
热门标签
热门文章
- 1Unity3D 设置透明材质_unity透明材质
- 2Windows on Arm平台浅尝pytorch-directml (x64)_pytorch on arm
- 3CurSor安装教程
- 4万字长文,详述TRIDENT: Poseidon 哈希算法的硬件加速与实现!_hash算法硬件
- 5【python】基础知识巩固(六)_turtle.rt
- 6实战PyQt5: 141-QChart图表之箱形图_pyqt qchart
- 7JSP的作用和特点_jsp表达式的作用和特点
- 8Eclipse中安装Jetty服务器
- 9【虚拟仿真】Unity3D中实现控制物体的旋转、移动、缩放_unity slider控制物体旋转
- 10八、Sqlsugar 通用方法整理
当前位置: article > 正文
LLaMA模型微调版本:斯坦福 Alpaca 详解_alpace全参微调
作者:小蓝xlanll | 2024-02-22 20:26:17
赞
踩
alpace全参微调
Alpaca 总览
Alpaca 是 LLaMA-7B 的微调版本,使用Self-instruct[2]方式借用text-davinct-003构建了52K的数据,同时在其构建策略上做了一些修改。
性能上作者对Alpaca进行了评估,与openai的text-davinct-003模型在self-instruct[2]场景下的性能表现相似。所以比起成本来看,Alpaca更便宜。
text-davinct-003 与 chatGPT 同为 gpt3.5模型之一,比GPT-3模型 curie、babbage、ada 模型更好的质量、更长的输出和一致的指令遵循来完成任何语言任务
