
- 1Docker超详细教程——入门篇+实战
- 2web安全学习笔记【13】——信息打点(3)
- 3springboot使用redis_springboot redis
- 4【华为OD机考 统一考试机试C卷】分配土地(C++ Java JavaScript Python C语言)_华为笔试土地分配
- 5Java网络编程基础部分_"datagramsocket socket = null; inetaddress address
- 6关于在anaconda中切换不同的python版本_anaconda和tf环境如何激活不同版本的python
- 7【Redis】缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存击穿、缓存降级_缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级
- 8YOLOv5-Lite 树莓派实时 | 更少的参数、更高的精度、更快的检测速度(C++部署分享)...
- 9如何基于spring boot和mybatis创建一个mysql数据库的访问接口_springboot连接数据库写接口
- 10Linux|zip 命令_linux zip压缩命令
警惕AI,我搭建了一个“枪枪爆头”的视觉AI自瞄程序,却引发了一场“山雨欲来”_ai瞄准真的检测不出吗
赞
踩
前言
前段时间在网上看到《警惕AI外挂!我写了一个枪枪爆头的视觉AI,又亲手“杀死”了它》 这个视频,引起了我极大的兴趣。
视频中提到,在国外有人给使命召唤做了个AI程序来实现自动瞄准功能。它跟传统外挂不一样,该程序不需要用游戏内存数据,也不往服务器发送作弊指令,只是通过计算机视觉来分析游戏画面,定位敌人,把准星移动过去,跟人类玩家操作一模一样,因此反外挂程序无法检测到它。而且更恐怖的是这AI程序全平台通用,不管是X-box,PS4还是手机,只要能把画面接出来,把操作送进去,就可以实现“枪枪爆头”。

外网的那个开发者用的是基于方框的目标检测,但是像射击游戏需要定位人体的场景,其实有比方框检测更好的算法。up主就利用了几个小时的时间就写出来了一个效果更好,功能更夸张的AI程序,也就是利用人体关节点检测技术,通过大量真人图片训练出来的视觉AI,可以把视频和图片里人物的关节信息提取出来 并给出每个部位中心点的精确像素坐标,而且虽然训练的是是真人图片,但是给它游戏里的人物,他也一样能把人体关节定位出来。
可以说由于这类AI程序的出现,现在fps游戏的形式就是山雨欲来风满楼,十分严峻啊!
下面,我们先开始介绍这个视觉AI自动瞄准的制作思路,然后再谈谈这个问题带来的影响以及如何解决这个问题。
一、核心功能设计
总体来说,我们首先需要训练好一个人体关节点检测的AI视觉模型,然后将游戏画面实时送入AI视觉模型中,再反馈出游戏人物各个部位的像素位置,然后确定瞄准点,并将鼠标移动到瞄准点位置。
拆解需求后,整理出核心功能如下:
- 训练人体关节点检测模型
- 输入视频或图片到AI视觉模型,并输出瞄准点位置。
- 自动操作鼠标移动到对应瞄准位置
最终想要实现的效果如下图所示:
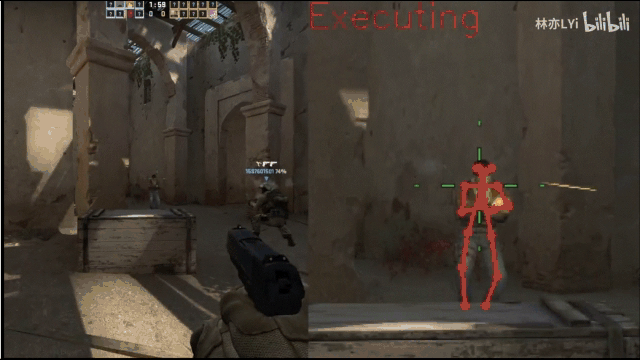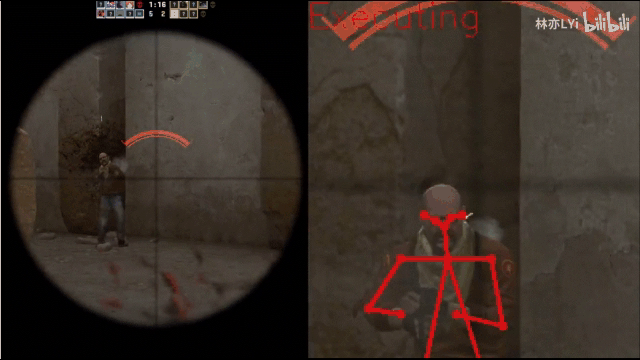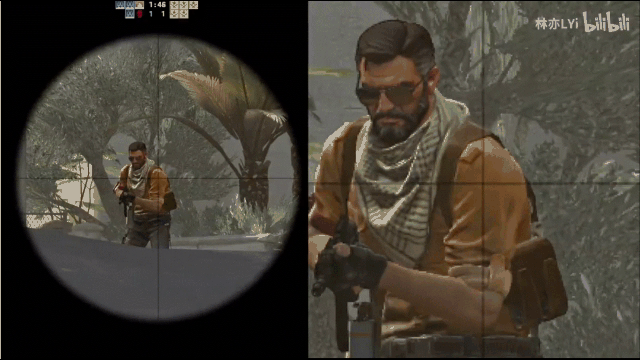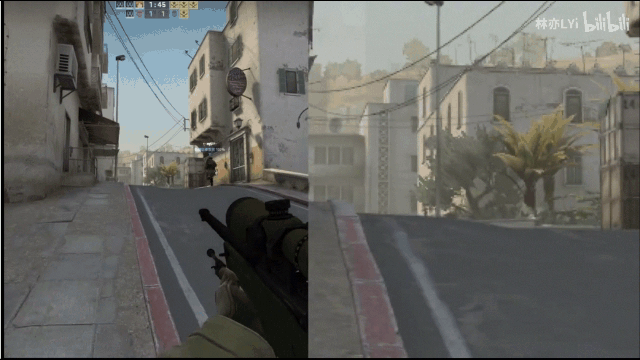
二、核心实现步骤
1.训练人体关节点检测模型
在这一部分,我打算使用由微软亚洲研究院和中科大提出High-Resoultion Net(HRNet)来进行人体关节点检测,该模型通过在高分辨率特征图主网络逐渐并行加入低分辨率特征图子网络,不同网络实现多尺度融合与特征提取实现的,所以在目前的通用数据集上取得了较好的结果。
1.1 HRNet代码库安装
按照官方的install指导命令,安装十分简单。我是采用本地源代码安装方式。
- git clone https://github.com/leoxiaobin/deep-high-resolution-net.pytorch.git
- python -m pip install -e deep-high-resolution-ne.pytorch
1.2 人体关键点数据集下载
首先打开COCO数据集官方下载链接。
对于Images一栏的绿色框需要下载三个大的文件,分别对应的是训练集,验证集和测试集:
2017 Train images [118K/18GB]
2017 Val images [5K/1GB]
2017 Test images [41K/6GB]
对于Annotations一栏绿色框需要下载一个标注文件:
2017 Train/Val annotations [241MB]
将文件解压后,可以得到如下目录结构:
其中的 person_keypoints_train2017.json 和 person_keypoints_val2017.json 分别对应的人体关键点检测对应的训练集和验证集标注。
annotations
├── captions_train2017.json
├── captions_val2017.json
├── instances_train2017.json
├── instances_val2017.json
├── person_keypoints_train2017.json 人体关键点检测对应的训练集标注文件
└── person_keypoints_val2017.json 人体关键点检测对应的验证集标注文件
在本地代码库datasets目录下面新建立coco目录,将上面的训练集,验证集以及标注文件放到本地代码的coco目录下面
datasets
├── coco
│ ├── annotations
│ ├── test2017
│ ├── train2017
│ └── val2017
1.3 环境配置与模型训练
核心训练代码如下:
- def train(config, train_loader, model, criterion, optimizer, epoch,
- output_dir, tb_log_dir, writer_dict):
- batch_time = AverageMeter()
- data_time = AverageMeter()
- losses = AverageMeter()
- acc = AverageMeter()
- # switch to train mode
- model.train()
- end = time.time()
- for i, (input, target, target_weight, meta) in enumerate(train_loader):
- data_time.update(time.time() - end)
- outputs = model(input)
- target = target.cuda(non_blocking=True)
- target_weight = target_weight.cuda(non_blocking=True)
- if isinstance(outputs, list):
- loss = criterion(outputs[0], target, target_weight)
- for output in outputs[1:]:
- loss += criterion(output, target, target_weight)
- else:
- output = outputs
- loss = criterion(output, target, target_weight)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- # measure accuracy and record loss
- losses.update(loss.item(), input.size(0))
- _, avg_acc, cnt, pred = accuracy(output.detach().cpu().numpy(),
- target.detach().cpu().numpy())
- acc.update(avg_acc, cnt)
- batch_time.update(time.time() - end)
- end = time.time()
- if i % config.PRINT_FREQ == 0:
- msg = 'Epoch: [{0}][{1}/{2}]\t' \
- 'Time {batch_time.val:.3f}s ({batch_time.avg:.3f}s)\t' \
- 'Speed {speed:.1f} samples/s\t' \
