
This article talks about the concept of adversarial examples as applied to NLP (natural language processing). The terminology can be confusing at times, so we’ll begin with an overview of the language used to talk about adversarial examples and adversarial attacks. Then, we’ll talk about TextAttack, our open-source Python library for adversarial examples, data augmentation, and adversarial training in NLP that’s changing the way people research the robustness of NLP models. We’ll conclude with some thoughts on the future of this area of research.
本文讨论了应用于NLP(自然语言处理)的对抗性示例的概念。 术语有时可能会引起混淆,因此我们将首先概述用于谈论对抗性示例和对抗性攻击的语言。 然后,我们将讨论TextAttack ,这是我们用于NLP中对抗性示例,数据增强和对抗性训练的开源Python库,它正在改变人们研究NLP模型的鲁棒性的方式。 我们将对这个研究领域的未来进行一些思考。
术语 (Terminology)
An adversarial example is an input designed to fool a machine learning model [1]. An adversarial example crafted as a change to a benign input is known as an adversarial perturbation. ‘Adversarial perturbation’ is more specific than just ‘adversarial example’, as the class of all adversarial examples also includes inputs designed from scratch to fool machine learning models. TextAttack attacks generate a specific kind of adversarial examples, adversarial perturbations.
一个对抗性的例子是设计用来欺骗机器学习模型的输入[1]。 对抗良性输入的对抗例子被称为对抗扰动 。 “对抗性摄动”比“对抗性示例”更为具体,因为所有对抗性示例的类别还包括从头设计到傻瓜式机器学习模型的输入。 TextAttack攻击会生成一种特殊的对抗示例,即对抗扰动。
An adversarial attack on a machine learning model is a process for generating adversarial perturbations. TextAttack attacks iterate through a dataset (list of inputs to a model), and for each correctly predicted sample, search for an adversarial perturbation. If an example is incorrectly predicted to begin with, it is not attacked, since the input already fools the model. TextAttack breaks the attack process up into stages and provides a system of interchangeable components for managing each stage of the attack.
对机器学习模型的对抗攻击是一种产生对抗性扰动的过程。 TextAttack攻击通过数据集(模型的输入列表)进行迭代,并为每个正确预测的样本搜索对抗性扰动。 如果一个示例被错误地预测为开始,则该示例不会受到攻击,因为输入已经使模型蒙蔽了。 TextAttack将攻击过程分为多个阶段,并提供了一个可互换组件的系统来管理攻击的每个阶段。
Adversarial robustness is a measurement of a model’s susceptibility to adversarial examples. TextAttack often measures robustness using attack success rate, the percentage of attack attempts that produce successful adversarial examples, or after-attack accuracy, the percentage of inputs that are both correctly classified and unsuccessfully attacked.
对抗性鲁棒性是对模型对对抗性示例敏感性的度量。 TextAttack通常使用攻击成功率 ,产生成功对抗示例的攻击尝试百分比或攻击后准确性 ,正确分类且未成功攻击的输入百分比来衡量鲁棒性。
To improve our numeracy for talking about adversarial attacks, let’s take a look at a concrete example:
为了提高我们讨论对抗性攻击的能力,让我们看一个具体的例子:

This attack was run on 200 examples. Out of those 200, the model initially predicted 43 of them incorrectly; this leads to an accuracy of 157/200 or 78.5%. TextAttack ran the adversarial attack process on the remaining 157 examples to try to find a valid adversarial perturbation for each one. Out of those 157, 29 attacks failed, leading to a success rate of 128/157 or 81.5%. Another way to articulate this is that the model correctly predicted the original sample and then resisted adversarial attack for 29 out of 200 total samples, leading to an accuracy under attack (or “after-attack accuracy”) of 29/200 or 14.5%.
