
- 1在Linux系统上安装Wine方法教程_linuxxiezaiwine教程
- 2linux文件移出目录命令_linux下如何删除整个文件夹及目录命令
- 3Spring Boot集成Kafka详解_spring boot 集成kafaka
- 4MATLAB中安装YALMIP及CPLEX详细步骤_yalmip安装
- 5OpenCV-Python Tutorials - 4.9.4. 轮廓:更多函数_opencv-python-tutorials#4.9.4. 轮廓
- 6SOPC之NiosⅡ系统(三)_niosii 串口
- 7python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序...
- 8.NET8杀疯了!微软:比.NET7超级快更快!
- 9训练ChatGPT的必备资源:语料、模型和代码库完全指南_如何训练chartgpt 体制内写材料
- 10图文解读:推荐算法架构——精排!
P2P 应用
赞
踩
P2P 工作方式概述
·在 P2P 工作方式下,所有的音频/视频文件都是在普通的互联网用户之间传输。
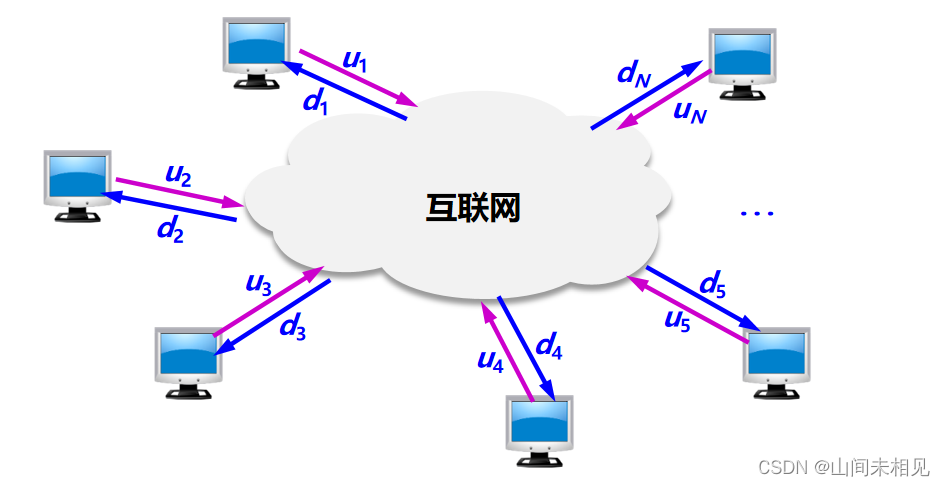
1 具有集中目录服务器的 P2P 工作方式
·Napster 最早使用 P2P 技术,提供免费下载 MP3 音乐。
·Napster 将所有音乐文件的索引信息都集中存放在 Napster 目录服务器中。
·使用者只要查找目录服务器,就可知道应从何处下载所要的 MP3 文件。
·用户要及时向 Napster 的目录服务器报告自己存有的音乐文件。
·Napster 的文件传输是分散的,文件的定位则是集中的。
Napster 的工作过程
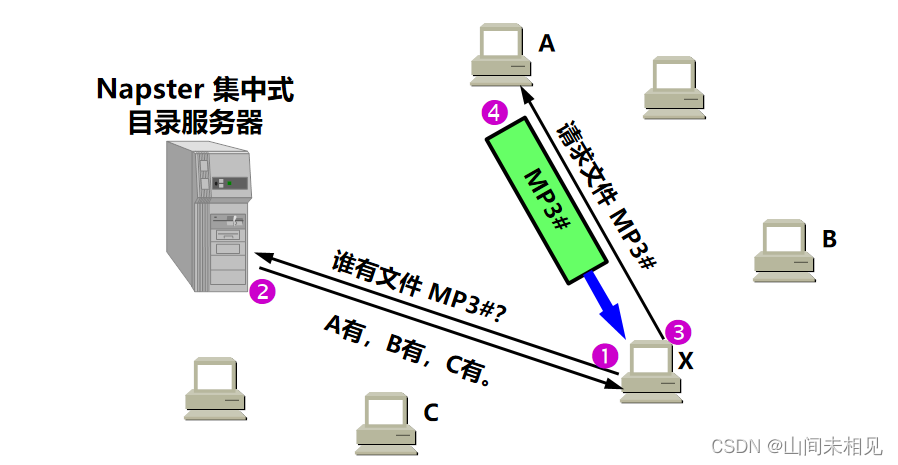
1.用户 X 向 Napster 目录服务器查询(采用客户服务器方式)谁有音乐文件 MP3#。
