
- 1什么是RPC?有哪些RPC框架?
- 2R9000P2021版拯救者 装ubuntu系统相关问题(WiFi、蓝牙、亮度调节,驱动安装)记录总结_r9000p重装蓝牙
- 3解决Spring Boot应用中的内存优化问题
- 4搭建hadoop+spark完全分布式集群环境
- 5软件测试除了做好功能测试自动化测试之外,如何在职位上获得提升?_测试工程师除了功能测试还能做什么
- 6BERT参数计算,RBT3模型结构
- 7Android Studio运行项目_android studio怎么运行当前项目csdn
- 8量化机器人能否实现多资产交易?
- 9深度学习环境配置_ubuntu18及以上_nvcc fatal : failed to preprocess host compiler pr
- 10数据库逻辑设计 完全函数依赖、部分函数依赖、传递函数依赖、码、候选码、主码、范式_数据库部分函数依赖
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战_langchain rag
赞
踩
Retrieval-Augmented Generation(RAG)是一种强大的技术,能够提高大型语言模型(LLM)的性能,使其能够从外部知识源中检索信息以生成更准确、具有上下文的回答。
本文将详细介绍 RAG 在 LangChain 中的应用,以及如何构建一个简单的 RAG 管道。
LangChain 是什么
LangChain 是一个强大的自然语言处理工具,提供了丰富的功能来简化文本处理和信息检索任务。它的强大之处在于可以无缝集成不同的组件,从而构建复杂的文本处理管道。
RAG 是什么
RAG 的核心思想是将语言模型(LLM)与检索模块结合起来,使其能够利用外部知识源的信息。这有助于生成更加准确和上下文相关的回答,从而减少幻觉(hallucination)的风险。
RAG 工作原理分为两个主要阶段:
索引阶段
该阶段是信息检索系统中的一个关键步骤,旨在将原始数据(例如文档、文本等)进行处理和组织,以便后续能够更快速、有效地检索和获取相关信息。
以下是索引阶段的主要组成部分:
-
索引: 数据被处理成一个索引结构,其中特定的信息块被赋予唯一的标识符或值。索引结构充当后续检索操作的入口,加速信息查找的过程。
-
文档加载器: 负责从各种来源(如私有S3存储桶、信息网站、社交平台等)获取原始数据。文档加载器的任务是将原始数据导入系统,以便进行后续的处理和索引。
-
文档转换器: 对原始文档进行处理,将其转换成更容易处理的形式。这可能包括将大型文档分解为小块,准备文档以便后续的信息检索。
-
文本嵌入模型: 一旦文档被转换,系统会使用文本嵌入模型为文本创建嵌入。嵌入捕捉文本的潜在语义含义,使得后续的检索可以更准确地匹配用户查询。
-
向量存储: 为了存储处理后的数据和相应的嵌入,系统提供与多种向量存储的连接。
检索和生成阶段
该阶段是信息检索系统中的两个关键步骤,涉及根据用户的查询检索相关信息并生成自然语言响应。以下是的主要组成部分:
-
检索: 在用户提出问题时,系统使用检索器从存储中获取与用户需求相关的信息。这类似于搜索引擎,系统寻找匹配用户问题的数据片段。
-
生成: 获取所需信息后,ChatModel 或大语言模型(LLM)介入,通过将用户的问题与获取的数据结合,生成自然而直接相关的响应。
RAG 的工作流程
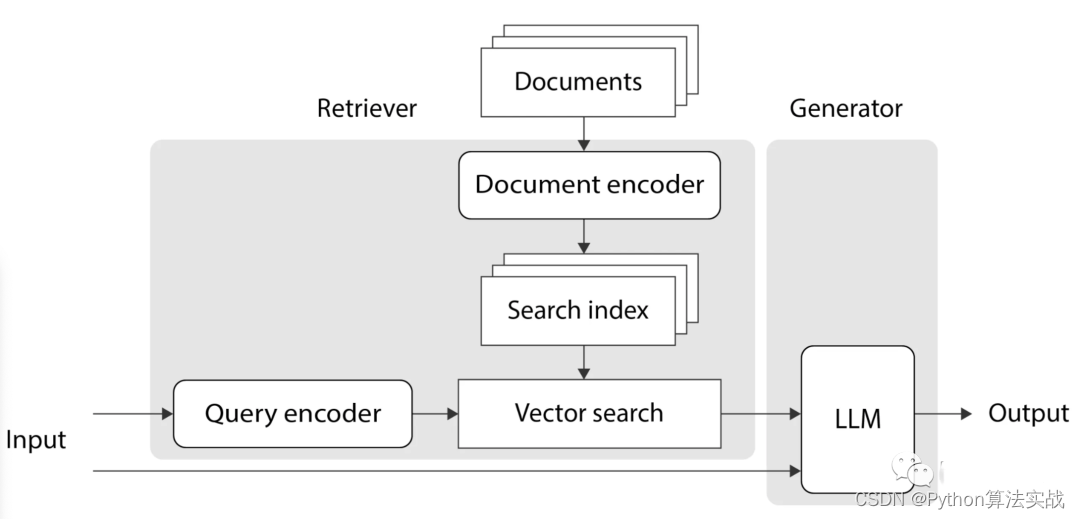
RAG 的工作流程主要分为三个步骤:检索、增强和生成。
-
检索: 使用用户查询从外部知识源中检索相关上下文。将用户查询嵌入到向量空间中,与向量数据库中的附加上下文进行相似性搜索,返回前 N 个最接近的数据对象。
-
增强: 使用用户查询和检索到的附加上下文填充提示模板。
-
生成: 将经过检索增强的提示传递给LLM。
通俗易懂讲解大模型系列
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群

配置与准备
在开始使用 LangChain 之前,首先需要安装必要的依赖。以下是配置OpenAI 环境和安装所需依赖项的代码:
!pip install openai --quiet
!pip install langchain --quiet
!pip install docx2txt --quiet
!pip install weaviate-client --quiet
- 1
- 2
- 3
- 4
然后,配置 OpenAI 环境的代码如下:
import os
# 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
- 1
- 2
- 3
- 4
文档处理与分段
接下来,加载并处理示例文档。这包括使用文档加载器加载文档,然后将其分成较小的段落。
from langchain.document_loaders import Docx2txtLoader
from langchain.text_splitter import CharacterTextSplitter
# 加载文档
document_path = "文件路径"
loader = Docx2txtLoader(document_path)
documents = loader.load()
# 分割文档
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
文本嵌入与向量存储
现在,使用 LangChain 进行文本嵌入和向量存储,以便后续的检索操作。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
# 初始化 OpenAI 嵌入模型
embeddings = OpenAIEmbeddings()
# 创建Weaviate向量数据库
vectorstore = Weaviate.from_documents(
client=weaviate.Client(embedded_options=EmbeddedOptions()),
documents=texts,
embedding=embeddings,
by_text=False
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
检索链的创建
接下来,将演示如何在 LangChain 中创建检索链。使用一个示例文档,并将其分段以便进行更有效的检索。
