
- 1《信息系统项目管理师(第3版)》目录 (复习路线)_系统规划与管理师目录
- 2基于信息增益的ID3决策树介绍。_基于信息增益的决策树
- 3化工和数学类Markdown语法_markdown化学方程式
- 4TypeError: makedirs() got an unexpected keyword argument ‘exist_ok‘_typeerror: makefile() got an unexpected keyword ar
- 5逻辑回归(Logistic Regression)详解
- 6Docker进阶教程 - 2 Docker部署SpringBoot项目_docker jar包在target目录下
- 7hql错误:No data type for node
- 8梅科尔工作室-寇涵冰-鸿蒙笔记4_每调用一次router.pushurl()方法,页面路由栈数量均会加1
- 9conda虚拟环境配置和pycharm添加conda解释器_pycharm conda解释器
- 10HarmonyOS原子化服务_harmonyos的原子化服务有哪些特点
<关键迭代--可信赖的线上对照实验>笔记_关键迭代:可信赖的线上对照实验知识点整理全面
赞
踩
目录
2.制定指标时有用的技巧和考量:(数据分析与指标考量相结合的案例)
3.指标的评估:建立从驱动指标到机构目标指标之间的因果关系方法
3.分析单元和随机化单元不一样case:CTR两种常见的计算方法:
第3章特威曼定律与实验的可信赖度
1.曲解统计结果:解读对照实验的数据时常见的错误
统计功效不足:1个常见的错误是仅仅由于指标不是统计显著的,就假设没有实验效应。而真实的情况很可能是因为实验的统计功效不足以检测到我们看到的效应量,也就是实验没有足够的用户
曲解p值:p值是当假定零假设为真时,得到的结果与观测到的结果相同或更极端的概率°零假设的条件至关重要°
2.置信区间
宽泛地说置信区间可以量化实验效应的不确定程度,置信水平表示置信区间应包含真正的实验效应的频率;p值和置信区间之间存在对偶性,对于对照实验中常用的零差异零假设,实验效应的95%,置信区间不包含零意味着p值<0.05。
3.对内部有效性的威胁
内部有效性是指在没有试图推广到其他人群或时间段情况下的实验结果的正确性
①违背了个体处理稳定性假设:分析对照实验时,通常会应用个体处理稳定性假设,实验单元(例如用户)不会互相干扰,他们的行为受他们自己被分配到的变体影响,但不受其他人的分配信息影响
②幸存者偏差:分析活跃了一段时间(例如两个月)的用户会导致幸存者偏差,比如应该在没有子弹孔的地方增加
装甲,因为轰炸机在那些地方遭到了袭击后再也没有飞回来接受检查.
③意向性分析:在某些实验中,变体存在非随机的损耗或减员,如果仅分析那些参与者,会导致选择性偏差’而且这时候通常会夸大实验效应。
④样本比率不匹配:如果实验设计是1比1的比例(实验组和对照组大小相等)’那么实验的实际用户比例出现偏差可能意味着有某个问题需要进一步调试,可能的原因:
- 浏览器跳转:性能差异\机器人\跳转是不对称的
- 有损的工具化日志记录:
- 残留或延滞效应:新的实验通常会涉及新的代码,这时错误率会比较高;新实验通常会因引起—些意想不到的严重问题而中止或者继续运行并等待快速修复,(这就是为什么要在正式实验前运行A/A实验,并主动重新随机化用户的重要原因)
- 时刻效应:在真实的案例中,用户被适当地随机分为大小相等的对照组和实验组,但电子邮件的打开率(应该大致相同)出现了样本比率不匹配,由于实施起来更容易,实验先将电子邮件发送给对照组用户,然后再发送给实验组用户,这造成对照组在工作时间收到电子邮件,而实验组在下班后才收到;
- 随机化时使用了错误的哈希函数
- 实验影晌触发机制
- 数据管线会受到实验影晌
- 机器人过滤
4.对外部有效性的威胁
外部有效性是指对照实验的结果可以沿不同维度如人群(例如其他国家/地区、其他网站)以及时间(例如2%的收人增长会持续很久还是减少?)推广的程度
- 初始效应:因为旧功能占主导地位,也就是说用户习惯了旧功能的工作方式,引人改动后用户可能需要一些时间来接受新功能;
- 新奇效应:无法持续的效应,引人新功能时尤其是容易被发现的功能,用户最初会被吸引并尝试;如果用户认为该功能无用,则重复使用的次数会变少;开始实验可能看起来效果不错,但是随着时间的推移,实验效应会迅速下降;
5.细分群的差异
