
- 1Leaflet包:从入门到跑路(一)_leaflet csdn
- 2鸿蒙安卓开发教程,Day5 鸿蒙,是如何精简安卓应用的界面开发的
- 3[Android Studio]新手向,安装创建项目构建很慢,下载依赖很慢的问题_安卓下载依赖慢
- 4STM32CubeMX 软件使用学习笔记1_cubemx有什么用
- 5深度学习04-CNN经典模型_cnn模型
- 6leetcode: 322.零钱兑换_leetcode 零钱兑换
- 7Android Studio 无法输入中文_android studio无法输入中文
- 8Spring Boot 中的 Sleuth 详解
- 9学习笔记之——基于深度学习的目标检测算法_特征映射 m属于h*w*
- 10数据结构-链表(二)
【Linux】——进程创建fork()详解_fork进程
赞
踩
一、fork()作用
我们都知道fork可以用于进程的创建,那首先我们来了解一下fork函数原型和基本的两种用法才真正的了解我们何时才会用到fork来进行进程的创建
1、fork函数原型
fork()函数 需要引入头文件#include<unistd.h>,fork函数原型为:
pid_t fork(void)
- 1
参数含义:无参传入,返回pid_t类型的数值。pid_t 的实质是int类型的。
2、用法一
一个父进程希望复制自己,使父、子进程同时执行不同的代码段。
这在网络服务进程中是最常见的一种处理,父进程等待客户端的服务请求,当达到请求到达时,父进程调用fork,使子进程处理此请求。父进程则等待下一个服务请求到达。
3、用法二
一个进程要执行一个不同的程序
这个用法对shell是常见的情况。在这种情况下,子进程从fork返回后立即调用exec。此概念我会在后续的博文中持续更新。
【注意】
在某些操作系统中会把fork和exec这两个操作组合成一个,并称其为spawn。
但是在UNIX系统中是将两个操作分开的,因为在很多场合需要单独使用fork,后面不跟随exec操作,使得子进程在这两个操作之间可以更改自己的属性,例如I/O重定向,用户ID、信号安排等等。
二、fork()特性
1、父子进程之间的关系
-
当我们执行fork函数时用fork()函数生成一个进程,调用fork函数的进程为父进程,新生成的进程为子进程,可以理解为复制一份一样的代码;
-
创建后父子进程是两个独立的进程,各自拥有一份代码。fork()方法调用之后,父,子进程都从fork()调用之后的代码开始运行。
他们的关系如下图所示:

【举个栗子】父子进程之间的关系验证
具体代码实现如下:
int main() { pid_t n = fork(); assert(-1 != n); if(0 == n) { printf("Hello: mypid = %d, myppid = %d\n", getpid(), getppid()); } else { sleep(1); // 保证新进程先执行完 printf("World: n = %d, mypid = %d\n", n, getpid()); } exit(0); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果如下:

2、父子进程返回情况
- fork函数被调用一次,但是返回两次
- 子进程返回的是0,而父进程返回值则是新子进程的进程ID。
【注意】父进程返回值是新进程的进程ID
因为一个进程的子进程可以有多个,并且没有一个函数是一个进程可以获得其所有子进程的进程ID。父进程中没有记录子进程的PID。所以为了方便父进程知道和处理子进程,fork()返回最新子进程的pid。
【举个栗子】下面这个程序,请问输出结果是什么?
#include <stdio.h> #include <stdlib.h> #include <assert.h> #include <unistd.h> #include <string.h> int main() { pid_t n = fork(); assert(-1 != n); if(0 == n) { printf("Hello\n"); } else { printf("World\n"); } exit(0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
运行结果如下:
原因分析:这个结果就和fork的返回值有关,调用一次有两个返回结果,首先打印world,因为子进程返回的值是0,所以打印hello.
