
- 1添加作者_投稿后,你要临时加“作者”?别逗了……
- 2利用LSTM+CNN+glove词向量预训练模型进行微博评论情感分析(二分类)_glove lstm 情感分类
- 3鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Grid)_arkts grid
- 4安装pyrender和OSMesa(非常详细)从零基础入门到精通,看完这一篇就够了
- 5国内外各ChatGPT类语言大模型API价格汇总, 对比,ChatGPT/Gmini/PaLM/Clude/Ernie/ChatGLM/千问/混元/星火/Minimax/百川
- 6three-sum(3个数的和)_three sum
- 7神经网络:GRU基础学习
- 8NLP自然语言处理的基本语言任务介绍_nlp基础任务
- 9前端学习笔记____基础篇HTML&CSS_前端学习时,一个盒子上边时ul加li,下边是img,为社么给ul加padding-bottom没有效
- 10Pygame —— 一个好玩的游戏 Python 库_pygame库
【完全攻略】畅游NLP海洋:HuggingFace的快速入门_couldn't reach 'seamew/chnsenticorp' on the hub (c
赞
踩
前言
Hugging Face是一个以自然语言处理(NLP)为重点的技术公司,也是一个开源社区和平台,旨在提供丰富的NLP模型、工具和资源。 Hugging Face的目标是成为NLP领域的社区和创新驱动者,他们通过为开发者和研究人员提供开源工具、预训练模型和数据集来实现这一目标。Hugging Face的开源库和工具广泛应用于各种NLP任务,包括文本分类、命名实体识别、情感分析、机器翻译等。一、HuggingFace介绍
1-1、HuggingFace的介绍
Hugging Face是一个致力于自然语言处理(NLP)领域的开源社区和技术公司。他们提供了一个广泛的NLP工具和资源平台,旨在帮助开发者和研究人员快速构建、训练和部署各种NLP模型。
通过Hugging Face,你可以使用他们开发的开源库和工具,如transformers、tokenizers和datasets等,来处理文本数据、构建预训练的Transformer模型,并进行微调和迁移学习。这些工具支持各种常见的NLP任务,如文本分类、命名实体识别、情感分析等。
HuggingFace的主要库为:
- Transformer模型库: 调用各类预训练模型
- Datasets数据集库: 数据集使用
- Tokenizer分词库:分词工具
官方文档:https://huggingface.co/docs
1-2、安装
# 安装transformers和datasets包
pip install transformers -i https://mirror.baidu.com/pypi/simple
pip install datasets -i https://mirror.baidu.com/pypi/simple
- 1
- 2
- 3
- 4
二、Tokenizer分词库:分词工具
2-0、加载BertTokenizer:需要传入预训练模型的名字
from transformers import BertTokenizer
#加载预训练字典和分词方法
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 可选,huggingface 中的预训练模型名称或路径,默认为 bert-base-chinese
cache_dir=None, # 将数据保存到的本地位置,使用cache_dir 可以指定文件下载位置
force_download=False,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2-1、使用Tokenizer对句子编码:
sents = [ '选择珠江花园的原因就是方便。', '笔记本的键盘确实爽。', '房间太小。其他的都一般。', '今天才知道这书还有第6卷,真有点郁闷.', '机器背面似乎被撕了张什么标签,残胶还在。', ] #编码两个句子 out = tokenizer.encode( text=sents[0], text_pair=sents[1], # 一次编码两个句子,若没有text_pair这个参数,就一次编码一个句子 #当句子长度大于max_length时,截断 truncation=True, #一律补pad到max_length长度 padding='max_length', # 少于max_length时就padding add_special_tokens=True, max_length=30, # 指定最大长度为30。 return_tensors=None, # None表示不指定数据类型,默认返回list ) print(out) print(tokenizer.decode(out))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
输出:开头是特殊符号 [CLS],两个句子中间用 [SEP] 分隔,句子末尾也是 [SEP],最后用 [PAD] 将句子填充到 max_length 长度
[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 511, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0]
[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 。 [SEP] 笔 记 本 的 键 盘 确 实 爽 。 [SEP] [PAD] [PAD] [PAD]
2-2、使用增强Tokenizer对句子编码:
sents = [ '选择珠江花园的原因就是方便。', '笔记本的键盘确实爽。', '房间太小。其他的都一般。', '今天才知道这书还有第6卷,真有点郁闷.', '机器背面似乎被撕了张什么标签,残胶还在。', ] #增强的编码函数 out = tokenizer.encode_plus( text=sents[0], text_pair=sents[1], #当句子长度大于max_length时,截断 truncation=True, #一律补零到max_length长度 padding='max_length', max_length=30, add_special_tokens=True, #可取值tensorflow,pytorch,numpy,默认值None为返回list return_tensors=None, #返回token_type_ids return_token_type_ids=True, #返回attention_mask return_attention_mask=True, #返回special_tokens_mask 特殊符号标识 return_special_tokens_mask=True, #返回offset_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用 #return_offsets_mapping=True, #返回length 标识长度 return_length=True, ) print(out) # 字典 print(tokenizer.decode(out['input_ids']))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
输出:
{‘input_ids’: [101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 511, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0], ‘token_type_ids’: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], ‘special_tokens_mask’: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1], ‘attention_mask’: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], ‘length’: 30}
[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 。 [SEP] 笔 记 本 的 键 盘 确 实 爽 。 [SEP] [PAD] [PAD] [PAD]
指标详细解释:
- input_ids 就是编码后的词,即将句子里的一个一个词变为一个一个数字
- token_type_ids 第一个句子和特殊符号的位置是0,第二个句子的位置是1(含第二个句子末尾的 [SEP])
- special_tokens_mask 特殊符号的位置是1,其他位置是0
- attention_mask pad的位置是0,其他位置是1
- length 返回句子长度
2-3、批量编码单个句子:
sents = [ '选择珠江花园的原因就是方便。', '笔记本的键盘确实爽。', '房间太小。其他的都一般。', '今天才知道这书还有第6卷,真有点郁闷.', '机器背面似乎被撕了张什么标签,残胶还在。', ] # 批量编码一个一个的句子 out = tokenizer.batch_encode_plus( batch_text_or_text_pairs=[sents[0], sents[1]], # 批量编码,一次编码了两个句子(与增强的编码函数相比,就此处不同) # 当句子长度大于max_length时,截断 truncation=True, # 一律补零到max_length长度 padding='max_length', max_length=15, add_special_tokens=True, # 可取值tf,pt,np,默认为返回list return_tensors=None, # 返回token_type_ids return_token_type_ids=True, # 返回attention_mask return_attention_mask=True, # 返回special_tokens_mask 特殊符号标识 return_special_tokens_mask=True, # 返回offset_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用 # return_offsets_mapping=True, # 返回length 标识长度 return_length=True, ) print(out) # 字典 print(tokenizer.decode(out['input_ids'][0]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
输出:
{‘input_ids’: [[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 102], [101, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0]], ‘token_type_ids’: [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], ‘special_tokens_mask’: [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]], ‘length’: [15, 12], ‘attention_mask’: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]}
[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 [SEP]
2-4、添加新词:
#获取字典 zidian = tokenizer.get_vocab() #添加新词 tokenizer.add_tokens(new_tokens=['月光', '希望']) #添加新符号 tokenizer.add_special_tokens({'eos_token': '[EOS]'}) # End Of Sentence # 获取更新后的字典 zidian = tokenizer.get_vocab() # 解码新词 #编码新添加的词 out = tokenizer.encode( text='月光的新希望[EOS]', text_pair=None, #当句子长度大于max_length时,截断 truncation=True, #一律补pad到max_length长度 padding='max_length', add_special_tokens=True, max_length=8, return_tensors=None, ) print(out) print(tokenizer.decode(out))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
输出:

2-5、AutoTokenizer与BertTokenizer的区别
AutoTokenizer是通用封装,根据载入预训练模型来自适应。
主要区别是:
-
自动选择模型类型: AutoTokenizer是一个自动选择适合任务的分词器的工具。它可以根据输入的预训练模型名称或模型类型自动选择对应的分词器。这使得在使用不同的模型时更加方便,而不需要手动指定分词器。例如,你可以使用AutoTokenizer.from_pretrained(“bert-base-uncased”),它将自动选择适合BERT模型的BertTokenizer。
-
具体模型的分词器: BertTokenizer是用于BERT模型的分词器,它是基于WordPiece分词算法的。它将输入的文本分割成小的单词单元(token),并为每个token分配一个唯一的ID。BertTokenizer还提供了其他有用的方法,如获取特殊token的ID(如[CLS]和[SEP]),将文本转换为模型所需的输入格式等。
-
支持更多模型类型: AutoTokenizer可以自动选择适合多种预训练模型的分词器,不仅限于BERT。它支持包括GPT、RoBERTa、XLNet等在内的各种模型。这使得你能够使用同一种工具在不同的模型之间进行切换和比较。
总的来说,AutoTokenizer是一个用于自动选择适合任务的分词器的工具,而BertTokenizer是专门用于BERT模型的分词器。AutoTokenizer提供了更大的灵活性和通用性,可以适用于多种不同的预训练模型。
三、Datasets数据集库: 数据集使用
3-1、数据集使用
Datasets数据集库: 数据集使用
- 数据下载到本地
- 直接从本地读取
- 数据集对应Hugging Face网站: https://huggingface.co/datasets.
# 1
from datasets import load_dataset
#加载数据