此攻击在200个示例上运行。 在最初的200个中,模型最初错误地预测了其中的43个; 这导致精度为157/200或78.5%。 TextAttack对其余157个示例进行了对抗攻击过程,以尝试为每个示例找到有效的对抗扰动。 在这157个攻击中,有29个攻击失败,成功率为128/157或81.5%。 另一种表达方式是,该模型可以正确预测原始样本,然后抵抗200个样本中的29个进行对抗攻击,从而使攻击下的准确性(或“攻击后准确性”)为29/200或14.5%。
TextAttack also logged some other helpful statistics for this attack. Among the 157 successful attacks, on average, the attack changed 15.5% of words to alter the prediction, and made 32.7 queries to find a successful perturbation. Across all 200 inputs, the average number of words was 18.97.
TextAttack还记录了此攻击的其他有用统计信息。 在157次成功的攻击中,平均而言,该攻击改变了单词的15.5%来更改预测,并进行了32.7次查询以找到成功的扰动。 在所有200个输入中,平均单词数为18.97。
Now that we have provided some terminology, let’s look at some concrete examples of proposed adversarial attacks. We will give some background on adversarial attacks in other domains and then examples of different attacks in NLP.
现在,我们已经提供了一些术语,让我们来看一些提议的对抗性攻击的具体例子。 我们将提供有关其他领域的对抗性攻击的一些背景知识,然后是NLP中不同攻击的示例。
对抗性例子 (Adversarial examples)
Research in 2013 [2] showed neural networks are vulnerable to adversarial examples. These original adversarial attacks apply a small, well-chosen perturbation to an image to fool an image classifier. In this example, the classifier correctly predicts the original image to be a pig. After a small perturbation, however, the classifier predicts the pig to be an airliner (with extremely high confidence!).
2013年的研究[2]表明神经网络容易受到对抗性例子的攻击。 这些原始的对抗性攻击对图像施加了精心选择的小扰动,以欺骗图像分类器。 在此示例中,分类器正确地预测原始图像为猪。 但是,经过一小段扰动后,分类器会预测这头猪是一架客机(具有极高的置信度!)。
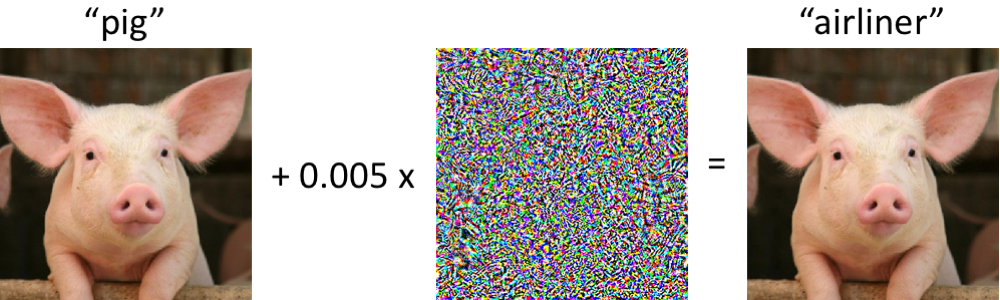
These adversarial examples exhibit a serious security flaw in deep neural networks. Therefore, adversarial examples pose a security problem for all downstream systems that include neural networks, including text-to-speech systems and self-driving cars. Adversarial examples are useful outside of security: researchers have used adversarial examples to improve and interpret deep learning models.
这些对抗性示例在深度神经网络中显示出严重的安全漏洞。 因此,对抗性示例对包括神经网络的所有下游系统(包括文本到语音系统和自动驾驶汽车)提出了安全问题。 对抗性示例在安全性之外很有用:研究人员已使用对抗性示例来改进和解释深度学习模型。
As you might imagine, adversarial examples in deep neural networks have caught the attention of many researchers around the world. Their discovery in 2013 spawned an explosion of research into the topic.
就像您想象的那样,深度神经网络中的对抗性示例吸引了全世界许多研究人员的注意。 他们在2013年的发现催生了对该主题的大量研究。
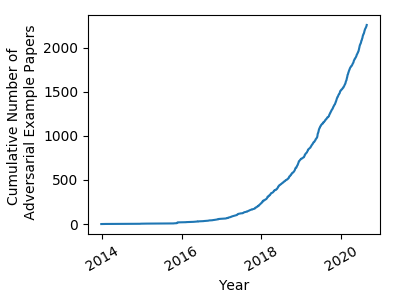
Many new, more sophisticated adversarial attacks have been proposed, along with defenses, procedures for training neural networks that are resistant (robust) against adversarial attacks. Training deep neural networks that are highly accurate while remaining robust to adversarial attacks remains an open problem [3].