2023.08.24
①下钻维度细分群的差异
- 市场或国家/地区
- 设备或平台
- 时刻效应和周内效应(周末的用户可能在许多方面有所不同)
- 用户类型(新用户还是老用户)
- 用户账户特征:奈飞的个人账户或共享账户,爱彼迎的单人旅客或家庭旅客
②细分群方法--机器学习
以使用机器学习和统计方法(例如决策树(AtheyandImbens2016)和随机森林(WagerandAthey2018))来确定有趣的细分群或搜索交互作用。
③总体和局部表现不一致的情况
OEC在两个细分群都增加,但总体OEC却下降,和辛普森悸论不同,这是由于用户从—个细分群迁移到另一个细分群所致;当用户从1个细分群迁移到另1个细分群时,在细分群级别上解释指标的变化可能会有迷惑性,因此应该使用非细分群的指标(总体)的实验效应
2023.08.25
1.分流节点的选择
变体分配可能会发生在多个地方:完全在产品代码之外使用流量分割(例如流量前门)、客户端(例如,移动应用程序)或服务器端,需要考虑如下问题:
①在流程中的什么节点,你获得了进行变体分配所需的全部信息
②你允许实验分配仅在流程中的1个点还是多个点:如果你有多个分配点则需要保证正交性,以确保较早发生的实验分配不会引起流程中较晚发生的实验分配偏差。
2.并行实验
方法是拥有多个实验层,其中每个层都类似于单层方法的操作,为了确保跨层之间实验的正交性在用户分配分桶时添加层ID,即将同时在所有实验中,对于每个运行的实验将用户分配到1个变体(对照组或其中一个实验组)。每个实验都与唯—的层ID相关联,因此所有实验都相互正交。
第6章机构指标
1.机构指标时常用的分类方法
①目标指标:也被称为成功指标或北极星指标,它体现了机构终极关心的是什么,且这些答案通常会跟使命宣言紧密相连;指标在短期内可能不易改变,因为每个改进对它的作用可能都非常小,或是因为这些作用需要很长—段时间才会体现出来。
②驱动指标:也被称为略标指标、代理指标、间接或预测指标,一般比目标指标更短期,变化更快也更灵敏。驱动指标反映了1个思维上的因果模型,它是关于如何做可以让机构更成功,也就是对成功的驱动力的假设
解释指标因果模型框架:
- HEART框架heart(Happiness幸福、Engagement参与、Adoption采纳、Retention留存和TaskSuccess任务成功)
- PIRATE框架pirate(AARRR : Acquisition获取、Activation激活、Retention留存、Referral传播以及Revenue营收)
- 常用的用户漏斗方法
③护栏指标:两种类型:保护业务的指标,以及评估实验结果可信赖度和内部有效性的指标;’而护栏指标的重要性在于可以保证我们在通往成功的路上有正确的权衡取舍,不会违背重要的限制,
例如密码管理公司,它可能需要在安全性(没有被人侵或信息泄露)易用性和可用度(如用户是否经常被拒绝登录)之间做权衡取舍,这里安全性可以作为目标指标,而易用性和可用度可以作为护栏指标

④存量和参与度指标:存量指标衡量静态的储量,如脸书的总用户(账户)数量或总关系连接数。参与度指标则衡量用户从自身或其他用户的动作中得到的价值,如一个会话或一个页面测览
⑤业务和运营指标:业务指标,如人均营收或日活用户数,追踪业务的健康程度而运营指标,如每秒搜索量,则衡量运营是否出现了问题。
⑥数据质量指标:保证实验所需的内部有效性和实验的可信赖度
⑦诊断或调试指标:它们可以提供额外的颗粒度或是一些日常追踪会显得太过细节、但针对特定情境研究时就很有用的其他信息
团队建指标考虑因素:一些则侧重于留存、性能或延迟每个团队都必须明确叙述自己的目标以及关于该指标是如何与公司总体指标挂钩的假设
2.制定指标时有用的技巧和考量:(数据分析与指标考量相结合的案例)
通过小规模方法得到的假设去形成想法,然后用大型数据分析来验证这些想法,从而做出精确的定义
例如:指标用户幸福度或用户任务成功度,也许只能通过用户调研来直接衡量,这并非一个可以规模化的方法。但我们可以通过做调研或用户体验调研来观察哪些行为跟成功和幸福感相关联,你可以用线上日志做大型数据分析来探索这些行动的模式,以决定这些指标是否可作为高阶指标。
一个实际的例子是跳出率,也就是那些只在网站上停留很短时间的用户比例,我们可能注意到"短时间的停留与不满意有所关联"。把这个观测跟数据分析结合起来就可以帮助确定精确定义1个指标所需的阈值(阈值应该是1个页面测览? 20秒?)