dataset = load_dataset(path='lansinuote/ChnSentiCorp')
#保存数据集到磁盘
dataset.save_to_disk(dataset_dict_path='./data/ChnSentiCorp')
# 2
#从磁盘加载数据
from datasets import load_from_disk
dataset = load_from_disk('./data/ChnSentiCorp')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
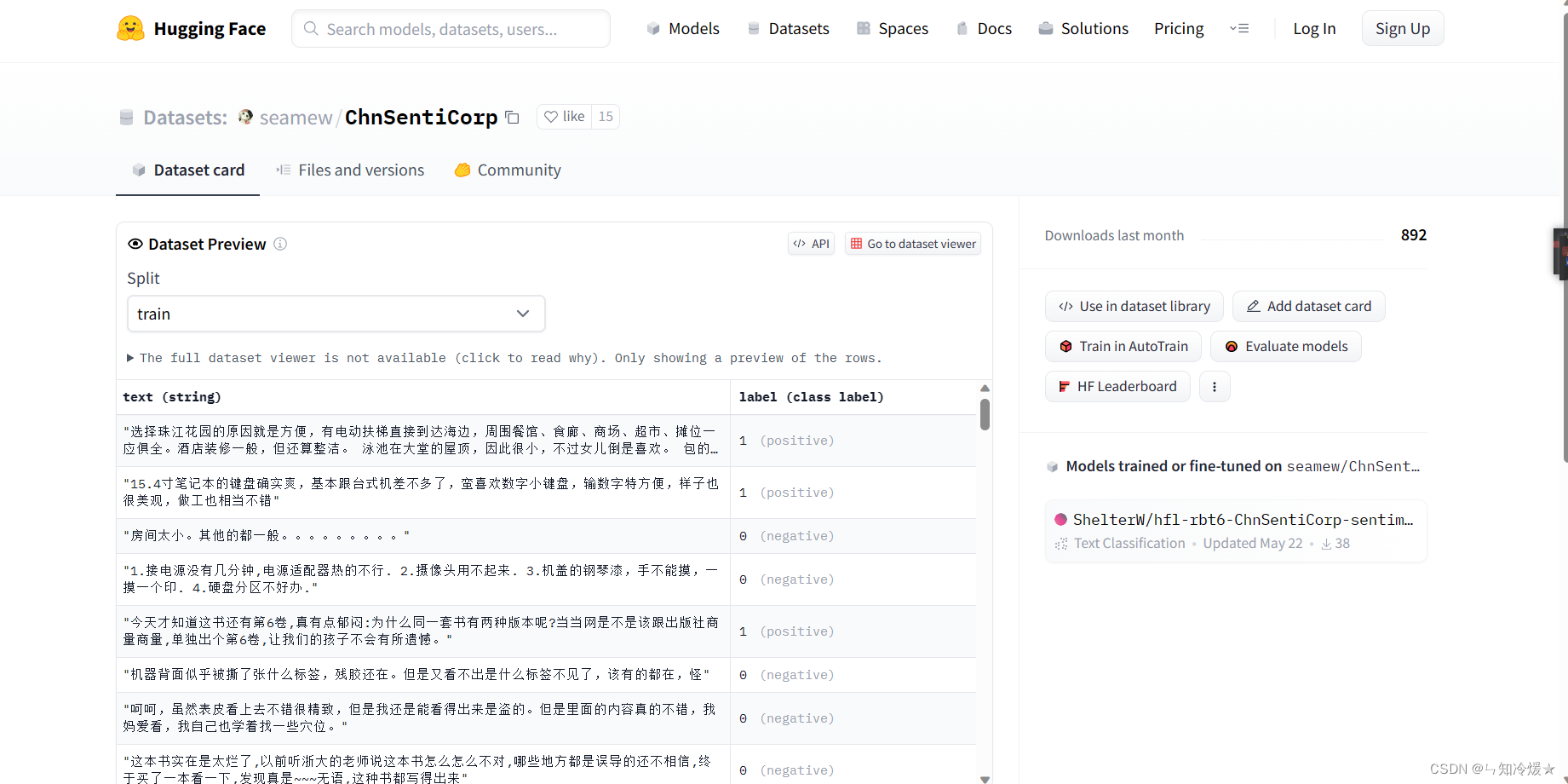
问题:容易报错无法找到数据*ConnectionError: Couldn’t reach ‘seamew/ChnSentiCorp’ on the Hub (ConnectionError)*l
解决方法:打开网站https://huggingface.co/datasets/seamew/ChnSentiCorp获取数据。
3-2、数据集操作
3-3、评价函数
查看所有的评价指标
from datasets import list_metrics
#列出评价指标
metrics_list = list_metrics()
print(metrics_list)
- 1
- 2
- 3
- 4
- 5
- 6
输出:
[‘accuracy’, ‘bertscore’, ‘bleu’, ‘bleurt’, ‘brier_score’, ‘cer’, ‘character’, ‘charcut_mt’, ‘chrf’, ‘code_eval’, ‘comet’, ‘competition_math’, ‘coval’, ‘cuad’, ‘exact_match’, ‘f1’, ‘frugalscore’, ‘glue’, ‘google_bleu’, ‘indic_glue’, ‘mae’, ‘mahalanobis’, ‘mape’, ‘mase’, ‘matthews_correlation’, ‘mauve’, ‘mean_iou’, ‘meteor’, ‘mse’, ‘nist_mt’, ‘pearsonr’, ‘perplexity’, ‘poseval’, ‘precision’, ‘r_squared’, ‘recall’, ‘rl_reliability’, ‘roc_auc’, ‘rouge’, ‘sacrebleu’, ‘sari’, ‘seqeval’, ‘smape’, ‘spearmanr’, ‘squad’, ‘squad_v2’, ‘super_glue’, ‘ter’, ‘trec_eval’, ‘wer’, ‘wiki_split’, ‘xnli’, ‘xtreme_s’, ‘AlhitawiMohammed22/CER_Hu-Evaluation-Metrics’, ‘BucketHeadP65/confusion_matrix’, ‘BucketHeadP65/roc_curve’, ‘Drunper/metrica_tesi’, ‘Felipehonorato/eer’, ‘He-Xingwei/sari_metric’, ‘JP-SystemsX/nDCG’, ‘Josh98/nl2bash_m’, ‘Kyle1668/squad’, ‘Muennighoff/code_eval’, ‘NCSOFT/harim_plus’, ‘Natooz/ece’, ‘NikitaMartynov/spell-check-metric’, ‘Pipatpong/perplexity’, ‘Splend1dchan/cosine_similarity’, ‘Viona/fuzzy_reordering’, ‘Viona/kendall_tau’, ‘Vipitis/shadermatch’, ‘Yeshwant123/mcc’, ‘abdusah/aradiawer’, ‘abidlabs/mean_iou’, ‘abidlabs/mean_iou2’, ‘andstor/code_perplexity’, ‘angelina-wang/directional_bias_amplification’, ‘aryopg/roc_auc_skip_uniform_labels’, ‘brian920128/doc_retrieve_metrics’, ‘bstrai/classification_report’, ‘chanelcolgate/average_precision’, ‘ckb/unigram’, ‘codeparrot/apps_metric’, ‘cpllab/syntaxgym’, ‘dvitel/codebleu’, ‘ecody726/bertscore’, ‘fschlatt/ner_eval’, ‘giulio98/codebleu’, ‘guydav/restrictedpython_code_eval’, ‘harshhpareek/bertscore’, ‘hpi-dhc/FairEval’, ‘hynky/sklearn_proxy’, ‘hyperml/balanced_accuracy’, ‘ingyu/klue_mrc’, ‘jpxkqx/peak_signal_to_noise_ratio’, ‘jpxkqx/signal_to_reconstruction_error’, ‘k4black/codebleu’, ‘kaggle/ai4code’, ‘langdonholmes/cohen_weighted_kappa’, ‘lhy/hamming_loss’, ‘lhy/ranking_loss’, ‘lvwerra/accuracy_score’, ‘manueldeprada/beer’, ‘mfumanelli/geometric_mean’, ‘omidf/squad_precision_recall’, ‘posicube/mean_reciprocal_rank’, ‘sakusakumura/bertscore’, ‘sma2023/wil’, ‘spidyidcccc/bertscore’, ‘tialaeMceryu/unigram’, ‘transZ/sbert_cosine’, ‘transZ/test_parascore’, ‘transformersegmentation/segmentation_scores’, ‘unitxt/metric’, ‘unnati/kendall_tau_distance’, ‘weiqis/pajm’, ‘ybelkada/cocoevaluate’, ‘yonting/average_precision_score’, ‘yuyijiong/quad_match_score’]
使用某个评价指标:
from datasets import load_metric
#加载一个评价指标
metric = load_metric('glue', 'mrpc')
#计算一个评价指标
predictions = [0, 1, 0]
references = [0, 1, 1]
final_score = metric.compute(predictions=predictions, references=references)
print(final_score)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
四、用pipeline来完成多种NLP任务
模型对应Hugging Face网站: https://huggingface.co/models.
