
- 1Python+wxauto=微信自动化?_python库wxauto
- 2Neo4j配合springboot与echarts进行方剂药物关系的可视化-1_echarts可视化neo4j
- 3Redis缓存穿透、缓存血崩、缓存击穿的原因和解决方案_redis 血崩 穿透
- 4Git工具的使用_如何在对应的文件中调用git软件
- 5[C++]C++基础知识概述_c++ 什么时候开始oop
- 6podman-docker详解
- 7Qt版科学计算器_qt科学计算库
- 8LLM大模型工程师面试经验宝典--进阶版1(2024.7月最新)_大模型面试宝典2024版
- 9全网最全RabbitMQ笔记 | 万字长文爆肝RabbitMQ基础_万字 rabbitmq
- 10分享一下自己从java工程师转型AI工程师的经历_java转ai
Go语言常见序列化协议全面对比
赞
踩
先说结论
从易用性、性能、内存占用、编码后大小等几个方面综合考虑 ProtoBuf 胜出。
Gob 从性能和 I/O 带宽占用上都和 ProtoBuf 差不多,唯一劣势是编解码时内存占用较多。考虑到不用再写 IDL 带来的易用性,如果整个系统内不存在使用除 Go 以外其他语言的服务,Gob 是更合适的选择。
| json | msgp | gob | pb | flatbuffers | |
|---|---|---|---|---|---|
| 易用性 | 好 | 好 | 好 | 一般 | 极差 |
| 性能 | 差 | 差 | 好 | 好 | 好 |
| 编解码内存占用 | 一般 | 差 | 差 | 好 | 差 |
| 编码后大小 | 差 | 差 | 好 | 好 | 差 |
| 成熟度 | 好 | 一般 | 较好 | 好 | 一般 |
测试场景
限制单核单线程场景,使用本地机器进行测试。
使用对象为 10 个字段对象,包括 string、int32、slice、map 等多种类型,且存在嵌套关系。
type Layer10 struct {
IntField int32
StringField string
SliceField []int32
MapField map[string]int32
Field5 int32
Field6 string
Field7 []int32
Field8 map[string]int32
Field9 int32
Field10 string
Layer10 *Layer10
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
主要验证 json、gob、msgp、pb、flatbuffers 这 5 种序列化方案。
场景1:层数逐渐增长
性能
