
- 1NLP实践——Few-shot事件抽取《Building an Event Extractor with Only a Few Examples》
- 2seetaface人脸识别引擎的windows java 实现,可用于搭建人脸识别java web服务器_seetaface java
- 3微信小程序自动化测试——智能化 Monkey_智能化monkey
- 4无依赖安装sentence-transformers
- 5文心一言 vs gpt-4 全面横向比较
- 6使用Spark清洗统计业务数据并保存到数据库中_spark在spring boot数据清洗
- 7Attention机制详解(深入浅出)
- 8查看transformers和torch版本_查看transformers版本
- 9自然语言处理之语言模型
- 102024最新AI系统ChatGPT商业运营网站源码,支持Midjourney绘画AI绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图_sparkai系统源码
array中不同值的数量 python_使用PyOD库在Python中进行离群值检测
赞
踩
数据探索包括许多方面,例如变量识别,处理缺失值,特征工程等。检测和处理离群值也是数据探索阶段的主要因素。输入的质量决定了输出的质量!
PyOD就是这样一个库,用于检测数据中的离群值。它提供了对20多种不同算法的访问来检测离群值,并且兼容Python 2和Python 3。
在本文中,我将带您了解离群值以及如何使用Python中的PyOD检测离群值。
目录
- 什么是离群值?
- 为什么我们需要检测离群值?
- 我们为什么要使用PyOD进行离群检测?
- PyOD库的功能
- 在Python中安装PyOD
- PyOD中使用的一些离群检测算法
- PyOD提供的额外实用程序
- Python中PyoD实例
什么是离群值?
离群值是指与数据集中其他观测值有很大差异的任何数据点。让我们看一些现实生活中的例子来理解离群检测:
- 当一个学生的平均成绩超过90%而其他同学的成绩达到70%时 - 一个明显的离群值
- 在分析某个客户的购买模式时,事实证明突然出现了非常高的值。他/她的大部分交易都低于10,000元,但有一项为100,000元。- 无论什么原因,它是整体数据的离群值
- 当你考虑到大多数运动员时,那些破纪录的短跑绝对是离群值
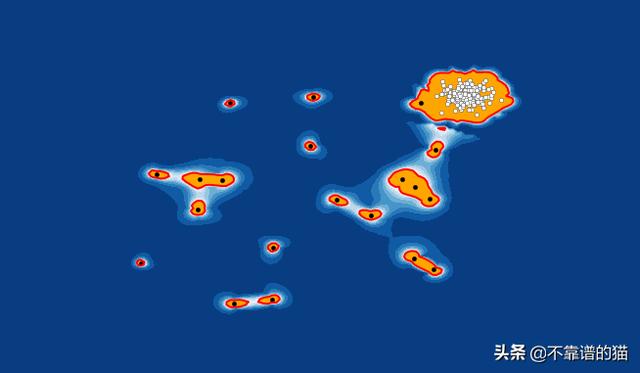
存在离群值的原因有很多。也许分析师在数据输入中出错,或者机器在测量中抛出了一个错误,或者离群值可能是故意的(有些人不想透露他们的信息,因此在表格中输入虚假信息)!
离群值有两种类型:单变量和多变量。单变量离群值是仅由一个变量的极值组成的数据点,而多变量离群值是至少两个变量的组合离群值。假设你有三个不同的变量X Y z。如果你在三维空间中画出它们的图形,它们应该会形成一种cloud。位于此cloud之外的所有数据点都是多变量离群值。
为什么我们需要检测离群值?
