
- 1鸿蒙应用开发-基础篇_鸿蒙 interface实现
- 2[问题已处理]-kubernetes使用hostpath在单节点上共享文件_0/1 nodes are available: 1 pod has unbound immedia
- 3qrcode将生成的二维码转成img格式_微信小程序qrcode生成二维码转成image
- 4CAS是什么_什么是cas
- 5逆战程序创建纹理失败_头发和毛发: 程序头发纹理生成工具
- 6C#基础语法_对象的保存与读取
- 7MySQL_14_查询优化_查询优化的一般步骤
- 8DevEco Studio智能家居app官网代码不能配网_deveco studio远程模拟器使用内网穿透没有用呢
- 9CCS使用常见问题_ccs6怎么转换为ansi编码
- 10程序猿成长之路之番外篇——矩阵算法
pytorch训练过程中出现错误:Assertion input_val >= zero && input_val <= one failed._assertion `input_val >= zero && input_val <= one`
赞
踩
pytorch训练过程中出现错误:Assertion input_val >= zero && input_val <= one failed.
详细报错信息如下:
在用服务器跑模型计算loss时,出现如下错误:Assertion input_val >= zero && input_val <= one failed.和 RuntimeError: CUDA error: device-side assert triggered。
../aten/src/ATen/native/cuda/Loss.cu:118: operator(): block: [307,0,0], thread: [31,0,0] Assertion `input_val >= zero && input_val <= one` failed. 130it [00:49, 2.60it/s] Traceback (most recent call last): File "/home/liuchuang/OPTICc/main.py", line 233, in <module> main(config) File "/home/liuchuang/OPTICc/main.py", line 129, in main train_DG.run() File "/home/liuchuang/OPTICc/train_DG.py", line 138, in run loss_meter.add(loss.sum().item() + 1e-6) RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1.

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
出现这个报错的原因可能有很多种,刚开始碰到感觉是个比较偏门的错误,很少碰见,而且我的问题和大多数的博客的解决办法也不一样,特此作记录,给出问题的小伙伴一些参考价值。
首先这是我的报错截图:

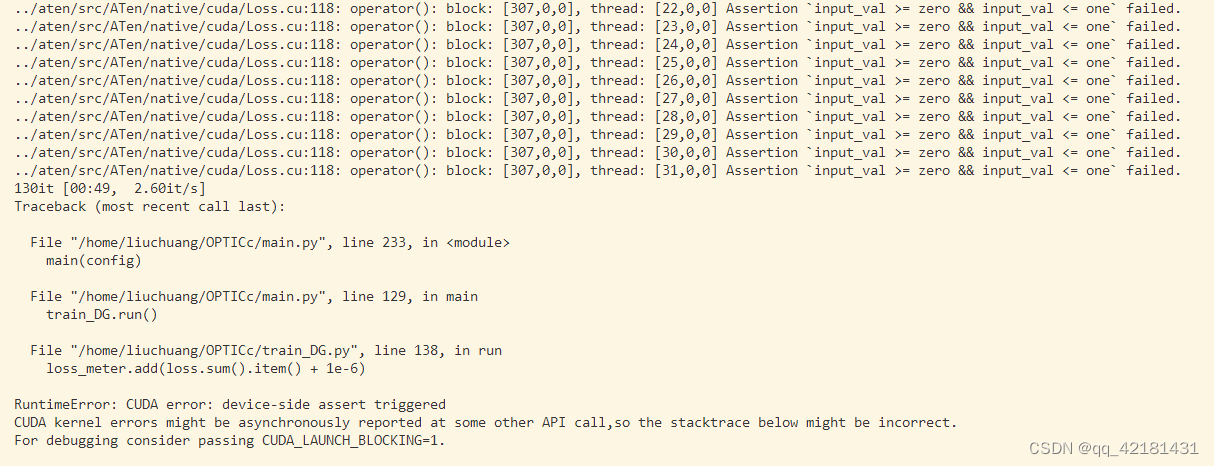
最后错误的提示为:RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
解决办法
1、故障定位
首先定位到出错的位置,我的代码出错的位置为计算损失函数的这一行:
loss = self.seg_cost(pred, y)
self.optimizer.zero_grad()
loss.backward()
# print(loss.sum().item())
**loss_meter.add(loss.sum().item())**
self.optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
中间我打花括号的那一行代码出错:loss_meter.add(loss.sum().item()),这个报错奇怪就在我前面的iteration计算都是正确的,到了这最后一个iteration报错了。因此我将pred和y的shape全部打印出来发现问题了,原来我的最后一个batch只有一个sample,维度为(1,2,256,256),这样在计算的时候就会报错,每一个batch至少大于1个样本,才能计算损失函数。
2、故障解决
通过查阅资料有好几种办法可以解决这个问题。以下列举三种:
我的训练样本总数是1041,每个batch的大小是8,这意味着最后一个batch的大小会是1,这可能会导致一些问题,例如如果你在计算损失函数时需要使用到更多的样本,或者在某些层(例如Batch Normalization)需要更多样本的情况。
有几种可能的解决方案:
- 丢弃最后一个batch:在许多情况下,简单地丢弃最后一个不完整的batch是可以接受的,尤其是当你有大量的训练数据时。
方案:在如下数据加载的代码处添加 drop_last = True.
source_dataloader = DataLoader(dataset=source_dataset,
batch_size=config.batch_size,
shuffle=True,
pin_memory=True,
collate_fn=collate_fn_w_transform,
num_workers=config.num_workers,
drop_last=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 补全最后一个batch:你可以通过复制一些样本来补全最后一个batch。虽然这可能会导致一些小的训练偏差,但如果你的数据集足够大,这个影响应该是可以忽略不计的。
方案:如果你希望在训练时保留最后一个不完整的batch,可以选择填充(padding)来补全这个batch。这种情况下,你需要设定一个固定的填充值或者策略。在PyTorch中,可以使用torch.utils.data.Dataset和torch.nn.utils.rnn.pad_sequence来创建一个可以进行填充操作的数据集。
from torch.nn.utils.rnn import pad_sequence from torch.utils.data import Dataset, DataLoader class MyDataset(Dataset): def __init__(self, data): self.data = data def __len__(self): return len(self.data) def __getitem__(self, index): return self.data[index] def collate_fn(batch): batch = pad_sequence(batch, batch_first=True, padding_value=0) return batch # 假设 data 是你的数据 dataset = MyDataset(data) dataloader = DataLoader(dataset, batch_size=8, collate_fn=collate_fn)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 调整batch size:如果可能,你可以尝试调整你的batch size,使其能够被你的样本总数整除。例如,如果你的样本总数是1041,你可以选择一个能被1041整除的数作为你的batch size,例如1、13、17、23、31、37等。
这是一些可能的解决方案,我是使用第一种方案解决了问题,当然第一种和第三种都非常好实现,第二种我没有试过,感兴趣的朋友可以自行尝试。
完结!撒花!

