
热门标签
热门文章
- 1【Anaconda】Windows 系统中 vision mamba环境配置教程_windows mamba环境安装
- 2[leetcode]——移除链表元素_go 移除链表元素 leetcode
- 3Latex系列[2]--公式中的字体_latex公式中的字体
- 4【前端素材】推荐优质机器人智能Ai公司商城网站设计FutureAI平台模板(附源码)_人工智能网页设计源代码
- 5【免费赠送源码】基于Hadoop平台的个性化图书推荐系统的研究
- 6Golang每日一练(leetDay0070) 移除链表元素、计数质数
- 7[Apache Kafka 3.2源码解析系列]-5- Kafka的发送器对象的初始化_explicitlymutedchannels
- 822-07-18 西安 RabbitMQ (01) RabbitMQ安装、控制控制台界面、RabbitMQ五种模式_rabbitmq控制台
- 9来自大厂 300+ 道前端面试题大全附答案(整理版)+前端常见算法面试题~~最全面详细_前端大厂面试题
- 10排序思想-快排
当前位置: article > 正文
python 爬虫 生成markdown文档
作者:小舞很执着 | 2024-07-21 20:01:11
赞
踩
python 爬虫 生成markdown文档
本文介绍的案例为使用python爬取网页内容并生成markdown文档,首先需要确定你所需要爬取的框架结构,根据网页写出对应的爬取代码
1.分析总网页的结构
我选用的是redis.net.com/order/xxx.html
(如:Redis Setnx 命令_只有在 key 不存在时设置 key 的值。);
进入后,f12,进入开发者模式,选中左侧元素

可看到,我们需要爬取的内容是div标签下的class为left的数据,ul下的li下的a标签的 href元素,
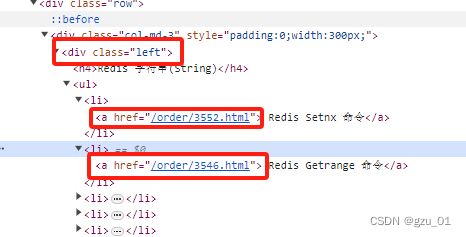
这段对应的python为
- req = requests.get(url="https://www.redis.net.cn/order/3552.html") #使用get方式获取该网页的数据。实际上我们获取到的就是浏览器打开百度网址时候首页画面的数据信息
- #print(req.text) #把我们获取数据的文字(text)内容输出(print)出来
- req.encoding = "utf-8" #指定获取的网页内容,即第二句定义req的内容,用utf-8编码
- html = req.text #指定获取的网页内容,即第二句定义req的内容,用text
- soup = BeautifulSoup(req.text,features="html.parser") #用html解析器(parser)来分析我们requests得到的html文字内容,soup就是我们解析出来的结果
- # 查找特定的div下的ul下的li下的a标签
- div = soup.find('div',class_="left")
- ul = div.find('ul')
- li_list = ul.find_all('li')
- href_list=[]
- # 遍历li标签并获取a标签的href内容
- for li in li_list:
- a = li.find('a')
- href = "https://www.redis.net.cn"+a['href']
- href_list.append(href)
- # print(href)
- n=1;
于是乎,我们就获得了以下链接地址
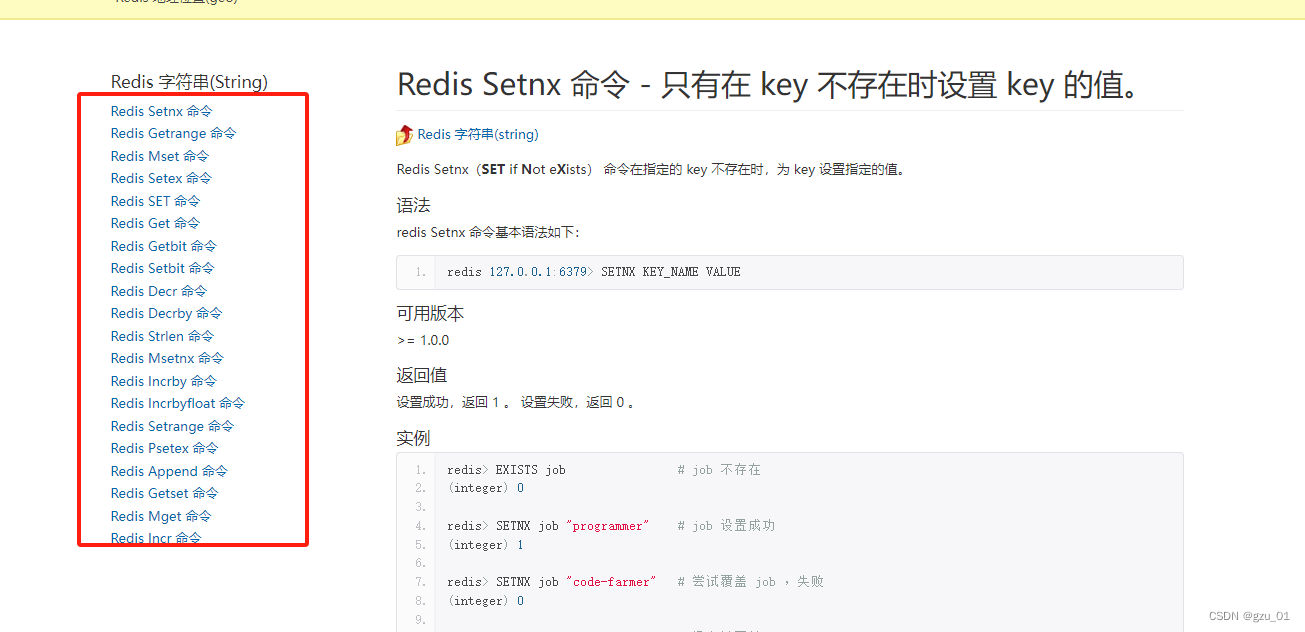
2.分析每个链接下的网页结构
首先可分为以下几个结构
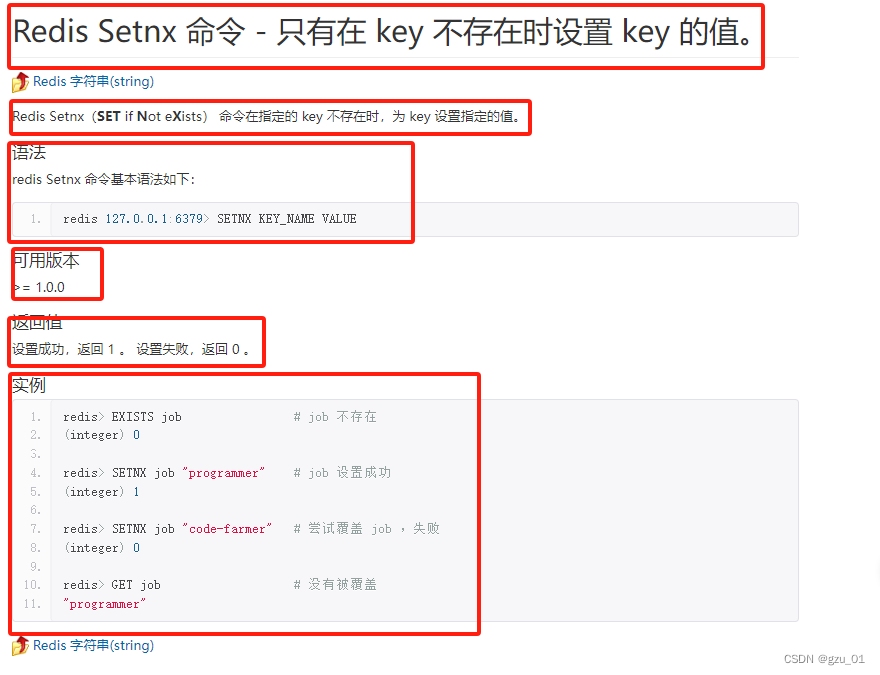
第一个为全局唯一的h1标签中的内容,并且处于div class为page-header中,因此代码为
- div_title=soup.find('div',class_="page-header")
- h1_title=div_title.find('h1').text
语法段的信息获取
- pres = soup.find_all('pre', class_='prettyprint linenums')
- syntax=pres[0].text.strip()
简介版本返回值,分别都是h3标签下的数据
- h3_tag = soup.find_all('h3')
- introduction_tags = h3_tag[0].find_previous_siblings('p')
- introduction=""
- version=""
- return_value=""
- for p_tag in introduction_tags:
- introduction+=p_tag.text.strip()
