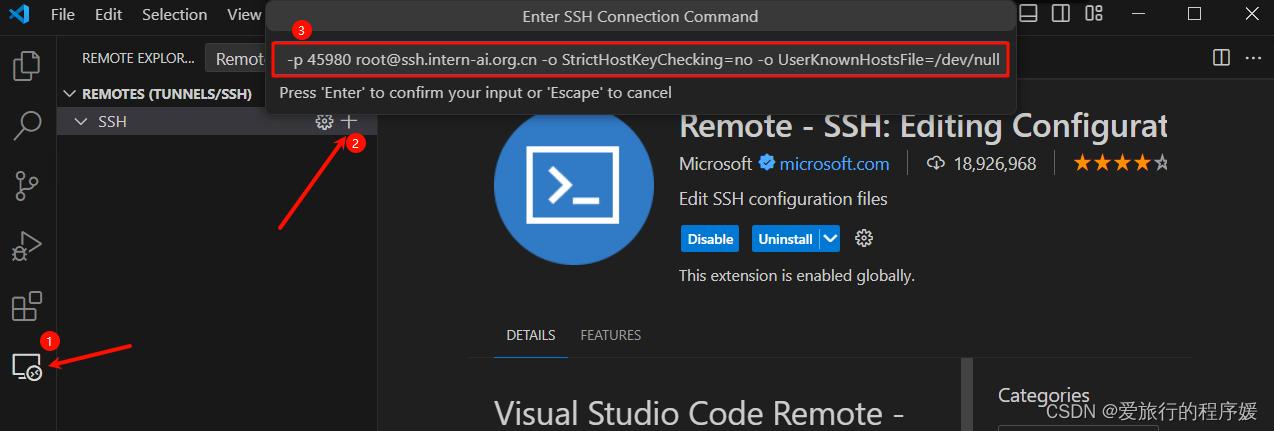
将 ssh 登录信息写入配置文件,我们刷新 ssh 列表就可以看到我们刚刚配置的 ssh 连接了。
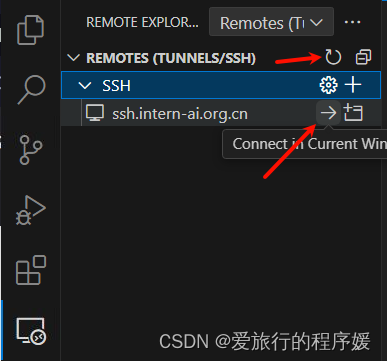
然后我们等待VSCode配置完成后,打开我们选择的文件夹
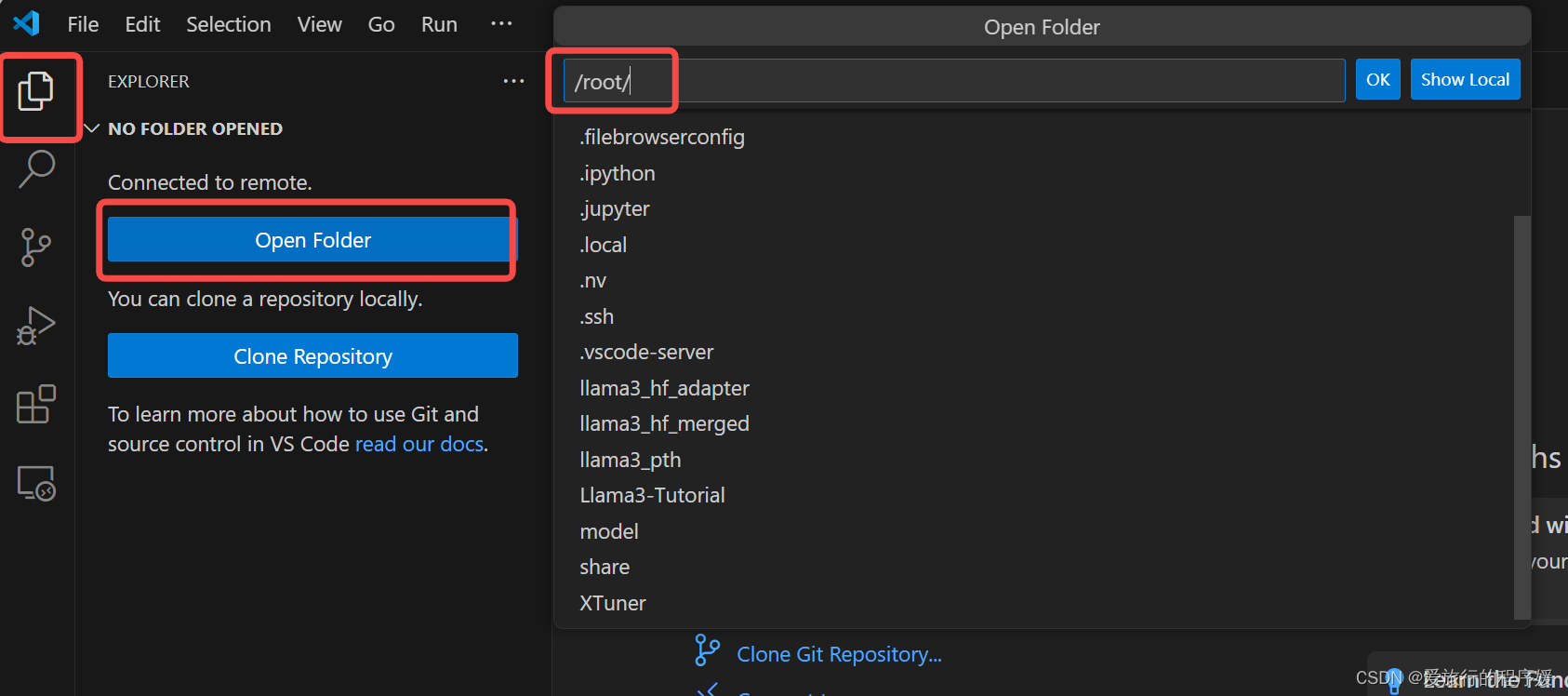
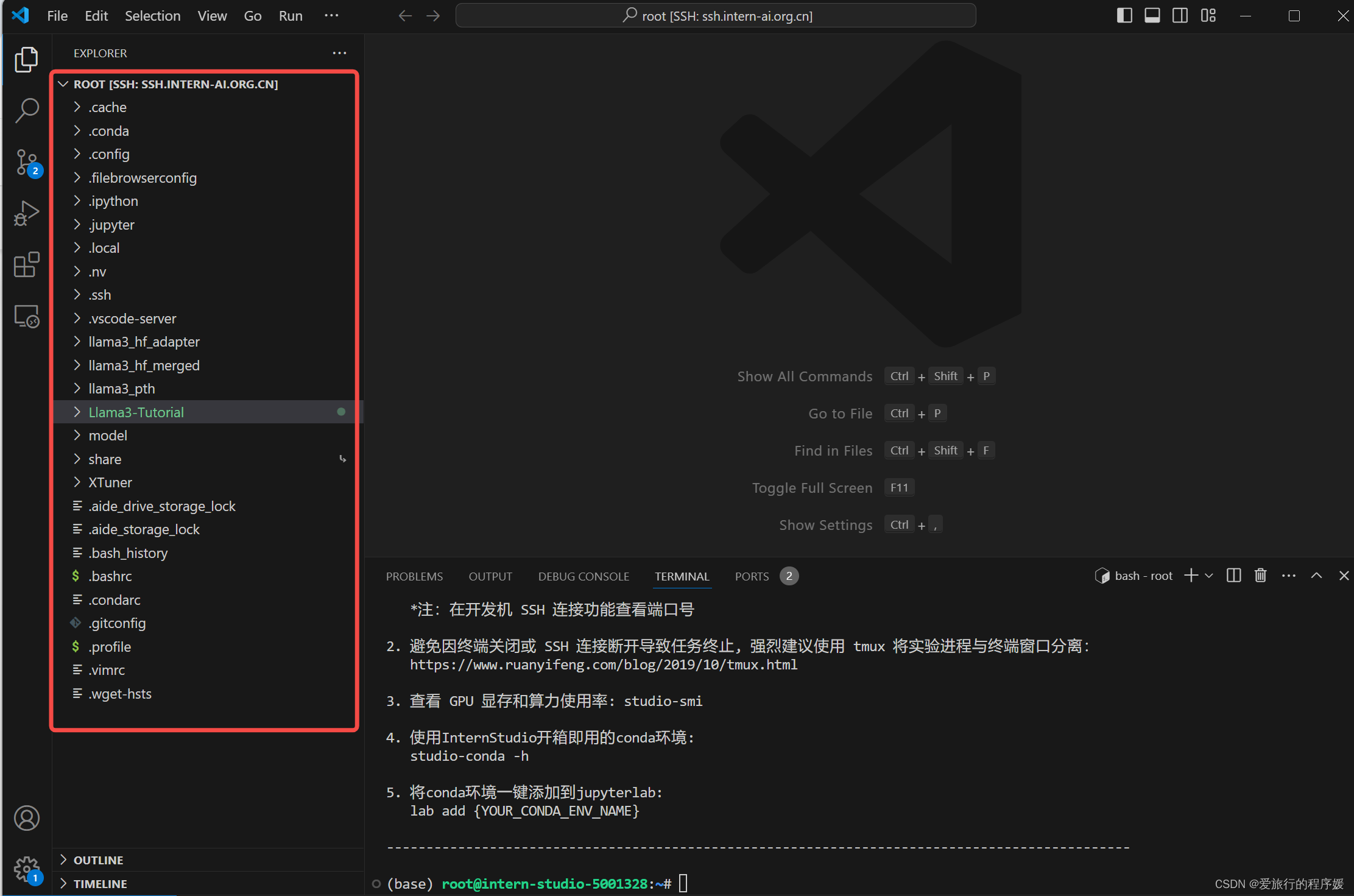
我们需要再次输入密码

此时能看到开发机的目录
1.4 VSCode端口配置
下面会介绍两种端口映射的方法:
方法一:
我们可以使用 Ctrl + Shift + ~ 快捷键打开 VSCode 终端,然后点击右边的 Ports 界面,接着点击 Foward a Port 按钮。

比如我们的端口为 6006 在这里我们就可以这样设置。

其中第一个 port 是映射在本机的端口,后面的Fowarded Address 是开发机的IP地址和端口。也就是将开发机的 6006 端口映射在了本机的 6006 这个端口,当然本机的端口是可以更改的。
但我们运行 streamlit 或者是 gradio 应用的时候,VSCode 会自动的帮我们进行端口映射,并不需要我们手动操作,所以我们介绍另一种端口映射方法,也是最常用的。
方法二:
我们打开本机的终端,我们使用 powershell,但是要确保你的本机是由 OpenSSH 服务的。
- 配置 ssh 密钥
配置 ssh 密钥一方面是方便我们登录,这样我们不用每次连接都需要输入密码,另一方面是为了我们端口映射的安全。 首先我们需要配置 ssh 密钥, 在powershell 中输入以下命令;
ssh-keygen -t rsa
- 1
公钥默认存储在 ~/.ssh/id_rsa.pub,可以通过系统自带的 cat 工具查看文件内容:
cat ~/.ssh/id_rsa.pub
- 1
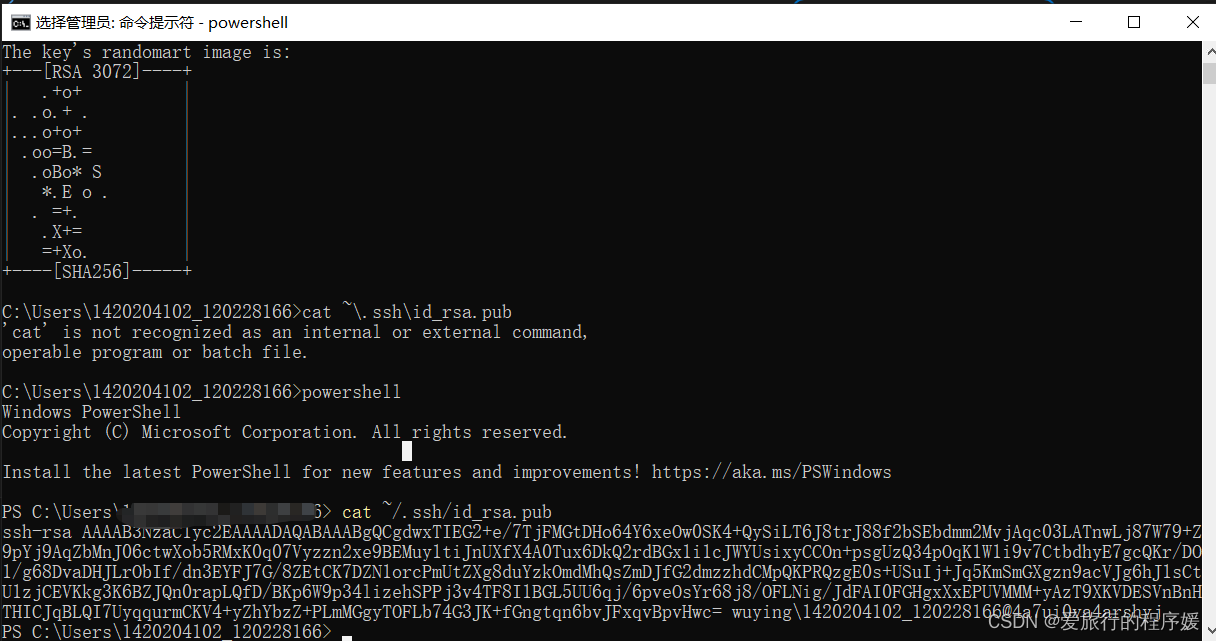
- 将 ssh 密钥添加到 InternStudio中
我们回到 InternStudio,找到配置 SSH Key,将我们刚刚生成的 ssh 公钥添加到 InternStudio 中,它会自动识别主机名称。
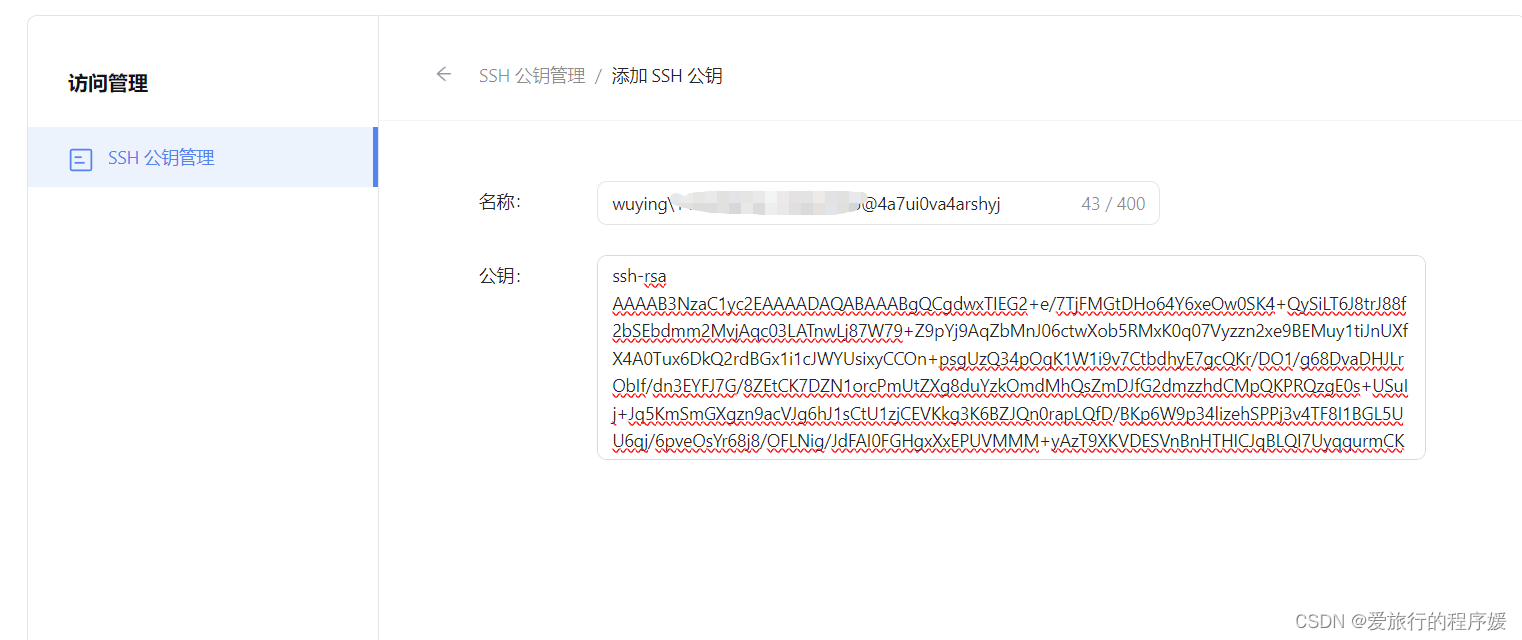
- 进行端口映射
接着我们来到开发机控制台,点击自定义服务

复制下面的命令:
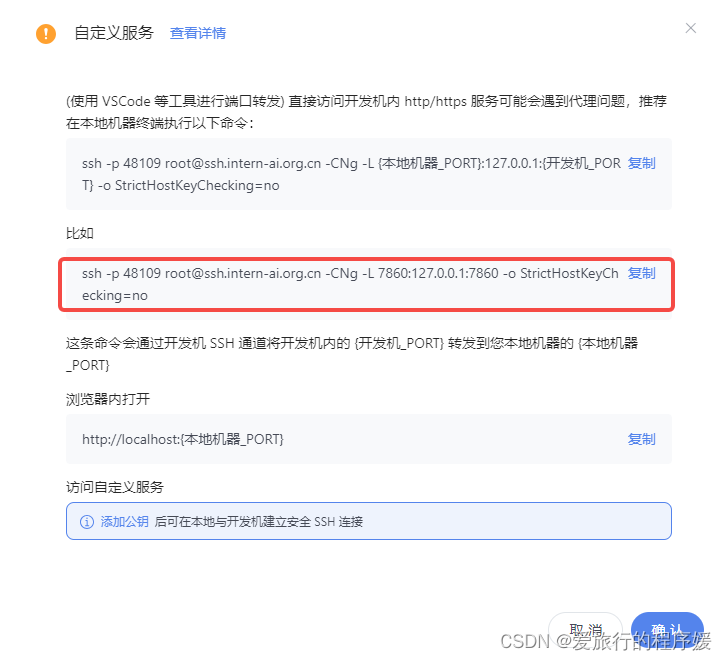
这里注意,因为之前在VSCode里输入的端口为6006,因此需要改个端口号
# 原给的命令(不要复制)
ssh -p 48109 root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
