
- 1多相滤波器MATLAB仿真---抽取&插值
- 2版本控制工具——Git常用操作(上)_$ git pull --rebase origin master remote: enumerat
- 3PicGo安装与图床配置,配置gitee
- 4理解Dagger2在SystemUI中的使用_android systemui dagger
- 5Git分支的状态存储——stash命令的详细用法_git切换分支的存储怎么应用
- 6在Elasticsearch中,过滤器(Filter)是用于数据筛选的一种机制_es filter过滤器
- 7AI绘画教程:Midjourney 使用方法与技巧从入门到精通_ai绘图绘画软件midjourney教程
- 8开源项目推荐:基于YOLov5与OpenPose的智能摔倒检测系统
- 9Iterative error correction of long sequencing reads maximizes accuracy and improves contig assembly_iterative baited assembly (iba)
- 10CentOS 7(Linux系统) 安装sqlserver_centos7 sqlserver
Big Model Weekly | 第28期
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Applying LLMs for Rescoring N-best ASR Hypotheses of Casual Conversations: Effects of Domain Adaptation and Context Carry-over
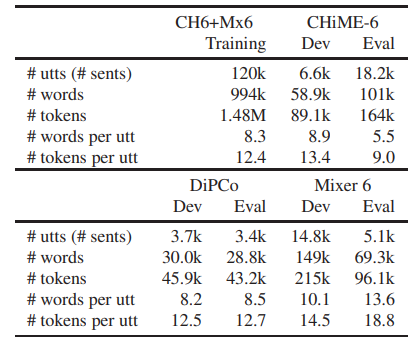
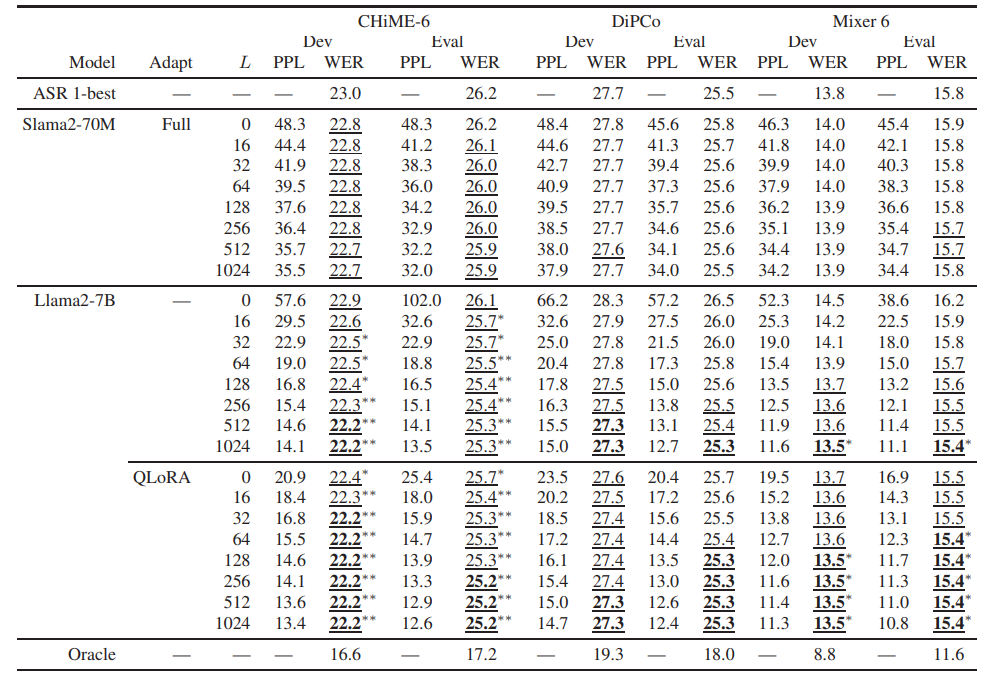
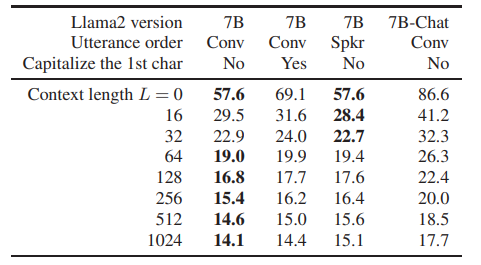
大语言模型(LLM)已成功应用于自动语音识别(ASR)假设的再评分。然而,他们的能力rescore ASR假设的随意交谈还没有得到充分的探讨。这项研究通过使用Llama 2对CHiME-7远距离ASR(DASR)任务执行N-最佳ASR假设重新评分来揭示这一点。Llama 2是最具代表性的LLM之一,CHiME-7 DASR任务提供了多个参与者之间的随意对话的数据集。作者调查域适应的LLM和上下文结转时,执行N-最好的重新评分的影响。实验结果表明,即使没有域自适应,Llama 2也优于标准大小的域自适应Transformer-LM,特别是在使用长上下文时。域自适应缩短了Llama 2实现其最佳性能所需的上下文长度,即,它降低了Llama 2的计算成本。

文章链接:
https://arxiv.org/pdf/2406.18972
02
DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment
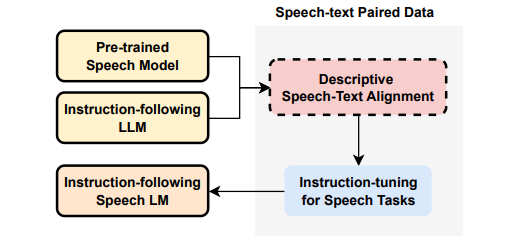
最近的语音语言模型(SLM)通常包含预训练的语音模型,以扩展大型语言模型(LLM)的功能。本文提出了一种描述性的语音文本对齐方法,利用语音字幕来弥合语音和文本模态之间的差距,使SLM能够解释和生成全面的自然语言描述,从而促进理解语音中的语言和非语言特征的能力。