
- 1机器学习笔记丨神经网络的反向传播原理及过程(图文并茂+浅显易懂)_神经网络反向传播原理
- 2vue细节讲解
- 3一维振动信号连续小波变换获得时频图(python)_sampling_period: 采样率(根据数据集实际情况设置,比如数据集采样率为12khz,则s
- 4RabbitMQ交换机(2)-Direct
- 5CentOS 7 Samba 共享云_centos frp samba cloud
- 6让AI“读懂”短视频,爱奇艺内容标签技术解析_爱奇艺开源视频分类算法
- 7Unity UnityWebRequest: InvalidOperationException: Insecure connection not allowed
- 8线性回归模型_线性模型的损失函数是凸函数吗
- 9对Numpy库ndarray对象(矩阵)中的数据元素的访问、选取操作示例_numpy.ndarray怎么获取元素
- 10更改element button 按钮颜色_el-button 按钮颜色
MyBatis缓存原理_mybatisplus多级缓存
赞
踩
前言
提示:自从上次发现mybatis缓存可被修改后,就一直想针对myBatis缓存单独做一期分析,包含其原理和运行方式,现在终于得空来详细写一篇了
一、MyBatis的两级缓存介绍
熟悉MyBatis的应该知道,MyBatis内置了两级缓存,会在查询数据库时,将查询结果缓存到内存中,以便下次查询时可以直接从缓存中获取数据,从而提高数据查询效率
MyBatis缓存一般分为一级缓存和二级缓存。
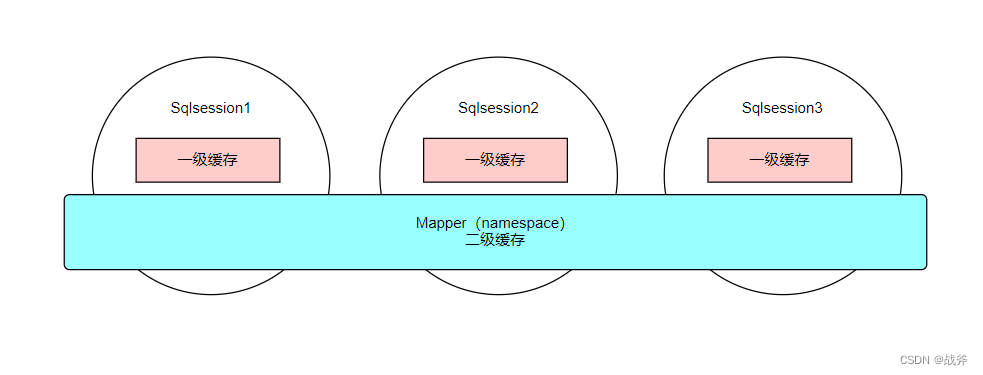
- 一级缓存
是指MyBatis自身的缓存机制,是SqlSession级别的缓存。当同一个SqlSession执行相同的SQL语句时,MyBatis会将查询结果缓存到内存中。一级缓存的作用域是SqlSession,当当前的SqlSession关闭时,一级缓存也将被清空。
- 二级缓存
是指MyBatis全局的缓存机制,在多个SqlSession之间共享缓存数据。二级缓存的作用域是Mapper级别的,每个Mapper对应一个缓存。在同一应用程序中的多个SqlSession都可以共享同一个缓存,这是一种横向共享的缓存机制。但是需要注意的是,该缓存只有在Mapper映射文件中声明了缓存的情况下才能启用。
二、一级缓存
1. sqlSession的结构和目的
在说SqlSession级别的缓存前,我们需要介绍下sqlSession本身的一些内容。我们都知道,在早期项目中,与数据库的连接通常以JDBC 的 connection(即连接)为核心,通过jdbc的API获取数据库连接,并执行代码,其形式大体如下:
import java.sql.*;
public class MySqlConnectionExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase";
String user = "root";
String password = "mypassword";
String sql = "SELECT * FROM mytable";
try {
// 1. 加载 MySQL JDBC 驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 建立数据库连接(仅举例,实际项目一般都有连接池)
Connection conn = DriverManager.getConnection(url, user, password);
// 3. 创建 Statement 对象
Statement stmt = conn.createStatement();
// 4. 执行 SQL 查询语句,并返回结果集
ResultSet rs = stmt.executeQuery(sql);
// 5. 遍历结果集,输出查询结果
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
System.out.println("id: " + id + ", name: " + name);
}
// 6. 关闭结果集、Statement 对象和数据库连接
rs.close();
stmt.close();
conn.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
看起来,通过获取连接来执行sql似乎就够了,为什么myBatis还要加入一个sqlSqlsession,sqlSqlsession又是拿来做什么的呢?其实,使用 SqlSession 相比于 Connection 直接执行 SQL 的主要优点如下:
- 封装了数据库连接的创建和释放,简化了代码编写,降低了出错风险。
- 提供了多种执行 SQL 的方法,支持动态 SQL 和对象关系映射(ORM)等高级特性。
- 支持缓存机制,可以缓存操作结果和查询结果,提高系统性能。
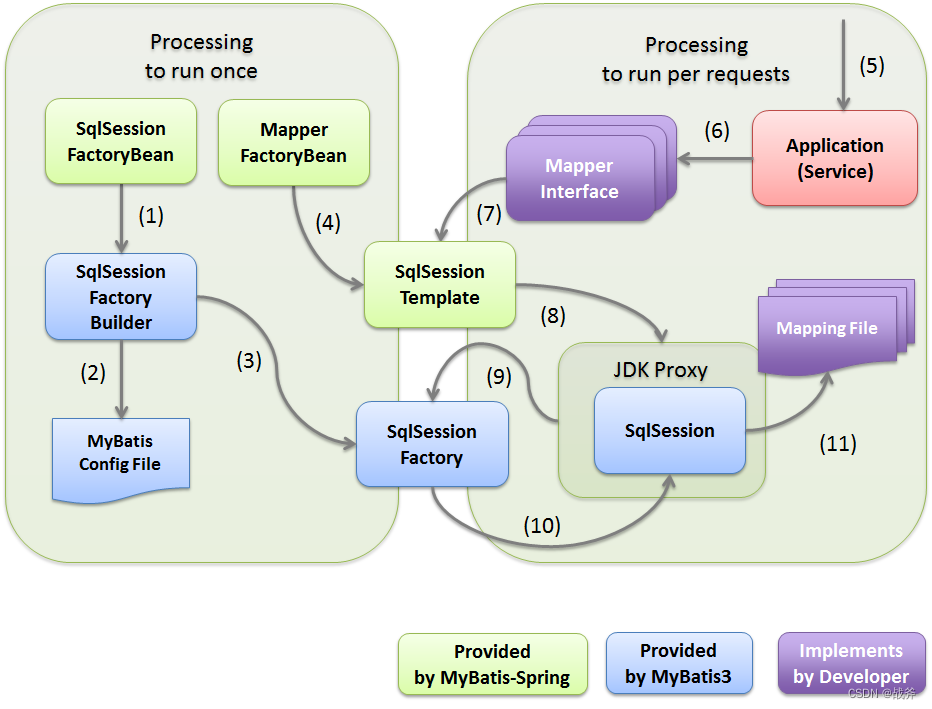
在应用程序启动时执行的进程。下述处理(1)至(4)对应于这种类型
- SqlSessionFactoryBean 请求SqlSessionFactory 构建SqlSessionFactoryBuilder