离群值可以极大地影响我们的分析和统计建模的结果。查看下面的图像,以可视化离群值出现时与处理离群值时机器学习模型所发生的变化:
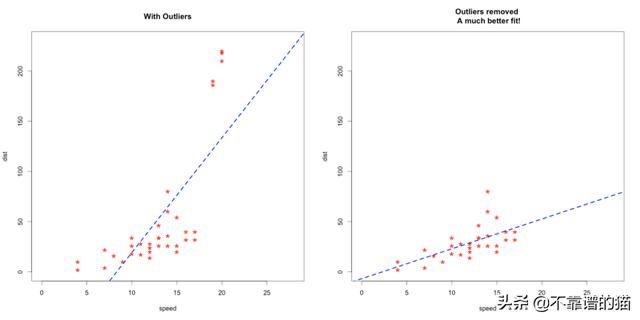
但需要注意的是,离群值并不总是坏事。理解这一点很重要。简单地从数据中删除离群值而不考虑它们对结果的影响是灾难性的。
“离群值不一定是坏事。这些只是观察到的不同于其他观察到的。但也有例外情况非常有趣。例如,如果在一个生物学实验中,一只老鼠没有死,而其他所有的老鼠都死了,那么理解其中的原因将是非常有趣的。这可能导致新的科学发现。因此,检测离群值非常重要。“ - Pierre Lafaye de Micheaux
我们倾向于使用简单的方法,如箱形图、直方图和散点图来检测离群值。但是,专用离群值检测算法在处理大量数据并需要在较大数据集中执行模式识别的方法中非常有价值。
金融中的欺诈检测和网络安全中的入侵检测等应用需要密集而准确的技术来检测离群值。
我们为什么要使用PyOD进行离群值检测?
像PyNomaly这样的现有实现并不是专门为离群值检测而设计的(尽管它仍然值得一试!)。为填补这一空白,Yue Zhao,Zain Nasrullah和Zheng Li设计并实现了PyOD库。
PyOD是一个Python工具包,用于检测多变量数据中的离群值。它的API 提供了大约20个离群值检测算法。
PyOD的特点
PyOD有一些有用的特性。
- 开放源码,包含各种算法的详细文档和示例
- 支持高级模型,包括神经网络、深度学习和Outlier Ensembles
- 使用JIT优化性能,使用numba和joblib并行化
- 兼容Python 2和3
在Python中安装PyOD
我们首先在我们的机器上安装PyOD:

注意,PyOD还包含了一些在Keras中实现的基于神经网络的模型。PyOD不会自动安装Keras或TensorFlow。如果您想使用基于神经网络的模型,您需要手动安装Keras和其他库。
PyOD中使用的离群值检测算法
让我们看看为PyOD提供的离群值检测算法。它我觉得理解它在底层是如何工作同样重要。当您在机器学习数据集上使用它时,这将为您提供更大的灵活性。
注意:我们将在本节使用一个术语outlay score。 这意味对数据点进行评分,然后使用阈值确定该点是否为离群值。
基于角度的离群值检测(ABOD)
- 它考虑每个点与其neighbors之间的关系。它不考虑这些neighbors之间的关系。其加权余弦值与所有邻域的方差可视为outlying score
- ABOD在多维数据上表现良好
- PyOD提供两种不同版本的ABOD:
- Fast ABOD:使用k近邻来近似
- Original ABOD:考虑所有具有高时间复杂性的训练点
k-Nearest Neighbors Detector
- 对于任意数据点,其到第k个最近邻的距离可以看作是outlying score
- PyOD支持三个kNN探测器:
- Largest:使用第k个neighbor的距离作为离群得分
- Mean:使用所有k个neighbors的平均值作为离群值得分
- Median:使用与neighbors的距离的中位数作为离群值得分
隔离森林
- 它在内部使用scikit-learn库。在此方法中,使用一组树完成数据分区。隔离森林提供了一个anomaly score ,用于查看结构中点的隔离程度。然后使用anomaly score 来识别来自正常观察的离群值
- 隔离森林在多维数据上表现良好
基于直方图的离群值检测
- 它是一种有效的非监督方法,假设特征不相关,通过构建直方图计算离群值
- 它比多变量方法快得多,但代价是精度较低
LOCI(Local Correlation Integral)
- LOCI对于检测离群值和离群值组非常有效。它为每个点提供LOCI图,总结了该点周围区域内数据的大量信息,确定了clusters,micro-clusters,它们的直径以及它们的clusters间距离
- 现有的离群值检测方法都不能匹配此功能,因为它们只为每个点输出一个数字
Feature Bagging
