
- 1MySQL 数据库查询缓存query_cache_type
- 2linux删除文件_Linux 删除目录下文件的 10 种方法
- 3js 获取元素的方式_js获取元素
- 4神经网络小记-主要组成简介_5.在神经网络中,基本的组成单元
- 5centos7挂起后重新启动无法网络连接_centos 挂起恢复后需要注意的事项
- 6Java中 单例(Singleton)的两种方式
- 7SSM(Spring+Springmvc+MyBatis)+ajax+JWT,实现登录JWT(token)认证获取权限_springmvc jwt
- 8mysql sql 关联更新数据库表_mysql的多表关联更新怎么写?
- 9Android VLC播放器二次开发2——CPU类型检查+界面初始化_ovv.cyp
- 10Axure教程—图片手风琴效果_csdn axure手风琴
使用JavaScript构建LLM驱动的基于Web的AI应用_javascript ai
赞
踩
众所周知,机器学习长时间以来主要是一门Python的领域,但最近ChatGPT的流行大幅增加了许多新的开发者。考虑到JavaScript是最广泛使用的编程语言,因此许多Web开发者也被吸引进入这个领域,自然而然地尝试构建Web应用程序。
已经有大量的文章讨论了通过API调用来使用LLMs,比如OpenAI、Anthropic、Google等,所以我想尝试一种不同的方法,尝试使用仅限本地模型和技术来构建Web应用程序,最好是在浏览器中运行的技术!
为什么用JavaScript?
这种构建方式的一些主要优势包括:
-
成本。由于所有计算和推断都在客户端进行,开发者构建应用程序时不需要额外的成本,只需要(非常便宜的)托管费用。
-
隐私。没有任何数据需要离开用户的本地计算机!
-
潜在的速度提升,因为没有HTTP调用的开销(这可能会因用户硬件限制而导致推断速度较慢而受到抵消)。
以一个项目为例子
我决定尝试使用开源、本地运行的软件来重新创建LangChain最流行的用例之一:执行检索增强生成(RAG),并允许您与文档进行交流。这使您可以从各种非结构化格式中锁定的数据中获取信息。
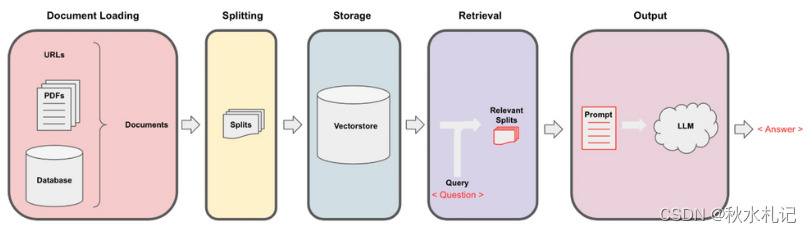
数据嵌入
首先要采取的步骤是加载我们的数据并以后可以使用自然语言进行查询的方式进行格式化。这包括以下内容:
-
将文档(PDF、网页或其他数据)拆分为语义块
-
使用嵌入模型创建每个块的向量表示
-
将这些块和向量加载到一个称为向量存储的专门数据库中
这些初始步骤需要一些组件:文本分割器、嵌入模型和向量存储。幸运的是,所有这些都已经存在于适用于浏览器的JavaScript中!
LangChain负责文档的加载和分割。对于嵌入模型,我使用了一个小型的HuggingFace嵌入模型,通过Xenova的Transformers.js包在浏览器中运行。至于向量存储,我使用了一个非常不错的Web Assembly向量存储,名为Voy。
检索和生成
既然我已经建立了加载数据的流水线,下一步就是查询数据:
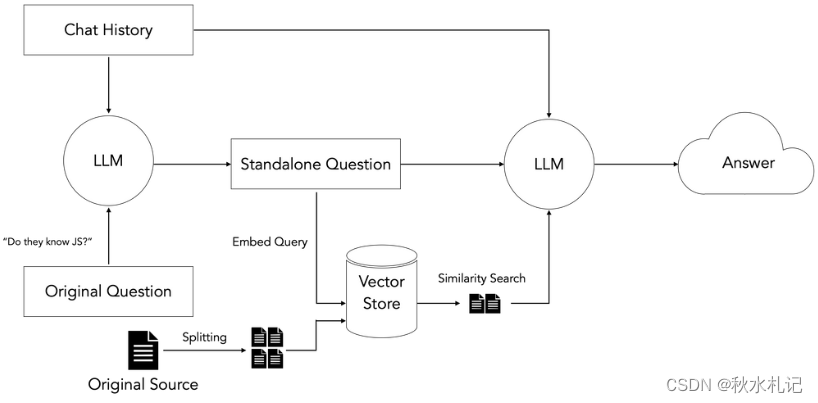
这里的一般想法是获取用户的输入问题,搜索我们准备好的向量存储,找到与查询语义最相似的文档块,并使用检索到的块以及原始问题来引导LLM生成基于我们的输入数据的最终答案。
对于后续问题,还需要额外的步骤,因为这些问题可能包含代词或其他引用之前的聊天历史。由于向量存储通过语义相似性来执行检索,这些引用可能会干扰检索。因此,我们添加了一个额外的去引用步骤,将初始步骤重新表述成一个“独立”的问题,然后使用该问题来搜索我们的向量存储。
寻找一个可以在浏览器中运行的LLM是困难的——强大的LLM模型非常庞大,而通过HuggingFace提供的模型在生成响应方面表现不佳。还有Machine Learning Compilation的WebLLM项目,看起来很有前途,但需要在页面加载时下载数GB的大文件,这会增加大量延迟。
Machine Learning Compilation的WebLLM项目 : https://webllm.mlc.ai/?ref=blog.langchain.dev