- SqlSessionFactoryBuilder 读取 MyBatis 配置文件生成SqlSessionFactory.
- SqlSessionFactoryBuilder 根据 MyBatis 配置文件的定义生成SqlSessionFactory ,SqlSessionFactory 生成的对象由 Spring 容器存储
- MapperFactoryBean 生成一个线程安全的SqlSession (SqlSessionTemplate)和一个线程安全的Mapper对象(Mapper接口的Proxy对象)。生成的Mapper对象存储在Spring 容器中。Mapper对象使用线程安全的SqlSession ( 即 SqlSessionTemplate) 提供线程安全的实现。
为每个请求执行的过程。下述处理(5)至(11)对应于这种类型
- 请求应用程序的进程
- Application(Service)调用容器注入的Mapper对象(实现Mapper接口的Proxy对象)的方法。
- Mapper对象调用与之对应的SqlSession (SqlSessionTemplate) 方法。
- SqlSession ( SqlSessionTemplate) 启用代理并调用其线程安全的SqlSession 方法
- 代理内的SqlSession 分配给事务。当事务没有对应的sqlSession时,将调用SqlSessionFactory 去获取一个SqlSession
- SqlSessionFactory 返回 SqlSession。返回的SqlSession 被分配给事务,如果它在同一个事务内,则使用该SqlSession而不创建新的
- SqlSession 从映射文件中获取要执行的 SQL 并执行 SQL。
2. sqlSession缓存
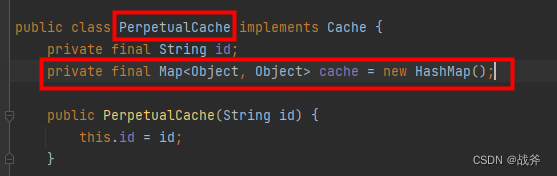
sqlSession缓存并非直接挂在sqlSession对象下,而是存储在执行器 BaseExecutor.class 中的 localCache(缓存查询结果) 和 localOutputParameterCache(缓存存储过程调用结果)实现,类名为 PerpetualCache.class
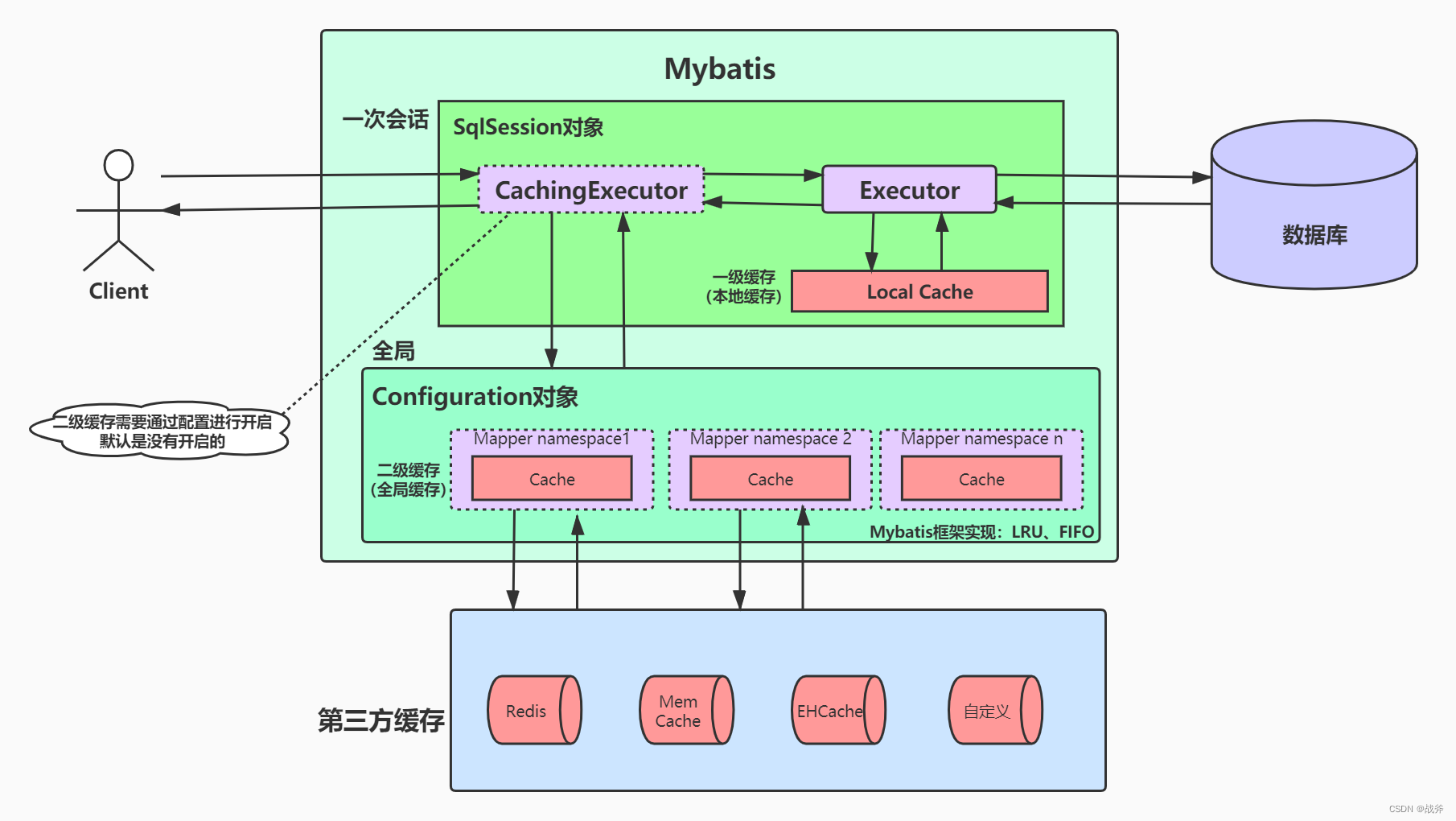
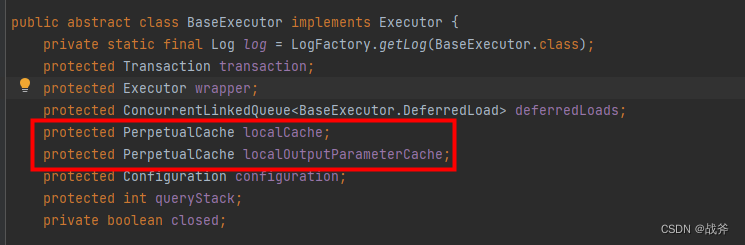
而PerpetualCache类则内含一个普通的HashMap,这个HashMap即真正的缓存位置
这样的缓存键值对,值我们是能想到的,就是SQL查询后返回的结果列表,那么键是什么呢?
