
- 1Leetcode 刷题笔记:字符串篇_字符串变形 leetcode
- 2【解刊】IEEE(Trans)系列,CCF-A类顶刊,国人友好,无需版面费!_ieice的trans需要版面费吗
- 3SQL Server的数据库创建、修改、查询、删除_sql新建数据库查询物理信息(2)_sql server数据库删除
- 4记一次公司阿里云被黑_sh -c echo iyevymlul2jhc2gkcgtpbgwglwygenn2ywpwa2l
- 5Centos7 执行sudo命令时,系统提示is not in the sudoers file. This incident will be reported.解决办法_cc is not in the sudoers file.
- 6Idea下载github代码失败,如何使用git直接下载代码到本地目录_idea下载代码
- 7Python语法(全)_python的语法
- 8python趣味编程-如何实现俄罗斯方块_基于python的俄罗斯方块小游戏的实现
- 9MySQL——常见数据类型_mysql 无符号整数
- 10python怎么查文献_查询论文的引用格式,支持批量查询
基于Bert模型的美团外卖评论文本情感分类(附完整代码与训练过程)_美团外卖评论数据集
赞
踩
基于Bert模型的美团外卖评论数据集的文本情感分类,是自然语言处理领域的经典案例之一。
这篇文章我将带大家使用 SwanLab、Transformers、datasets 三个开源工具,完成从数据集准备、代码编写、可视化训练的全过程。
观察了一下,中文互联网上似乎很少有能直接跑起来的Bert训练代码和教程,所以也希望这篇文章可以帮到大家。
- 代码:完整代码直接看本文第5节
- 模型:bert-base-chinese
- 数据集:XiangPan/waimai_10k - HuggingFace
- 实验过程:Bert-Meituan - SwanLab
- SwanLab:https://swanlab.cn
