- 1关闭windows defender安全中心的方法_安全中心关闭后又自动开启
- 2配置系统PATH环境变量
- 3Linux最新云计算 (持续更新中)(1),2024年最新看这篇文章就行了
- 4axios常用5种请求详解_axios请求
- 5根本上解决mysql启动失败问题Job for mysqld.service failed because the control process exited with error code_job for dmservicedmserver.service failed because t
- 6hive表的存储格式; ORC格式的使用_unsupported tablesink format(s): orc
- 7第三阶段Spark
- 8浅谈 HTTP协议(url/请求/响应/get/post)_post url上参数叫什么协议
- 9微信小程序生成分享二维码,自定义内容二维码_uniapp微信小程序将数据生成二维码并分享
- 10RabbitMQ面试题_rabbitmq的面试题
Transformer pytorch 代码解读(2)Encoder层
赞
踩
目录
0.Encoder层整体的架构
在每一个Encoder层中包括一个Multi-Head Attention层以及一个Feed Forward层。
Multi-Head Attention层主要就是进行attention的计算,QKV的矩阵运算都在这里。
Feed Forward层就是进行特征的提取,进行向前传播。
总的来看进入Multi-Head Attention层时数据的维度是(2,5,512)即(batch_size,len,d_model)。出Multi-Head Attention层时数据的维度也是(2,5,512)即(batch_size,len,d_model)。而前馈神经网络没有进行维度的变化,所以每个Encoder层进出的维度都是不变的。
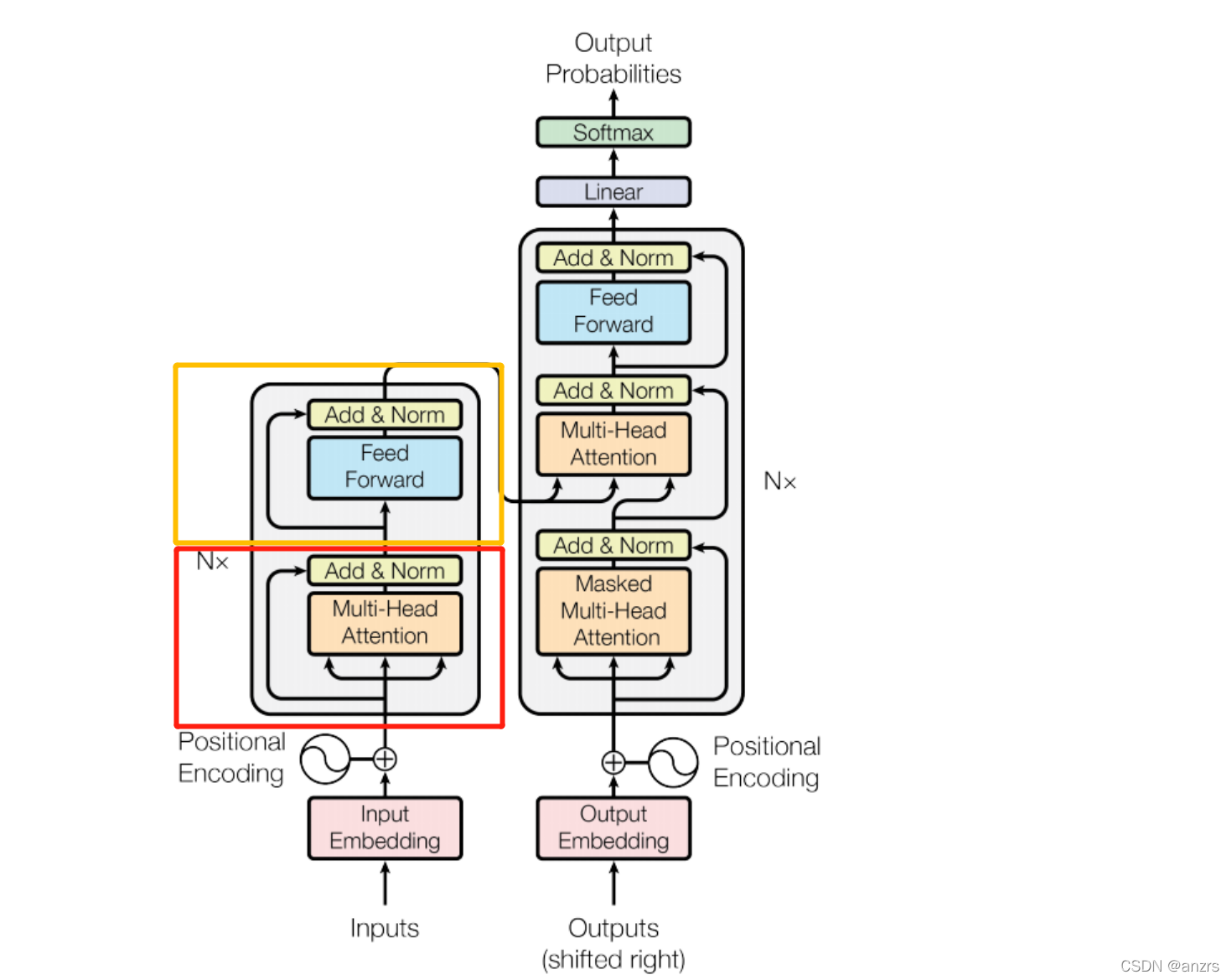
在这一层传入的是上一层的output,也就是之前(1)文中的(2,5,512)的数据。
(在进入多头注意力的计算之前,原始数据从(2,5)->(2,5,512)->(2,5,512),经过了两次变换,第一次是进行词编码,第二次虽然维度没有变换但是增加了位置的信息。)
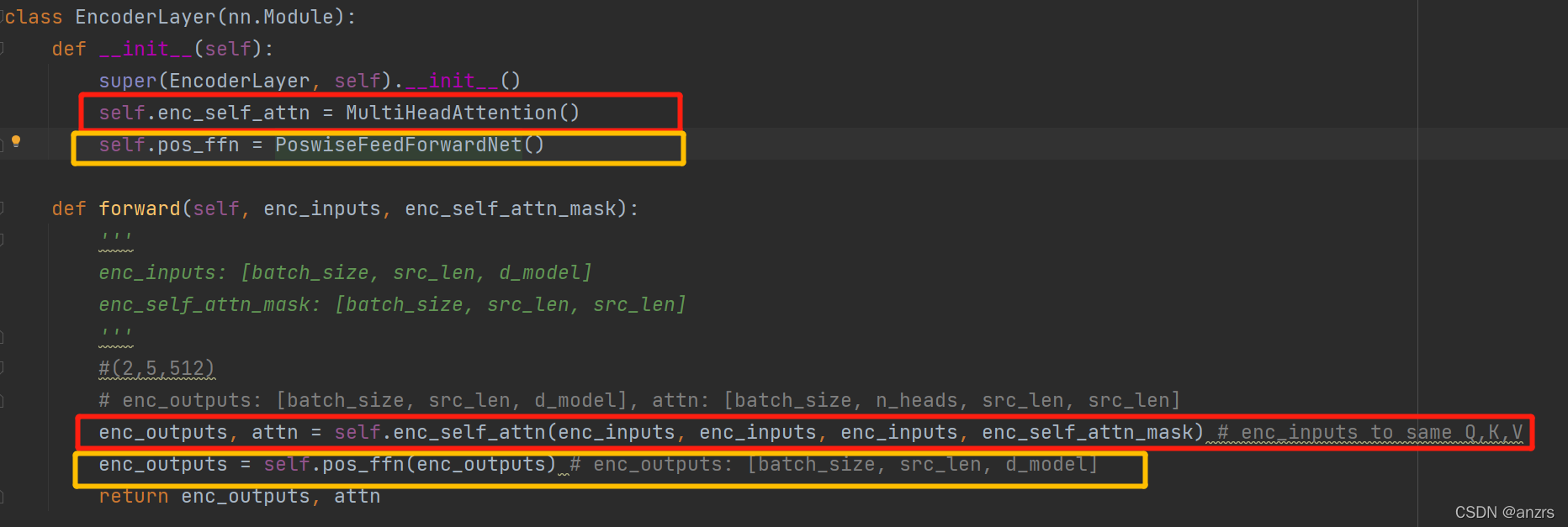
1.MultiHeadAttention()
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