- version_tags=h3_tag[1].find_next_sibling('p')
- for p_tag in version_tags:
- version+=p_tag.text.strip()
- return_tags=h3_tag[2].find_next_sibling('p')
- for p_tag in return_tags:
- return_value+=p_tag.text.strip()
示例段的数据获取
- pres = soup.find_all('pre', class_='prettyprint linenums')
-
- if len(pres) >=2:
- examples=pres[1].text.strip()
- else :examples = ""
3.markdown源代码生成
- # 定义一个方法来生成Markdown内容
- def generate_markdown(website_obj,n):
- markdown_content = "# "+str(n)+f".{website_obj.title}\n\n"
-
- markdown_content += f"## 简介\n```\n{website_obj.introduction}\n```\n\n"
-
- markdown_content += f"## 语法\n```\n{website_obj.syntax}\n```\n\n"
-
- markdown_content += f"### 可用版本: {website_obj.version}\n\n"
-
- markdown_content += f"### 返回值: {website_obj.return_value}\n\n"
-
- markdown_content += f"## 示例\n\n```shell\n"
-
- for example in website_obj.examples:
- markdown_content += f"{example}"
-
- markdown_content += "\n```\n"
-
- return markdown_content
4.完整示例
- import requests #导入我们需要的requests功能模块
- from bs4 import BeautifulSoup #使用BeautifulSoup这个功能模块来把充满尖括号的html数据变为更好用的格式,from bs4 import BeautifulSoup这个是说从bs4这个功能模块中导入BeautifulSoup,是的,因为bs4中包含了多个模块,BeautifulSoup只是其中一个
- class Website:
- def __init__(self, href, title,syntax,examples,introduction,version,return_value):
- self.href = href
- self.title = title
- self.syntax=syntax
- self.examples=examples
- self.introduction=introduction
- self.version=version
- self.return_value=return_value
-
- def __str__(self):
- return f"Website(href={self.href}, title={self.title},syntax={self.syntax},examples={self.examples},introduction={self.introduction},version={self.version},return_value={self.return_value})"
- # 定义一个方法来生成Markdown内容
- def generate_markdown(website_obj,n):
- markdown_content = "# "+str(n)+f".{website_obj.title}\n\n"
-
- markdown_content += f"## 简介\n```\n{website_obj.introduction}\n```\n\n"
-
- markdown_content += f"## 语法\n```\n{website_obj.syntax}\n```\n\n"
-
- markdown_content += f"### 可用版本: {website_obj.version}\n\n"
-
- markdown_content += f"### 返回值: {website_obj.return_value}\n\n"
-
- markdown_content += f"## 示例\n\n```shell\n"
-
- for example in website_obj.examples:
- markdown_content += f"{example}"
-
- markdown_content += "\n```\n"
-
- return markdown_content
- req = requests.get(url="https://www.redis.net.cn/order/3552.html") #使用get方式获取该网页的数据。实际上我们获取到的就是浏览器打开百度网址时候首页画面的数据信息
- #print(req.text) #把我们获取数据的文字(text)内容输出(print)出来
- req.encoding = "utf-8" #指定获取的网页内容,即第二句定义req的内容,用utf-8编码
- html = req.text #指定获取的网页内容,即第二句定义req的内容,用text
- soup = BeautifulSoup(req.text,features="html.parser") #用html解析器(parser)来分析我们requests得到的html文字内容,soup就是我们解析出来的结果
- # 查找特定的div下的ul下的li下的a标签
- div = soup.find('div',class_="left")
- ul = div.find('ul')
- li_list = ul.find_all('li')
- href_list=[]
- # 遍历li标签并获取a标签的href内容
- for li in li_list:
- a = li.find('a')
- href = "https://www.redis.net.cn"+a['href']
- href_list.append(href)
- # print(href)
- n=1;
- for hrefitem in href_list:
- req = requests.get(url=hrefitem)
- req.encoding = "utf-8" # 指定获取的网页内容,即第二句定义req的内容,用utf-8编码
- html = req.text # 指定获取的网页内容,即第二句定义req的内容,用text
- soup = BeautifulSoup(req.text, features="html.parser")
- div_title=soup.find('div',class_="page-header")
- h1_title=div_title.find('h1').text
- pres = soup.find_all('pre', class_='prettyprint linenums')
- syntax=pres[0].text.strip()
- if len(pres) >=2:
- examples=pres[1].text.strip()
- else :examples = ""
-
- h3_tag = soup.find_all('h3')
- introduction_tags = h3_tag[0].find_previous_siblings('p')
- introduction=""
- version=""
- return_value=""
- for p_tag in introduction_tags:
- introduction+=p_tag.text.strip()
- version_tags=h3_tag[1].find_next_sibling('p')
- for p_tag in version_tags:
- version+=p_tag.text.strip()
- return_tags=h3_tag[2].find_next_sibling('p')
- for p_tag in return_tags:
- return_value+=p_tag.text.strip()
- website=Website(href,h1_title,syntax,examples,introduction,version,return_value)
- # print(introduction)
- # print(website.__str__())
- # 使用上述定义的方法生成Markdown源码
- markdown_source = generate_markdown(website,n)
- n=n+1
- print(markdown_source)
-
-
-
以上案例可将redis key命令篇的案例,爬取生成markdown代码,如果需要爬取多类代码,可修改
req = requests.get(url="https://www.redis.net.cn/order/3552.html") 中的url属性为你所想爬取的类型的一种命令的网址。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/862075
推荐阅读
相关标签