2.Napster 目录服务器回答 X:有三个地点有文件 MP3#,即 A, B 和 C(给出了这三个地点的 IP 地址)。于是用户 X 得知所需的文件 MP3# 的三个下载地点。
3.用户 X 可以随机地选择三个地点中的任一个。假定 X 向 A 发送下载文件 MP3# 的请求报文。双方都使用 P2P 方式通信。
4.对等方 A(现在作为服务器)把文件 MP3# 发送给 X。
集中式目录服务器的缺点
·可靠性差。
·会成为性能的瓶颈。
2 具有全分布式结构的 P2P 文件共享程序
·Gnutella 是第二代 P2P 文件共享程序,采用全分布方法定位内容的 P2P 文件共享应用程序。
·Gnutella 与 Napster 最大的区别:不使用集中式的目录服务器,而是使用洪泛法在大量 Gnutella 用户之间进行查询。
·为了不使查询的通信量过大,Gnutella 设计了一种有限范围的洪泛查询,减少了倾注到互联网的查询流量,但也影响到查询定位的准确性。
·第三代 P2P 文件共享程序采用分散定位和分散传输技术。例如 KaZaA,电骡 eMule,比特洪流 BT (Bit Torrent) 等。
使用 P2P 的比特洪流 BT 主要特点
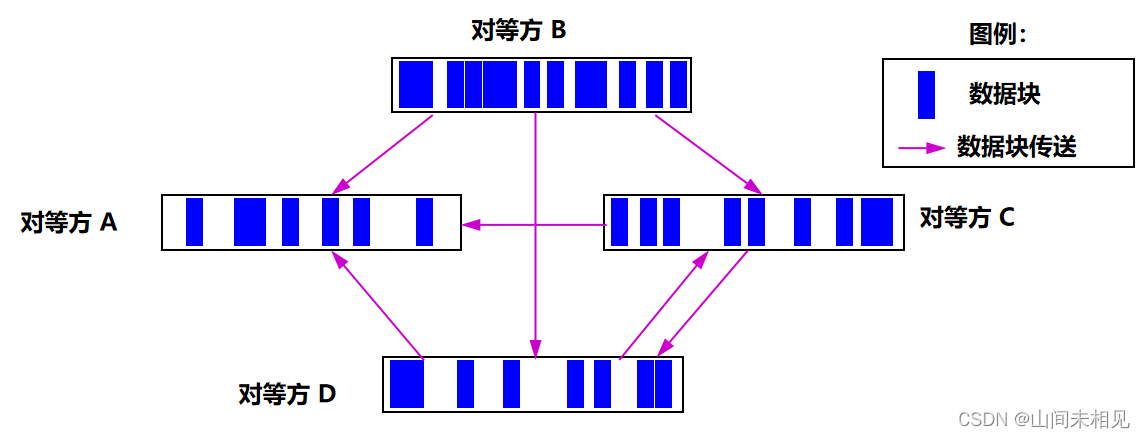
·BitTorrent 所有对等方集合称为一个洪流 (torrent)。
·下载文件的数据单元为长度固定的文件块 (chunk)。
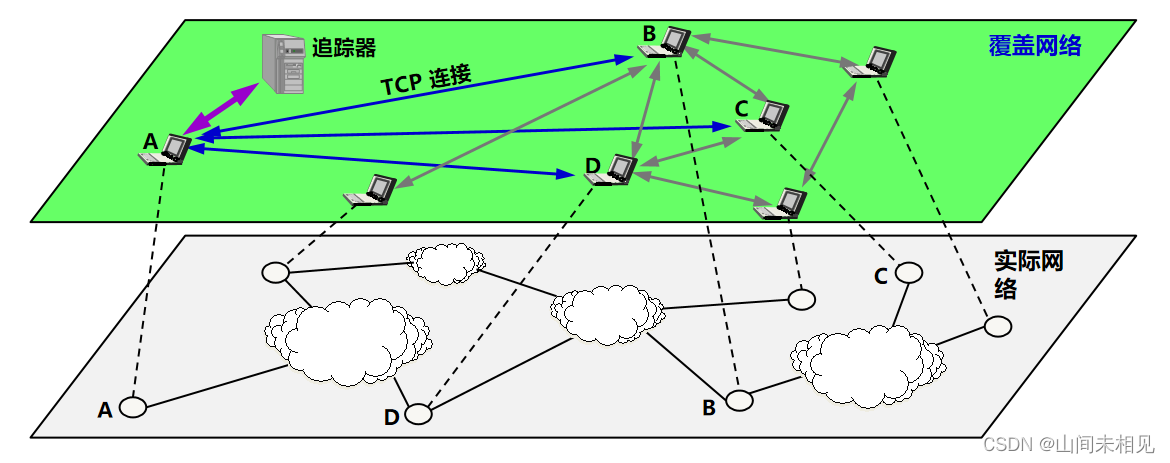
·基础设施结点,叫做追踪器 (tracker)。
·A 和对等方建立了 TCP 连接。所有与 A 建立了 TCP 连接的对等方为相邻对等方(neighboring peers)。

相邻关系是逻辑的,对等方的数目是动态变化的
对等方之间互相传送文件数据块
BT 协议
问题:哪些文件块是首先需要向其相邻对等方请求的?