这里不对CPU利用率做分析,原因是编解码属于纯计算密集型场景,每一种序列化方式都能跑满CPU。我们应该关注同等CPU性能下,序列化的效率。下面分别测试编解码混合、仅编码和仅解码的效率。
编解码混合
设定层级数从1层到100层递增,使用5种序列化方式进行编码+解码。
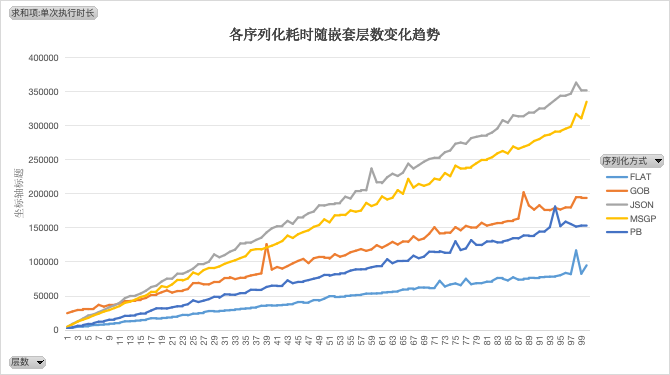
可以看出,在对象简单时(嵌套层级不超过5层),gob的性能不是很好,甚至比json更差;但在对象复杂度很高时,gob的性能优势就体现出来。
pb的性能略好于gob,二者的增长斜率基本一致。在应对复杂对象场景时,GOB性能要比JSON好一倍以上。
性能排名(>表示优于):FLAT > PB > GOB > MSGP > JSON
仅编码
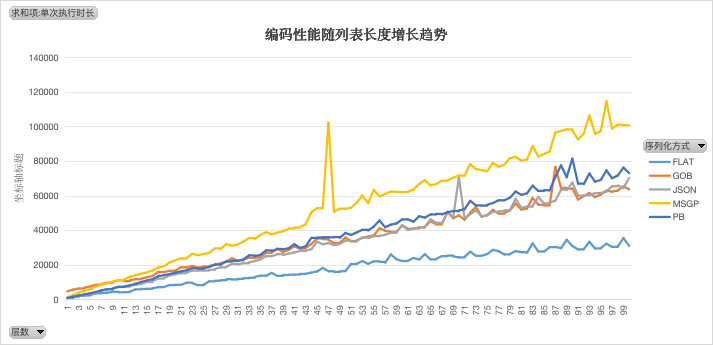
JSON 的编码效率并不低,甚至能和 GOB 和 PB 保持在同一水平线上。
仅解码
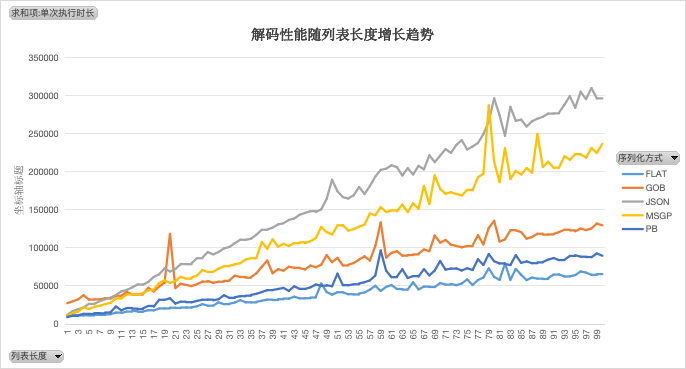
解码效率拉开差距,JSON 解码性能很差,GOB 和 PB 较好,GOB 略低于 PB。
内存使用率
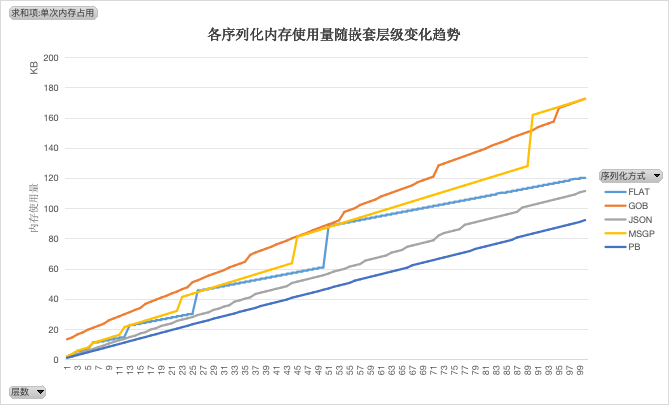
在序列化过程中,gob 需要消耗较多内存。而 pb 一直保持较低内存消耗
内存使用排序(>表示优于):PB > JSON > FLAT > MSGP >GOB
编码后大小
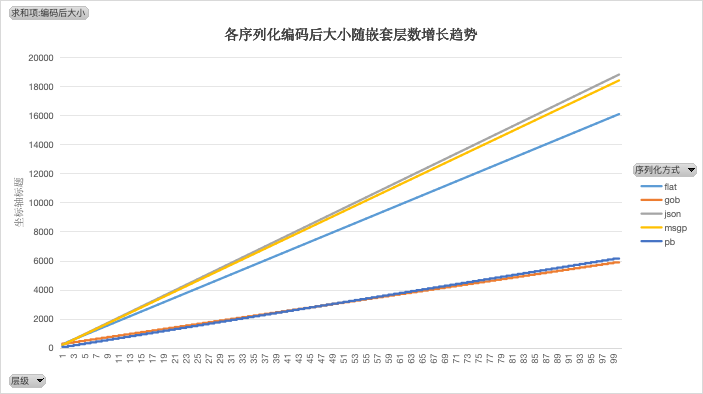
编码后,pb 和 gob 的长度都较小,基本不分伯仲。其他三种表现一般。
编码后大小排序(>表示优于):GOB > PB > FLAT > MSGP > JSON
以下是不同数量级时的性能表现:
# 层级为1时 Layer-1-Size-1-JSON 1000 3887 ns/op 1384 B/op 34 allocs/op Layer-1-Size-1-GOB 1000 23707 ns/op 13270 B/op 333 allocs/op Layer-1-Size-1-PB 1000 1594 ns/op 1000 B/op 30 allocs/op Layer-1-Size-1-MSGP 1000 4139 ns/op 2040 B/op 59 allocs/op Layer-1-Size-1-FLAT 1000 6.708 ns/op 1 B/op 0 allocs/op # 层级为10时 Layer-10-Size-1-JSON 1000 39244 ns/op 11592 B/op 256 allocs/op Layer-10-Size-1-GOB 