3.指标的评估:建立从驱动指标到机构目标指标之间的因果关系方法
测量框架最初是由对关键指标以及它们的因果假设(假定)所构成的,这些假设之后会被真实数据检测’并可以被验证"推翻或修改”这个特性是最难被满足的,因为我们通常并不知道所隐含的因果模型,而只有—个假设的思维上的因果模型而已,可用的方法:
①使用其他数据源,如调研、焦点小组或用户体验调研来检查它们是否都指向同—个方向
②分析观测所得数据:从观测数据中建立因果关系是很难的,但—个仔细进行的观测研究有助于否定错误的假设。
③检查其他公司是否做过类似的验证:例如数个公司曾经分享过研究展示了网站速度会影响营收和用户参与度
④用历史实验集合作为黄金样例,来评估新的指标:非常重要的一点是"这些实验必须是被深人理解并且可信赖的,我们可以用这些历史实验来检查灵敏度和因果统一
第10章补充技法20230829
收集用户数据的补充技法
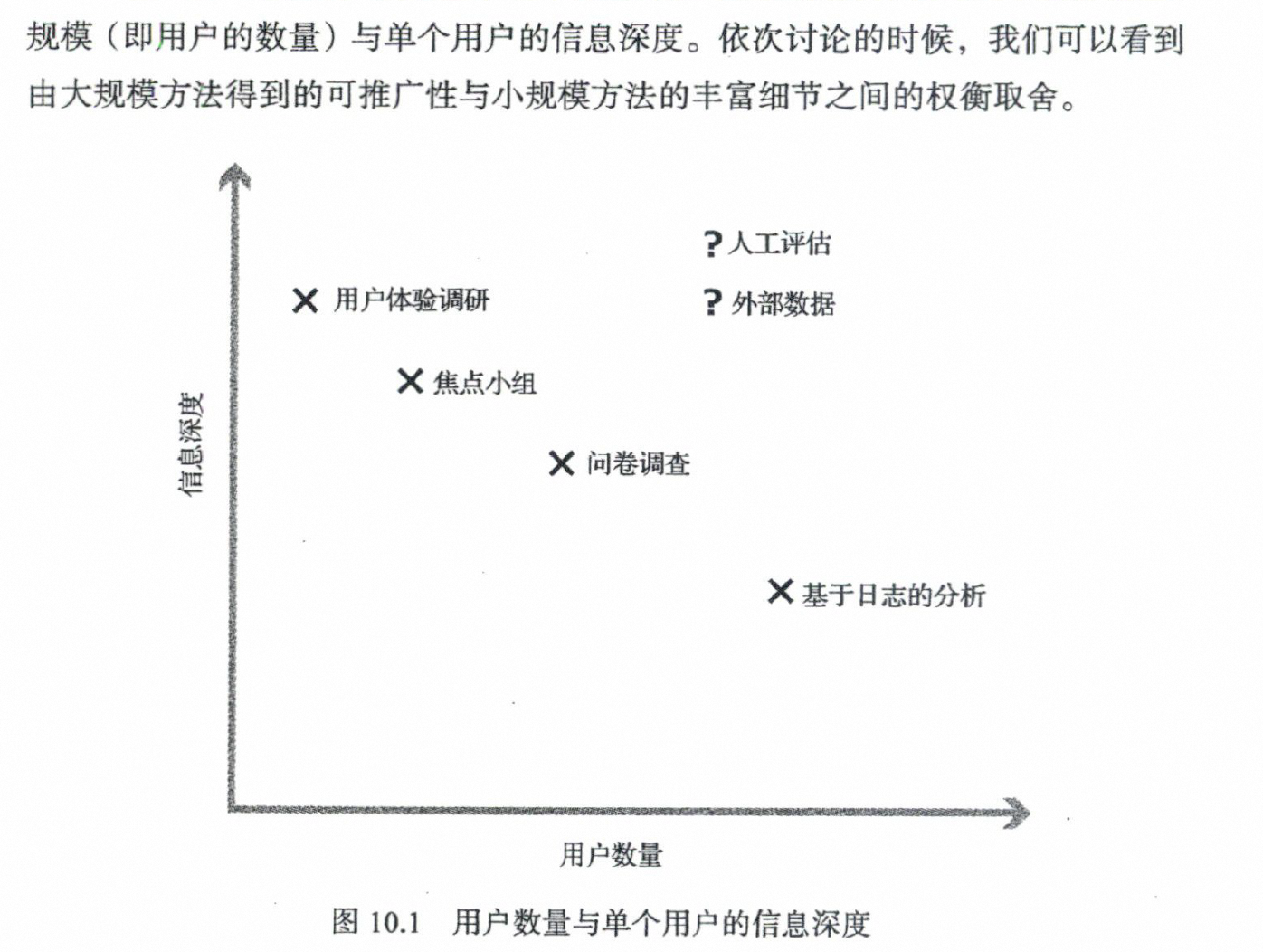
①基于日志分析:
基于数据探索生成A/B实验的创意:
比如:"可以通过检查购买漏斗中每—步的转化率来识别大的流失点;分析会话化的数据能揭示某个特定的行为序列花了比预期更长的时间";这种发现路径能引出改进产品的创意比如引进新的功能或者改进用户界面的设计
建立直觉:你可以通过回答如下问题来定义指标并建立直觉:
人均会话数或点击率是怎样分布的?
