
- 1react中form可以嵌套一个form吗_React Hooks在SD-WAN项目中实践
- 2Unity踩坑:解决ui自转时不停抖动Bug_unity 多个物体跟随问题出现抖动
- 31.深度学习环境配置-windows11安装cuda和cudnn驱动_win11深度学习显卡驱动选取
- 4unity 查找所以物体_用Unity来实现一下绳子效果——Obi Rope插件介绍
- 5QT+OSG/osgEarth编译之二:giflib+Qt编译(一套代码、一套框架,跨平台编译,版本:giflib-5.2.1)_giflib编译
- 6invalid use of incomplete type struct 或者是class的解决办法_invalid use of incomplete type 鈥榮truct
- 7【Unity2D像素风格小游戏】期末考考完,和搭档一个月从零开始的Unity速成作品!_像素游戏开发csdn
- 8PyTorch搭建预训练AlexNet、DenseNet、ResNet、VGG实现猫狗图片分类_如何调用densenetnet等预训练模型 pytorch
- 9windows nexus安装_nexus私服搭建及使用笔记
- 10数学建模-相关性分析(Matlab)_matlab相关性分析代码
用 Python 从单个文本中提取关键字的四种超棒的方法_笔录信息中的部分关键词特征提取
赞
踩
自然语言处理分析的最基本和初始步骤是关键词提取,在NLP中,我们有许多算法可以帮助我们提取文本数据的关键字。本文中,云朵君将和大家一起学习四种即简单又有效的方法,它们分别是 Rake、Yake、Keybert 和 Textrank。并将简单概述下每个方法的使用场景,然后使用附加示例将其应用于提取关键字。
本文关键字:关键字提取、关键短语提取、Python、NLP、TextRank、Rake、BERT
在我之前的文章中,我介绍了使用 Python 和 TFIDF 从文本中提取关键词,TFIDF 方法依赖于语料库统计来对提取的关键字进行加权,因此它的缺点之一是不能应用于单个文本。
为了说明每种关键字提取方法(Rake、Yake、Keybert 和 Textrank)的实现原理,将使用已发表的文章[1]的摘要以及主题指定的关键字,并通过检查哪些方法的提取的关键词与作者设置的关键词更接近,来检验每种方法。在关键词提取任务中,有显式关键词,即显式地出现在文本中;也有隐式关键词,即作者提到的关键词没有显式地出现在文本中,而是与文章的领域相关。

在上图展示的示例中,有文本标题和文章摘要,标准关键字(由作者在原始文章中定义)被标记为黄色。注意machine learning这个词并不明确,也没有在摘要中找到。虽然可以在文章的全文中提取,但这里为了简单起见,语料数据仅限于摘要。
文本准备
标题通常与提供的文本相结合,因为标题包含有价值的信息,并且高度概括了文章的内容。因此,我们将文本和标题两个变量之间通过加上一个加号而简单地拼接。
- title = "VECTORIZATION OF TEXT USING DATA MINING METHODS"
-
- text = "In the text mining tasks, textual representation should be not only efficient but also interpretable, as this enables an understanding of the operational logic underlying the data mining models. Traditional text vectorization methods such as TF-IDF and bag-of-words are effective and characterized by intuitive interpretability, but suffer from the «curse of dimensionality», and they are unable to capture the meanings of words. On the other hand, modern distributed methods effectively capture the hidden semantics, but they are computationally intensive, time-consuming, and uninterpretable. This article proposes a new text vectorization method called Bag of weighted Concepts BoWC that presents a document according to the concepts’ information it contains. The proposed method creates concepts by clustering word vectors (i.e. word embedding) then uses the frequencies of these concept clusters to represent document vectors. To enrich the resulted document representation, a new modified weighting function is proposed for weighting concepts based on statistics extracted from word embedding information. The generated vectors are characterized by interpretability, low dimensionality, high accuracy, and low computational costs when used in data mining tasks. The proposed method has been tested on five different benchmark datasets in two data mining tasks; document clustering and classification, and compared with several baselines, including Bag-of-words, TF-IDF, Averaged GloVe, Bag-of-Concepts, and VLAC. The results indicate that BoWC outperforms most baselines and gives 7% better accuracy on average"
-
-
- full_text = title +", "+ text
-
- print("The whole text to be usedn", full_text)
现在开始使用今天的四个主角来提取关键字!
Yake
它是一种轻量级、无监督的自动关键词提取方法,它依赖于从单个文档中提取的统计文本特征来识别文本中最相关的关键词。该方法不需要针对特定的文档集进行训练,也不依赖于字典、文本大小、领域或语言。Yake 定义了一组五个特征来捕捉关键词特征,这些特征被启发式地组合起来,为每个关键词分配一个分数。分数越低,关键字越重要。你可以阅读原始论文[2],以及yake 的Python 包[3]关于它的信息。
特征提取主要考虑五个因素(去除停用词后)
大写term
(Casing)
大写字母的term(除了每句话的开头单词)的重要程度比那些小写字母的term重要程度要大。
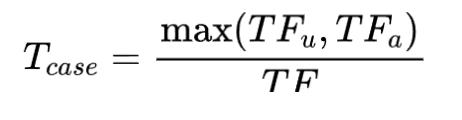
其中, 表示该词的大写次数, 表示该词的缩写次数。
词的位置
(Word Position)
文本越开头的部分句子的重要程度比后面的句子重要程度要大。
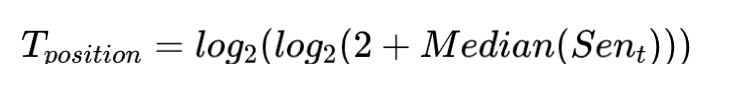
其中 表示包含该词的所有句子在文档中的位置中位数。
词频
(Term Frequency)
一个词在文本中出现的频率越大,相对来说越重要,同时为了避免长文本词频越高的问题,会进行归一化操作。
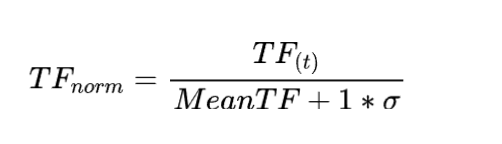
其中,MeanTF是整个词的词频均值, 是标准差。
上下文关系
(Term Related to Context)
一个词与越多不相同的词共现,该词的重要程度越低。
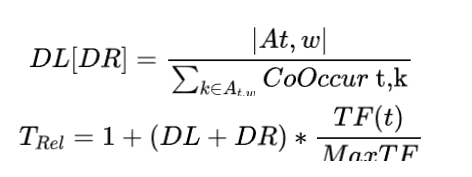
其中 表示窗口size为 从左边滑动, 表示从右边滑动。 表示出现在固定窗口大小为 下,出现不同的词的个数。 表示所有词频的最大值。
词在句子中出现的频率
(Term Different Sentence)
一个词在越多句子中出现,相对更重要
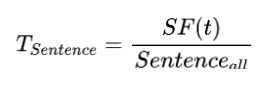
其中 SF(t) 是包含词t tt的句子频率, 表示所有句子数量。
最后计算每个term的分值公式如下:

S(t)表示的是单词t 的分值情况,其中 s(t)分值越小,表示的单词 t越重要。
安装和使用
- pip install git+https://github.com/LIAAD/yake
- import yake
首先从 Yake 实例中调用 KeywordExtractor 构造函数,它接受多个参数,其中重要的是:要检索的单词数top,此处设置为 10。参数 lan:此处使用默认值en。可以传递停用词列表给参数 stopwords。然后将文本传递给 extract_keywords 函数,该函数将返回一个元组列表 (keyword: score)。关键字的长度范围为 1 到 3。
- kw_extractor = yake.KeywordExtractor(top=10, stopwords=None)
- keywords = kw_extractor.extract_keywords(full_text)
- for kw, v in keywords:
- print("Keyphrase: ",kw, ": score", v)

从结果看有三个关键词与作者提供的词相同,分别是text mining, data mining 和 text vectorization methods。注意到Yake会区分大写字母,并对以大写字母开头的单词赋予更大的权重。
Rake
Rake 是 Rapid Automatic Keyword Extraction 的缩写,它是一种从单个文档中提取关键字的方法。实际上提取的是关键的短语(phrase),并且倾向于较长的短语,在英文中,关键词通常包括多个单词,但很少包含标点符号和停用词,例如and,the,of等,以及其他不包含语义信息的单词。
Rake算法首先使用标点符号(如半角的句号、问号、感叹号、逗号等)将一篇文档分成若干分句,然后对于每一个分句,使用停用词作为分隔符将分句分为若干短语,这些短语作为最终提取出的关键词的候选词。
每个短语可以再通过空格分为若干个单词,可以通过给每个单词赋予一个得分,通过累加得到每个短语的得分。Rake 通过分析单词的出现及其与文本中其他单词的兼容性(共现)来识别文本中的关键短语。最终定义的公式是:
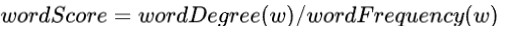
即单词 的得分是该单词的度(是一个网络中的概念,每与一个单词共现在一个短语中,度就加1,考虑该单词本身)除以该单词的词频(该单词在该文档中出现的总次数)。
然后对于每个候选的关键短语,将其中每个单词的得分累加,并进行排序,RAKE将候选短语总数的前三分之一的认为是抽取出的关键词。
安装和使用
- # $ git clone https://github.com/zelandiya/RAKE-tutorial
- # 要在python代码中导入rake:
- import rake
- import operator
-
- # 加载文本并对其应用rake:
- filepath = "keyword_extraction.txt"
- rake_object = rake.Rake(filepath)
- text = "Compatibility of systems of linear constraints over the set of natural numbers. Criteria of compatibility of a system of linear Diophantine equations, strict inequations, and nonstrict inequations are considered.Upper bounds for components of a minimal set of solutions and algorithms of construction of minimal generatingsets of solutions for all types of systems are given. These criteria and the corresponding algorithms for constructing a minimal supporting set of solutions can be used in solving all the considered types of systems and systems of mixed types."
- sample_file = open(“data/docs/fao_test/w2167e.txt”, ‘r’)
- text = sample_file.read()
- keywords = rake_object.run(text) print “Keywords:”, keywords
候选关键字
如上所述,我们知道RAKE通过使用停用词和短语分隔符解析文档,将包含主要内容的单词分类为候选关键字。这基本上是通过以下一些步骤来完成的,首先,文档文本被特定的单词分隔符分割成一个单词数组,其次,该数组再次被分割成一个在短语分隔符和停用单词位置的连续单词序列。最后,位于相同序列中的单词被分配到文本中的相同位置,并一起被视为候选关键字。
- stopwordpattern = rake.build_stop_word_regex(filepath)
- phraseList = rake.generate_candidate_keywords(sentenceList, stopwordpattern)
关键词得分
从文本数据中识别出所有候选关键字后,将生成单词共现图,该图计算每个候选关键字的分数,并定义为成员单词分数。借助该图,我们根据图中顶点的程度和频率评估了计算单词分数的几个指标。
keywordcandidates = rake.generate_candidate_keyword_scores(phraseList, wordscores)提取关键词
计算候选关键字得分后,将从文档中选择前T个候选关键字。T值是图中字数的三分之一。
- totalKeywords = len(sortedKeywords)
- for keyword in sortedKeywords[0:(totalKeywords / 3)]:
- print “Keyword: “, keyword[0], “, score: “, keyword[1]
另一个库
- # pip install multi_rake
- from multi_rake import Rake
- rake = Rake()
- keywords = rake.apply(full_text)
- print(keywords[:10])