1000 40830 ns/op 27202 B/op 623 allocs/op Layer-10-Size-1-PB 1000 17232 ns/op 9280 B/op 264 allocs/op Layer-10-Size-1-MSGP 1000 32549 ns/op 15208 B/op 431 allocs/op Layer-10-Size-1-FLAT 1000 20.79 ns/op 13 B/op 0 allocs/op # 层级为100时 Layer-100-Size-1-JSON 1000 351715 ns/op 111428 B/op 2422 allocs/op Layer-100-Size-1-GOB 1000 183746 ns/op 172531 B/op 3509 allocs/op Layer-100-Size-1-PB 1000 162784 ns/op 92208 B/op 2604 allocs/op Layer-100-Size-1-MSGP 1000 315320 ns/op 172416 B/op 4125 allocs/op Layer-100-Size-1-FLAT 1000 88.75 ns/op 120 B/op 1 allocs/op

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
场景2:切片长度逐渐增长
设定一个[]Layer10,Layer10 只有一层,不做嵌套。切片中对象的数量逐渐增长
性能
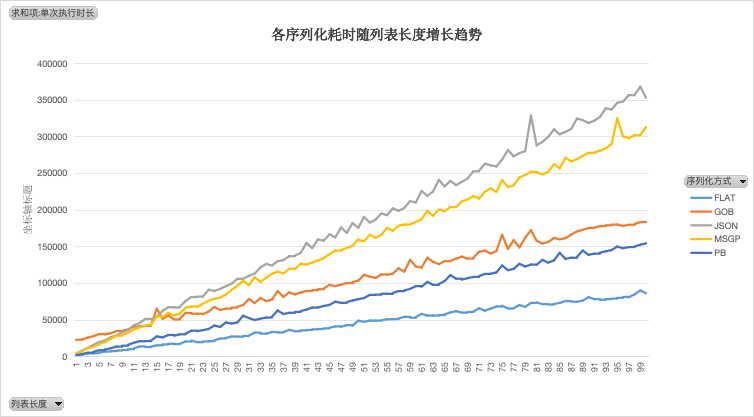
与层级增长的情况一致,在对象简单时(列表长度不超过 15 个时),gob 的性能不是很好,甚至比 json 更差;但在对象复杂度很高时,gob 的性能优势才能体现出来。
性能排名:FLAT > PB > GOB > MSGP > JSON
内存使用率
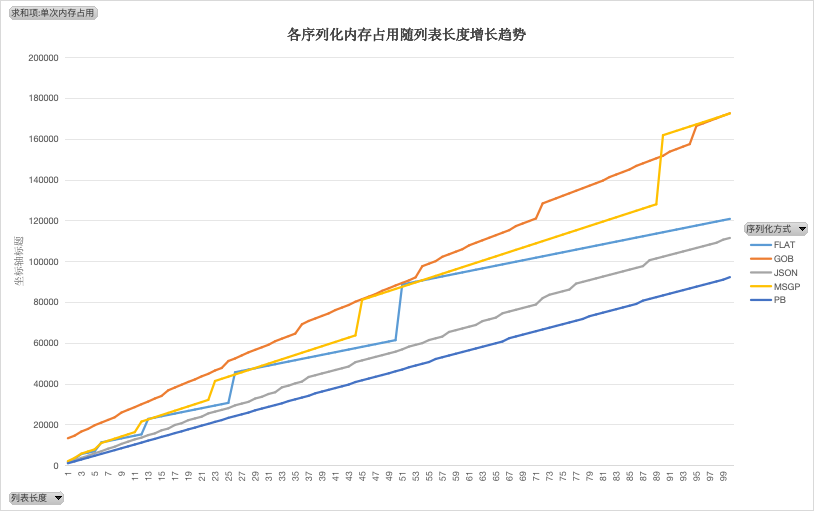
结论同场景 1 一致
编码后大小
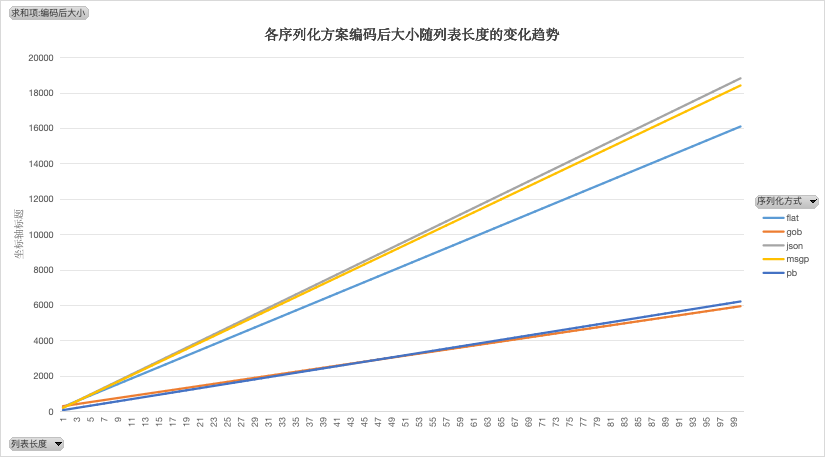
结论同场景 1 一致
不同数量级时的性能表现:
# 层级为1时 Layer-1-Size-1-JSON 1000 3903 ns/op 1384 B/op 34 allocs/op Layer-1-Size-1-GOB 1000 23681 ns/op 13267 B/op 333 allocs/op Layer-1-Size-1-PB 1000 1614 ns/op 1000 B/op 30 allocs/op Layer-1-Size-1-MSGP 1000 4010 ns/op 