整体思路如下图
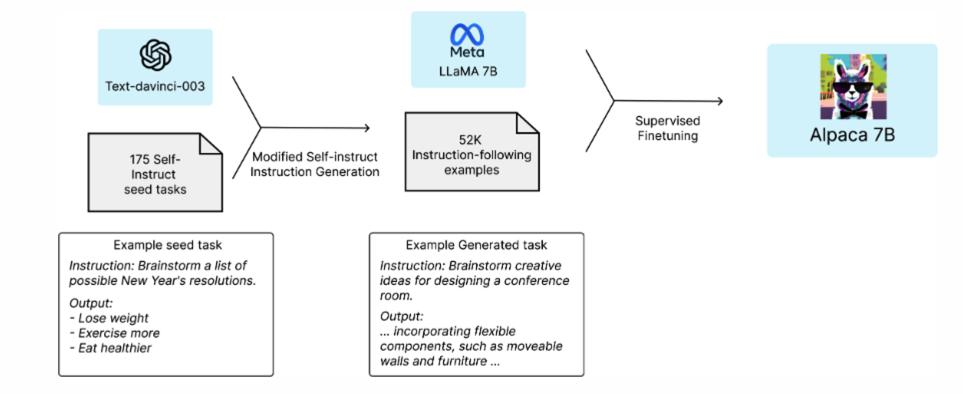
基于 Self-instruct 的数据生成
Self-instruct
Self-instruct是一个利用LLM来生成指令遵循数据来指令微调模型的框架,核心贡献是生成指令遵循数据。
指令数据由指令、输入、输出组成。作者的数据生成piple包含四个步骤:
1)生成任务指令,
2)确定指令是否代表分类任务,方便3区别
3)正常任务使用输入优先方法,分类任务使用输出优先的prompt指令方法生成实例
4)过滤低质量的数据。

详细的Self-instruct可以看我别的文章。
Alpaca
Alpaca基于self-instruct,
- 改用GPT-3.5:text-davinci-003来生成指令数据(self-instruct使用的GPT-3:davinci)
- 指令生成时使用新的prompt,直接一次性生成20个任务的指令(self-instruct是迭代生成的,更费钱)
- 指令生成不区分 分类/非分类任务,可能是GPT3.5更好,不需要区别了。
- 每个指令只生成1个实例。
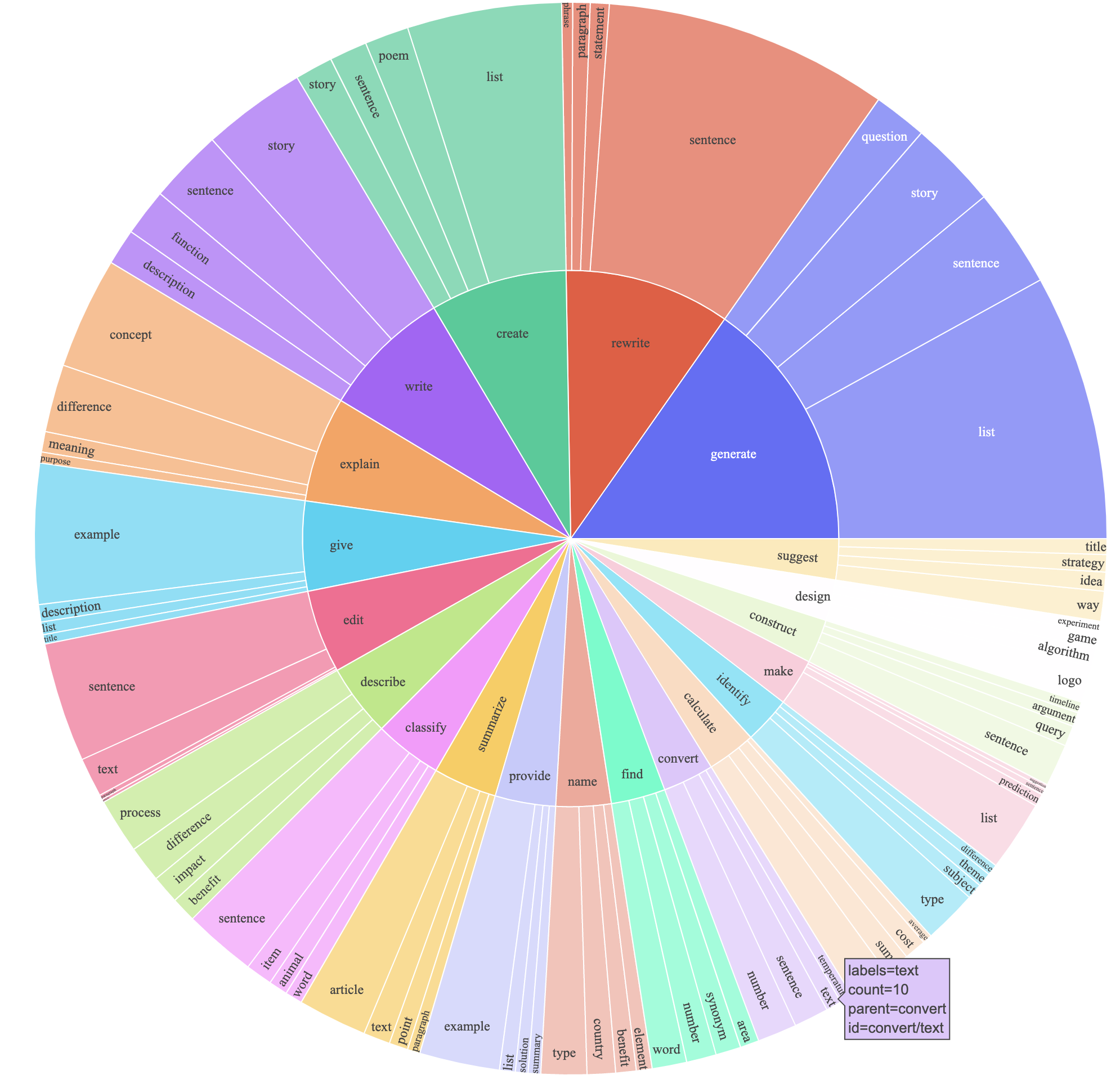
最终的结果是以少于$500的便宜价格获得了52K的数据,下图反映了其数据多样性,内圈是词根是动词的指令,外圈是表示目标的指令。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/131310
推荐阅读
相关标签