- feature bagging检测器将许多基础检测器安装在数据集的各种子样本上。它使用平均或其他组合方法来提高预测准确度
- 默认情况下,Local Outlier Factor(LOF)用作基本estimator。但是,任何estimator都可以用作基本estimator,例如kNN和ABOD
- feature bagging首先通过随机选择特征子集来构造n个子样本。这带来了base estimators的多样性。最后,通过平均或取所有基本检测器的最大值来生成预测分数
基于聚类的局部离群因子
- 它将数据分为小聚类和大聚类。然后根据该点所属的聚类的大小以及距离最近的大聚类的距离计算anomaly score
PyOD提供的额外实用程序
- 函数generate_data可用于生成具有离群值的随机数据。内部数据由多元高斯分布生成,离群值由均匀分布生成。
- 我们可以提供我们自己的离群值分数和我们想要在数据集中的样本总数。我们将使用这个实用函数在实现部分创建数据。
PyOD实例
在本节中,我们将在Python中实现PyOD库。我将使用两种不同的方法来演示PyOD:
- 使用模拟数据集
- 使用真实世界的数据集 - The Big Mart Sales Challenge
模拟数据集上的PyOD
首先,让我们导入所需的Python库:
import numpy as npfrom scipy import statsimport matplotlib.pyplot as plt%matplotlib inlineimport matplotlib.font_manager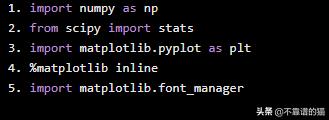
现在,我们将导入我们想要用来检测机器学习数据集中离群值的模型。我们将使用ABOD和KNN:
from pyod.models.abod import ABODfrom pyod.models.knn import KNN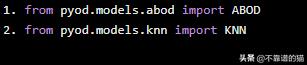
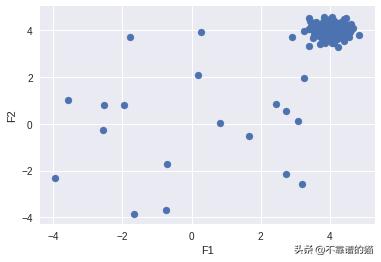
现在,我们将创建一个带有离群值的随机数据集并绘制它。
from pyod.utils.data import generate_data, get_outliers_inliers#generate random data with two featuresX_train, Y_train = generate_data(n_train=200,train_only=True, n_features=2)# by default the outlier fraction is 0.1 in generate data function outlier_fraction = 0.1# store outliers and inliers in different numpy arraysx_outliers, x_inliers = get_outliers_inliers(X_train,Y_train)n_inliers = len(x_inliers)n_outliers = len(x_outliers)#separate the two features and use it to plot the data F1 = X_train[:,[0]].reshape(-1,1)F2 = X_train[:,[1]].reshape(-1,1)# create a meshgrid xx , yy = np.meshgrid(np.linspace(-10, 10, 200), np.linspace(-10, 10, 200))# scatter plot plt.scatter(F1,F2)plt.xlabel('F1')plt.ylabel('F2')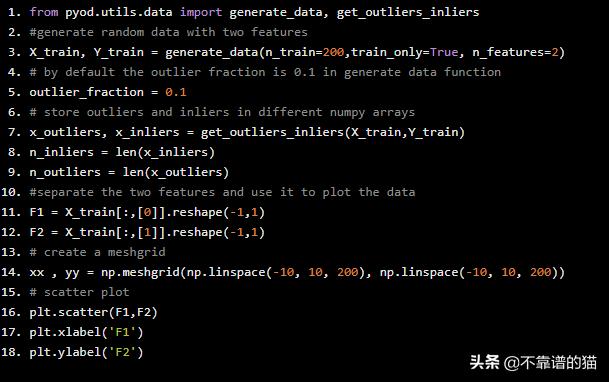
创建一个字典并添加要用于检测离群值的所有模型:
classifiers = { 'Angle-based Outlier Detector (ABOD)' : ABOD(contamination=outlier_fraction), 'K Nearest Neighbors (KNN)' : KNN(contamination=outlier_fraction)}
