
- 1【深度学习】LSTM实现情感分析 (Pytorch)_test.ft.txt.bz2
- 2PyTorch实战气温预测_神经网络温度预测数据
- 3强化学习中的actorcritic优化
- 4FAIR 何恺明、Piotr、Ross等新作,MAE才是YYDS!仅用ImageNet1K,Top-1准确率87.8%!
- 5得物社区推荐精排模型演进_得物社区推荐技术
- 6处理文本数据(scikit-learn 教程3)_count_vect.vocabulary_.get(u'algorithm')
- 7数据结构--二叉树_#include 二叉树
- 8一文整理深度学习【医学图像处理领域期刊和会议】_医学图像sci期刊和会议csdn
- 9分布式数字身份DID简介(一)基本概念_did数字身份
- 10Docker Compose Scale网络、水平扩展与负载均衡_docker compose headscale
综述:弱监督下的异常检测算法
赞
踩
一、前言
文章标题是: Weakly Supervised Anomaly Detection: A Survey
这是一篇针对“弱监督”异常检测的综述。 其中弱监督异常检测 简称为 WSAD
论文链接:https://arxiv.org/abs/2302.04549
代码链接:https://github.com/yzhao062/wsad
二、问题
针对异常检测问题,其实面临的挑战和问题基本上比较一致。
数据的极度不平衡(异常和非异常的样本比例)
有限的标签数据(2.1 标签不准 2.2 获取标签浪费很大的人力物力)