通过增强所提出的方法,模型表现出卓越的性能动态SUPERB基准,特别是在推广到看不见的任务。此外,作者发现,对齐的模型表现出zero-shot后续的能力,没有明确的语音指令调整。这些研究结果强调了通过整合丰富的描述性语音字幕来重塑预防性后续SLM的潜力。
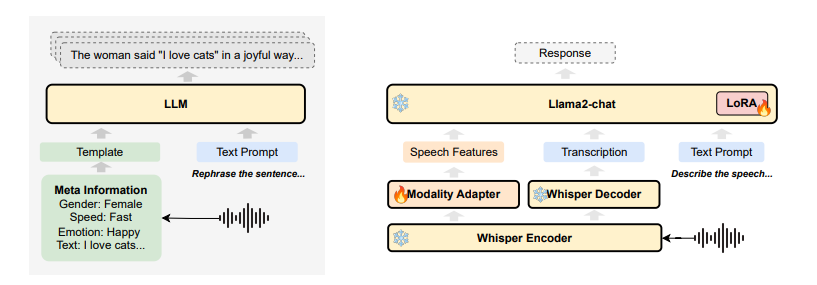
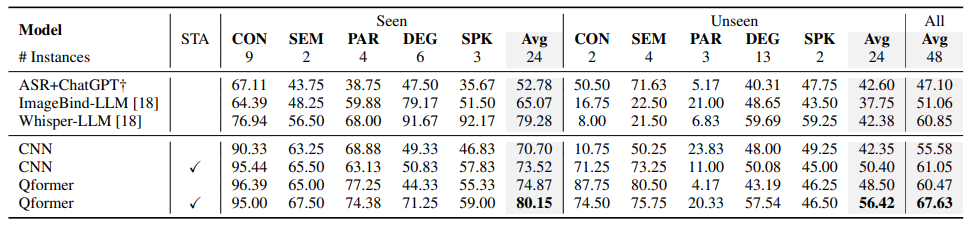
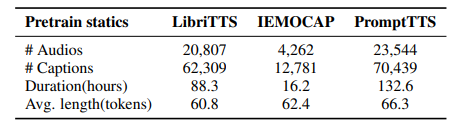
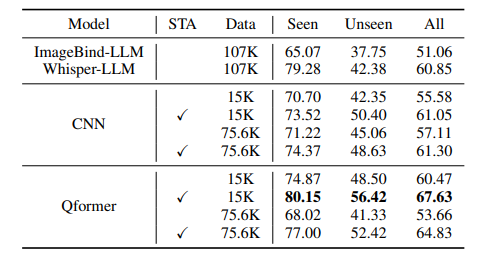
文章链接:
https://arxiv.org/pdf/2406.18871
03
Efficient World Models with Context-Aware Tokenization
在深度强化学习(RL)方法的扩展面临重大挑战的背景下,基于模型的RL作为一个强有力的竞争者正在崛起,紧随生成建模的发展步伐。最近在序列建模方面的进展导致了效果显著的基于Transformer的世界模型,尽管需要处理长序列令牌的高计算量来准确模拟环境。本工作提出了∆-IRIS,这是一种新的代理机制,其世界模型架构由一个编码随机时间步长增量的离散自编码器和一个自回归Transformer组成,通过连续令牌总结当前世界状态以预测未来增量。在Crafter基准测试中,∆-IRIS在多个帧预算下创造了新的技术水平,同时训练速度比以往基于注意力机制的方法快一个数量级。
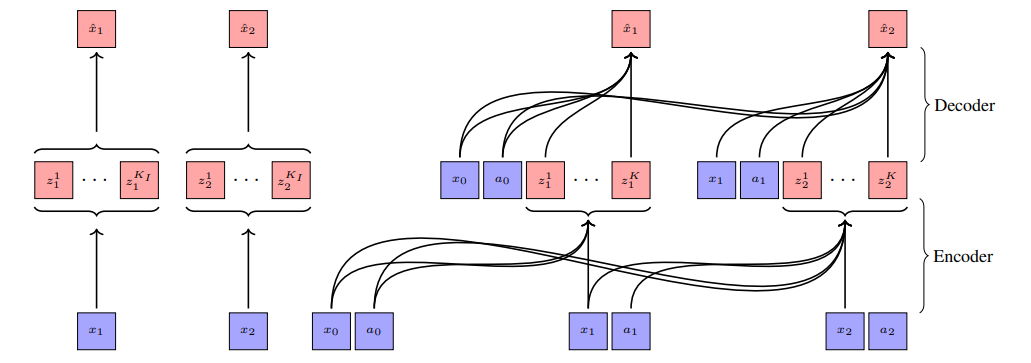
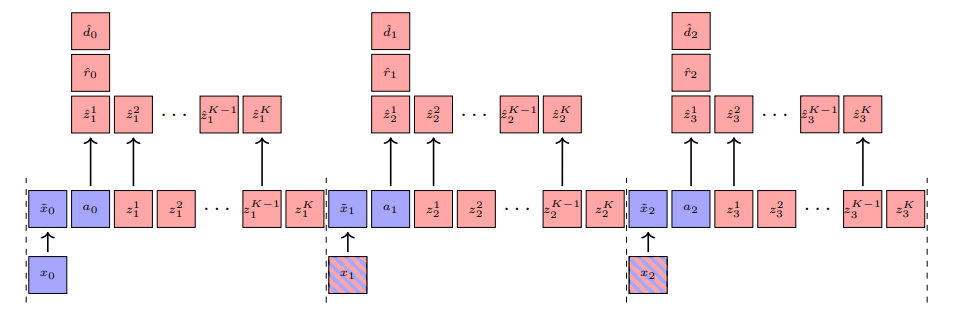