重要的细分群间有何差别(如按国家或平台细分)(见第3章)?
这些分布随着时间如何变化?
用户数量随着时间如何增长?
②人工评估:指的是—个公司雇佣人工判断者(或者叫作评估者)来完成某些任务。
局限性:评估者—般来说不是你的最终用户,评估者执行分配给他们的任务(通常批量进行)然而你的产品是你的最终用户在生活中自然而然接触到的。另外评估者可能不了解最终用户的当地情境。
我们最好把人工评估提供的校准过的标签数据看作是对从真实用户收集的数据的补充,所有这些技法都有不同的权衡取舍。
③用户体验调研★
深人研究少数用户的田野调查或实验室研究。调研者通常在实地或者实验室环境下观察用户执行调研者感兴趣的任务以及回答问题。这—类研究是深入的高强度的,通常不超过10个用户可以用于生成创意发现问题以及通过直接的观察和及时的问题获得洞察
这—类田野调查和实验室研究可能包括:
- 特殊的仪器用以收集数据,比如像眼动追踪这种不能从日志记录中收集的数据。(跟客sample)
- 日记研究意为用户按时间顺序自我记录他们的行为可以用于收集与线上日志记录相似的数据,同时可以扩展数据的维度,得到普通日志收集不到的数据,比如用户意图或者线下活动。(用户24小时生活轨迹)
③焦点小组
焦点小组指的是与招募的用户或潜在用户进行有引导的小组讨论
焦点小组相比于用户体验调研更容易规模化,也能处理相似程度的模糊的、开放性的问题用以指引产品开发和假设
焦点小组对在处于设计的早期阶段的、尚未成型的、在未来可以实验的假设上得到反馈是有用的,也可以用于理解通常针对品牌或营销变动的内在的情绪反应,换句话说它的目标是收集无法通过工具化日志记录的信息,获得对未完全成型的变动的反馈以推动设计的进行
④调查问卷
与用户体验调研和焦点小组相比,问卷调查可以接触到更多的用户,但它的主要用途还是回答工具化数据中无法回答的问题,比如用户离线时的行为或者用户的意见或者信任和满意程度。问题可能包括用户做购买的决定时会考虑哪些额外信息,包括线下的行为(比如和朋友交流)或者询问用户购买后三个月的满意度
⑤外部数据
需要注意的是因为取样和分析的确切方法不受控制,外部数据中的绝对数字可能不总是有用,但是趋势、相关性以及生成并验证指标都是好的使用场景。
外部数据来源:提供站点级别详细数据/提供用户级别详细数据/开展问卷调查的公司/发表的学术论文/提供经验教训的公司和网站
所有这些技法都有:
- 你需要考虑可以从多大的人群中收集数据,这会影响结果的可推广性;换句话说是否可以确立外部有效性;用户数量通常和获取信息的详细程度是矛盾的,例如日志通常能大规模记录用户行为,但不能像用户体验调研中那样可以收集用户某种行为的原因。
- 在产品开发周期中所处的阶段也是一个重要的考虑因素,早期有太多想法需要测试时,焦点小组和用户体验调研等更偏定性的方法可能更合适,随着项目进展拥有定量数据时,观察性研究和实验变得更有意义
20230831
第14章选择随机化单元
用户体验的一致性:(选择随机化单元时要考虑的1个维度是颗粒度)
另一个例子是引人新功能的实验,如果随机化是在页面级别或会话级别的,则该功能可能会时而显示时而消失°这些潜在的糟糕且不一致的用户体验会影响关键指标°
用户越会注意到的实验改动,随机化的过程使用更粗糙的颗粒度以确保用户体验的一致性就越重要°
随机化单元与分析单元颗粒度:
- 选择与关注的指标的分析单元相同(或更粗糙的颗粒度)的随机化单元,如果随机化单元是用户’且指标分析单元也是用户,例如人均会话数、人均点击量和人均测览量则分析是直观的
- 考虑限制任何单个用户可能对更精细的颗粒度的指标的影响,或切换到基于用户的指标(例如人均点击率)这两者都限制任何单个用户对最终结果的影响
- 随机化的颗粒度不能比指标更精细:
- 当指标是在用户级别(例如人均会话数或人均营收)计算的,而随机化单元更精细(如页面级别)时,用户可能混合体验到多个实验变体,因此用户级别的指标是没有意义的
用户级别的随机化则可以考虑以下几种选择:
- 用户可以在各种设备和平台使用的登录用户ID或登录名。已登录ID不仅在平台间特别稳定,而且在时间纵向上也很稳定
- 匿名用户ID如cookie。大部分网站在用户访问时,会录人—个含标识符(通常是随机的)的cookje°对于本机应用程序的移动设备’操作系统通常提供cookie’例如苹果系统的jdFA或idFV或安卓系统的广告ID,这些ID在平台间是不—致的,因此通过桌面浏览器和移动网页访问的同—用户将被视为两个不同的ID。