TextRank
TextRank 是一种用于提取关键字和句子的无监督方法。它一个基于图的排序算法。其中每个节点都是一个单词,边表示单词之间的关系,这些关系是通过定义单词在预定大小的移动窗口内的共现而形成的。
该算法的灵感来自于 Google 用来对网站进行排名的 PageRank。它首先使用词性 (PoS) 对文本进行标记和注释。它只考虑单个单词。没有使用 n-gram,多词是后期重构的。
TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
把给定的文本T按照完整句子进行分割,即
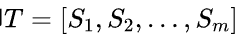
对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即
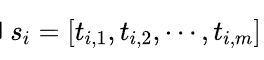
其中是保留后的候选关键词。
构建候选关键词图G=(V, E) ,其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系co-occurrence构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
根据上面公式,迭代传播各节点的权重,直至收敛。
对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
安装及使用
要使用Textrank生成关键字,必须首先安装 summa 包,然后必须导入模块 keywords。
- pip install summa
- from summa import keywords
之后,只需调用 keywords 函数并将要处理的文本传递给它。我们还将 scores 设置为 True 以打印出每个结果关键字的相关性。
- TR_keywords = keywords.keywords(full_text, scores=True)
- print(TR_keywords[0:10])
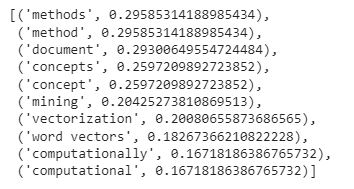
KeyBERT
KeyBERT[4]是一种简单易用的关键字提取算法,它利用 SBERT 嵌入从文档中生成与文档更相似的关键字和关键短语。首先,使用 sentences-BERT 模型生成文档embedding。然后为 N-gram 短语提取词的embedding。然后使用余弦相似度测量每个关键短语与文档的相似度。最后将最相似的词识别为最能描述整个文档并被视为关键字的词。
安装和使用
要使用 keybert 生成关键字,必须先安装 keybert 包,然后才能导入模块 keyBERT。
- pip install keybert
- from keybert import KeyBERT
然后创建一个接受一个参数的 keyBERT 实例,即 Sentences-Bert 模型。可以从以下来源[5]中选择想要的任何embedding模型。根据作者的说法,all-mpnet-base-v2模型是最好的。
kw_model = KeyBERT(model='all-mpnet-base-v2')它将像这样开始下载:
下载 BERT 预训练模型
- keywords = kw_model.extract_keywords(full_text,
- keyphrase_ngram_range=(1, 3),
- stop_words='english',
- highlight=False,
- top_n=10)
-
- keywords_list= list(dict(keywords).keys())
- print(keywords_list)

考虑到大多数关键短语的长度在 1 到 2 之间,可以将 keyphrase_ngram_range 更改为 (1,2)。这次我们将 highlight 设置为 true。

参考资料
[1]
文章: https://www.researchgate.net/publication/353592446_TEXT_VECTORIZATION_USING_DATA_MINING_METHODS
[2]
论文: https://www.sciencedirect.com/science/article/abs/pii/S0020025519308588
[3]
yake包: https://github.com/LIAAD/yake
[4]
KeyBERT: https://github.com/MaartenGr/KeyBERT
[5]
pretrained_models: https://www.sbert.net/docs/pretrained_models.html
[6]
[7]
https://blog.csdn.net/chinwuforwork/article/details/77993277

