
- 12024年HarmonyOS鸿蒙最全备考cisp拿证,收藏这一篇就够了(1),鸿蒙view的绘制流程面试_cisp复习资料
- 2java试卷练习1_若要给当前的程序添加一个包名,添加包名的语句关键字为: 应该放在程序的位置 为:
- 3利用 Selenium 和 Python 实现网页新闻链接抓取
- 4springCloud + eureka + zuul实现多版本控制和灰度发布_feign+eueka如何实现灰度
- 5Oracle的sql常用技巧_oracle sql解题技巧总结
- 6国家开放大学2021春1474临床医学概论(本)题目_国开临床医学概论
- 7大语言模型——语言模型的发展历程_大语言模型发展历程
- 8基于LLM+场景识别+词槽实体抽取实现多轮问答_llm 多轮对话
- 9Android自定义锁屏实现----仿正点闹钟滑屏解锁_android 滑动开锁效果
- 102025江苏科技大学计算机考研信息汇总_江苏科技大学大学计算机考研知乎2025
NLP进阶,Bert+BiLSTM情感分析实战,被面试官问的Python-Framework难倒了
赞
踩

将数据集放在工程的根目录
==================================================================
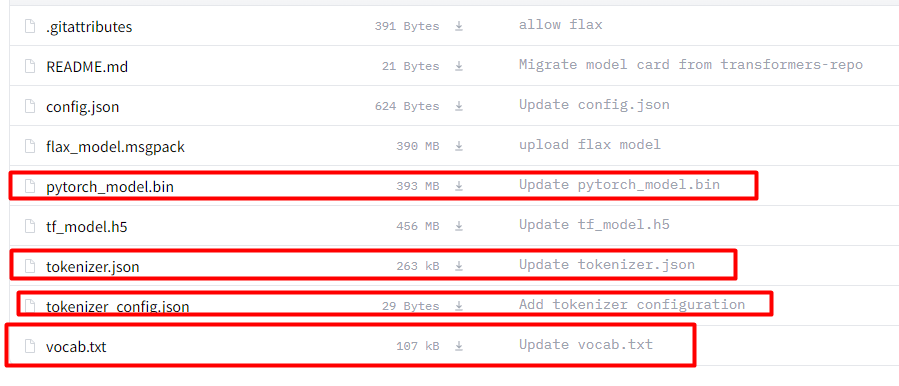
下载地址:https://huggingface.co/bert-base-chinese/tree/main。
我们的数据集是中文,所以,选择中文的预训练模型,这点要注意,如果选择其他的可能会出现不收敛的情况。将下图中画红框的文件加载下来。
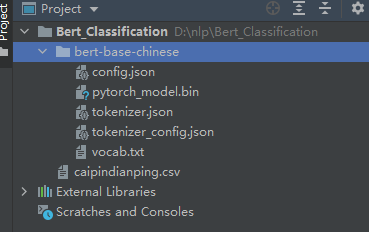
在工程的根目录,新建文件夹“bert_base_chinese”,将下载的模型放进去,如下图:
=============================================================
思路:将bert做为嵌入层提取特征,然后传入BiLSTM,最后使用全连接层输出分类。创建bert_lstm模型,代码如下:
class bert_lstm(nn.Module):
def init(self, bertpath, hidden_dim, output_size,n_layers,bidirectional=True, drop_prob=0.5):
super(bert_lstm, self).init()
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.bidirectional = bidirectional
#Bert ----------------重点,bert模型需要嵌入到自定义模型里面
self.bert=BertModel.from_pretrained(bertpath)
for param in self.bert.parameters():
param.requires_grad = True
LSTM layers
self.lstm = nn.LSTM(768, hidden_dim, n_layers, batch_first=True,bidirectional=bidirectional)
dropout layer
self.dropout = nn.Dropout(drop_prob)
linear and sigmoid layers
if bidirectional:
self.fc = nn.Linear(hidden_dim*2, output_size)
else:
self.fc = nn.Linear(hidden_dim, output_size)
#self.sig = nn.Sigmoid()
def forward(self, x, hidden):
batch_size = x.size(0)
#生成bert字向量
x=self.bert(x)[0] #bert 字向量
lstm_out
#x = x.float()
lstm_out, (hidden_last,cn_last) = self.lstm(x, hidden)
#print(lstm_out.shape) #[32,100,768]
#print(hidden_last.shape) #[4, 32, 384]
#print(cn_last.shape) #[4, 32, 384]
#修改 双向的需要单独处理
if self.bidirectional:
#正向最后一层,最后一个时刻
hidden_last_L=hidden_last[-2]
#print(hidden_last_L.shape) #[32, 384]
#反向最后一层,最后一个时刻
hidden_last_R=hidden_last[-1]
#print(hidden_last_R.shape) #[32, 384]
#进行拼接
hidden_last_out=torch.cat([hidden_last_L,hidden_last_R],dim=-1)
#print(hidden_last_out.shape,‘hidden_last_out’) #[32, 768]
else:
hidden_last_out=hidden_last[-1] #[32, 384]
dropout and fully-connected layer
out = self.dropout(hidden_last_out)
#print(out.shape) #[32,768]
out = self.fc(out)
return out
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
number = 1
if self.bidirectional:
number = 2
if (USE_CUDA):
hidden = (weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float().cuda(),
weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float().cuda()
)
else:
hidden = (weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float(),
weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float()
)
return hidden
bert_lstm需要的参数功6个,参数说明如下:
–bertpath:bert预训练模型的路径
–hidden_dim:隐藏层的数量。
–output_size:分类的个数。
–n_layers:lstm的层数
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/829977
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