- 用户可以通过浏览器级别的控件或设备操作系统的控件来控制这些cookie,这意味着cookie的纵向持久性通常不如已登录的用户ID
- 设备ID是与特定设备绑定的ID,因为它们是不可变的,所以这些ID被认为是可识别的设备ID,不具有已登录ID所具有的跨设备或跨平台的—致性,但通常在时间纵向上是稳定的
第15章实验放量:权衡速度\质量与风险

第1阶段主要是为了降低风险,因此SQR框架专注于权衡速度和风险
第2阶段主要是为了精准测量,重点是权衡速度和质量
最后两个阶段不是必需的’它们考虑到了其他运营方面的问题(第三阶段)和长期影响或重复实验(第四阶段)
第16章规模化实验分析
数据清洗:删除不太可能是真实用户的会话,关于会话的有用的启发法包括:会话活动太多或太少,事件间隔时间太短,页面上的点击次数过多,以及以违反物理定律的方式与网站互动等°
20230908
第17章线上对照实验中的统计学知识
1.双样本t检验和P值
双样本t检验:衡量相对于方差而言的两个分组均值的差异,差异的显著性是通过p值描述的。越小的p值代表有越强的证据证明实验组不同于对照组;
p值表示零假设为真时,基于观测到的数据,两组指标差异为或更极端的概率

2.—/二型错误和统计功效
第—型错误"弃真"是指得出实验组和对照组之间有统计显著的差异的结论,但真实情况是没有差别的
第二型错误"取伪"是指得出实验组和对照组之间没有统计显著的差异的结论,但真实情况是有差别的
统计功效:是检测到实验组和对照组差异的概率

—个实验有足够的统计功效能检测到10%的差异并不意味着有足够的统计功效能检测到1%的差异,通过游戏“找不同’来比喻统计功效的意思;检测更大差异的统计功效更高
3.实验结果的偏差:
指估计值和真实值之间出现了系统性差异,造成偏差的原因,包括平台的漏洞、实验设计的缺陷或者样本不具备代表性
4.多重检验
如果有1个指标出乎意料的统计显著,可以通过下面两步经验法则进行分析:
①将所有的指标分成3组:
·第一类指标:我们期待这些指标直接受到实验影响。
·第二类指标:这些指标可能会受到实验影响(比如通过侵蚀)°
·第三类指标:这些指标不太可能受到实验影响。
②对每组指标进行不同级别显著性水平的测试(比如0.05、001和0.001),这些经验法则基于1个有趣的贝叶斯解释:实验前我们有多么相信零假设(H0)是真实的,信心越坚定所需的显著性水平越低;
5.费舍尔统合分析:提高统计功效并降低假阳率

第18章方差估计和提高灵敏度:陷阱及解决方法
1.降低方差的方法
①比率指标:当分析单元和实验单元不同时,可以把比率指标写成两个用户平均指标的比率
②去除离群值:估计方差时去除离群值是非常关键的,1个实用且有效的方法是直接对观测指标添加—个合理的阑值°例如’正常人是不会搜索同一个词500多次或者每天访问页面1000多次的
2.提高灵敏度
- 创建1个方差更小并能捕捉相同信息的评估指标
- 通过添加阈值、二元化和对数转化来改变指标
- 通过分层采样、控制变量法或者CUPED:
- 对于分层采样法,我们对采样范围进行分层然后在每层内分别进行采样,最后把每层内采样的结果合并得到总体的估计;总体的估计方差通常比不分层获得的估计方差要小,常见的分层包括平台(桌面系统和移动系统)、浏览器类别(Chrome〈火狐或者Edge)和星期几等
第19章A/A测试(0911)
如果每件事都是在控制(control)下,那么你的行动可能不够快
(桌面系统和移动系统)
1.A/A测试概念
A/A测试的想法很简单:像A/B测试—样把用户分成两组,但B和A是一样的(因此命名为A/A测试),如果系统运作正确,那么对于大约5%的重复测试1个给定的指标会统计显著并且p值小于0.05。通过t检验计算p值,基于重复测试得到的p值近似于均匀分布°
2.A/A测试目的
A/A测试和A/B测试是—样的,但实验组用户的体验和对照组的是一致的。
A/A测试可用于多种目的:
评估指标的波动性:我们可以通过分析A/A测试的数据来确定指标方差是如何随着更多用户进人实验而变化的,以及观测平均值的方差下降是否符合预期
确保实验组和对照组的用户之间没有偏差:特别是当我们再次使用之前实验的人群时,A/A测试在鉴别偏差时是非常有效的,尤其是平台层面的偏差°比如:必应通过持续使用A/A测试找出延滞效应(或者残余效应),因为之前的实验可能会在之后的实验中对同—群用户造成影响