- transformers:transformers
- datasets:datasets
1.环境安装
我们需要安装以下这4个Python库:
transformers>=4.41.0
datasets>=2.19.1
swanlab>=0.3.8
- 1
- 2
- 3
一键安装命令:
pip install transformers datasets swanlab
- 1
他们的作用分别是:
transformers:HuggingFace出品的深度学习框架,已经成为了NLP(自然语言处理)领域最流行的训练与推理框架。代码中用transformers主要用于加载模型、训练以及推理。datasets:同样是HuggingFace出品的数据集工具,可以下载来自huggingface社区上的数据集。代码中用datasets主要用于下载、加载数据集。swanlab:一个深度学习实验管理与训练可视化工具,由西安电子科技大学团队打造,官网, 融合了Weights & Biases与Tensorboard的特点,可以记录整个实验的超参数、指标、训练环境、Python版本等,并可视化图表,帮助你分析训练的表现。本项目用swanlab主要用于记录指标和可视化。
本文的代码测试于transformers4.41.0、datasets2.19.1、swanlab==0.3.8,更多库版本可查看SwanLab记录的Python环境。
2. 加载BERT模型
BERT模型我们直接下载来自HuggingFace上由Google发布的bert-case-chinese(中文版Bert)预训练模型。
执行下面的代码,会自动下载模型权重并加载模型:
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
# 加载预训练的BERT tokenizer
model = AutoModelForSequenceClassification.from_pretrained('google-bert/bert-base-chinese', num_labels=2)