许多新的,更复杂的攻击对抗,已经提出抗辩 ,训练神经网络有抗药性( 稳健 )对敌对攻击程序一起。 训练高度准确的深度神经网络,同时保持强大的对抗性攻击仍然是一个悬而未决的问题[3]。
Naturally, many have wondered about what adversarial examples for NLP models might be. No natural analogy to the adversarial examples in computer vision (such as the pig-to-airliner bamboozle above) exists for NLP. In the above example, the pig-classified input and its airliner-classified perturbation are literally indistinguishable to the human eye. Unlike images, two sequences of text cannot be truly indistinguishable without being the same.
自然,许多人想知道NLP模型的对抗示例是什么。 对于NLP,不存在与计算机视觉中的对抗性示例(例如上面的“猪到客机竹编”)自然相类的例子。 在上面的示例中,猪的输入及其班机的扰动在肉眼上几乎是无法区分的。 与图像不同,两个文本序列如果不相同,就无法真正区分 。
NLP中的对抗示例 (Adversarial Examples in NLP)
Because two text sequences are never indistinguishable, researchers have proposed various alternative definitions for adversarial examples in NLP. We find it useful to group adversarial attacks based on their chosen definitions of adversarial examples.
由于两个文本序列永远都无法区分,因此研究人员针对NLP中的对抗性示例提出了各种替代定义。 我们发现根据选择的对抗性示例定义将对抗性攻击分组非常有用。
Although attacks in NLP cannot find an adversarial perturbation that is literally indistinguishable to the original input, they can find a perturbation that is very similar. Our mental model groups NLP adversarial attacks into two groups, based on their notions of ‘similarity’:
尽管NLP中的攻击无法找到与原始输入几乎无法区分的对抗性扰动,但他们可以找到非常相似的扰动。 我们的心理模型根据他们的“相似性”概念将NLP对抗性攻击分为两类:

Visual similarity. Some NLP attacks consider an adversarial example to be a text sequence that looks very similar to the original input — perhaps just a few character changes away — but receives a different prediction from the model. Some of these adversarial attacks try to change as few characters as possible to change the model’s prediction; others try to introduce realistic ‘typos’ similar to those that humans would make.
视觉相似度。 一些NLP攻击将一个对抗示例视为一个文本序列,该文本序列看起来与原始输入非常相似(也许只是几个字符变化了),但收到的预测与模型不同。 其中一些对抗性攻击试图更改尽可能少的字符,以更改模型的预测。 其他人则试图引入与人类类似的现实“错别字”。
Some researchers have raised concern that these attacks can be defended against quite effectively, either by using a rule-based spellchecker or a sequence-to-sequence model trained to correct adversarial typos.
一些研究人员提出了一种担忧,即通过使用基于规则的拼写检查器或训练为纠正对抗性拼写错误的序列到序列模型,可以非常有效地防御这些攻击。
TextAttack attack recipes that fall under this category: deepwordbug, hotflip, pruthi, textbugger*, morpheus
属于此类别的TextAttack攻击配方: Deepwordbug,hotflip,pruthi,textbugger *,morpheus
Semantic similarity. Other NLP attacks consider an adversarial example valid if it is semantically indistinguishable from the original input. In other words, if the perturbation is a paraphrase of the original input, but the input and perturbation receive different predictions, then the input is a valid adversarial example.
语义相似度。 如果在语义上无法与原始输入区分开来,则其他NLP攻击都将其视为对抗性示例有效。 换句话说,如果扰动是原始输入的释义,但是输入和扰动接收到不同的预测,则输入是有效的对抗性示例。
Some NLP models are trained to measure semantic similarity. Adversarial attacks based on the notion of semantic similarity typically use another NLP model to enforce that perturbations are grammatically valid and semantically similar to the original input.