在这一层对应的就是上层的红色部分,三个inputs的维度都是(2,5,512),attn_mask的维度是(2,5,5),attn_mask的样子是如下:
- torch.Size([2, 5, 5])
- tensor([[[False, False, False, False, True],
- [False, False, False, False, True],
- [False, False, False, False, True],
- [False, False, False, False, True],
- [False, False, False, False, True]],
-
- [[False, False, False, False, True],
- [False, False, False, False, True],
- [False, False, False, False, True],
- [False, False, False, False, True],
- [False, False, False, False, True]]])
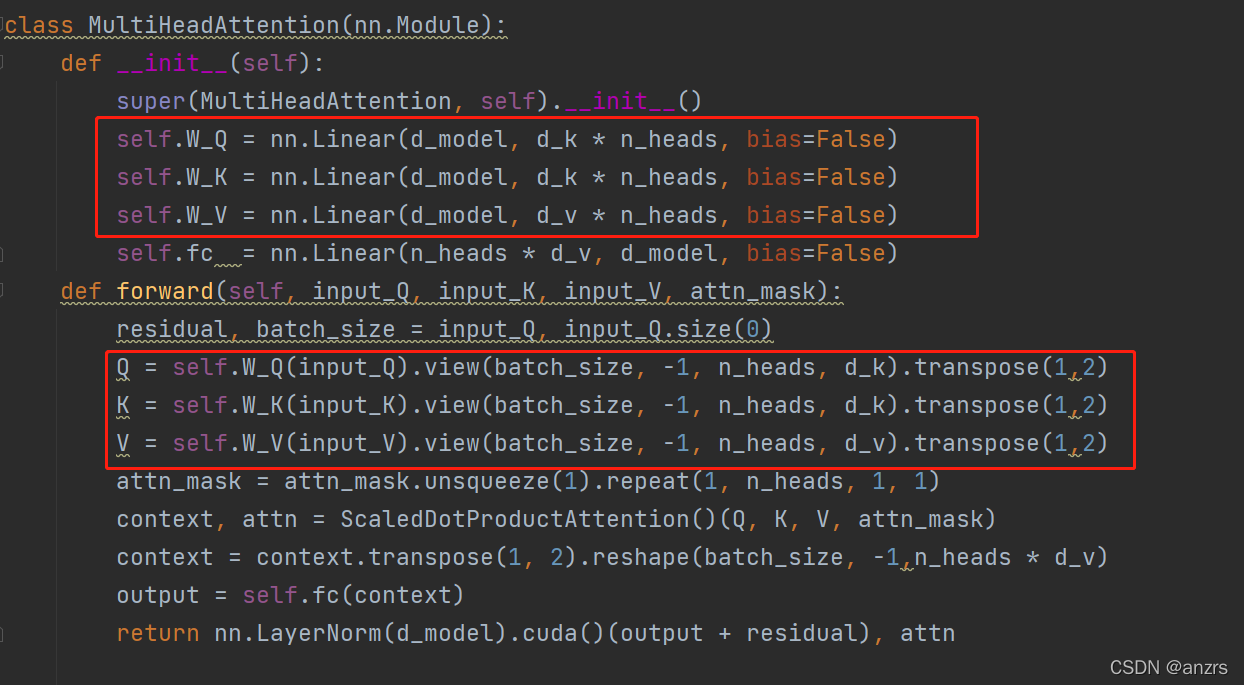
所谓的W_Q,K,V实际上就是一层Linear层,
在经过第一次相乘的时候,并没有展现出多头。维度还是(2,5,512)。

