
热门标签
热门文章
- 1Elasticsearch - Docker安装Elasticsearch8.12.2
- 2Flutter入门之Row、Column、Container布局_flutter container和row
- 3如何修改YOLOV8?(从这8方面入手帮你提升精度)_yolov8改进
- 476. 最小覆盖子串 滑动窗口
- 5【运维】MacOS Wifi热点设置
- 6Java导出Excel里包含图片(包括GIF)_java excel导出图片
- 7解决将IDEA中的项目上传到Gitee平台时报错:Failed to connect to 127.0.0.1 port XXXX: Connection refused_idea failed to connect to 127.0.0.1 port 15732 aft
- 8最小二乘法(LSM)入门详解(原理及公式推导),MATLAB实现及应用_最小二乘法原理和公式
- 9Android Studio 自定义Gradle Plugin_android studio process release agcpligin
- 10LlamaIndex:轻松构建索引查询本地文档的神器_spacytextsplitter
当前位置: article > 正文
热力图的使用与理解
作者:小蓝xlanll | 2024-03-22 07:15:35
赞
踩
热力图
热力图(Heatmap)是一种数据可视化技术,根据需要用热力图显示的矩阵,可以用来显示区域内数据的相对密集程度或分布情况。它通常通过使用色彩映射来表示数据的密度或值大小。
在热力图中,每个数据点或区域都被赋予一个颜色值,该颜色值反映了该位置上的数据密集程度或数值大小。一般而言,较高的数值或密集程度会使用较暖的颜色表示(如红色),而较低的数值或密集程度会使用较冷的颜色表示(如蓝色)。其他颜色,如黄色和绿色,则表示中间程度的数值或密集程度。
一、显示混淆矩阵(Confusion Matrix)
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第一行第二列的2表示有2个实际归属为第一类的实例被错误预测为第二类。

代码实现:
- import numpy as np
- import seaborn as sns
- aa = np.array([[43,2,0],[5,45,1],[2,3,49]])
- ax = sns.heatmap(aa, annot=True, cmap='Blues')
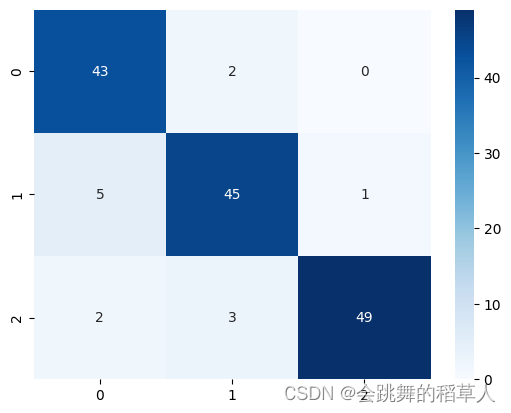