4-1、各类NLP任务的常用模型
以下列举一些任务的常用模型:
文本分类:finbert、roberta-base-go_emotions、twitter-roberta-base-sentiment-latest
问答:roberta-base-squad2、xlm-roberta-large-squad2、distilbert-base-cased-distilled-squad
零样本分类:bart-large-mnli、mDeBERTa-v3-base-mnli-xnli
翻译:t5-base、 opus-mt-zh-en、translation_en-zh
总结:bart-large-cnn、led-base-book-summary
文本生成:Baichuan-13B-Chat、falcon-40b、starcoder
文本相似度:all-MiniLML6-v2、text2vec-large-chinese、all-mpnet-base-v2
4-2、在管道方式中指定NLP任务
pipeline:管道方式"(Pipeline)指的是一种方便的方式,用于将不同的NLP(自然语言处理)任务串联在一起,使其更容易使用。管道方式允许您轻松地使用transformers库中提供的各种预训练模型来执行一系列自然语言处理任务,而无需编写大量的额外代码。内置流水线的处理方法(包含数据读取、数据预处理、创建模型、评估模型结果、模型调参等)。
管道方式通常涉及以下几个步骤:
- 导入相应的库
- 加载模型:根据任务加载相应的模型
- 调用模型直接对文本进行处理。
所涉及到的NLP任务如下:
- feature-extraction 特征提取:把一段文字用一个向量来表示
- fill-mask 填词:把一段文字的某些部分mask住,然后让模型填空
- ner 命名实体识别:识别文字中出现的人名地名的命名实体
- question-answering 问答:给定一段文本以及针对它的一个问题,从文本中抽取答案
- sentiment-analysis 情感分析:一段文本是正面还是负面的情感倾向
- summarization 摘要:根据一段长文本中生成简短的摘要
- text-generation文本生成:给定一段文本,让模型补充后面的内容
- translation 翻译:把一种语言的文字翻译成另一种语言
- conversational: 多轮聊天对话任务
4-3、使用管道来完成文本分类任务&完形填空任务
文本分类任务:(自动下载)
from transformers import pipeline # 加载文本分类管道 text_classification = pipeline("text-classification") # 输入文本 text = "这是一篇关于自然语言处理的文章。" # 执行文本分类任务 result = text_classification(text) # 输出结果 print(result) # 如果出现OSError,即无法加载模型,则需要手动下载对应的模型 # 参考4-N
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
完形填空任务:(使用手动下载好的模型并且进行加载)
from transformers import pipeline
config = BertConfig.from_pretrained("./bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("./bert-base-uncased")
model = BertForMaskedLM.from_pretrained("./bert-base-uncased", config=config, ignore_mismatched_sizes=True)
unmasker = pipeline('fill-mask', model=model, tokenizer = tokenizer)
