
- 1添加作者_投稿后,你要临时加“作者”?别逗了……
- 2利用LSTM+CNN+glove词向量预训练模型进行微博评论情感分析(二分类)_glove lstm 情感分类
- 3鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Grid)_arkts grid
- 4安装pyrender和OSMesa(非常详细)从零基础入门到精通,看完这一篇就够了
- 5国内外各ChatGPT类语言大模型API价格汇总, 对比,ChatGPT/Gmini/PaLM/Clude/Ernie/ChatGLM/千问/混元/星火/Minimax/百川
- 6three-sum(3个数的和)_three sum
- 7神经网络:GRU基础学习
- 8NLP自然语言处理的基本语言任务介绍_nlp基础任务
- 9前端学习笔记____基础篇HTML&CSS_前端学习时,一个盒子上边时ul加li,下边是img,为社么给ul加padding-bottom没有效
- 10Pygame —— 一个好玩的游戏 Python 库_pygame库
并行文件系统风云再起,华为NFS+让大模型效率飞升_并行文件系统性能
赞
踩
导读:什么才是适配大模型高效训练推理的存储方案?
从2022年11月,OpenAI发布人工智能聊天机器人ChatGPT开始,生成式AI模型:AIGC(AI-Generated Content)迎来了爆发式增长。2023年,AI大模型的火爆还在继续。
外界的关注点更多在模型层面,各个公司、企业惊叹于大模型的智能化程度,并开始着手布局大模型。AI大模型作为连接技术生态和商业生态的桥梁,不断渗透至垂直领域,赋能千行百业快速发展。如此,形成了如今的“百模大战”,新的基础大模型不断涌现,各个场景领域的行业大模型也层出不穷。
实际上,一场更深维度的较量也同时拉开了帷幕,那就是围绕AI大模型的底层技术创新。
数据是AI的燃料。AI大模型的智能化需要依赖数据驱动,数据的规模和质量决定了AI智能的高度。大模型从拼模型到拼数据,数据规模将影响模型的效果。大模型时代,数据存储的价值从未像今天这样重要,存储已经成为影响大模型训练推理效率的关键突破口。面对大模型时代的存储挑战,创新者的脚步从未停止。

AI大模型时代,需要什么样的存储方案
AI大模型相比传统AI模型,在模型参数、数据集等方面截然不同,且表现出的智能化程度更高,一个模型能够完成以前多个模型完成的任务,在诸多考试方面甚至达到与人类持平。AI大模型已经从传统模型的单模态走向多模态,包含文本、图片、视频、音频等信息,这种变化带来了1000倍的数据增长,数据集规模达到PB级别,需要更大的存储空间;从大模型走向超大模型,从几百万参数,走向几亿、几十亿,发展到现在的千亿甚至万亿参数,需要更多的GPU计算资源。
在AI大模型底层的硬件基础设施中,相比备受关注的GPU计算资源,存储的价值往往被低估。实际上,存储与GPU计算性能、大模型训练效率密切相关。不妨先看一个很多企业都很关注的模型训练成本的例子。
大模型是相当烧钱的赛道。据悉微软Azure为ChatGPT构建了超过1万枚英伟达A100 GPU芯片的AI计算集群。ChatGPT一次完整的模型训练成本超过千万美元。可以说,在训练阶段对GPU资源的每分钟占用都是经费在燃烧。
如此巨大的算力消耗,同样需要有与之相匹配的存储底座,搭配强大的运力网络,才能充分发挥GPU资源,大大提高大模型的训练效率。如果存储做得不好,将直接影响AI大模型计算集群性能的充分发挥,造成成本的巨大浪费。
下图是AI大模型训练过程中一个训练周期的过程图解。shuffle代表将训练模型的数据集打乱,相当于“洗牌”,可以增强算法的鲁棒性,从而加快模型的训练速度。R1-RN代表对每一个batch size数据集的读取。C1-CN代表对每一个bacth size数据集的训练。黄色的wait_read代表GPU闲置等待时间。
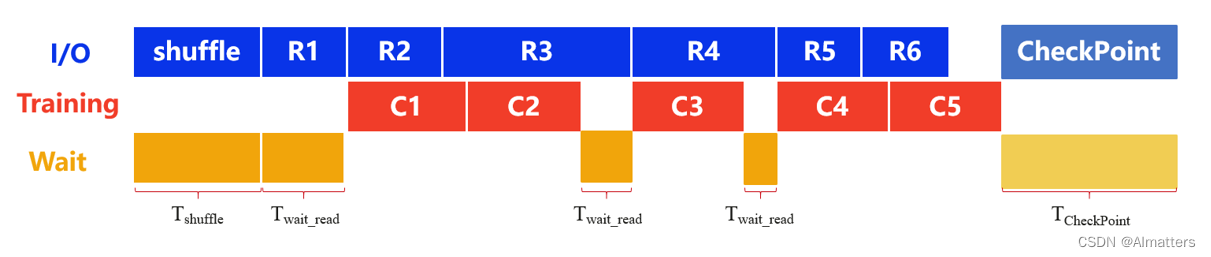