3.分析单元和随机化单元不一样case:CTR两种常见的计算方法:
CTR两种常见的计算方法:
第一种是总点击数除以总页面测览量
第二种是先计算每个用户的CTR然后平均所有用户的CTR。
如果随机化是在用户层面的,那么第1种方法使用了1个与随机化单元不同的分析单元。这种情况会违背独立性假设,并且让方差计算变得复杂。


0912
第20章以触发来提高实验灵敏度(trigger)
1.触发实例
- 有意识的局部曝光:假设改动只针对部分用户,例如仅针对美国的用户,那么应该只分析美国的用户
- 条件曝光:如果改动只针对访问了网站的某部分(例如结账)或使用某一功能(例如在Excel中绘制图形)的用户,则仅需要分析这些用户。在这些示例中用户一旦接触到改动,就会被触发进人实验而产生差异

- 覆盖范围的扩大:例如如果用户的购物车商品金额超过35美元,则可享受免运费的优惠,而我们正在测试将免运费门槛降低为25美元,对照组:35以上免邮用户群体,实验组:35以上免邮和25-35免邮用户群体
- 对照组代表了对一些免运费的用户,而实验组则将覆盖范围扩大到更广泛的用户群体。你不需要触发其他用户(如示例2),但是也不需要触发同时满足实验组和对照组条件的用户,因为他们都已经享受免运费的优惠,只需要触发在实验组但不在对照组的用户
- 覆盖范围的改变:若实验组为购物车中商品金额超过25美元并且在实验开始前60天内没有退货的用户提供免运费的优惠,实验组改变了覆盖范围,如果交集中的用户所见完全相同,那么只触发剩下的用户
2.最佳的和保守的触发
最佳触发:对比两个变体时,最佳触发条件是仅触发两个变体之间存在某些差异的用户(例如用户所在的变体与另—个变体的虚拟事实之间存在差异)
保守触发:在实践中非最佳的但保守的触发,有时会更容易,例如包含比最佳触发更多的用户,这不会使分析失效,但同时可以降低统计功效。
保守触发实例:
①多实验组。变体之间的任何差异都会触发用户进人分析,你无须记录每个变体的输出,只需记录1个布尔值以表明它们有所不同。可能对于某些用户"对照组”和“实验组1”的行为相同,但“实验组2”的行为有所不同,因此仅比较“对照组"和“实验组1"时也请包括实验效应为零的用户。
②事后分析。假设实验已经开始而虚拟事实日志记录存在问题,结账期间函数使用的推荐模型的虚拟事实也许因此没能被准确记录,可以使用类似“用户启动结账流程”的触发条件。尽管与结账时推荐模型不同的用户相比,更多用户被触发,但仍可能剔除90%因从未启动结账而实验效应为零的用户。
第21章样本比率不匹配与其他可信度相关的护栏指标
1.SRM的概念:样本比率不匹配
样本比率不匹配指标检测的是两个实验变体(通常是一个实验组和—个对照组)的用户量(也可以是其他单元)的比率;如果实验设计要求曝光特定的用户比率(例如1:1)到实验的两个变体,那么实际得到的比率应该和设计的比率匹配
2.调试SRM的方法
①验证在随机化时机点或触发时机点的上游没有区别:例如:如果改动的是结账功能而且从结账的时间点开始分析用户,那么要确保两个实验组在这个时间点的上游没有区别。如果比较结账时降价50%和买1赠1的策略,那么不能在首页提到其中任何—个策略,如果提到了,那么必须以首页为起点开始分析用户;
②验证实验变体的分配设置是正确的,数据管线源头的用户随机化是否合理?虽然大多数实验分流系统都是通过基于用户ID的哈希值的简单随机化机制实现的,但是当需要支持并行实验和孤立群组时,不同的实验要确保不能曝光给相同的用户,分流就变得复杂
③顺着数据处理管线排查是否有任何环节引发SRM。例如, SRM的—个很常见的来源是机器人过滤,一般使用启发式方法来剔除机器人,因为机器人往往会增加噪声并且降低分析的灵敏度
④去除起始阶段.两个实验变体是否有可能没有同时开始?对于一些系统,多个实验组会共用1个对照组。较晚开启实验组会引发很多问题,即使分析时间段的开始点设置在实验组开始之后也是如此,例如缓存需要一些时间才发挥效力,手机应用程序需要一些时间才能发推送,手机可能处于离线状态而造成延迟°
⑤查看用户细分群组的样本比率
- 分别查看每1天;是否某1天发生了异常的事件?例如’是否有人某天放量了实验组的百分比?或者另—个实验开始并且‘窃取”了流量?
- 是否有—个浏览器的群组明显不同,像情景2提到的那样?
- 新用户和老用户是否比率不同?