CacheKey key = this.createCacheKey(ms, parameter, rowBounds, boundSql);
- 1
CacheKey 由以下几个因素影响
- namespace.id
- 用户传递给 SQL 语句的实际参数值
- 指定查询结果集的范围(分页信息)
- 查询所使用的 SQL 语句
而它的存储流程,其实很简单
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 省略部分代码
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 如果开启了flushCache,则清除缓存
clearLocalCache();
}
List<E> list;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
// 省略部分代码
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
this.localCache.putObject(key, ExecutionPlaceholder.EXECUTION_PLACEHOLDER);
List list;
try {
list = this.doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
this.localCache.removeObject(key);
}
this.localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
this.localOutputParameterCache.putObject(key, parameter);
}
return list;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3. 缓存生命周期
BaseExecutor不仅定义了一级缓存,同时也声明了这种缓存的生命周期:
- 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
- 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
- SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可-以继续使用;
- 会话结束
但是,从源码我们不难发现一个问题,从缓存中取到的内容,是作为查询结果直接返回的。这意味着,如果我们对结果进行修改,将直接改变缓存值。并且,因为一级缓存没有提供关闭的参数,所以此时我们有两种方式解决
- 深拷贝sql结果,对拷贝的对象进行操作而非原对象
- 对指定sql,设置参数 flushCache=“true”,表示任何时候语句被调用,都会导致本地缓存和二级缓存被清空,形如
<select id="save" parameterType="XX" flushCache="true" useCache="false"> </select>
这样设置能生效的原因是,该参数打开后,会在SQL执行前清除掉缓存,这样相当于禁用了缓存功能
三、二级缓存
1. 开启二级缓存
二级缓存不同于一级缓存,它默认是关闭的,需要手动开启,我们知道一级缓存是由BaseExecutor负责存储的,那么负责二级缓存的实际上是它的兄弟类CachingExecutor
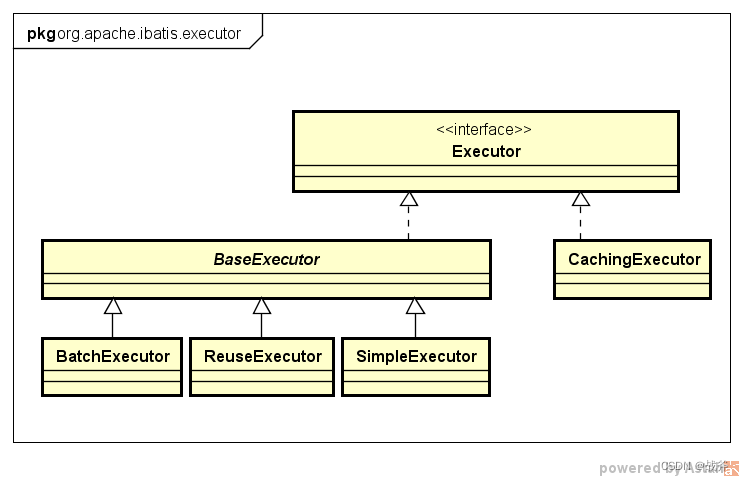
它的缓存存储位置在TransactionalCacheManager 类中
public class CachingExecutor implements Executor {
// 普通的执行器,通常就是我们上面的BaseExecutor的一个子类
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
}
public class TransactionalCacheManager {
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
那么,我们如何才能启用这个执行器呢?首先,我们必须得在全局设置缓存可用,在配置文件上加上
mybatis.configuration.cache-enabled=true
或
mybatis-plus.configuration.cache-enabled=true
然后在我们都mapper层加上设置即可。
<mapper namespace="xx.xxx.xxx.mapper.xxxMapper">
<cache eviction="FIFO" flushInterval="60000" readOnly="false" size="1024"></cache>
</mapper>
- 1
- 2
- 3
当然,如果sql不是以xml形式写的,而是在mapper接口里以注解形式写的,那只要在mapper层加上注解 @CacheNamespace 也是同样的效果
2. 二级缓存的弊端
二级缓存开启后,同一个 namespace 下的所有操作语句,都影响着同一个 Cache,即二级缓存被多个 SqlSession 共享,是一个全局的变量。
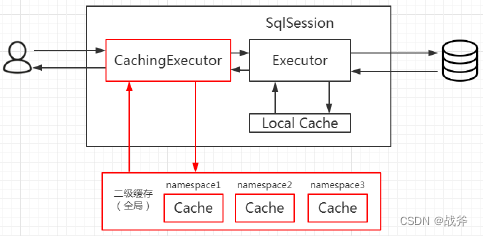
即使我们为其设定了自动刷新的时间,二级缓存的脏读概率仍然很大。尤其是在多表查询的情况下,尽管可以给不同的mapper设定同一个缓存,但复杂场景下这种繁琐的配置几乎不可用。
<cache-ref namespace="com.example.mapper.UserInfoMapper" />
- 1
所以二级缓存实际上很少有人会开启。