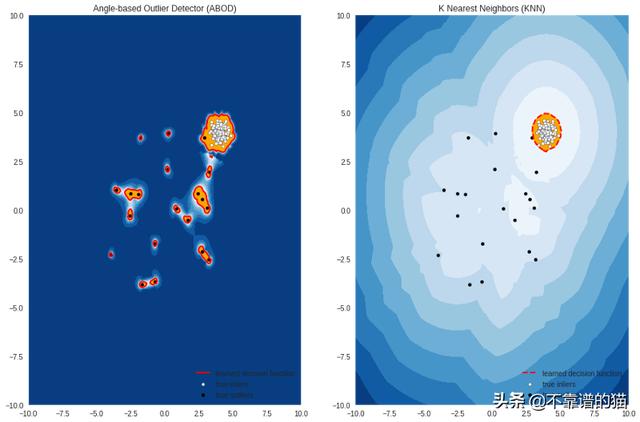
将数据拟合到我们在字典中添加的每个模型,然后,查看每个模型如何检测离群值:
#set the figure sizeplt.figure(figsize=(10, 10))for i, (clf_name,clf) in enumerate(classifiers.items()) : # fit the dataset to the model clf.fit(X_train) # predict raw anomaly score scores_pred = clf.decision_function(X_train)*-1 # prediction of a datapoint category outlier or inlier y_pred = clf.predict(X_train) # no of errors in prediction n_errors = (y_pred != Y_train).sum() print('No of Errors : ',clf_name, n_errors) # rest of the code is to create the visualization # threshold value to consider a datapoint inlier or outlier threshold = stats.scoreatpercentile(scores_pred,100 *outlier_fraction) # decision function calculates the raw anomaly score for every point Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) * -1 Z = Z.reshape(xx.shape) subplot = plt.subplot(1, 2, i + 1) # fill blue colormap from minimum anomaly score to threshold value subplot.contourf(xx, yy, Z, levels = np.linspace(Z.min(), threshold, 10),cmap=plt.cm.Blues_r) # draw red contour line where anomaly score is equal to threshold a = subplot.contour(xx, yy, Z, levels=[threshold],linewidths=2, colors='red') # fill orange contour lines where range of anomaly score is from threshold to maximum anomaly score subplot.contourf(xx, yy, Z, levels=[threshold, Z.max()],colors='orange') # scatter plot of inliers with white dots b = subplot.scatter(X_train[:-n_outliers, 0], X_train[:-n_outliers, 1], c='white',s=20, edgecolor='k') # scatter plot of outliers with black dots c = subplot.scatter(X_train[-n_outliers:, 0], X_train[-n_outliers:, 1], c='black',s=20, edgecolor='k') subplot.axis('tight') subplot.legend( [a.collections[0], b, c], ['learned decision function', 'true inliers', 'true outliers'], prop=matplotlib.font_manager.FontProperties(size=10), loc='lower right') subplot.set_title(clf_name) subplot.set_xlim((-10, 10)) subplot.set_ylim((-10, 10))plt.show()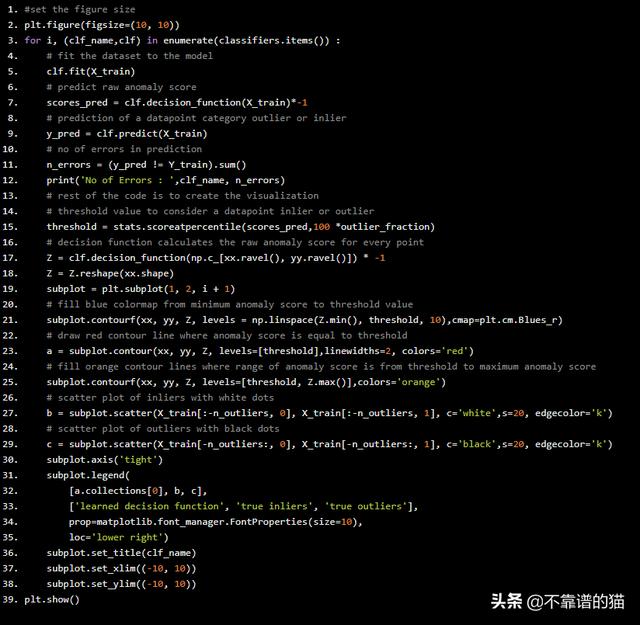