⑥查看与其他实验的交集:实验组和对照组与其他实验的变体之间应该有类似的交集百分比。
3.其他与可信度相关的护栏指标
除了SRM一些其他指标可以表明实验哪些地方出错了,有时候这些是在深人调查后发现的和软件漏洞相关的指标:cookie写人速率(实验变体写人永久(非会话)cookie的速率);快速搜索词条(同1个用户1秒之内搜索的两个及以上的搜索词)
第21章实验变体之间的泄露和干扰
1.干扰概念
SUTVA个体处理稳定性假设:Rubin因果模型的—个关键假设是个体处理稳定性假设(Stable Unit TreatmentValueAssumption’SUTVA)。SUTVA假定实验单元的行为不受其他单元的变体分配的影响
干扰:如果SUTVA不成立那么基于此的分析可能导致不正确的结论,我们定义干扰(interference)为违反SUTVA的情况,有时也会叫作实验变体之间的溢出或泄露
2.干扰的两种方式:
这两种方式是类似的,因为都存在某种连接实验组和对照组的媒介,使得两组实验变体可以交互。
直接关联:如果两个实验单元是社交网络的朋友或者它们同时访问了同—个物理地点,那么它们可以是直接关联的
比如:对于像脸书或领英这样的社交网络,用户行为可能会被他们的社交邻居干扰;作为通信工具Skype的每通电话至少有两方参与,这些通话可以打给实验组或者对照组的用户,结果是对照组的用户使用Skype打电话的频率也增加了,从而可能低估实验组和对照组之间的差别。
间接关联:是指由于存在—些隐形变量或共享资源而形成的关联,例如实验组和对照组的实验单元共享同个营销活动的预算。间接关联的例子如下:(很多知识点)
①广告活动:让我们考虑这样—个实验,不同组的用户将看到同样广告的不同排序,如果实验组的排序促使用户点击更多广告,那么实验组会更快地使用完广告预算。因为1个给定的广告活动的预算是实验组和对照组共享的,这会导致对照组能使用的预算变少。因此,实验组和对照组的差异被高估了.
②关联模型训练:关联模型通常严重依赖于用户的互动数据去学习什么是相关的以及什么是不相关的,考虑这样一个实验:实验组的关联模型可以更好地预测用户喜欢点击什么。如果使用从所有用户那里收集到的数据训练实验组和对照组的模型这个实验运行的时间越长,实验组产生的“好的"点击也使对照组受益越多;
③CPU:当用户在网站上做出某种行为时,比如往购物车里添加了1个商品或点击了1个搜索结果’这种行为常常会向网站服务器发起一个请求。简单地说,这个请求被服务器处理后返还信息给用户°对于A/B测试,实验组和对照组的请求往往通过同—批服务器处理。
实验组的漏洞异常地占用了服务器的CPU和内存’导致实验组和对照组的请求都需要花费更长的时间处理。如果用通常的方法对比实验组和对照组’那么我们会低估这个延迟造成的负面实验效应°
④比用户颗粒度更精细的实验单元:如果实验改动有较强的学习效应,使用诸如页面测览这样的比用户颗粒度更精细的实验单元,则可能引起同属于同—个用户的实验单元之间的泄露°这个例子的“用户,"是那个潜在的关联
假设1个实验改动大幅度地改进了延迟,而我们是按照页面访问随机分流的’那么同1个用户将时而在实验组时而在对照组测览页面,更快的页面加载用时常常带来更多的点击和更多的营收°但是, 由于用户有着混合的体验,他们在快速加载的页面的表现可能会受慢速加载的页面的表现所影响’反之亦然°如同之前的例子’这里的实验效应也会被低估
3.解决干扰带来偏差的方案
3.1经验验法则:行为的生态价值
不是所有的用户行为都会从实验组向对照组产生溢出效应。我们可以界定一些可能会产生溢出的行为’只有当这些行为被实验影响时’才需要关注干扰这个问题.