3、父子进程执行情况
- fork之后是两个独立的进程,所以两个进程会被交给操作系统,然后操作系统进行调度,调度到谁就运行谁,故父子进程并发执行,不是按顺序的,父进程和子进程输出的结果是交替的,随机的。
如下图所示的程序:
# include<stdio.h> # include<stdlib.h> # include<unistd.h> # include<string.h> # include<assert.h> int main() { pid_t pid=fork(); assert(pid!=-1); if(pid==0)//子进程 { printf("child:PPID=%d,PID=%d\n",getppid(),getpid()); int i=0; for(;i<5;i++) { printf("child\n"); sleep(1); } } else//父进程 { printf("father:PPID=%d,PID=%d\n",getppid(),getpid()); int i=0; for(;i<5;i++) { printf("father\n"); sleep(1); } } exit(0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
根据上述的执行情况,该程序的运行结果是不定的,父子进程谁先执行谁后执行都是随机的,如下图所示为执行两次该程序的不同结果:
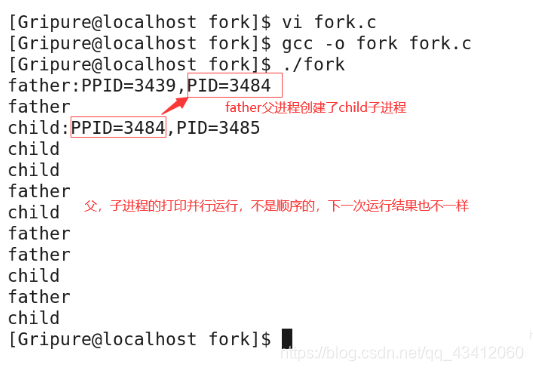
结果分析:
- 父子进程均从fork()之后的代码开始执行,也就是执行 if 判断。
- 父进程打印father,子进程打印child,我们可以看到输出的顺序不是固定的,而是随机的,每一次运行的结果是不一样的,这就是我们说的fork()之后父子进程并发执行。
4、父子进程的存储空间
我们已经知道了内存空间布局,主要由数据段,堆栈空间等组成,那么我们现在用代码来测试一下父子进程的内存空间:
思路:
- 代码定义全局初始化变量,局部初始化变量,动态开辟指针,那么它们分别在==.data段,栈,堆==存储。
- 子进程对这三个变量修改数值,子进程中输出数值和地址,父进程也输出三个变量的值和地址
- 我们用sleep来保证父进程在子进程修改数值之后执行,先让父进程睡眠,这样我们就可以根据父进程输出的数值判断子进程的修改是否影响父进程。
- 进而判断父子进程的三个变量是否存储在一块存储空间中。
代码实现如下:
# include<stdio.h> # include<stdlib.h> # include<assert.h> # include<unistd.h> int gdata=10;//全局初始化 int main() { int ldata=10; int *hdata=(int*)malloc(4); *hdata=10; pid_t pid=fork(); assert(pid!=-1); //子进程 if(pid==0) { printf("child:%d,%d,%d\n",gdata,ldata,*hdata); printf("child addr:0x%x,0x%x,0x%x\n",&gdata,&ldata,hdata); gdata=20; ldata=20; *hdata=20; printf("change num after:\n"); printf("child:%d,%d,%d\n",gdata,ldata,*hdata); printf("child addr:0x%x,0x%x,0x%x\n",&gdata,&ldata,hdata); sleep(3); } else { sleep(3);//保证子进程先修改了变量值 printf("father:%d,%d,%d\n",gdata,ldata,*hdata); printf("father addr:0x%x,0x%x,0x%x\n",&gdata,&ldata,hdata); } free(hdata); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
运行结果为:
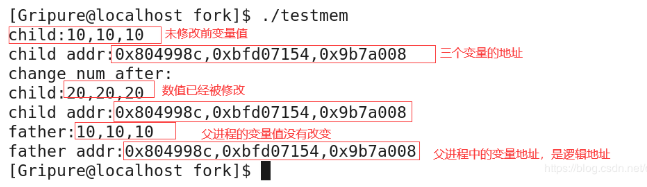
仔细观察上面运行结果,我们可以发现:
- 输出变量的地址是一样的,但是子进程修改了变量的值,父进程的值没有改变。这表示父子进程中的变量存储不在一个空间,是独立的两个存储空间
【解释】为啥输出变量的地址一样但是值却没有被修改呢?
这就涉及到我们之前所讲的逻辑地址和物理地址。我们在程序中输出的地址都是逻辑地址,需要通过映射表才能真正的得出在内存上的物理地址。因为操作系统为每一个进程维护一个页表所以即使逻辑地址一样页表不一样对应的物理地址也就不一样,数据就在不同的存储空间。
- 我们开辟动态内存,malloc只调用一次,但是free会调用两次,是因为父进程开辟了空间,然后拷贝给了子进程,子进程拥有了独立的堆空间,所以调用两次free.