接下来会将Q矩阵进行维度的变化,同理K和V也是如此。

 经过黄色的这一步,attn_mask的尺度,变成了(2,8,5,5)。
经过黄色的这一步,attn_mask的尺度,变成了(2,8,5,5)。

总结一下,到现在Q,K,V的尺度是(2,5,8,64)而attn_mask的维度是(2,8,5,5)

这一步进行的是,
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
接下来将对ScaledDotProductAttention进行分析:
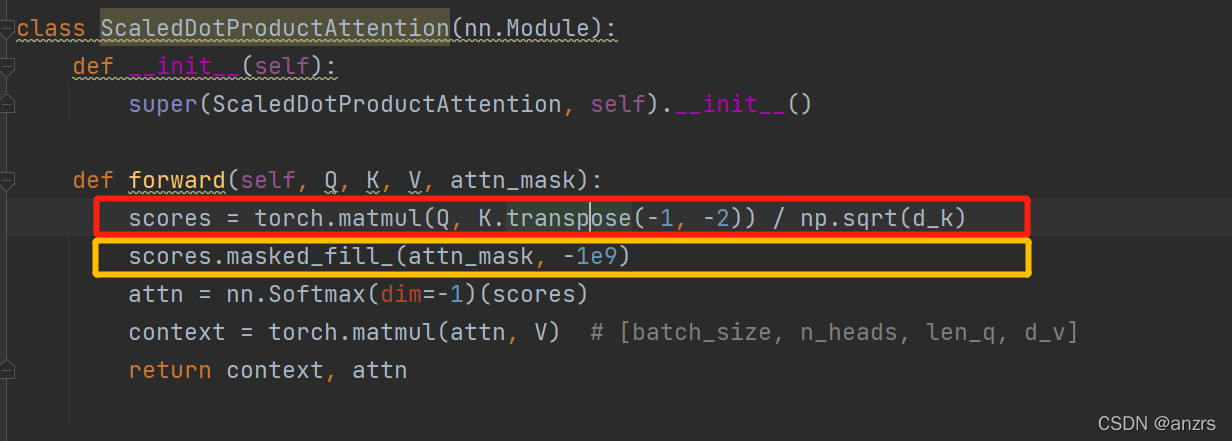
经过红色部分,Q(2,8,5,64)* K(2,8,64,5)-> scores(2,8,5,5)

经过黄色部分,会将attn_mask的为0的部分进行赋值为很负的负数,这样经过softmax这个部分就会接近于0。

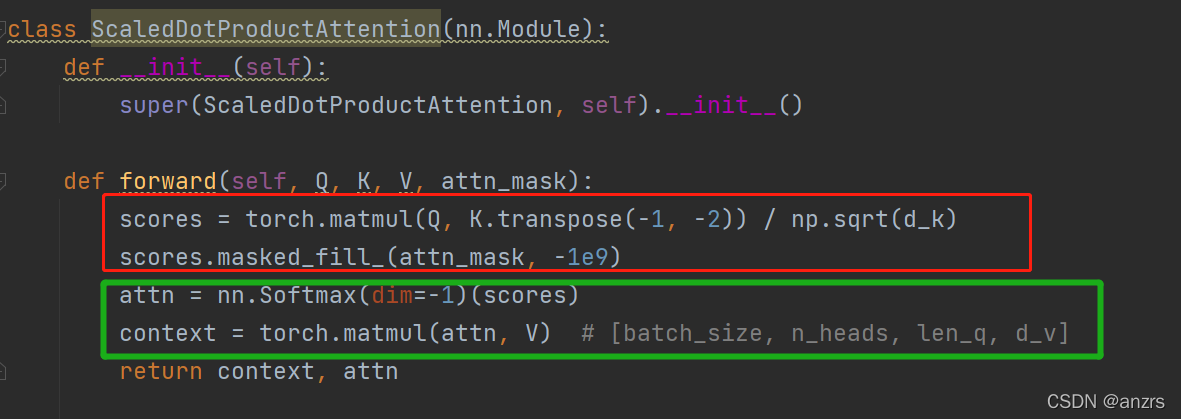
经过绿色的部分,第一句是进行softmax会将负的数变成0.