- 1
- 2
- 3
- 4
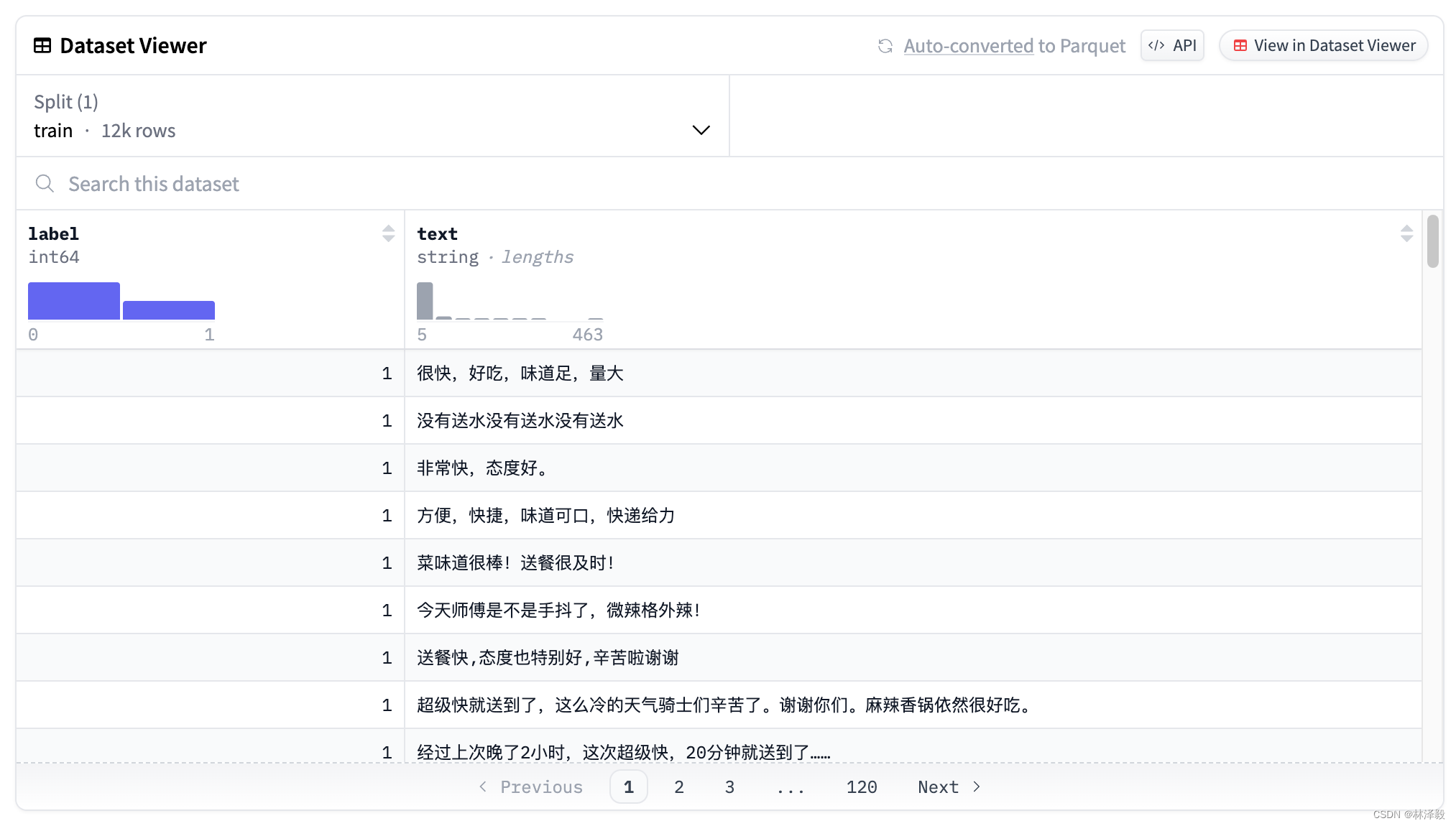
3. 加载Meituan数据集
美团外卖数据集(waimai_10k)包含了1.2万条外卖评价以及它们的情感标签(积极或消极):
from datasets import load_dataset
# 加载美团外卖数据集
dataset = load_dataset('XiangPan/waimai_10k')
- 1
- 2
- 3
- 4
4. 集成SwanLab
因为swanlab已经和transformers框架做了集成,所以将SwanLabCallback类传入到trainer的callbacks参数中即可实现实验跟踪和可视化:
from swanlab.integration.huggingface import SwanLabCallback # 设置swanlab回调函数 swanlab_callback = SwanLabCallback( project="Bert-meituan", experiment_name="Bert-美团外卖评价分析", ) ... # 定义Transformers Trainer trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets['train'], eval_dataset=tokenized_datasets['test'], # 传入swanlab回调函数 callbacks=[swanlab_callback], )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
想了解更多关于SwanLab的知识,请看SwanLab官方文档。
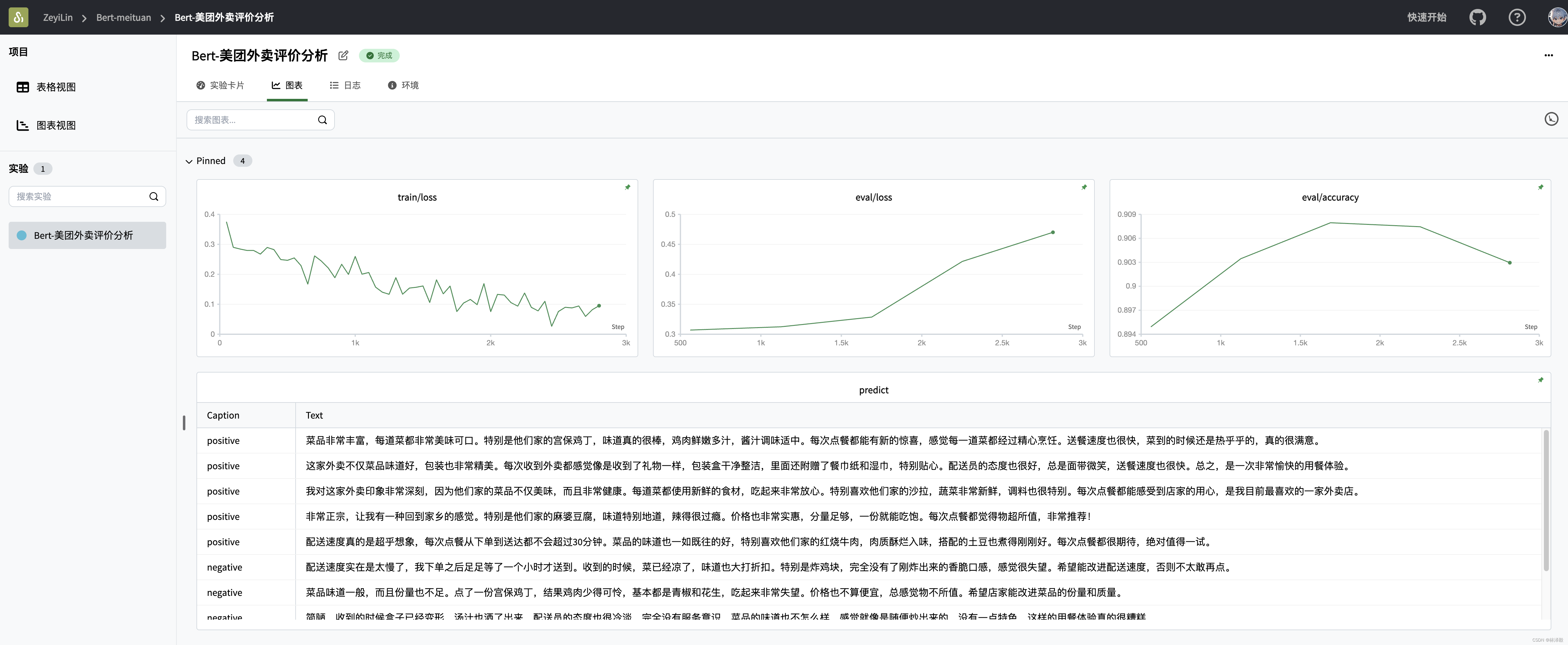
5. 开始训练!