#修改之后(复制这个)
ssh -p 48109 root@ssh.intern-ai.org.cn -CNg -L 6006:127.0.0.1:6006 -o StrictHostKeyChecking=no
- 1
- 2
- 3
- 4
其中 45980 是你当前运行的开发机的端口,7860 是我们要进行映射端口,这个端口要根据运行的应用程序的端口来自行修改。
将复制的命令粘贴到本机的 powershell 中,回车

如果出现如上图所示的情况,就说明已经成功进行了端口映射,它不输出任何信息是正常的,因为端口映射服务正在运行,接下来大家就可以快乐的进行课程实践了。
二、Llama 3 本地 Web Demo 部署
2.1 环境配置
先打开远程开发机终端
在终端中粘贴以下指令
#新建conda环境
conda create -n llama3 python=3.10
#激活llama3的conda环境
conda activate llama3
#安装依赖库(等的时间会久一些)
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
- 1
- 2
- 3
- 4
- 5
- 6
2.2 下载模型
新建文件夹
mkdir -p ~/model
cd ~/model
- 1
- 2
从OpenXLab中获取权重(开发机中不需要使用此步,直接跳到软连接)
下载模型 (InternStudio 中不建议执行这一步)
安装 git-lfs 依赖
如果下面命令报错则使用 apt install git git-lfs -y
conda install git-lfs
git-lfs install
git clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
软链接 InternStudio 中的模型
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
- 1
- 2
2.3 Web Demo 部署
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
- 1
- 2
安装 XTuner 时会自动安装其他依赖
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .
- 1
- 2
- 3
- 4
运行 web_demo.py
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
~/model/Meta-Llama-3-8B-Instruct
- 1
- 2
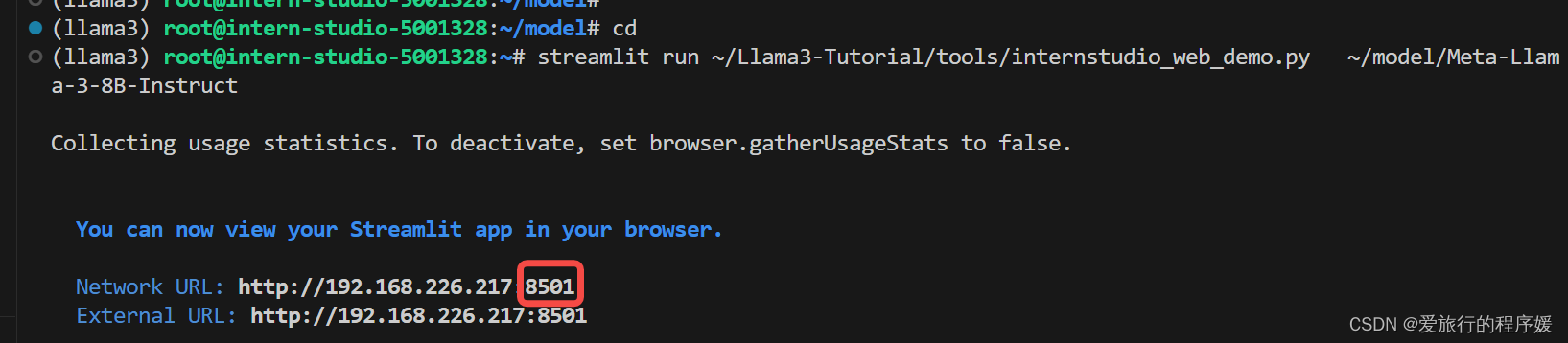
将http://192.168.226.217:8501 中的8501粘贴到VSCode的端口中,点网页(小地球图标)

成功啦!