第二句是将attn和V进行相乘,(2,8,5,5)*(2,8,5,64)=(2,8,5,64)
也就是说返回的context是将
1.Q K进行相乘得到的scores
2.将scores进行pad位置填负
3.经过softmax
4.在进行和v相乘
返回的attn是前三步,也就是
1.Q K进行相乘得到的scores
2.将scores进行pad位置填负
3.经过softmax

如论文中所示。

接下来绿色的这一步是进行信息的提取以及维度的变换,

因为有用到残差连接,所以每次的维度到最后都是不变的。即(2,5,512)
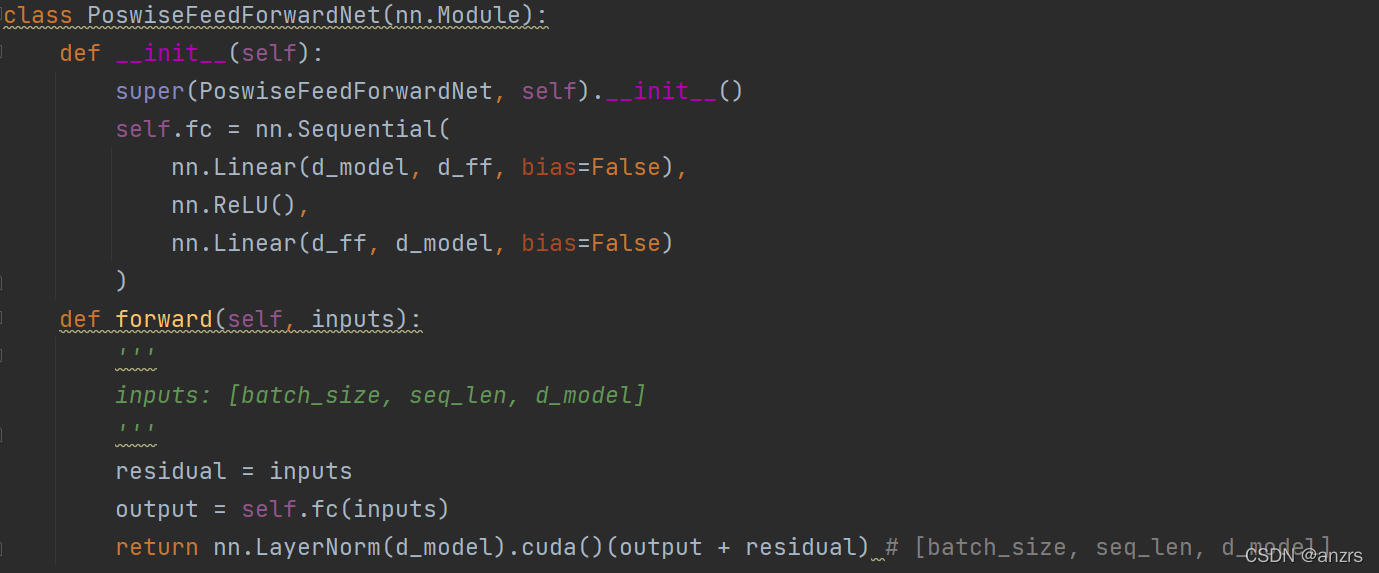
2.Feed Forward()
黄色部分 是前馈网络主要就是进行信息的提取进行前馈。这一层比较简单,主要就是一层Linear一层ReLU然后再一层Linear,维度是不变的。得到这一层EncoderLayer的输出是output,这一层的output就是下一层的inputs。
所以经过一层Encoder数据的维度是不变的,(2,5,512)即(batch_size,len,d_model)。