unmasker("Hello I'm a [MASK] model.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:

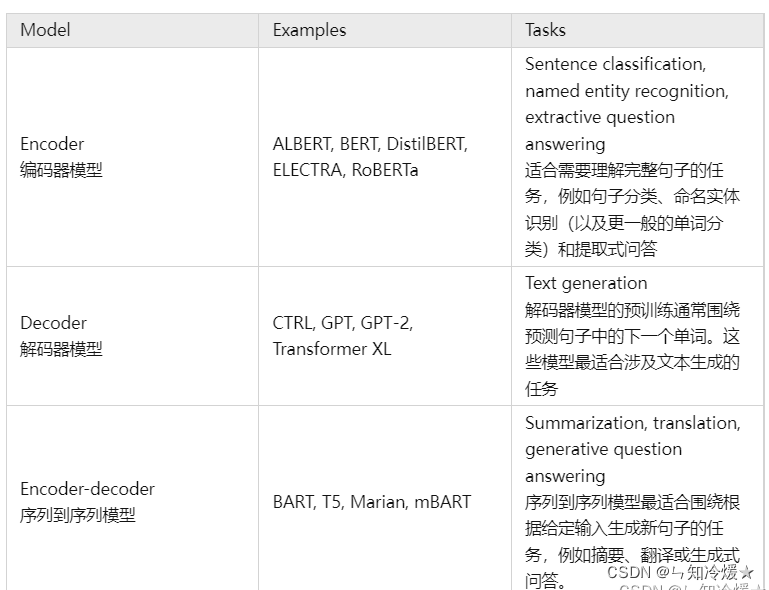
不同任务需要的模型:
4-4、用Bert模型实现完型填空任务(展开Pipeline过程)
- 载入词表,对输入文本进行转换:这里使用手动下载到本地的模型
from transformers import *
import torch
# 这里使用的是下载到本地的模型,参考4-N来操作
tokenizer = BertTokenizer.from_pretrained("./bert-base-uncased")
# bert模型需要[CLS] [SEP]来标记段落的开始和结束,结束可以有多个,即标记多句话
# 使用模型对文本进行转换,看起来类似中文分词如果在词表中没有找到,则系统会使用通配符的单词将该单词拆开
text = "[CLS] who is Li Jinhong ? [SEP] Li Jinhong is a programmer [SEP]"
# 分词处理,这里输入的字符串是已经用特殊标识符处理好。
# 一般情况下,我们直接使用tokenizer.encode()来完成特殊词标识、分词、转换为词向量这三步操作。
tokenizer_text = tokenizer.tokenize(text)
tokenizer_text
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出:
[‘[CLS]’,
‘who’,
‘is’,
‘li’,
‘jin’,
‘##hong’,
‘?’,
‘[SEP]’,
‘li’,
‘jin’,
‘##hong’,
‘is’,
‘a’,
‘programmer’,
‘[SEP]’]
- 屏蔽单词,将其转换为索引值 :使用标识符[MASK]代替输入文本中索引值为8的单词,并且将整个句子中的单词转成词表中的索引值。在BERT模型的训练过程中,会将输入文本的随机位置用[MASK]进行替换,并训练模型预测出[MASK]对应的值,这是BERT模型特有的一种训练方式。
# 定义掩码位置
masked_index=8
tokenizer_text[masked_index] = '[MASK]'
# 将标识转换为词汇表索引
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenizer_text)
# 将输入内容转换为pytorch张量。
tokens_tensor = torch.tensor([indexed_tokens])
print(tokens_tensor)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:
tensor([[ 101, 2040, 2003, 5622, 9743, 19991, 1029, 102, 103, 9743,
19991, 2003, 1037, 20273, 102]])
- 加载模型,对屏蔽单词进行预测
# 检查是否有GPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 这里可能会报错,大小不匹配,添加参数忽视尺寸匹配即可 # model = BertForMaskedLM.from_pretrained("./bert-base-uncased", ignore_mismatched_sizes=True) model = BertForMaskedLM.from_pretrained("./bert-base-uncased") # 该类可以对句子中的标识[MASK]进行预测 model.eval() model.to(device) # 标识;0对应第一个句子,1对应第二个句子。 