2040 B/op 59 allocs/op Layer-1-Size-1-FLAT 1000 7.458 ns/op 1 B/op 0 allocs/op # 层级为10时 Layer-1-Size-10-JSON 1000 37965 ns/op 11592 B/op 256 allocs/op Layer-1-Size-10-GOB 1000 40962 ns/op 27205 B/op 623 allocs/op Layer-1-Size-10-PB 1000 16340 ns/op 9280 B/op 264 allocs/op Layer-1-Size-10-MSGP 1000 31643 ns/op 15208 B/op 431 allocs/op Layer-1-Size-10-FLAT 1000 14.50 ns/op 13 B/op 0 allocs/op # 层级为100时 Layer-1-Size-100-JSON 1000 388890 ns/op 111420 B/op 2422 allocs/op Layer-1-Size-100-GOB 1000 190858 ns/op 172533 B/op 3509 allocs/op Layer-1-Size-100-PB 1000 166676 ns/op 92208 B/op 2604 allocs/op Layer-1-Size-100-MSGP 1000 309114 ns/op 172416 B/op 4125 allocs/op Layer-1-Size-100-FLAT 1000 85.62 ns/op 120 B/op 1 allocs/op
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
分析
不管是嵌套层级数增加还是切片长度增加,整体趋势改变不大。各序列化方案的差异会随着对象复杂度的增加而拉大。
单从性能角度考虑,flatbuffers 的性能很好,原因是 flatbuffers 是直接向 ByteBuffer 里塞字节流的,就省掉了反射的步骤。但这样就牺牲了易用性。编写代码时,连set字段值的顺序都有非常严格的要求。这对研发的要求太高了,可能会导致很多问题。像这种极端难用的,除非有非常迫切的性能需要,否则肯定是不建议使用的。
综合考虑各方面因素,ProtoBuf 脱颖而出,但唯一不好的就是要写 IDL。是否可以通过二次开发或者包装工具的方式来抹平 IDL 带来的缺点。
Gob 从性能和 I/O 带宽占用上都和 ProtoBuf 差不多,唯一劣势是编解码时内存占用较多。考虑到不用再写IDL带来的易用性,在「只使用 Go 语言」的背景下,Gob 是更合适的选择。