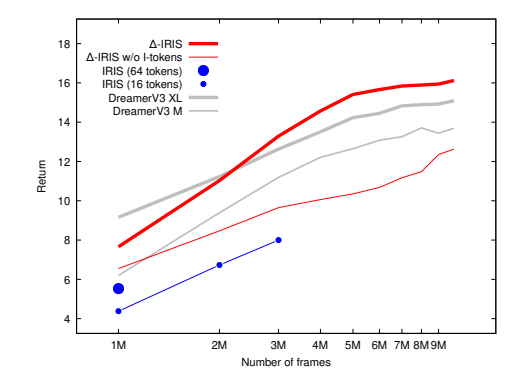
文章链接:
https://arxiv.org/pdf/2406.19320
04
From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
近期研究表明,大型语言模型(LLMs)在处理长上下文输入时,往往难以准确检索信息并保持推理能力。为解决这些限制,作者提出了一种微调方法,利用精心设计的合成数据集,包括数值键值检索任务。作者在诸如GPT-3.5 Turbo和Mistral 7B等模型上进行实验,结果显示,将LLMs在这一数据集上进行微调显著提升了它们在长上下文环境中的信息检索和推理能力。文章对微调模型进行了分析,展示了从合成任务到真实任务评估中技能的转移(例如,对于GPT-3.5 Turbo,在20篇文档MDQA的第10位置上提升了10.5%)。文中还发现,微调后的LLMs在通用基准测试中的表现几乎保持不变,而微调在其他基线长上下文增强数据上的LLMs可能会导致幻觉(例如,在TriviaQA上,Mistral 7B微调合成数据不会导致性能下降,而其他基线数据可能导致下降范围从2.33%到6.19%不等)。该研究突显了利用合成数据进行微调,提升LLMs在长上下文任


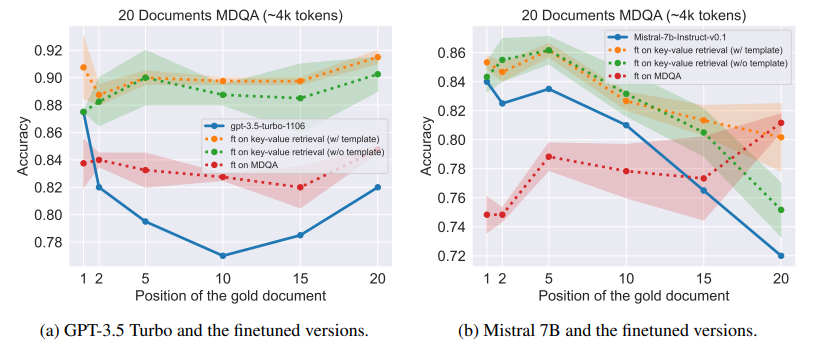
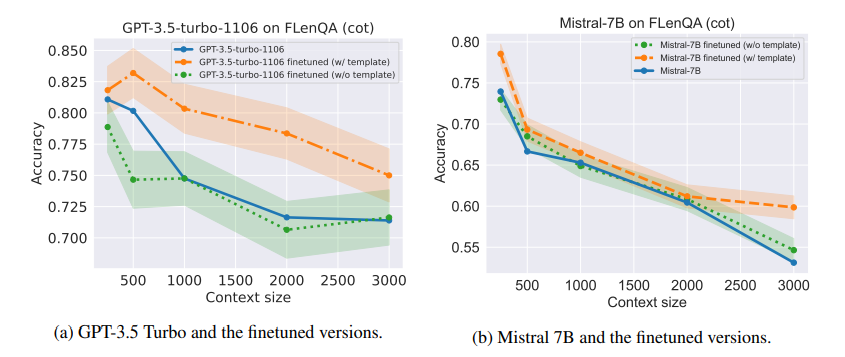

文章链接:
https://arxiv.org/pdf/2406.19292
05
Large Language Models are Interpretable Learners