segments_ids = [0,0,0,0,0,0,0,0,1,1,1,1,1,1,1] segments_tensors = torch.tensor([segments_ids]).to(device) tokens_tensor = tokens_tensor.to(device) # 将文本和句子指示参数输入模型进行预测。 with torch.no_grad(): outputs = model(tokens_tensor, token_type_ids = segments_tensors) predictions = outputs[0] # 预测索引值 predicted_index = torch.argmax(predictions[0, masked_index]).item() # 将其转换为单词 tokenizer.convert_ids_to_tokens([predicted_index])[0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4-5、用手动加载GPT-2模型权重的方式将句子补充完整
介绍:使用PreTrainedTokenizer类实现GPT-2模型。
import torch from transformers import GPT2Tokenizer, GPT2LMHeadModel # 加载预训练模型权重,这里依然使用手动下载的模型,下载方法详见4-N tokenizer = GPT2Tokenizer.from_pretrained("./gpt2") # 将文本进行转换,encode会一次性完成加特殊词标识、分词、转换成词向量索引这三步操作,得到的就是已经转化好的词向量索引。 indexed_token = tokenizer.encode("Who is Li Jinhong ? Li Jinhong is an ") # 转换为tensor tokens_tensor = torch.tensor([indexed_token]) # 加载预训练模型 model = GPT2LMHeadModel.from_pretrained("./gpt2") # 将模型设置为评估模式,这意味着模型不会在训练时更新权重,只会用来做推断。 model.eval() # 预测所有标识 # torch.no_grad():用于关闭梯度计算,因为在生成文本时不需要梯度。 with torch.no_grad(): # 将文本编码传递给模型,可以获得模型的输出。 outputs = model(tokens_tensor) # 模型的输出outputs包含多个元素,但我们主要关注其中的第一个元素predictions,它包含了模型对下一个词的预测。 predictions = outputs[0] # 得到预测的下一个词 # 这一部分代码通过选择具有最高概率的下一个词的索引,来获得模型的生成结果。 predicted_index = torch.argmax(predictions[0, -1, :]).item() # 最后,这行代码使用tokenizer的decode方法将模型生成的下一个词的索引转换为文本,并将其添加到原始文本的末尾,从而得到了最终的生成文本。 tokenizer.decode(indexed_token + [predicted_index])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
输出:(好家伙,我让你句子补全你给我直接输出一条直线让我填空!!!)
‘Who is Li Jinhong? Li Jinhong is an _____’
4-6、用迁移学习训练模型来对中文分类
迁移学习:迁移学习(Transfer Learning)是一种机器学习方法,其核心思想是将从一个任务或领域中学到的知识和经验应用到另一个相关任务或领域中,从而改善目标任务的性能。迁移学习的主要目标是提高目标任务的泛化能力,特别是在目标任务的训练数据有限或昂贵的情况下,以及在目标任务与源任务或领域之间存在某种程度的相关性时。以下是迁移学习的核心概念和要点:
- 源任务和目标任务:在迁移学习中,通常会涉及两个任务,一个是源任务(source task)或源领域(source domain),另一个是目标任务(target task)或目标领域(target domain)。源任务是已经训练好的任务,而目标任务是我们希望改善性能的任务。迁移学习的目标是通过源任务的知识来改进目标任务的性能。
- 相关性:关键的假设是源任务和目标任务之间存在某种相关性或共享的知识。这种相关性可以是任务之间的相似性,例如两个文本分类任务,或是领域之间的相似性,例如将从一种语言的数据迁移到另一种语言的数据。
- 知识传递:迁移学习的核心机制是知识传递,即将从源任务中学到的知识、模型参数、特征表示等应用到目标任务中。这可以通过多种方式实现,包括参数初始化、特征提取、模型微调等。
- 领域自适应:在某些情况下,源领域和目标领域之间的分布差异(领域差异)可能会导致迁移学习变得更加复杂。领域自适应是一种特殊的迁移学习方法,旨在减轻领域差异对性能的影响。
- 迁移策略:选择合适的迁移策略对于成功的迁移学习至关重要。迁移策略包括哪些层级的模型参数需要共享、如何共享、是否微调等决策。
- 监督和无监督迁移学习:迁移学习可以分为监督和无监督两种。监督迁移学习需要源任务和目标任务都有标注数据,而无监督迁移学习则在目标任务上缺少标签数据。
- 预训练模型:预训练语言模型(如BERT、GPT)已经成为NLP领域迁移学习的重要工具。这些模型在大规模文本数据上进行了预训练,然后可以微调到各种NLP任务中,从而提供了迁移学习的便捷方式。
4-N、如何手动下载模型
- 访问官网https://huggingface.co/models, 搜索我们想要的模型
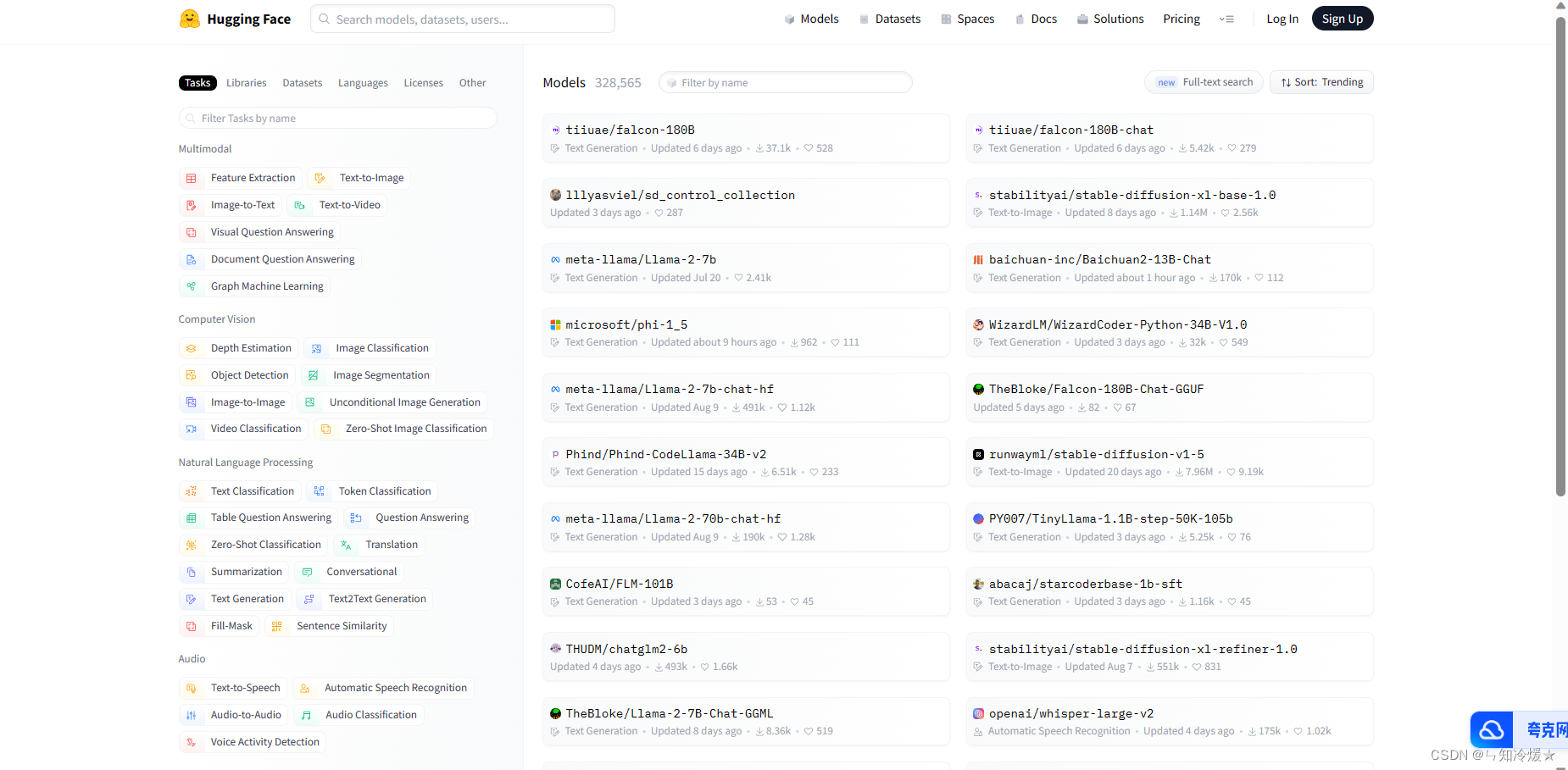
- 找到我们需要的文件(如果不知道下载哪个就全部下载)
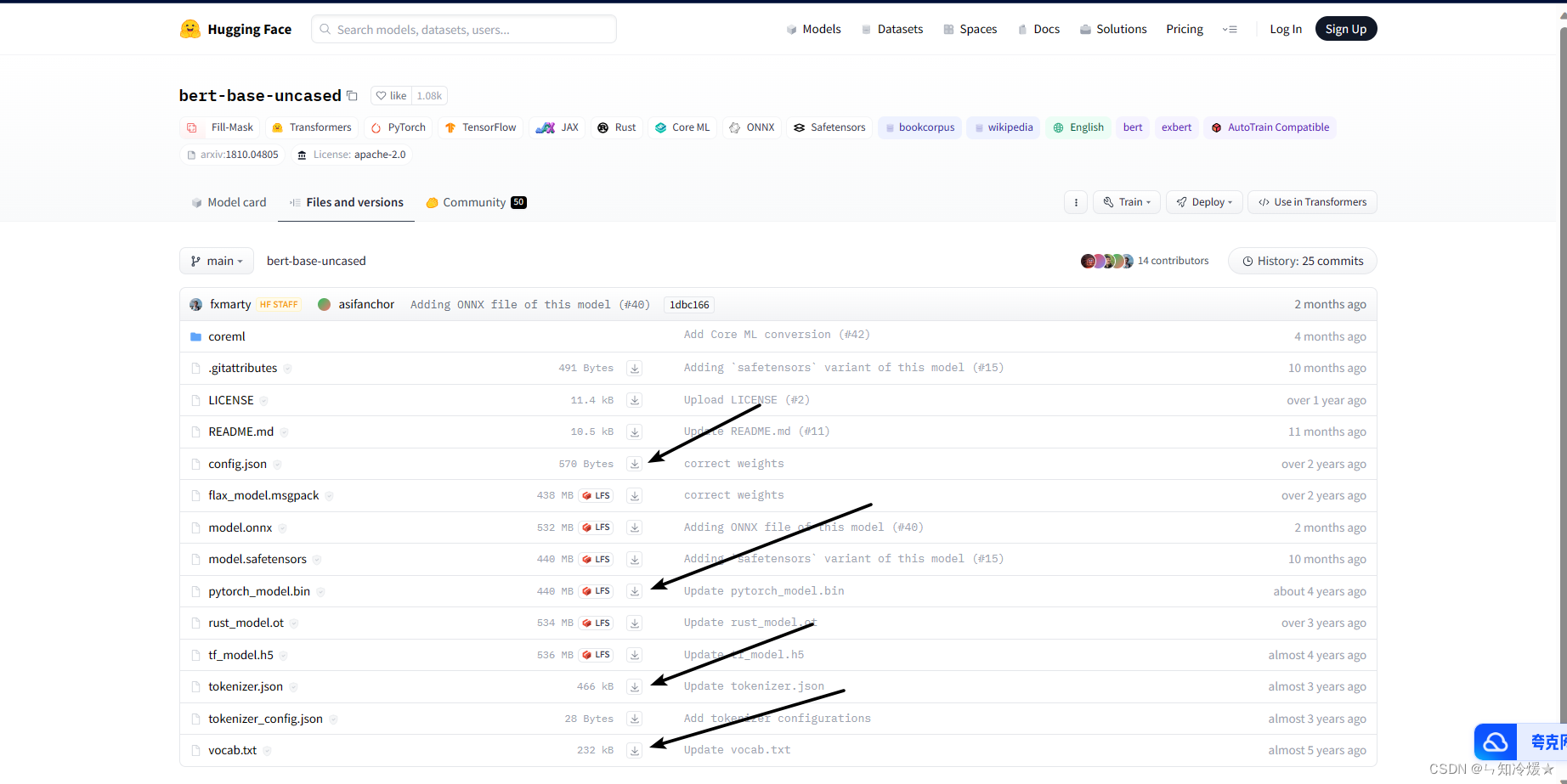
- 将这些文件放在指定文件夹内调用(我这里放置的文件夹是当前的bert-base-uncased文件夹内)
# 之后直接调用即可
from transformers import *
import torch
tokenizer = AutoTokenizer.from_pretrained("./bert-base-uncased")
text = "[CLS] who is Li Jinhong ? [SEP]"
tokenizer.tokenize(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
五、实战案例分析
5-1、Kaggle竞赛 Real or Not? NLP with Disaster Tweets 文本分类
5-1-1、数据介绍
数据来源于:kaggle竞赛- Natural Language Processing with Disaster Tweets
任务:我们需要根据文章的location、keyword以及文本text来判断这篇推文是否和灾难有关,相关部门可以据此来第一时间发现可能存在的灾难并且迅速做出反应,将损失降低到最低。
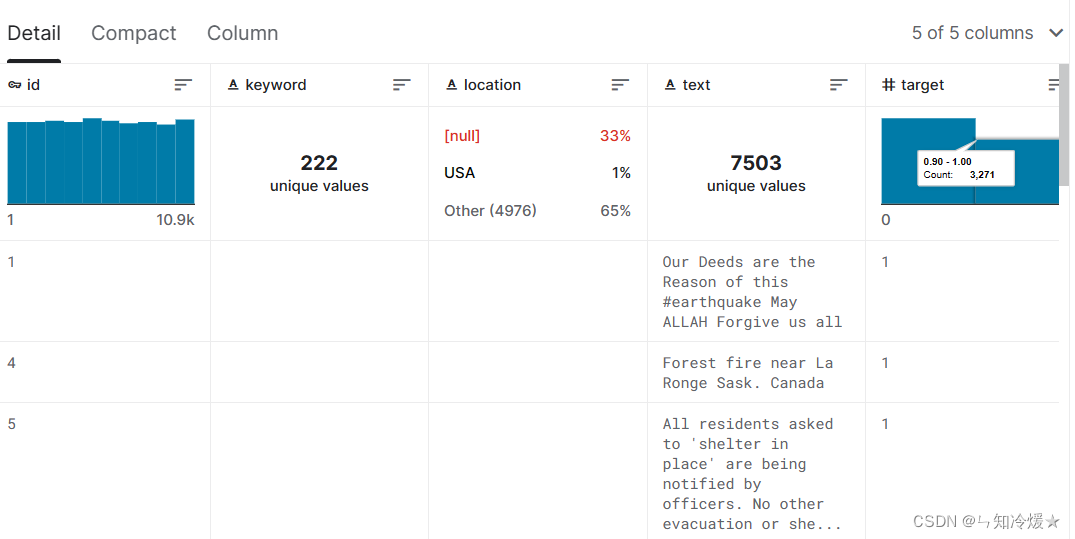
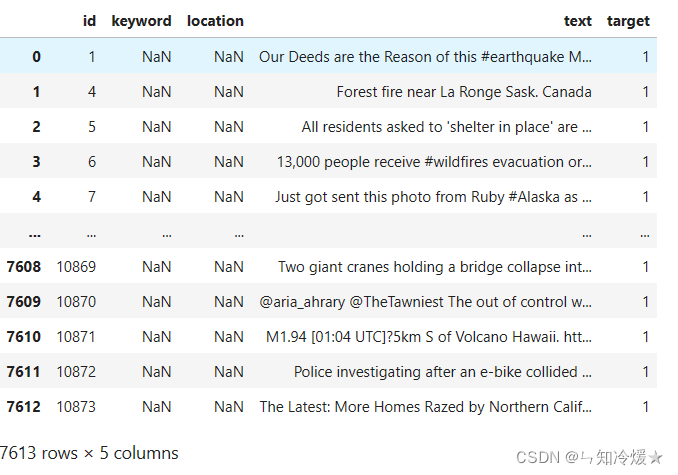
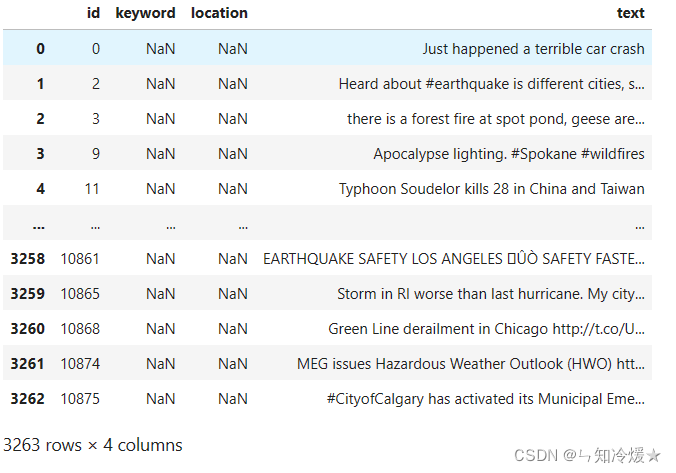
数据规模:Training Set Shape: (7613, 5); Test Set Shape: (3263, 4)
训练集:
验证集:
其他事项:根据数据分析得知
- location这一列缺失值较多,直接摒弃
- keyword这一列缺失值很少,根据数据分析得知,keyword与标签之间有可见的强相关性。
- 标签分布均匀,我们可以直接拿来训练模型
- 这里我们省略数据分析阶段,进入模型训练阶段,如果对完整过程感兴趣请查看我的另一篇文章Kaggle竞赛 Real or Not? NLP with Disaster Tweets 文本分类.