一些NLP模型经过训练可以测量语义相似度。 基于语义相似性概念的对抗攻击通常使用另一个NLP模型来强制扰动在语法上有效,并且在语义上与原始输入类似。
TextAttack attack recipes that fall under this category: alzantot, bae, bert-attack, faster-alzantot, iga, kuleshov, pso, pwws, textbugger*, textfooler
属于以下类别的TextAttack攻击配方: Alzantot,bae,bert-attack,faster-alzantot,iga,kuleshov,pso,pwws,textbugger *,textfooler
*The TextBugger attack generates perturbations using both typo-like character edits and synonym substitutions. It could be considered to use both definitions of indistinguishability.
* TextBugger攻击使用类似错字的字符编辑和同义词替换产生干扰。 可以考虑使用两种不可区分的定义。
使用TextAttack生成对抗性示例 (Generating adversarial examples with TextAttack)
TextAttack supports adversarial attacks based in both definitions of indistinguishability. Both types of attacks are useful for training more robust NLP models. Our goal is to enable research into adversarial examples in NLP by providing a set of intuitive, reusable components for building as many attacks from the literature as possible.
TextAttack支持基于两种不可区分性的对抗性攻击。 两种类型的攻击都可用于训练更强大的NLP模型。 我们的目标是通过提供一组直观,可重用的组件来研究NLP中的对抗性示例,以从文献中构建尽可能多的攻击。
We define the adversarial attack processing using four components: a goal function, constraints, transformation, and search method. (We’ll go into this in detail in a future post!) These components allow us to reuse many things between attacks from different research papers. They also make it easy to develop methods for NLP data augmentation.
我们使用四个组件来定义对抗攻击处理:目标函数,约束,变换和搜索方法。 (我们将在以后的文章中对此进行详细介绍!)这些组件使我们能够在不同研究论文的攻击之间重用许多东西。 它们还使开发NLP数据增强方法变得容易。
TextAttack also includes code for loading popular NLP datasets and training models on them. By integrating this training code with adversarial attacks and data augmentation techniques, TextAttack provides an environment for researchers to test adversarial training in many different scenarios.
TextAttack还包括用于加载流行的NLP数据集和训练模型的代码。 通过将训练代码与对抗性攻击和数据增强技术集成在一起,TextAttack为研究人员提供了一个环境,可以在许多不同的情况下测试对抗性训练。
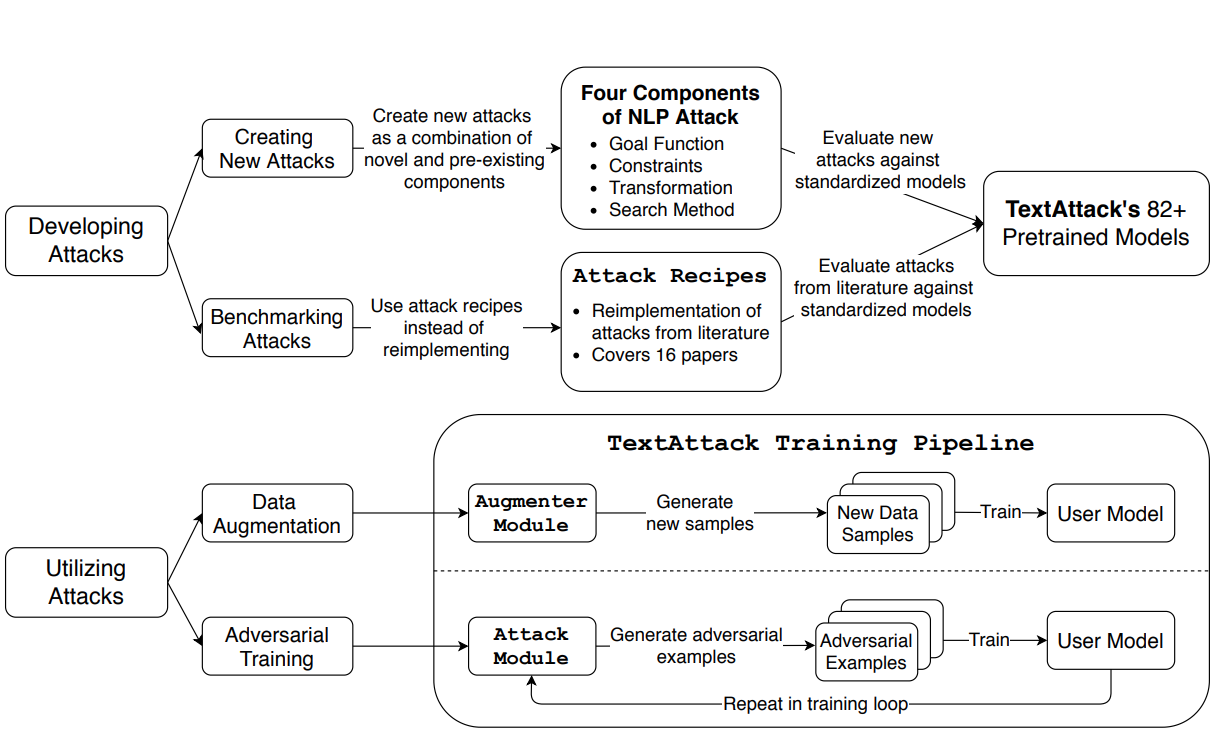
The following figure shows an overview of the main functionality of TextAttack:
下图概述了TextAttack的主要功能:
NLP中对抗性攻击的未来 (The future of adversarial attacks in NLP)