方法:A 使用最稀有的优先 (rarest first) 的技术,首先向其相邻对等方请求对应的文件块。
稀有:如果 A 所缺少的文件块在相邻对等方中的副本很少,那就是“很稀有的”。
问题:在很多向 A 请求文件块的相邻对等方中,A 应当向哪些相邻对等方发送所请求的文件块?
方法:凡当前以最高数据率向 A 传送文件块的某相邻对等方,A 就优先把所请求的文件块传送给该相邻对等方。
3 P2P 文件分发的分析
从互联网传送数据到主机,叫做下载 (download);
从主机向互联网传送,则称为上传 (upload) 或上载。
有 N 台主机从服务器下载一个大文件,其长度为 F bit。
假定主机与互联网连接的链路的上传速率和下载速率分别为 ui 和 di ,单位都是 bit/s。

客户-服务器方式下分发的最短时间分析:
·从服务器端考虑,所有主机分发完毕的最短时间 Tcs 不可能小于 NF/us ;
·下载速率最慢的主机的下载速率为 dmin,则 Tcs 不可能小于 F/dmin 。
·由此可得出所有主机都下载完文件 F 的最少时间是: Tcs=max( NF/us,F/dmin )。
P2P 方式下分发的最短时间分析:
·初始服务器文件分发的最少时间不可能小于 F/us ;
·下载文件分发的最少时间不可能小于 F/dmin ;
·上载文件分发的最少时间不可能小于 NF/uT ,其中是 uT 是上传速率之和。
·所有主机都下载完文件 F 的最少时间的下限是: Tp2p >= max( F/us , F/dmin, NF/uT )
时间比较
·设所有的对等方的上传速率都是 u,并且 F/u = 1 小时。
·设服务器的上传速率 us = 10u。
·当 N = 30 时,
1.P2P 方式:最少时间的下限是 0.75 小时 < 1 小时(不管 N 多大)。
2.客户服务器方式:最少时间是 3 小时。
4 在 P2P 对等方中搜索对象
·Napster 在一个集中式目录服务器中构建查找数据库,简单,但性能上有瓶颈。
·Gnutella 是一种采用全分布方法定位内容的 P2P 文件共享应用程序,它解决了集中式目录服务器所造成的瓶颈问题。但 Gnutella 是在非结构化的覆盖网络中采用查询洪泛的方法进行查找,因此查找的效率较低。
·现在广泛使用的索引和查找技术叫做分布式散列表 DHT (Distributed Hash Table)。
·DHT 也可译为分布式哈希表,由大量对等方共同维护。
·广泛使用的 Chord 算法是美国麻省理工大学于 2001 年提出的。
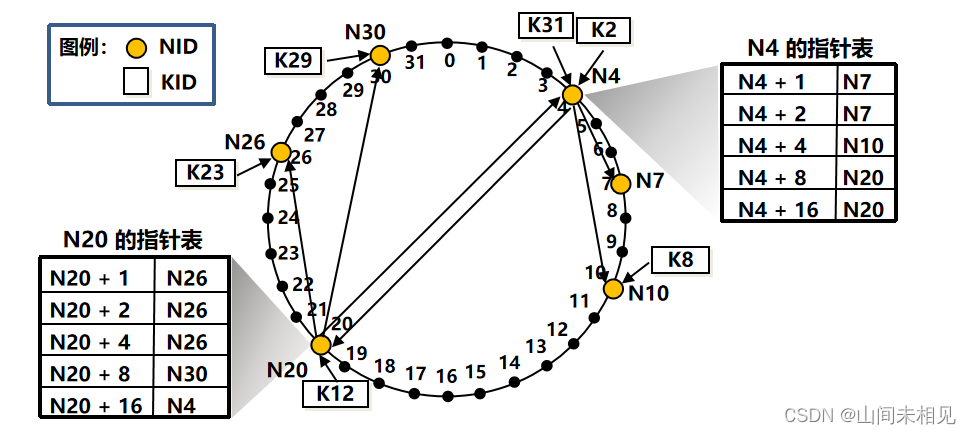
基于 DHT 的 Chord 环
·分布式散列表 DHT 利用散列函数,把资源名 K 及其存放的结点 IP 地址 N 都分别映射为资源名标识符 KID 和结点标识符 NID。
·Chord 把结点按标识符数值从小到大沿顺时针排列成一个环形覆盖网络。
·每个资源由 Chord 环上与其标识符值最接近的下一个结点提供服务。

通过指针表加速 Chord 表查找
·为了加速查找,在 Chord 环上可以增加一些指针表(finger table),又称为路由表或查找器表。
·对于结点 N4,其指针表的第 2 列第 i 行根据(N4 + 2i – 1)计算得出其后继结点。
欢迎一起学习~
- 前端界面 [详细] -->
赞
踩
- 输入框代码:
[详细] -->赞
踩