训练过程看这里:Bert-Meituan - SwanLab
在首次使用SwanLab时,需要去官网注册一下账号,然后在用户设置复制一下你的API Key。
然后在终端输入swanlab login:
swanlab login
- 1
把API Key粘贴进去即可完成登录,之后就不需要再次登录了。
完整的训练代码:
import evaluate import numpy as np from swanlab.integration.huggingface import SwanLabCallback from datasets import load_dataset import torch import swanlab from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True) def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) def predict(text, model, tokenizer): inputs = tokenizer(text, return_tensors="pt") with torch.no_grad(): outputs = model(**inputs) logits = outputs.logits predicted_class = torch.argmax(logits).item() return int(predicted_class) CLASS_NAME = {0: "negative", 1: "positive"} dataset = load_dataset("XiangPan/waimai_10k") tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese") tokenized_datasets = dataset.map(tokenize_function, batched=True) # 将数据集划分为训练集和验证集 datasets_all = tokenized_datasets["train"].shuffle(seed=42) train_dataset = datasets_all.select(range(9000)) eval_dataset = datasets_all.select(range(9001,11000)) metric = evaluate.load("accuracy") model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-chinese", num_labels=2) training_args = TrainingArguments( output_dir="./results", eval_strategy="epoch", save_strategy="epoch", learning_rate=2e-5, weight_decay=0.01, num_train_epochs=1, logging_steps=50, per_device_train_batch_size=8, per_device_eval_batch_size=8, report_to="none", ) # 实例化SwanLabCallback swanlab_callback = SwanLabCallback( project="Bert-meituan", experiment_name="Bert-美团外卖评价分析", ) trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, compute_metrics=compute_metrics, # 传入callbacks参数 callbacks=[swanlab_callback], ) trainer.train() # 测试模型 test_reviews = [ "菜品非常丰富,每道菜都非常美味可口。