AI大模型训练时,采用数据预读取的方式进行,即边训练边读取,当GPU开始训练C1时,这时候可以预读取R2数据集。若存储性能足够强大,理想情况下每一个数据集的训练可以实现无缝衔接,即黄色的wait_read区域应该是不存在的。但实际情况往往并非如此,GPU会存在等待,以第一次出现的wait_read为例,由于存储对R3数据集的读取速度太慢,以至于GPU早已完成了对R2数据集的训练,但只能等存储读取完数据之后才能进行R3数据集的训练。
同理,强大的存储还能够缩短shuffle和CheckPoint保存的时间。为了应对在大模型训练过程中出现的GPU故障、网络故障、超参设置不合理等问题,需要定时保存CheckPoint,且保存CheckPoint时,GPU是需要停止训练的。CheckPoint是用来记录关键点的文件,类似于存储的“快照”功能,其功能是为了实现“断点续训”。时间就是金钱,GPU等待的每分每秒都是金钱在燃烧。
模型训练过程中存储与计算的交互特点可以总结为:以海量小文件读为主,涉及CheckPoint读写操作。也就是说,所有黄色的wait区域,存储都有大幅优化的空间,而IOPS和带宽成为存储性能的关键。鉴于大模型每分每秒都在烧钱,如果不重视存储,整个训练周期下来,黄色区域浪费掉的计算资源将会非常惊人。
这只是存储关键价值的一个典型场景。那么综合来看,AI大模型究竟需要什么样的存储?
第一,数据共享是多个分布式节点训练场景下的存储首要诉求。随着大模型的参数规模越来越大,往往需要几十上百个节点并发训练,若仍采用本地盘的形式,各节点缓存相同副本导致数据成本较高,且本地盘的可扩展性差,单节点SSD能力存在瓶颈,无法实现数据共享。此时,便对数据共享提出了强烈诉求,能够支持数据的高效流转。
第二,海量数据高并发处理能力是大模型时代存储的核心诉求之一。以GPT-4为例,其原始数据集规模已达PB级。AI大模型需要处理海量小文件训练样本,对应海量的元数据操作,同时也要兼顾大文件处理。服务器客户端与存储节点之间要具备高并发,us级低时延的能力。这些都需要存储具有并发访问的能力。
第三,强大的读写性能。在大模型训练阶段,对训练数据样本存储要读得快,对CheckPoint大文件保存也要写的快,将wait时长无限降低,尽可能减少GPU闲置等待时间,提升模型训练效率。这需要存储在大小文件场景下都能提供高性能。
第四,数据存储的高可靠、高安全要求。行业大模型中的数据属于私域数据,其独有的高安全、高可靠性属性且包含敏感信息,要求要有数据备份、远程复制等。CheckPoint是关键性文件,其保存同样需要高性能存储增加可靠性。保障模型训练的稳定性,就是省钱。
第五,向量数据库的快速检索、低时延要求。向量数据库可以一定程度上避免大模型幻觉,及时更新最新的新闻数据等,加强对私域数据的保护。向量数据库是对共有数据集和行业数据集的向量化,由此生成的数据库,可以部署在推理侧,大大加快模型的推理速度。因此,同样需要高性能存储保存向量数据库,加快检索速度。
根据以上这些核心诉求,什么才是适配AI大模型时代的存储,答案已经非常清晰:高性能高可靠的并行文件存储。
并行文件存储支持使用多个 IO 路径将数据读/写到多个存储设备,同时可横向扩展容纳PB级数据,并支持高带宽,天然适配AI大模型对存储的要求。

并行文件系统江湖风云再起,华为NFS+崭露头角
并行文件系统诞生至今已经有20多年的历史。目前市场上主流的并行文件系统有Lustre、GPFS、NFS等,每种技术路线都有其特点和适用场景。
Lustre 与GPFS都是应用非常广泛的并行文件系统,在石油勘探、卫星遥感、气象预测等超大规模高性能计算场景下有广泛应用。两者都具有按需扩展容量和性能的能力,其容量可扩容到PB级别。
总体来看,Lustre和GPFS的优势在于,通过对底层存储资源池化,以及元数据服务器MDS等底层设计,实现计算节点跟存储之间N对N多条链路访问,从而保证存储系统的高性能、高扩展。但是,由于所有数据都要经由元数据服务器MDS进行交互会话,尤其当面临AI大模型这种海量数据高性能处理需求时,可能会出现单点的性能与可靠性的瓶颈。而且,Lustre与GPFS已经较长时间没有大的更新,难以适配AI时代新的存储需求。