We are excited to see the impact that TextAttack has on the NLP research community! One thing we would like to see research in is the combination of components from various papers. TextAttack makes it easy to run ablation studies to compare the effects of swapping out, say, search method from paper A with the search method from paper B, without making any other changes. (And these tests can be run across dozens of pre-trained models and datasets with no downloads!)
我们很高兴看到TextAttack对NLP研究社区的影响! 我们希望看到的一件事是各种论文的组成部分的组合。 使用TextAttack可以轻松进行消融研究,以比较换出例如纸张A的搜索方法和纸张B的搜索方法的效果,而无需进行任何其他更改。 (并且这些测试可以在数十个经过预先训练的模型和数据集中运行,而无需下载!)
We hope that use of TextAttack leads to more diversity in adversarial attacks. One thing that all current adversarial attacks have in common is that they make substitutions on the word or character level. We hope that future adversarial attacks in NLP can broaden scope to try different approaches to phrase-level replacements as well as full-sentence paraphrases. Additionally, there has been a focus on English in the adversarial attack literature; we look forward to seeing adversarial attacks applied to more languages.
我们希望使用TextAttack可以在对抗性攻击中带来更多多样性。 当前所有对抗性攻击的共同点是,它们在单词或字符级别进行替换。 我们希望NLP未来的对抗性攻击能够扩大范围,以尝试使用不同的方法来替换短语和全句释义。 此外,在对抗性攻击文献中,英语也得到了关注。 我们期待看到对抗性攻击应用于更多语言。
If you are interested in TextAttack, or the broader problem of generating adversarial examples for NLP models, please get in touch! You might have a look at our paper on ArXiv or our repository on Github.
如果您对TextAttack感兴趣,或者对为NLP模型生成对抗示例更广泛的问题感兴趣,请联系! 您可以看看我们在ArXiv上的论文或我们在Github 上 的存储库 。
[1] “Attacking Machine Learning with Adversarial Examples”, Goodfellow, 2013. [https://openai.com/blog/adversarial-example-research/]
[1]“使用对抗性示例攻击机器学习”,Goodfellow,2013年。[ https://openai.com/blog/adversarial-example-research/ ]
[2] “Intriguing properties of neural networks”, Szegedy, 2013. [https://arxiv.org/abs/1312.6199]
[2]“神经网络的有趣特性”,塞格迪,2013年。[ https://arxiv.org/abs/1312.6199 ]
[3] “Robustness May Be at Odds with Accuracy”, Tsipras, 2018. [https://arxiv.org/abs/1805.12152]
[3]“稳健性可能成正比”,齐普拉斯,2018年。[ https://arxiv.org/abs/1805.12152 ]
翻译自: https://towardsdatascience.com/what-are-adversarial-examples-in-nlp-f928c574478e