- 'Data {data_time.val:.3f}s ({data_time.avg:.3f}s)\t' \
- 'Loss {loss.val:.5f} ({loss.avg:.5f})\t' \
- 'Accuracy {acc.val:.3f} ({acc.avg:.3f})'.format(
- epoch, i, len(train_loader), batch_time=batch_time,
- speed=input.size(0)/batch_time.val,
- data_time=data_time, loss=losses, acc=acc)
- logger.info(msg)
- writer = writer_dict['writer']
- global_steps = writer_dict['train_global_steps']
- writer.add_scalar('train_loss', losses.val, global_steps)
- writer.add_scalar('train_acc', acc.val, global_steps)
- writer_dict['train_global_steps'] = global_steps + 1
- prefix = '{}_{}'.format(os.path.join(output_dir, 'train'), i)
- save_debug_images(config, input, meta, target, pred*4, output,
- prefix)
训练结果:

2.输入视频或图片实时反馈瞄准点坐标
2.1 实时读取屏幕画面
- import pyautogui
- img = pyautogui.screenshot()
在一个 1920×1080 的屏幕上,screenshot()函数要消耗100微秒,基本达到实时传入游戏画面要求。
如果不需要截取整个屏幕,还有一个可选的region参数。你可以把截取区域的左上角XY坐标值和宽度、高度传入截取。
im = pyautogui.screenshot(region=(0, 0, 300 ,400))
2.2 读取图片反馈坐标
- parser.add_argument('--keypoints', help='f:full body 17 keypoints,h:half body 11 keypoints,sh:small half body 6 keypotins')
- hp = PoseEstimation(config=args.keypoints, device="cuda:0")
可以选择人体关节点检测数目,包括上半身6个关键点、上半身11个关键点以及全身17个关键点,然后构建探测器。
人体关节点对应序号:
"keypoints": { 0: "nose", 1: "left_eye", 2: "right_eye", 3: "left_ear", 4: "right_ear", 5: "left_shoulder", 6: "right_shoulder", 7: "left_elbow", 8: "right_elbow", 9: "left_wrist", 10: "right_wrist", 11: "left_hip", 12: "right_hip", 13: "left_knee", 14: "right_knee", 15: "left_ankle", 16: "right_ankle" }
因此如果为了自动瞄准头部实现“枪枪爆头”,仅需要反馈 0: "nose"的坐标点就行了。
代码如下:
- location=hp.detect_head(img_path, detect_person=True, waitKey=0)
-
- def detect_head(self, image_path, detect_person=True, waitKey=0):
-
- bgr_image = cv2.imread(image_path)
- kp_points, kp_scores, boxes = self.detect_image(bgr_image,
- threshhold=self.threshhold,
- detect_person=detect_person)
- return kp_points[0][0]
输出结果:[701.179 493.55]