三、Llama 3 微调个人小助手认知(XTuner 版)
开发机需要用30%A100的开发机
3.1 自我认知训练数据集准备
将Llama 3 Tutorial仓库克隆到本地
# 克隆
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
# 进入文件夹中
cd Llama3-Tutorial
# 用VSCode进到项目下
code .
- 1
- 2
- 3
- 4
- 5
- 6
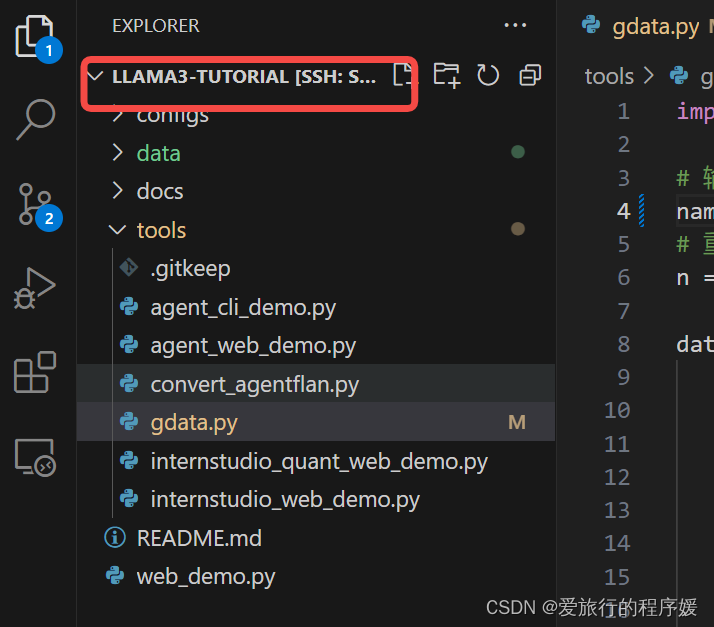
进入/tools/gdata.py文件,修改name为【爱旅行的程序媛】