关于大市场销售问题的PyOD
现在,让我们看看PyOD如何在著名的 Big Mart Sales Problem(https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/?utm_source=outlierdetectionpyod&utm_medium=blog)上做到。
让我们从导入所需的Python库并加载数据开始:
import pandas as pdimport numpy as np# Import modelsfrom pyod.models.abod import ABODfrom pyod.models.cblof import CBLOFfrom pyod.models.feature_bagging import FeatureBaggingfrom pyod.models.hbos import HBOSfrom pyod.models.iforest import IForestfrom pyod.models.knn import KNNfrom pyod.models.lof import LOF# reading the big mart sales training datadf = pd.read_csv("train.csv")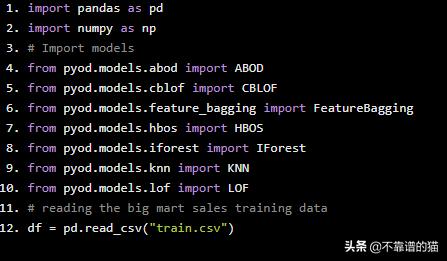
让我们绘制Item MRP vs Item Outlet Sales以了解数据:
df.plot.scatter('Item_MRP','Item_Outlet_Sales')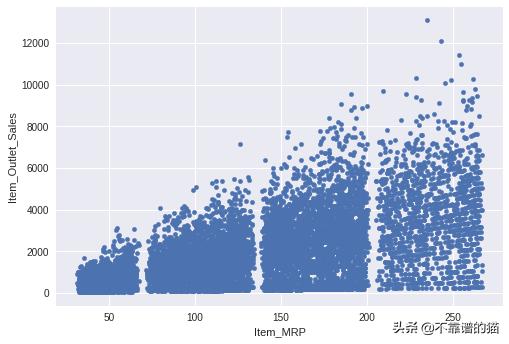
Item Outlet Sales的范围是0到12000,Item MRP是0到250。我们将这两个特征缩小到0到1之间的范围。这是创建可解释的可视化所必需的。
注意:如果您不想要可视化,您可以使用相同的比例来预测一个点是否为离群值。
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler(feature_range=(0, 1))df[['Item_MRP','Item_Outlet_Sales']] = scaler.fit_transform(df[['Item_MRP','Item_Outlet_Sales']])df[['Item_MRP','Item_Outlet_Sales']].head()
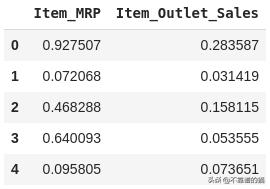
将这些值存储在NumPy数组中,以便稍后在我们的模型中使用:
X1 = df['Item_MRP'].values.reshape(-1,1)X2 = df['Item_Outlet_Sales'].values.reshape(-1,1)X = np.concatenate((X1,X2),axis=1)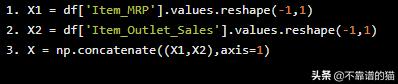
再次,我们将创建一个字典。但这一次,我们将添加更多模型,并了解每个模型如何预测离群值。
您可以根据您的问题和您对数据的理解来设置离群分数的值。在我们的示例中,我想检测5%的观察值,这些观察值与其他数据不相似。我把离群分数的值设为0.05。