5-2、训练模型
处理final_text,返回编码后的ID串。
def encode_fn(text_list):
all_input_ids = []
for text in text_values:
input_ids = tokenizer.encode(text, add_special_tokens=True, max_length=180, pad_to_max_length=True, return_tensors='pt')
all_input_ids.append(input_ids)
all_input_ids = torch.cat(all_input_ids, dim=0)
return all_input_ids
- 1
- 2
- 3
- 4
- 5
- 6
- 7
划分数据为训练集和验证集
epochs = 4 batch_size = 32 # Split data into train and validation # 将数据转化为输入模型需要的数据类型 all_input_ids = encode_fn(text_values) labels = torch.tensor(labels) # TensorDataset是pytorch中的一个类,用于将多个张量打包成一个数据集,将输入数据张量和标签张量进行一一对应组合。 # 划分训练集和验证集 dataset = TensorDataset(all_input_ids, labels) train_size = int(0.90 * len(dataset)) val_size = len(dataset) - train_size train_dataset, val_dataset = random_split(dataset, [train_size, val_size]) # Create train and validation dataloaders train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
加载bert模型
# Load the pretrained BERT model
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2, output_attentions=False, output_hidden_states=False)
model.cuda()
# create optimizer and learning rate schedule
optimizer = AdamW(model.parameters(), lr=2e-5)
# len(train_dataloader),数据被分为N个批次,每个批次的数据长度是32
# total_steps
total_steps = len(train_dataloader) * epochs
# get_linear_schedule_with_warmup: 创建学习率调度器函数,
# get_linear_schedule_with_warmup函数在训练初期使用一种称为"warm-up"的策略,即在初始几个epoch中逐步增加学习率,以帮助模型更快地收敛到一个相对合适的参数范围。然后,在warm-up之后,学习率线性地减少或保持恒定。
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
准确率计算

from sklearn.metrics import f1_score, accuracy_score
def flat_accuracy(preds, labels):
"""A function for calculating accuracy scores"""
pred_flat = np.argmax(preds, axis=1).flatten()
# 将真实标签数组labels进行展平,得到一维的真实标签数组。
labels_flat = labels.flatten()
# 计算展平后的真实标签数组与预测结果数组之间的准确率
return accuracy_score(labels_flat, pred_flat)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
训练和验证
for epoch in range(epochs): model.train() total_loss, total_val_loss = 0, 0 total_eval_accuracy = 0 for step, batch in enumerate(train_dataloader): model.zero_grad() loss, logits = model(batch[0].to(device), token_type_ids=None, attention_mask=(batch[0]>0).to(device), labels=batch[1].to(device)) total_loss += loss.item() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() scheduler.step() model.eval() for i, batch in enumerate(val_dataloader): with torch.no_grad(): loss, logits = model(batch[0].to(device), token_type_ids=None, attention_mask=(batch[0]>0).to(device), labels=batch[1].to(device)) total_val_loss += loss.item() logits = logits.detach().cpu().numpy() label_ids = batch[1].to('cpu').numpy() total_eval_accuracy += flat_accuracy(logits, label_ids) avg_train_loss = total_loss / len(train_dataloader) avg_val_loss = total_val_loss / len(val_dataloader) avg_val_accuracy = total_eval_accuracy / len(val_dataloader) print(f'Train loss : {avg_train_loss}') print(f'Validation loss: {avg_val_loss}') print(f'Accuracy: {avg_val_accuracy:.2f}') print('\n')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
Train loss : 0.441781023875452
Validation loss: 0.34831519580135745
Accuracy: 0.86
Train loss : 0.3275374324204257
Validation loss: 0.3286557973672946
Accuracy: 0.88
Train loss : 0.2503694619696874
Validation loss: 0.355623895690466
Accuracy: 0.86
Train loss : 0.19663514375973207
Validation loss: 0.3806843503067891
Accuracy: 0.86
预测
# Create the test data loader text_values = df_test['final_text'].values all_input_ids = encode_fn(text_values) pred_data = TensorDataset(all_input_ids) pred_dataloader = DataLoader(pred_data, batch_size=batch_size, shuffle=False) model.eval() preds = [] for i, (batch,) in enumerate(pred_dataloader): with torch.no_grad(): outputs = model(batch.to(device), token_type_ids=None, attention_mask=(batch>0).to(device)) logits = outputs[0] logits = logits.detach().cpu().numpy() preds.append(logits) final_preds = np.concatenate(preds, axis=0) final_preds = np.argmax(final_preds, axis=1) # Create submission file submission = pd.DataFrame() submission['id'] = df_test['id'] submission['target'] = final_preds submission.to_csv('submission.csv', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
参考文章:
HuggingFaceg官方GitHub.
HuggingFace快速上手(以bert-base-chinese为例).
NLP各类任务.
EDA探索式数据分析.
pytorch+huggingface实现基于bert模型的文本分类(附代码).
HuggingFace简明教程.
huggingface transformers预训练模型如何下载至本地,并使用?.
hugging face 模型库的使用及加载 Bert 预训练模型.
总结
只想要快乐。