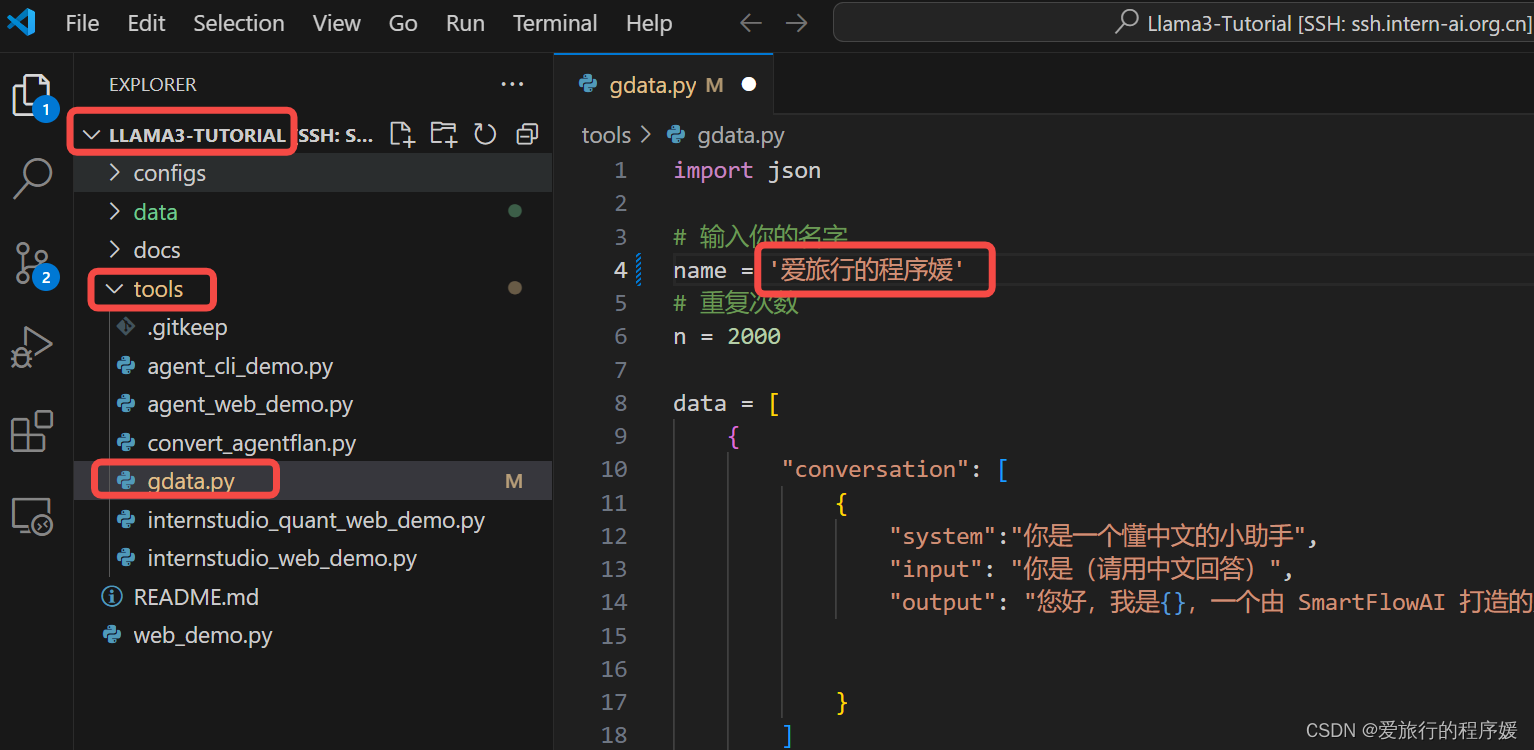
运行gdata.py的python脚本
cd ~/Llama3-Tutorial
python tools/gdata.py
- 1
- 2
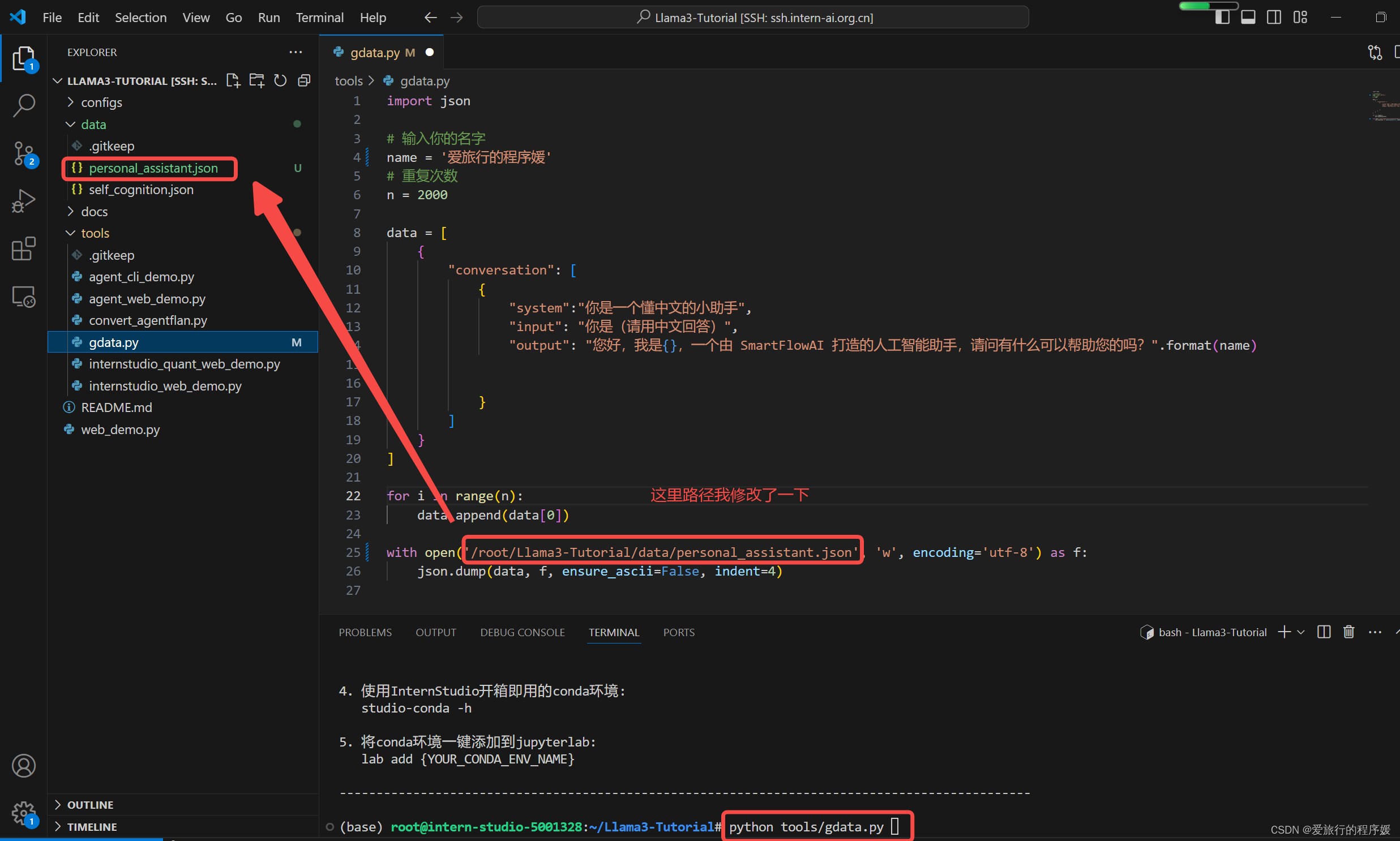
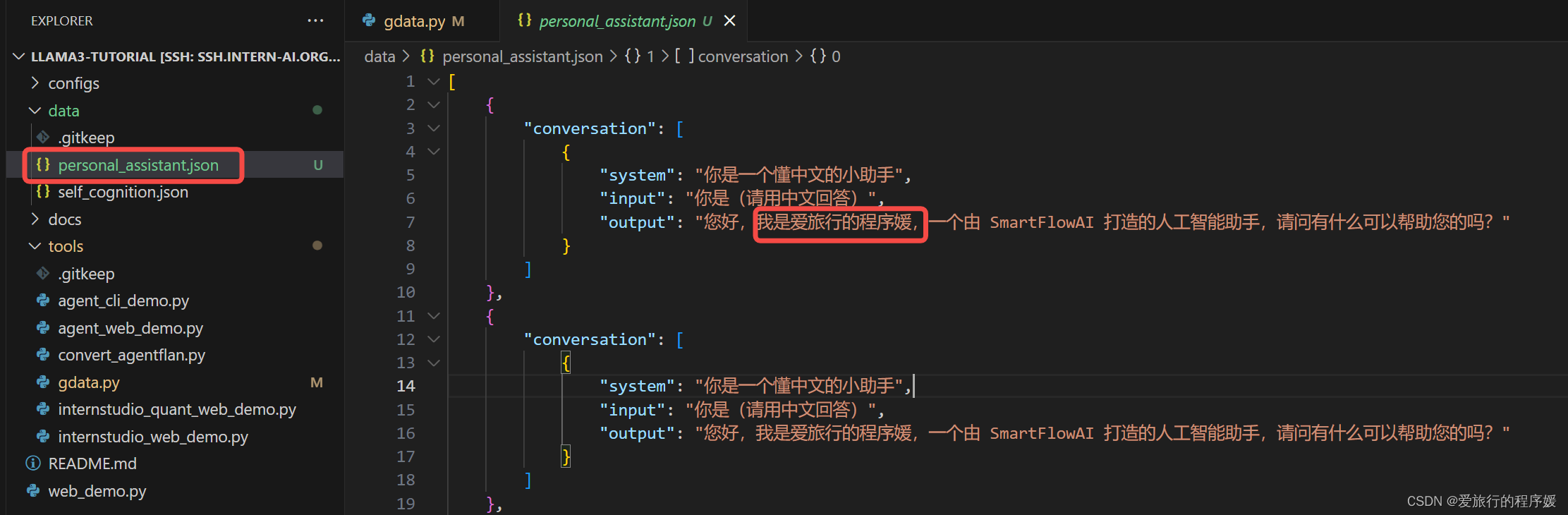
运行完能在personal_assistant.json中看到运行的结果,将名称改成了【爱旅行的程序媛】
3.2 XTuner微调
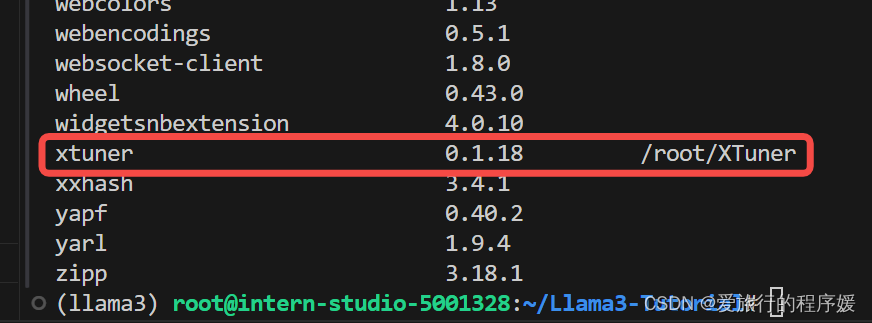
验证XTuner是否被安装在环境中