5、父进程把存储空间拷贝给子进程的时机和方式
那么父进程是什么时候把自己的存储空间拷贝给子进程的呢?是一下子全部拷贝过去,还是慢慢的一部分拷贝过去呢?
我们先判断一下是否是在fork()函数执行后,父进程把自己的存储空间拷贝给子进程,然后通过系统资源管理器查看内存变化,判断是怎样拷贝的,那么还是用代码来测试,思路如下:
- 我们先在主函数中开辟1G的内存,然后初始化为0,这是父进程的存储空间
- 我们在fork()函数执行之前打印一句话,标识开始创建子进程,我们就要观察系统内存的变化了。
- 子进程对这1G的内存空间进行修改。父进程此时啥也不干,睡眠即可
- 运行程序后,我们就观察内存的变化以及终端的显示,得到何时拷贝空间和拷贝方式的答案。
测试代码实现如下:
# include<stdio.h> # include<stdlib.h> # include<assert.h> # include<unistd.h> # include<string.h> int main() { int size = 1024 * 1024 * 1024; // 设置申请的基数位1G char *ptr = (char *)malloc(size * 2); // 一共申请2G空间 // 循环使用申请的空间 int i = 0; for(; i < 32; ++i) { sleep(1); memset(ptr + i * 1024 * 1024 * 34, 'a', 1024 * 1024 * 34);//初始化32兆 } printf("I Will Fork\n"); pid_t n = fork(); assert(-1 != n); if(0 == n) { // 循环使用申请的空间 printf("child start\n"); int i = 0; for(; i < 32; ++i) { sleep(1); memset(ptr + i * 1024 * 1024 * 32, 'b', 1024 * 1024 * 32);//相当于对数据的一个修改 } printf("child over\n"); } else { sleep(35); } free(ptr); exit(0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
编译这段代码,结果如下:

我们可以看到前32秒内存会不断增长到1G,此时父进程正在开辟内存。

终端输出了I Will Fork,表示此时创建了子进程,可以看到内存并没有一下子变为2G,而是以一种缓慢的速度在增长,此时子进程正在修改内存数据。

父子进程都结束了,可以看到内存有两次瞬间降低的过程,此时父子进程都已经结束。
那么我们根据上面的结果,可以得到以下结论:
- malloc申请空间并不是malloc成功后就直接将物理内存空间分配给用户,而是在用户使用的时候才会给用户分配物理内存空间,malloc调用成功只是将虚拟地址空间上的堆区空间分配给用户。所以最开始内存慢慢增长到1G.
- fork方法并不会直接将父进程的数据空间复制给子进程,而是子进程在修改数据空间上的数据时,才会给子进程分配空间。所以在fork之后内存缓慢从1G增长到2G
- 释放空间时,会直接将物理内存空间释放,父子进程,谁用完谁释放。所以出现2次递减
5.1写时拷贝
我们把父进程给子进程拷贝存储空间的方式称为写时拷贝。
写时拷贝是一种可以推迟甚至免除拷贝数据的技术。在父进程创建子进程时,内核此时并不复制整个父进程地址空间给子进程,而是让父进程和子进程共享父进程的地址空间,内核将它们对这块地址空间的权限变为只读的。只有在需要写入修改的时候,内核为修改区域的内存制作一个副本,通常是虚拟存储器系统的一页。从而使父子进程拥有各自的地址空间。
也就是说,新的地址空间只有在需要写入修改的时候才开辟,在此之前,父子进程只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。
三、关于fork的例题
1、下列代码中会有几个A和几个B输出?