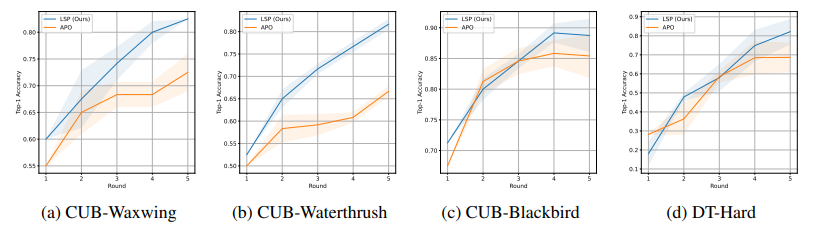
在构建以人为中心的分类和决策预测模型时,表达性与可解释性之间的权衡仍然是一个核心挑战。虽然符号规则提供了可解释性,但它们通常缺乏表达能力,而神经网络在性能上表现出色,但也因为黑盒特性而著称。本文展示了大型语言模型(LLMs)与符号程序的结合可以弥合这一差距。在提出的基于LLM的符号程序(LSPs)中,预训练的LLM通过自然语言提示提供了大量可解释的模块,这些模块可以将原始输入转化为自然语言概念。符号程序随后将这些模块集成到可解释的决策规则中。为了训练LSPs,作者采用了一种分而治之的方法,逐步从头开始构建程序,每个步骤的学习过程由LLMs引导。为了评估LSPs从数据中提取可解释且准确知识的效果,本文引入了IL-Bench,一个包含各种任务的集合,涵盖了不同模态的合成和真实场景。实证结果表明,与传统的神经符号程序和普通的自动提示调整方法相比,LSP表现出了更优越的性能。此外,由于LSP学习到的知识结合了自然语言描述和符号规则,因此易于转移给人类(可解释),其他LLMs,并且对分布外样本具有良好的泛化能力。
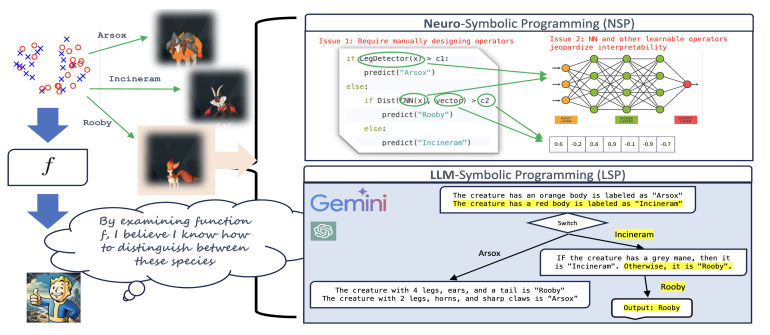
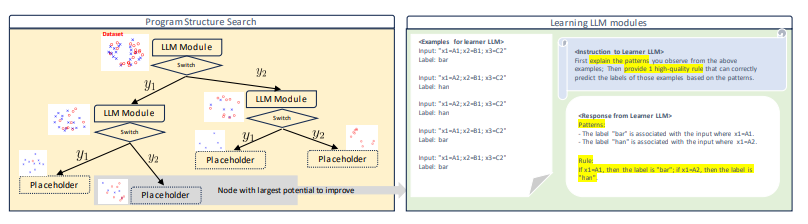

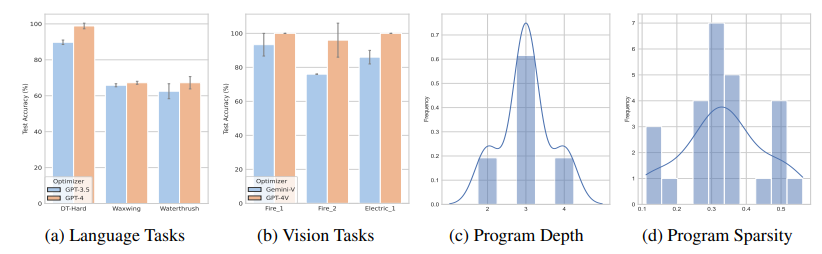
文章链接:
https://arxiv.org/pdf/2406.17224
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!