pip list
- 1
开始训练,使用 deepspeed 加速,A100 40G显存 耗时24分钟
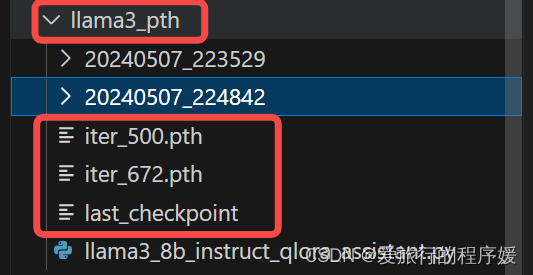
保存的模型在‘/root/llama3_pth’文件夹下
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
- 1
运行状态:

训练完成
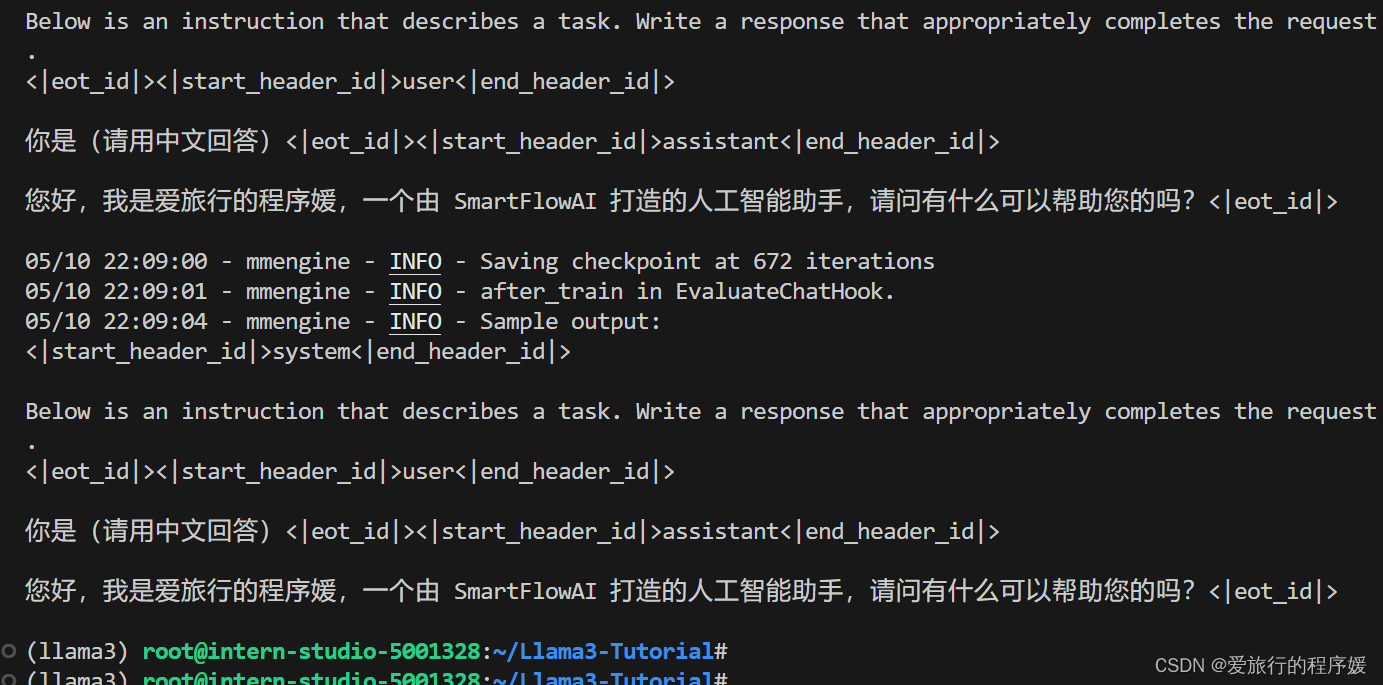
本次微调使用的是QLoRA
训练完成后,可以看到pth模型输出成功
Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