random_state = np.random.RandomState(42)outliers_fraction = 0.05# Define seven outlier detection tools to be comparedclassifiers = { 'Angle-based Outlier Detector (ABOD)': ABOD(contamination=outliers_fraction), 'Cluster-based Local Outlier Factor (CBLOF)':CBLOF(contamination=outliers_fraction,check_estimator=False, random_state=random_state), 'Feature Bagging':FeatureBagging(LOF(n_neighbors=35),contamination=outliers_fraction,check_estimator=False,random_state=random_state), 'Histogram-base Outlier Detection (HBOS)': HBOS(contamination=outliers_fraction), 'Isolation Forest': IForest(contamination=outliers_fraction,random_state=random_state), 'K Nearest Neighbors (KNN)': KNN(contamination=outliers_fraction), 'Average KNN': KNN(method='mean',contamination=outliers_fraction)}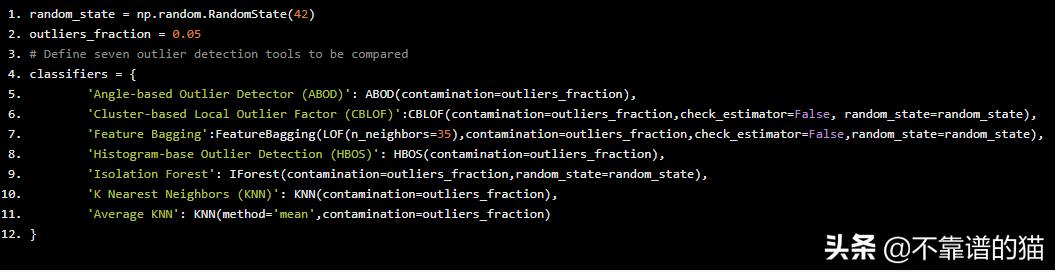
现在,我们将逐个拟合每个模型的数据,看看每个模型预测离群值的方式有什么不同。
xx , yy = np.meshgrid(np.linspace(0,1 , 200), np.linspace(0, 1, 200))for i, (clf_name, clf) in enumerate(classifiers.items()): clf.fit(X) # predict raw anomaly score scores_pred = clf.decision_function(X) * -1 # prediction of a datapoint category outlier or inlier y_pred = clf.predict(X) n_inliers = len(y_pred) - np.count_nonzero(y_pred) n_outliers = np.count_nonzero(y_pred == 1) plt.figure(figsize=(10, 10)) # copy of dataframe dfx = df dfx['outlier'] = y_pred.tolist() # IX1 - inlier feature 1, IX2 - inlier feature 2 IX1 = np.array(dfx['Item_MRP'][dfx['outlier'] == 0]).reshape(-1,1) IX2 = np.array(dfx['Item_Outlet_Sales'][dfx['outlier'] == 0]).reshape(-1,1) # OX1 - outlier feature 1, OX2 - outlier feature 2 OX1 = dfx['Item_MRP'][dfx['outlier'] == 1].values.reshape(-1,1) OX2 = dfx['Item_Outlet_Sales'][dfx['outlier'] == 1].values.reshape(-1,1) print('OUTLIERS : ',n_outliers,'INLIERS : ',n_inliers, clf_name) # threshold value to consider a datapoint inlier or outlier threshold = stats.scoreatpercentile(scores_pred,100 * outliers_fraction) # decision function calculates the raw anomaly score for every point Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) * -1 Z = Z.reshape(xx.shape) # fill blue map colormap from minimum anomaly score to threshold value plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), threshold, 7),cmap=plt.cm.Blues_r) # draw red contour line where anomaly score is equal to thresold a = plt.contour(xx, yy, Z, levels=[threshold],linewidths=2, colors='red') # fill orange contour lines where range of anomaly score is from threshold to maximum anomaly score plt.contourf(xx, yy, Z, levels=[threshold, Z.max()],colors='orange') b = plt.scatter(IX1,IX2, c='white',s=20, edgecolor='k') c = plt.scatter(OX1,OX2, c='black',s=20, edgecolor='k') plt.axis('tight') # loc=2 is used for the top left corner plt.legend( [a.collections[0], b,c], ['learned decision function', 'inliers','outliers'], prop=matplotlib.font_manager.FontProperties(size=20), loc=2) plt.xlim((0, 1)) plt.ylim((0, 1)) plt.title(clf_name) plt.show()
OUTPUT
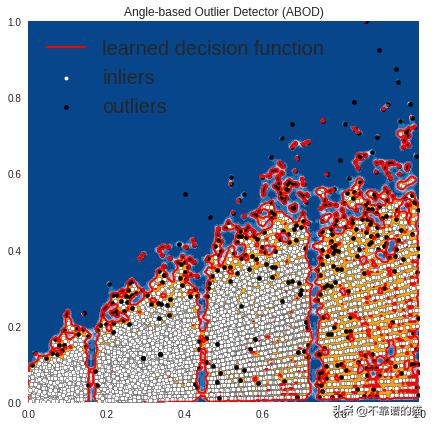
OUTLIERS : 447 INLIERS : 8076 Angle-based Outlier Detector (ABOD)
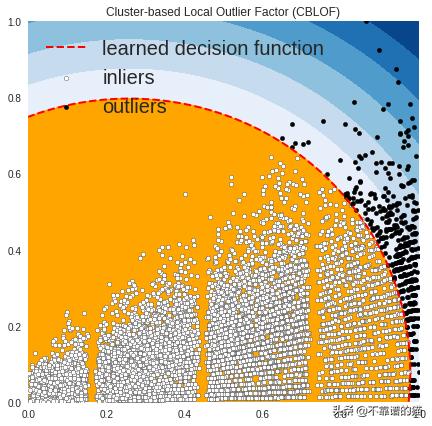
OUTLIERS : 427 INLIERS : 8096 Cluster-based Local Outlier Factor (CBLOF)
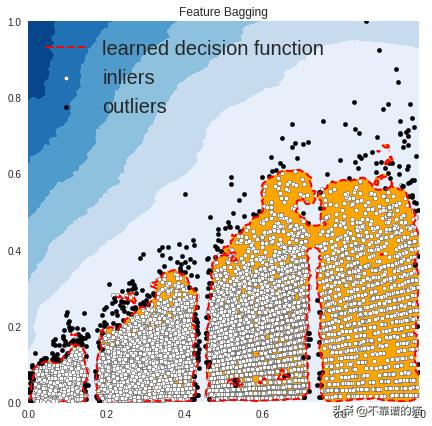
OUTLIERS : 386 INLIERS : 8137 Feature Bagging
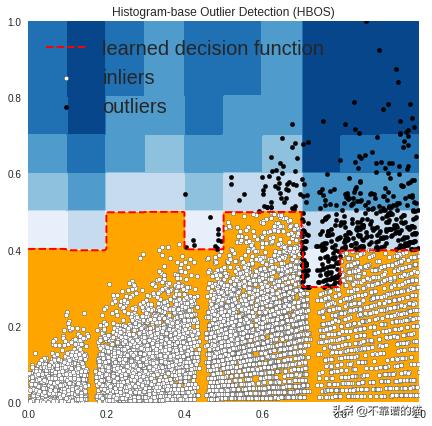
OUTLIERS : 501 INLIERS : 8022 Histogram-base Outlier Detection (HBOS)
OUTLIERS : 427 INLIERS : 8096 Isolation Forest

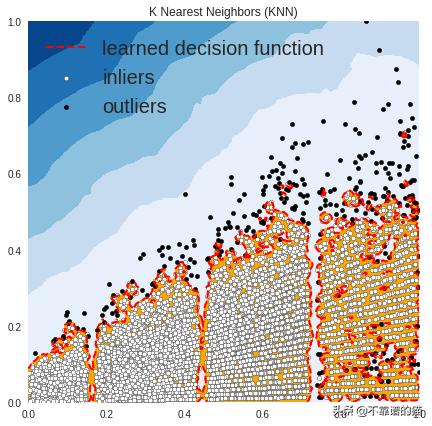
OUTLIERS : 311 INLIERS : 8212 K Nearest Neighbors (KNN)
OUTLIERS : 176 INLIERS : 8347 Average KNN
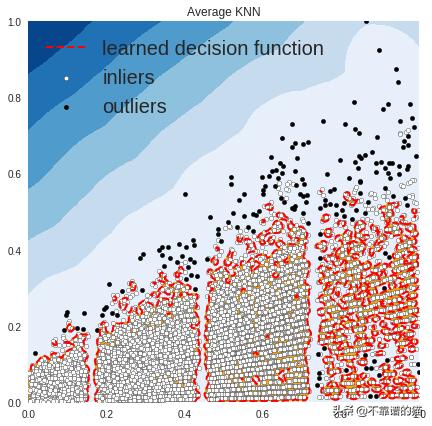
在上图中,白点是由红线包围的内点,黑点是蓝色区域中的离群值。
最后
PyOD已经支持大约20种经典的离群值检测算法,这些算法可以在学术和商业项目中使用。它的贡献者计划通过实现能够很好地处理时间序列和地理空间数据的模型来增强工具箱。