此时矩阵为混淆矩阵,由于横轴为预测样本,对角线深度越大数据越多,预测结果也就越精确。
二、相关系数矩阵(Correlation Matrix)
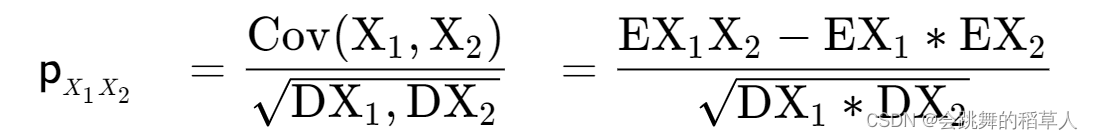
公式中,ρ 为皮尔逊相关系数,Cov表示协方差,E表示数学期望/均值
值得注意的是,该相关系数只能度量出变量之间的线性相关关系;也就是说,相关系数越高,则变量间的线性相关程度越高。对于相关系数小的两个变量,只能说明变量间的线性相关程度弱,但不能说明变量之间不存在其它的相关关系,如曲线关系等。
代码实现:
- from sklearn.datasets import load_iris
- data = load_iris()
- iris_target = data.target
- iris_features = pd.DataFrame(data=data.data, columns=data.feature_names)
- iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改
- iris_all['target'] = iris_target
- corr = iris_all.corr()
- ax = plt.subplots(figsize=(10, 8))#调整画布大小
- ax = sns.heatmap(corr, annot=True, cmap='Blues')#画热力图 annot=True 表示显示系数
- # 设置刻度字体大小
- plt.xticks(fontsize=10)
- plt.yticks(fontsize=10)
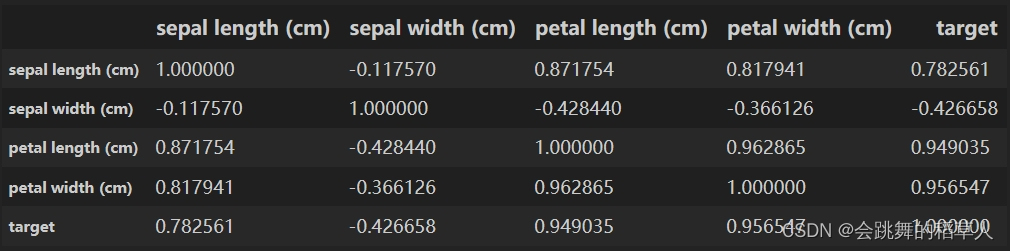
corr具体内容如下:
用热力图显示:
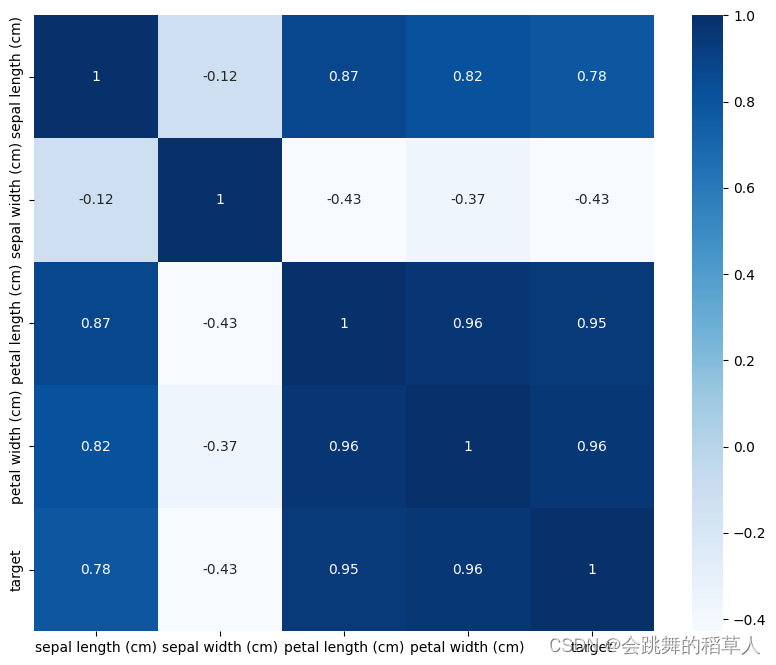
由图可知,target与pw,pl正相关性较强。
案例:
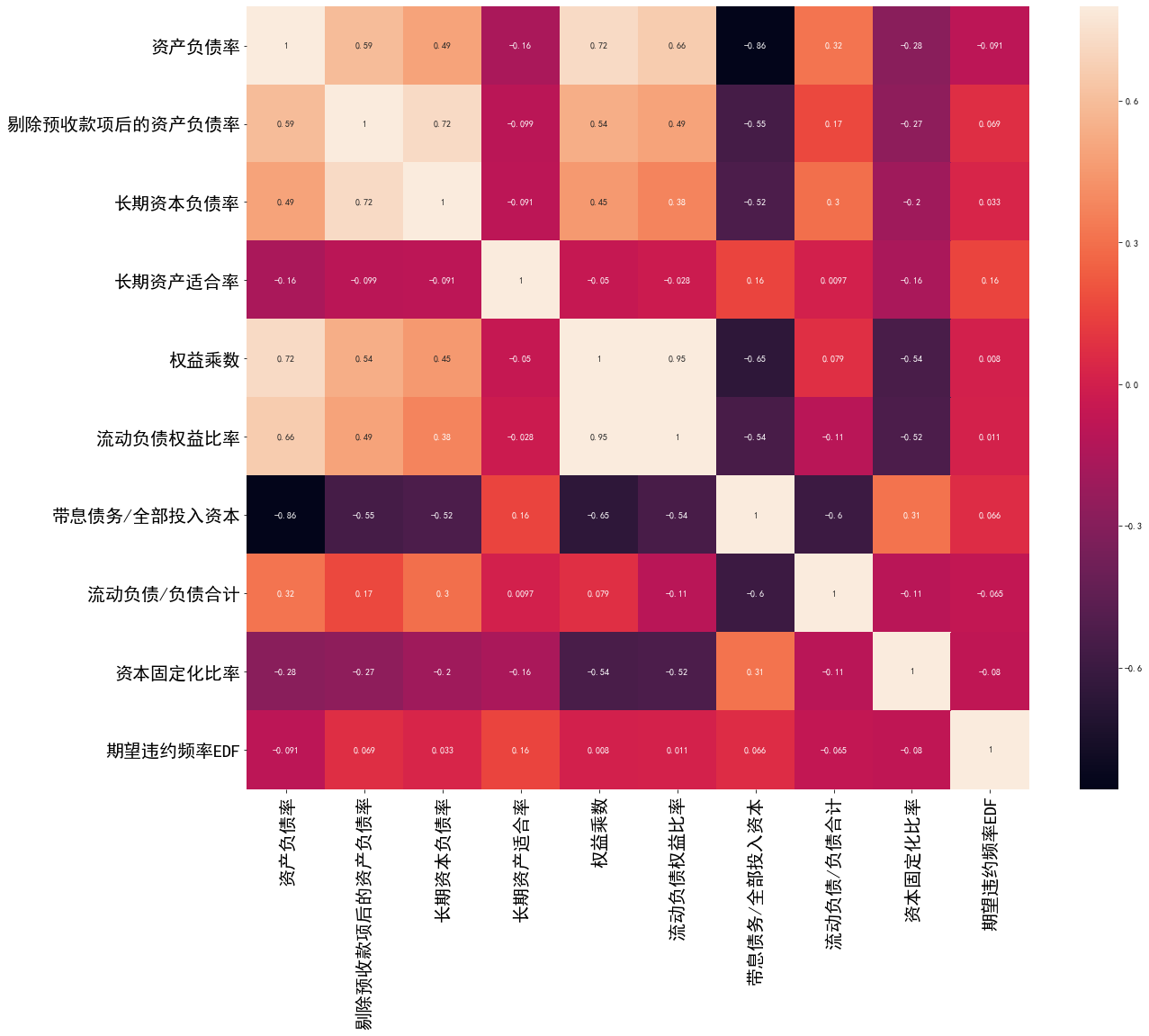
- 热力图右侧的刻度展示了不同相关系数对应的颜色深浅。从图中可以看出,权益乘数和流动负债权益比率之间的相关性较高,为0.95,即存在很强的多重共线性。在进行特征工程时可以考虑剔除二者中的一个变量,以免导致因多重共线性造成的过拟合。
- 从热力图的最后一列或最后一行可以看出,长期资产适合率和期望违约频率的相关系数相对最高,为0.16。因此,在进行违约风险评估建模时,可以考虑保留长期资产适合率这一变量。
参考 :
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/286181
推荐阅读
相关标签