- 1
- 2
- 3
模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged
- 1
- 2
- 3
- 4
3.3 推理验证
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
/root/llama3_hf_merged
- 1
- 2
同样将8501端口复制到PORTS中,然后打开网页
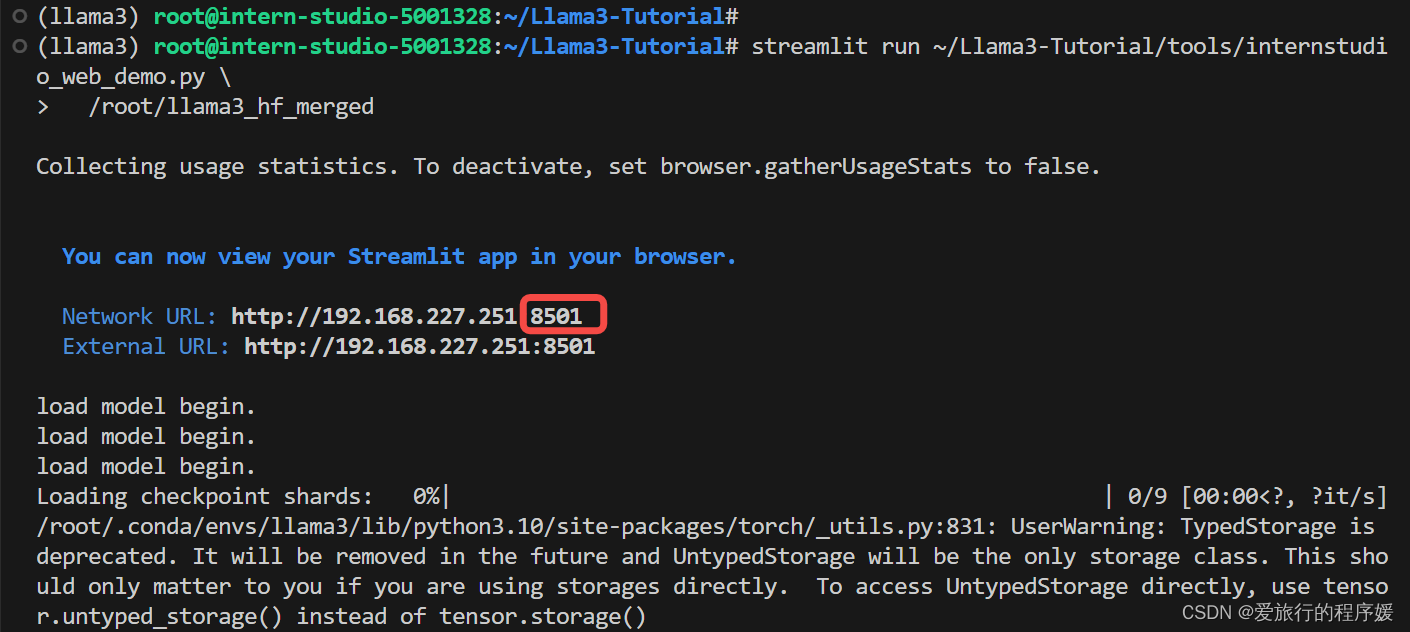
此时 Llama3 拥有了他是 SmartFlowAI 打造的人工智能助手的认知。