我之前曾尝试使用Ollama,它是一种简单的、开箱即用的方式来运行本地模型,当我听说可以通过shell命令将本地运行的模型暴露给Web应用程序时,我感到非常惊喜。我将它连接到了系统,并发现它是缺失的一部分!我启动了更先进的、最新的Mistral 7B模型,它在我的16GB M2 MacBook Pro上运行得非常顺畅,最终得到了以下本地堆栈:

结果
您可以在Vercel上尝试Next.js应用程序的实时版本,链接在这里。
您需要在本地计算机上通过Ollama运行一个Mistral实例,并通过运行以下命令使其在相关域名上可访问,以避免CORS问题:
- ollama run mistral
- OLLAMA_ORIGINS=https://webml-demo.vercel.app OLLAMA_HOST=127.0.0.1:11435 ollama serve
它的另一个差异化方面是它使用了保密计算,这意味着甚至它的匿名化服务也无法访问原始数据;这对于追求隐私的用户来说是一个很棒的功能。最后,它会在从LLM获取响应后对数据进行去匿名化,因此用户将获得包含他们提到/请求的原始实体的答案。
以下是在我们的可观察性和跟踪平台LangSmith中的一些示例跟踪,针对一些问题。我使用了我的个人简历作为输入文档:
-
"Who is this about?”
-
"Do they know JavaScript?”
结论
总的来说,这个项目进展顺利。以下是一些观察:
-
开源模型正在迅速发展——我用Llama 2构建了这个应用程序的初始版本,而Mistral在几周后才被宣布。
-
越来越多的消费类硬件制造商将GPU纳入他们的产品中。
-
随着开源模型变得更小更快,使用类似Ollama的工具在本地硬件上运行这些模型将变得越来越普遍。
-
尽管在过去几个月中,用于向量存储、嵌入模型和其他任务特定模型的浏览器友好技术取得了一些令人难以置信的进展,但LLM模型仍然过于庞大,难以合理地捆绑在Web应用程序中发布。
对于Web应用程序利用本地模型的唯一可行解决方案似乎是我上面使用的流程,其中一个强大的、预安装的LLM模型被暴露给应用程序。
一个新的浏览器API?
由于非技术性的Web终端用户可能不太愿意运行shell命令,因此最好的答案似乎是创建一个新的浏览器API,使Web应用程序可以请求访问本地运行的LLM,例如通过一个弹出窗口,然后将该功能与其他浏览器内任务特定模型和技术一起使用。

以下是该应用程序中使用的各种组件的链接:
Demo app: https://webml-demo.vercel.app/
Demo app GitHub repo: https://github.com/jacoblee93/fully-local-pdf-chatbot
Voy: https://github.com/tantaraio/voy
Ollama: https://github.com/jmorganca/ollama/
LangChain.js: https://js.langchain.com/
Transformers.js: https://huggingface.co/docs/transformers.js/index
文章来源: https://blog.langchain.dev/building-llm-powered-web-apps-with-client-side-technology/
作者:
Hacubu https://twitter.com/Hacubu
视频: https://www.youtube.com/watch?v=-1sdWLr3TbI