比如一个来自用户A的消息多大程度可以转化成A和A的社交邻居们的访问会话?一种建立起这个经验法则的方法是利用历史上具有下游影响的实验,将这个影响通过工具变量的方法外推为行为X/Y/Z的下游影响
3.2隔离
你可以通过定位媒介并把每1个实验变体隔离开来的方法移除潜在的干扰,—些实践中可用的隔离方法:
①划分共享资源:如果共享资源会造成干扰’那么将资源划分给实验组和对照组是显而易见的第_选择°例如’可以根据实验变体的流量划分广告预算,对1个占20%流量的变体,只允许使用20%的预算
②基于地理位置的随机化:干扰会产生是因为两个实验单元在地理位置离得很近,你可以在地区级别上随机化,进而隔离实验组和对照组的干扰.需要注意地域级别上随机化的样本量会受限于可供随机化的地域单元数量
③基于时间的随机化。可以利用时间制造隔离,在任意时间t可以抛1枚硬币决定给所有用户实施实验组策略,还是对照组策略
④网络群组随机化。类似于基于地理位置的随机,对于社交网络,可以根据结点之间相互干扰的可能性定义哪些用户是相近的,从而建立“群组",我们把每一个群组作为1个超级单元,然后把它们独立随机分配到实验组和对照组
⑤以网络焦点为中心的随机化:以焦点为中心的随机化可以解决类似的社交网络干扰问题且局限性更少。这种方法创建的每个群组有1个“焦点"(ego,1个焦点个体)和它的“相邻点"(alters它直接关联的个体),通过这样的方式你可以达到更好的隔离和更小的方差
3.3级别分析
一些溢出是通过两个用户之间的定义明确的交互发生的。这些交互(边)很容易定位,通过对比不同类型的边级别发生的交互(例如消息`点赞)’可以帮助理解重要的网络效应
第22章测量实验的长期效应
1.长期效应概念
对于本书讨论的大多数情况,我们建议运行实验一到两周。在如此短的时间内测得的实验效应称为短期效应;对于大多数实验,我们只需要了解这种短期效应,因为它是稳定的,并且可以推广到我们在乎的长期效应
长期效应被定义为实验的渐近效应,从理论上讲,它可以持续数年°实际上通常将长期考虑为3个月以上,或者基于曝光次数(例如’对于使用新功能 至少10次的用户的实验效应
2.短期效应利长期效应可能不同的原因
①用户的习得效应。随着用户学习并适应变化’他们的行为也会发生变化°
②网络效应。用户行为往往会受到其网络中其他人的影响,尽管功能通过其网络传播可能需要—段时间才能完全发挥作用
③延迟的体验和评估:用户可能会需要一段时间来体验到整个实验改动,诸如用户留存之类的重要指标可能会受到延迟的用户线下体验的影响
④生态系统的变化:生态系统中的许多事物都会发生变化,并可能影响用户对实验的反应,比如启动其他新功能\季节性\竞争格局\政府政策\软件性能下降\概念漂移(随着分布的变化,在未更新的数据上训练的机器学习模型的性能可能会随时间下降°)
3.测量长期效应的方法(长期运行实验的替代方法)
①群组分析:
可以在实验开始之前构建稳定的用户群,并且仅分析对该用户群的短期效应和长期效应;一种方法是根据稳定的ID(例如已登录用户的ID)选择同类群组,此方法可有效解决稀释和幸存者偏差,特别是在能够以稳定的方式跟踪和测量同类群组时
②后期分析
情况1:你可以在运行了一段时间(时间T)后关闭实验,然后在时间T和T+1期间测量实验用户和对照用户之间的差异;
情况2:如果由于用户体验问题而无法关闭实验组,你仍然可以通过将实验组发布给所有用户来应用此方法,
该方法的关键是实验组和对照组的用户在测量期间的产品体验完全相同,但是两组之间的区别在于对于情况
1实验组经历了对照组没有经历的产品功能;对于情况2实验组经历这些功能的时间比对照组更长
③时间交错式实验
要确定测量的时间’可以在开始时间错开的情况下运行同实验的两个版本。1个版本(Ib)在时间′T0开始’而另1个版本(T1)在时间t=1开始,在任何给定时间′t>1可以测量实验两个版本之间的差异。
④留出和反转实验
留出实验:实验结果出来后’只将新功能发布给90%的用户’剩下的10%的用户留在原来的对照组数周或数月
反转实验:是将实验的新功能发布给100%的用户后数周(或数月)’将10%的用户重新放回对照组°这种方法的好
处是每个人都已经接受了一段时间的实验组变体的体验
⭐名词解释:
辛普森悖论:如果—个实验经历了放量,即两个或两个以上周期中的变体分配到了不同的百分比,那么将结果结合在—起可能会错误地估计实验效应的方向,也就是说,实验组的结果可能会在第一阶段和第二阶段好于对照组,但把两个阶段合并时实验组总体比对照组会更差,这种现象被称为辛普森悖论
特威曼定律: 任何看起来有趣的统计数据几乎肯定是错误的
虚拟事实:即如果没有改动的话本来要发生的事情,例如,对于实验组用户我们可能希望记录如果他们在对照组将会返回的搜索结果
统合分析:从实验中进行数据挖掘对你来说有什么用呢?这就是我们说的统合分析
变体分配:是将用户前后一致地分配给—个特定的实验变体的过程
SOR(Speed ,Quality and Risk)放量框架:如何在控制风险和提高决策质量的同时快速迭代,换句话说我们如何权衡速度、质量和风险
PLT(PageLoadTime):测量页面加载用时
MPR(Maximum Power Ramp MPR)按最大统计功效放来运行该实验。
SRM样本比率不匹配(Sample Ratjo Mismatch)
SUTVA个体处理稳定性假设(Stable Unit Treatment Value Assumption SUTVA)。
⭐亮点
分析报告:查看实验数据之前,还必须彻底测试和检查所有数据处理和计算,以确保这些处理是可信赖的
用户参与度指标:如活跃天数、人均会话数、人均点击量
获取用户数据补充方法:用户数量与单个用户信息深度的权衡取舍