基于文档填充的检索链
from langchain.chains import RetrievalQA
# 创建 RetrievalQA 检索链
retriever = vectorstore.as_retriever()
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0), chain_type="stuff", retriever=retriever)
# 运行查询
query = "这文档里都有什么内容?"
result = qa_map_reduce.run(query)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Map-Reduce 文档链
from langchain.chains import RetrievalQA
# 构建 Map-Reduce文档链
retriever = vectorstore.as_retriever()
qa_map_reduce = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="map_reduce", retriever=retriever)
# 运行查询
query = "这文档里都有什么内容?"
result = qa_map_reduce.run(query)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
优化文档链
from langchain.chains import RetrievalQA
# 构建优化文档链
retriever = vectorstore.as_retriever()
qa_refine = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="refine", retriever=retriever)
# 运行查询
query = "这文档里都有什么内容?"
result = qa_refine.run(query)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
RAG 实现示例
1. 基础设置和文档处理:通过 LangChain 处理文本数据,将其嵌入为向量,并通过 Weaviate 向量数据库,为文本搜索或相似性匹配提供支持。
import requests
from weaviate import Weaviate, Client, EmbeddedOptions
from weaviate.language_embedding.vectorization import OpenAIEmbeddings
from weaviate.util import CharacterTextSplitter, TextLoader
import dotenv
# 加载环境变量
dotenv.load_dotenv()
# 下载数据
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
# 使用 TextLoader 加载文本
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
# 使用 CharacterTextSplitter 拆分文本成小块
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# 初始化 Weaviate 客户端
client = Client(embedded_options=EmbeddedOptions())
# 在 Weaviate 中创建向量存储
vectorstore = Weaviate.from_documents(
client=client,
documents=chunks,
embedding=OpenAIEmbeddings(),
by_text=False
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2. 构建 RAG Pipline:使用 RAG 模型进行问答对话,通过检索上下文信息来支持生成更精准的回答。
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
# 定义检索器
retriever = vectorstore.as_retriever()
# 准备中文prompt模板
template = """你是一个用于问答任务的助手。
使用以下检索到的上下文片段来回答问题。
如果你不知道答案,只需说你不知道。
最多使用三句话,保持回答简洁。
问题: {question}
上下文: {context}
回答:
"""
prompt = ChatPromptTemplate.from_template(template)
# 定义LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 构建RAG链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 运行RAG链
query = "总结内容并列出关键词."
result = rag_chain.invoke(query)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
以上就是一个简单的 RAG Pipline 的构建和运行过程。通过这种方式,LangChain 提供了一种方便而强大的方法来实现检索增强生成任务,使得语言模型能够更好地利用外部知识源来提高其性能。
总结
LangChain 提供了丰富的组件和功能,使得 RAG 的实现变得简单而灵活。通过检索增强生成,使我们能够充分利用大语言模型和外部知识源,生成更加准确和具有上下文的回答,从而提高自然语言处理任务的性能。
引用
- https://github.com/langchain-ai/langchain
- https://python.plainenglish.io/rag-using-langchain-c371fcd02d13
- https://towardsdatascience.com/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2