可以看到虽然训练的是真人图片,但是给它游戏里的人物,它也一样能把人体关节定位出来。
深度神经网络之所以厉害,就是因为它有一定的演绎推广能力。没见过的东西,他也能靠着层次线索分析一波,结果往往也挺准。而且游戏场景是现实场景的简化之后的结果,环境和光影都要简单的多,能把现实世界分析明白的视觉AI,对付个3D游戏更是小菜一碟了。
3.自动移动鼠标到对应的坐标点
3.1 移动鼠标
移动到指定位置:
pyautogui.moveTo(100,300,duration=1)将鼠标移动到指定的坐标;duration 的作用是设置移动时间,所有的gui函数都有这个参数,而且都是可选参数。
获取鼠标位置:
print(pyautogui.position()) # 得到当前鼠标位置;输出:Point(x=200, y=800)3.2 控制鼠标点击
单击鼠标:
- # 点击鼠标
- pyautogui.click(10,10) # 鼠标点击指定位置,默认左键
- pyautogui.click(10,10,button='left') # 单击左键
- pyautogui.click(1000,300,button='right') # 单击右键
- pyautogui.click(1000,300,button='middle') # 单击中间
双击鼠标:
- pyautogui.doubleClick(10,10) # 指定位置,双击左键
- pyautogui.rightClick(10,10) # 指定位置,双击右键
- pyautogui.middleClick(10,10) # 指定位置,双击中键
点击 & 释放:
- pyautogui.mouseDown() # 鼠标按下
- pyautogui.mouseUp() # 鼠标释放
至此,视觉AI自瞄程序已经基本设计完成。最终实现效果可以参见这个up主的视频。
【亦】警惕AI外挂!我写了一个枪枪爆头的视觉AI,又亲手“杀死”了它
三、引发的思考
也正如up主所说,视觉AI给FPS游戏带来的这一轮重大危机!
这类视觉AI程序目前存在三个威胁:
- 准确性
- 隐蔽性
- 通用性
第一个威胁就是超越人类的准确性。虽然人脑的高层次演绎归纳能力是远胜于AI的,但是在低级信息处理速度和精确度上,人类就很难比得过专精某个功能的AI了,比如在人体关节定位这件事上,给出人体每个部位的中心位置只需要几毫秒,而且精确到像素点,而同样一张图片给人类看个几毫秒,都不一定能够看清人在哪,更别说定位关节移动鼠标了。
第二个威胁就是无法被外挂程序检测的隐蔽性。和传统外挂不一样,传统外挂要操作游戏的内存数据或者文件数据,从而获取游戏世界的信息。让开挂的人打出一些正常玩家不可能实现的作弊操作。而视觉AI是完全独立于游戏数据之外的,和人一样,也是通过实时观察画面发送鼠标和键盘指令,所以传统的反外挂程序只能反个寂寞。
第三个威胁就是适用全平台的通用性。首先这个AI视觉模型是通过大量真人照片训练出来的,但是能够识别游戏中的人物,这意味着可以攻陷大部分FPS游戏。AI操作游戏和人操作游戏交互方式是没区别的,所以衍生出更大的问题,只要能把画面接入到这个模型中,就可以攻陷任意一种游戏平台,包括电脑、主机、手机等,无论你做的多封闭,生态维护的多好,在视觉AI面前众生平等。
那么我们该如何解决这个问题呢?
up主提到可以通过算法检测游戏异常操作,这也是一种思路,但是实现起来还是比较困难,毕竟可以让AI更像人类的操作。
而我想到之前比较火的deepfake,那么我们是不是可以通过对抗样本来解决这个问题呢,使得视觉AI识别错误?
说了那么多,其实也没有什么好的结论,只能说技术的发展是在不断对抗中前进以及规范。
参考:
《Deep High-Resolution Representation Learning for Human Pose Estimation》https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
2D Pose人体关键点实时检测(Python/Android /C++ Demo)
PyQt5 实时获取屏幕界面图像,python3使用matplotlib
警惕AI外挂!我写了一个枪枪爆头的视觉AI,又亲手“杀死”了它
今天我们就到这里,明天继续努力!

如果该文章对您有所帮助,麻烦点赞,关注,收藏三连支持下!
创作不易,白嫖不好,各位的支持和认可,是我创作的最大动力!
如果本篇博客有任何错误,请批评指教,不胜感激 !!!