特别是他们家的宫保鸡丁,味道真的很棒,鸡肉鲜嫩多汁,酱汁调味适中。每次点餐都能有新的惊喜,感觉每一道菜都经过精心烹饪。送餐速度也很快,菜到的时候还是热乎乎的,真的很满意。", "这家外卖不仅菜品味道好,包装也非常精美。每次收到外卖都感觉像是收到了礼物一样,包装盒干净整洁,里面还附赠了餐巾纸和湿巾,特别贴心。配送员的态度也很好,总是面带微笑,送餐速度也很快。总之,是一次非常愉快的用餐体验。", "我对这家外卖印象非常深刻,因为他们家的菜品不仅美味,而且非常健康。每道菜都使用新鲜的食材,吃起来非常放心。特别喜欢他们家的沙拉,蔬菜非常新鲜,调料也很特别。每次点餐都能感受到店家的用心,是我目前最喜欢的一家外卖店。", "非常正宗,让我有一种回到家乡的感觉。特别是他们家的麻婆豆腐,味道特别地道,辣得很过瘾。价格也非常实惠,分量足够,一份就能吃饱。每次点餐都觉得物超所值,非常推荐!", "配送速度真的是超乎想象,每次点餐从下单到送达都不会超过30分钟。菜品的味道也一如既往的好,特别喜欢他们家的红烧牛肉,肉质酥烂入味,搭配的土豆也煮得刚刚好。每次点餐都很期待,绝对值得一试。", "配送速度实在是太慢了,我下单之后足足等了一个小时才送到。收到的时候,菜已经凉了,味道也大打折扣。特别是炸鸡块,完全没有了刚炸出来的香脆口感,感觉很失望。希望能改进配送速度,否则不太敢再点。", "菜品味道一般,而且份量也不足。点了一份宫保鸡丁,结果鸡肉少得可怜,基本都是青椒和花生,吃起来非常失望。价格也不算便宜,总感觉物不所值。希望店家能改进菜品的份量和质量。", "简陋,收到的时候盒子已经变形,汤汁也洒了出来。配送员的态度也很冷淡,完全没有服务意识。菜品的味道也不怎么样,感觉就像是随便炒出来的,没有一点特色。这样的用餐体验真的很糟糕。", "每一道菜都非常油腻,吃起来很不舒服。特别是他们家的红烧肉,油腻得让人无法下咽,完全没有食欲。配送速度也很慢,收到的时候菜已经冷了。希望店家能改进菜品质量,否则真的不会再点了。", "这家外卖的价格实在是太高了,性价比很低。点了一份麻婆豆腐,味道很一般,完全不值这个价钱。而且份量也很少,根本吃不饱。配送速度也不快,整体用餐体验非常差。希望店家能调整价格,提升菜品质量。" ] model.to('cpu') text_list = [] for review in test_reviews: label = predict(review, model, tokenizer) text_list.append(swanlab.Text(review, caption=f"{CLASS_NAME[label]}")) if text_list: swanlab.log({"predict": text_list}) # (可选) # swanlab.finish()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
训练可视化过程:
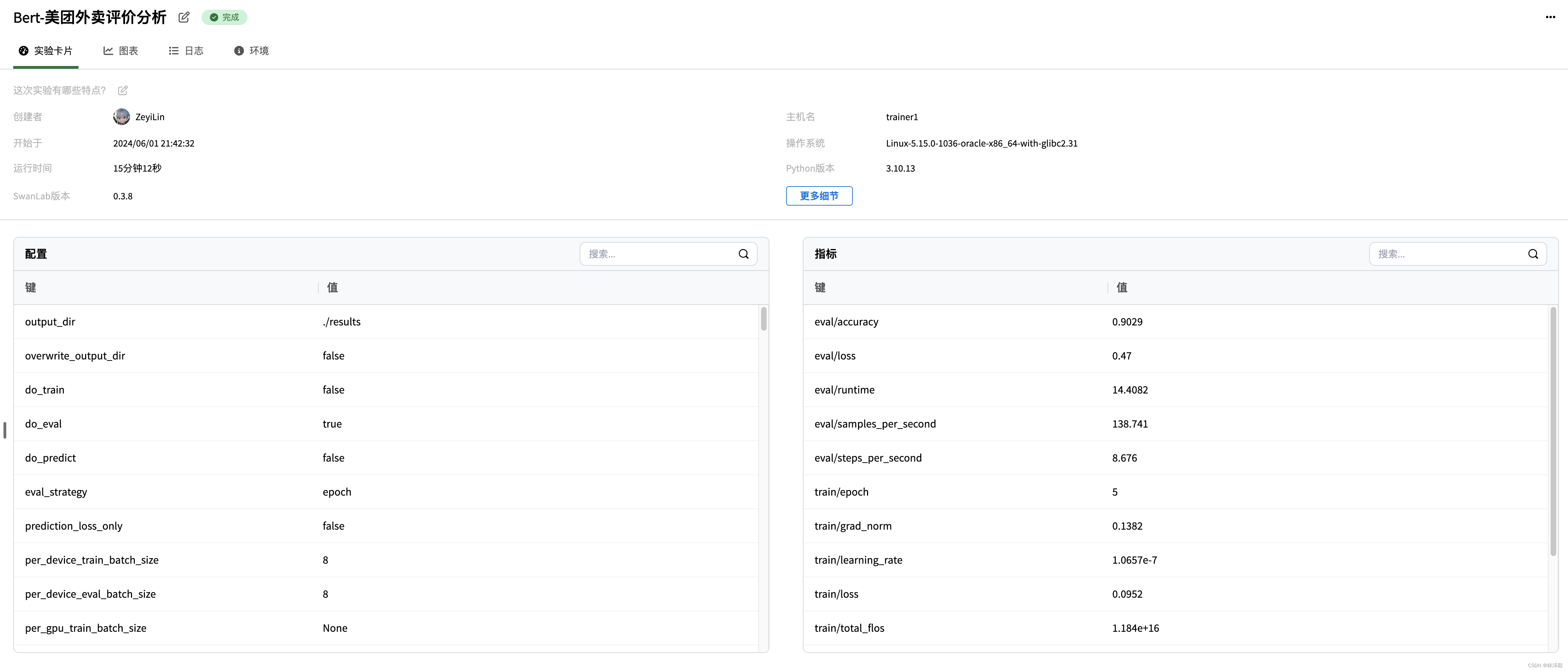
这里我生成了10个模拟美团评价的文本,微调后的BERT模型基本都能答对。

至此,我们顺利完成了用Bert模型微调美团外卖评论数据集的训练过程~
相关链接
- 代码:完整代码直接看本文第5节
- 模型:bert-base-chinese
- 数据集:XiangPan/waimai_10k - HuggingFace
- 实验过程:Bert-Meituan - SwanLab
- SwanLab:https://swanlab.cn
- transformers:transformers
- datasets:datasets