# include<stdio.h> # include<stdlib.h> # include<unistd.h> # include<string.h> # include<assert.h> int main() { int i=0; for(;i<2;i++) { pid_t pid=fork(); assert(pid!=-1); if(pid==0) { printf("A\n"); } else { printf("B\n"); } } exit(0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
分析:fork生成子进程1,父子进程均执行fork之后的代码,那么i=0,父进程打印B,子进程1打印A,i++,i=1,父进程创建子进程2,打印B,子进程2打印A,子进程1创建子进程3,打印B,子进程3打印A,i++,循环结束。所以为3个A3个B,具体的,如图所示。
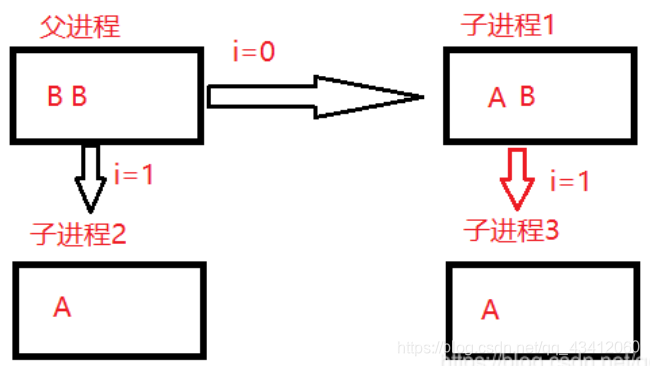
2、在上一题的基础上printf函数去除\n
# include<stdio.h> # include<stdlib.h> # include<unistd.h> # include<string.h> # include<assert.h> int main() { int i=0; for(;i<2;i++) { pid_t pid=fork(); assert(pid!=-1); if(pid==0) { printf("A"); } else { printf("B"); } } exit(0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
分析:关键就是在于父进程在创建子进程的时候会把父进程的缓冲区也给子进程复制一份,所以打印出来是4个A4个B
3、下面这个代码,打印几个A?
# include<stdio.h>
# include<stdlib.h>
# include<unistd.h>
# include<string.h>
# include<assert.h>
int main()
{
fork()||fork();
printf("A\n");
sleep(2);
exit(0);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
分析:||的逻辑是,如果前一个条件为真,那么后面的条件不用判断,如果第一个为假,那么需要判断第二个条件。执行fork(),父进程返回子进程PID,子进程返回0。那么父进程的第一个fork()执行后,返回一个大于0的数,故不必进行下一次判断,打印1个A。而创建的子进程fork()返回0,所以需要判断第二个条件,fork()再创建出另一个子进程,故加上父进程,共3个进程,打印3个A。如图所示:
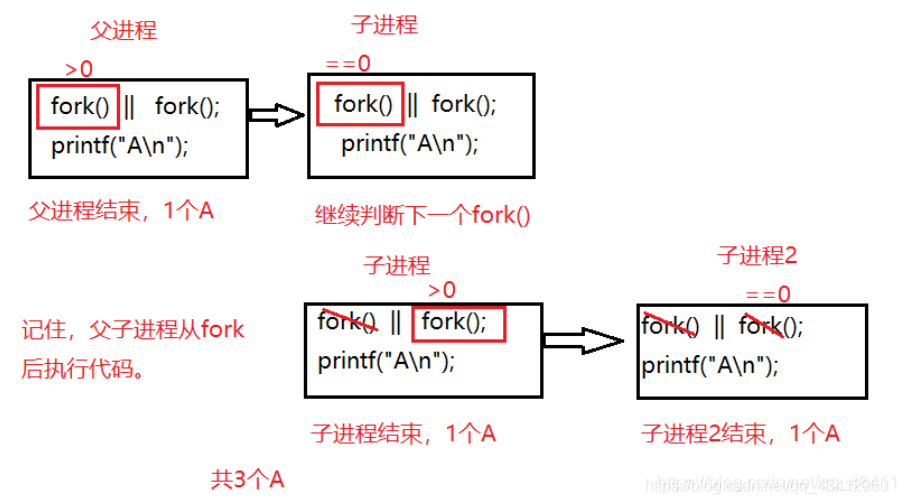
4、下面一段代码,输出结果为什么?
# include<stdio.h>
# include<stdlib.h>
# include<unistd.h>
# include<string.h>
# include<assert.h>
int main()
{
printf("A");
write(1,"B",1);
fork();
exit(0);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
分析:printf为库函数,没有\n,所以先在缓冲区里面。write是系统调用,1代表打印到屏幕,立马打出B,fork创建子进程,父进程有个A,子进程有个A,结束后缓冲区打出AA,所以结果是BAA。