这就导致在主流方案之外,业界其实也在期待更能够满足AI大模型训练需求的高性能文件存储方案。

不妨来看看华为的解题思路。华为OceanStor Dorado NAS是公认的高性能文件存储,其内置的OceanFS创新分布式文件系统具备极高的性能和可靠性设计,小文件性能领先业界30%,大文件场景领先业界50%。
今年,华为OceanStor Dorado 全闪存NAS,在OceanFS高性能的基础上,联合openEuler发布全新NFS+协议,打造了更高性能的并行文件系统,向AI场景发力。NFS+协议是华为自研的并行文件访问客户端,既可以实现计算节点跟存储节点之间多条链路访问,又规避了元数据服务器MDS可能带来的性能与可靠性瓶颈,实现高可靠、高性能、易运维的并行文件存储体验。
为什么华为OceanStor Dorado NAS全闪存叠加NFS+后,更能满足AI大模型时代对存储的需求,将为企业带来哪些价值?
架构领先,华为NFS+为AI存储而生
一种新的技术路径是否实现了真正的创新,往往体现在底层架构层面。
相比已有的并行文件系统,华为NFS+在架构层面做了突破与创新:不再设立元数据服务器MDS这样的架构单元,从而规避了MDS在性能和可靠性方面的瓶颈,元数据不再聚焦于某一个存储节点,而是通过分布式文件系统将目录文件均衡打散到集群,在主机侧和存储侧都实现多链路访问,从架构上保证了存储系统的高性能、高可靠。
此外,相对于Lustre与GPFS复杂的管理门槛,华为NFS+内置于openEuler操作系统,不修改操作系统数据面,对主机CPU资源无占用,仅在控制面新增多路径功能,屏蔽了管理的复杂性。
具体到AI大模型训练场景中,华为NFS+可以为企业带来四大技术优势:
高性能
华为NFS+通过多IP聚合,实现主机侧与存储侧之间多链路访问通道,支持多条 IP通道轮询。服务器客户端与每个存储控制器节点间RDMA全互联、高并发链接,实现极致时延,IO平衡,不存在访问热点问题。在大模型训练场景中,华为NFS+智能均衡的特性,可实现无跨核跨控开销,将GPU计算资源最大程度发挥出来。通过性能测试,华为NFS+可实现小文件比业界性能高30%,大文件带宽高出40%,带宽密集型业务性能高出50%。
高可靠
华为NFS+通过多路径设计,可以实现软硬件故障秒级自动切换。存储系统的软硬件故障将直接导致大模型训练故障和重启。以原生NFS协议为例,单一链路的IO 路径上一旦出现软硬件故障,该IO将被挂起,即使通过切换IP地址更换存储节点,也不可避免地导致IO短暂归零。华为NFS+的多链路设计为软硬件故障提供了充足的冗余空间,可实现故障秒级自动切换链路,实现对业务无影响。
缓存优化
华为NFS+推出了面向海量小文件场景设计的元数据灵活布局和多级缓存技术。通过增大主机侧缓存大小、延长缓存失效时间,华为NFS+扩大了计算侧处理元数据的缓存容量,降低了元数据读取带宽压力。通过元数据智能预取与淘汰算法,大大提升了缓存和预取效率,从而提升模型训练效率。
低时延
华为NFS+支持Storage 数据视图,为数据访问提供最优链路,降低时延。华为NFS+采用元数据顺序表布局,可以大幅提高文件定位速度。客户端感知文件所在存储控制器节点位置,直接与对应节点高效放置和访问数据,保障极致时延。根据性能测试,数据视图方式可将训练样本小IO随机读性能提升4倍以上,将CheckPoint大文件切片+多路径传输提升4-6倍带宽能力。
大模型时代,在相同计算资源投入下,如何提升AI大模型训练效率、降低成本成为企业致胜的关键。在文件存储领域,华为NFS+从场景出发,敢于探索架构创新,为解决大模型时代存储瓶颈提供了全新的思路与解决方案,将助力提升生成式AI产业的创新效率。
文中图片来自摄图网
END
本文为「智能进化论」原创作品。