场景非常广泛(数据类型很多):tabular, time-series, image and video, and graph data
本文主要从标签角度,来阐述弱监督情况下的异常检测问题,大多异常检测都采用非监督方法(最常见的就是去编码高级特征,重新生成数据,进行对比,得到异常),而对于监督方法来说,就是存在标签,但标签的质量很难保障。
所以本文从三个角度来分类:
incomplete supervision: 标签不完成的情况,主要指很多样本没有标签(这种在实际环境下,还是蛮常见的一种情况),一些存在标签,另外一些因为某些原因(比如传感器失灵)等不存在标签。
inexact supervision:: 标签不准确的情况,主要指粗粒度的异常,即更高维度的异常是被标识的,但细粒度没有(举例:1. 一个视频是异常的,但不知道视频哪几帧是异常的, 2. 知道哪几个机器实体是异常的,但不知道具体机器的哪些指标异常)
inaccurate supervision: 标签不精确的情况,主要指标签本身不精确,样本都存在细粒度标签,但标签本不准确,有一些噪声或者误差。
本文非常大的贡献,在于把近几年针对弱监督异常检测的论文进行整合,且进行以上三种类别的分类,对于想进一步了解这个方面的同学来说,可以更近一步的去寻找更合适的论文阅读。
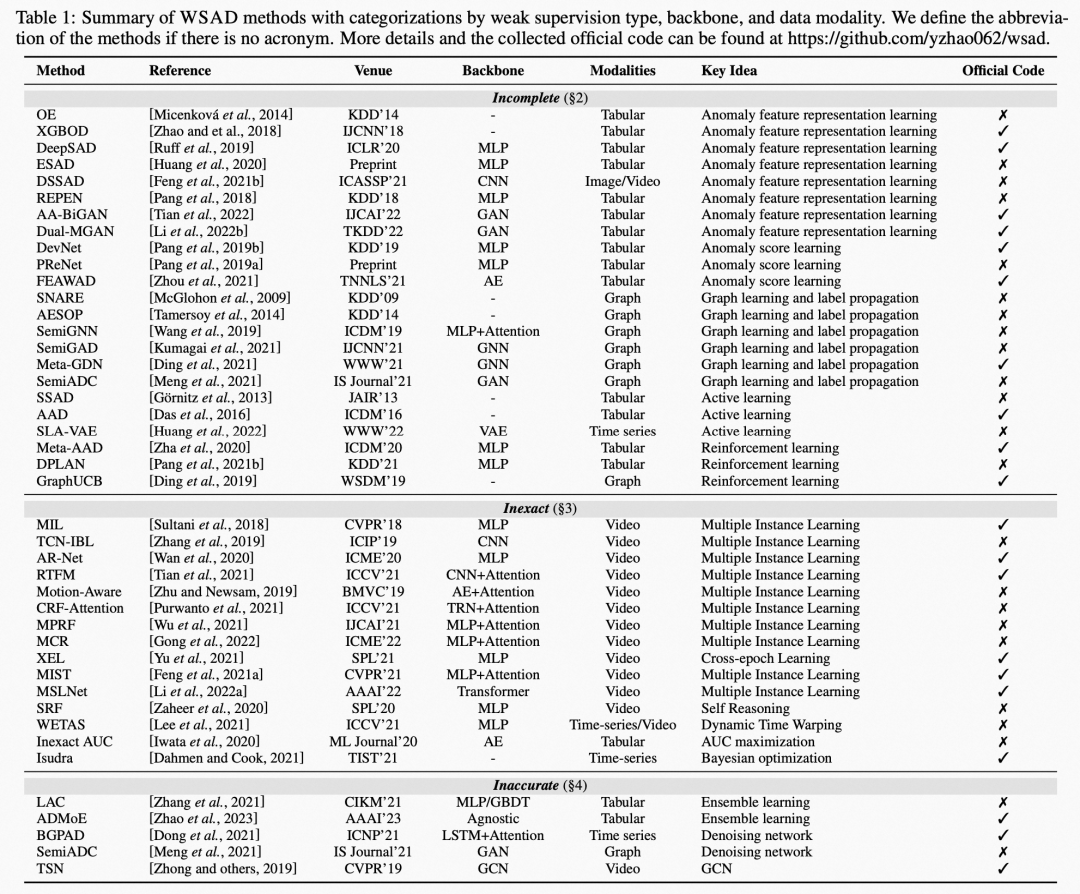
三、Incomplete Supervision
3.1 场景
举例:获取完整的信用卡欺诈标签集,要求手动标注所有正常和异常交易,这往往耗时且成本高。
3.2 方法
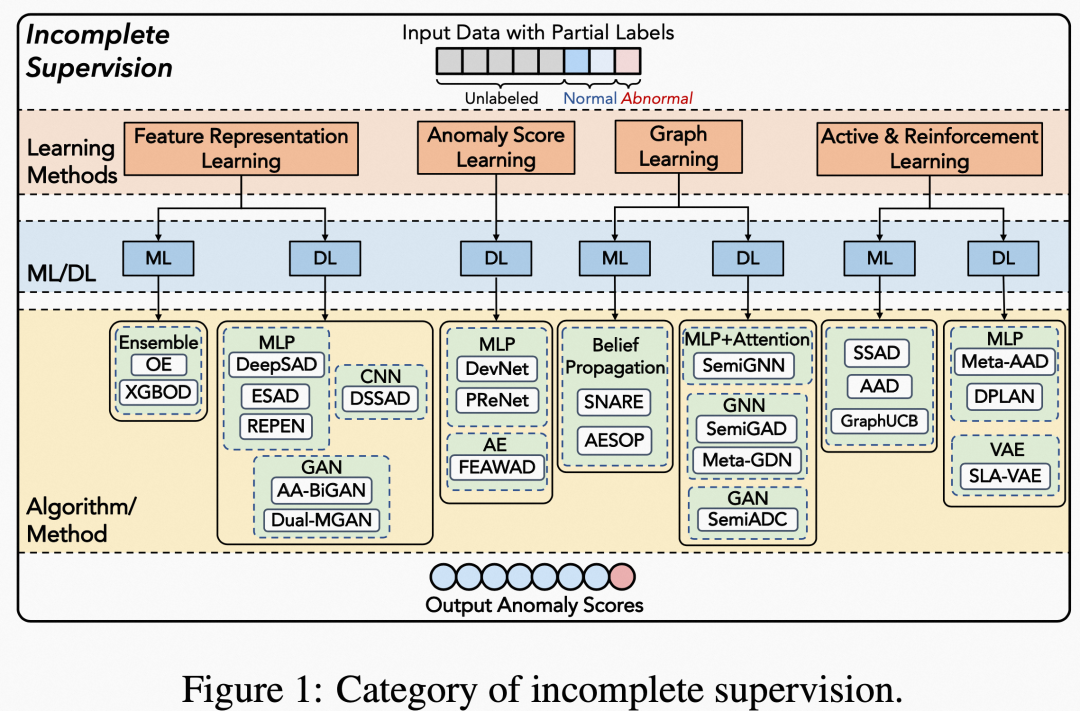
这张图可以说非常清晰了,从这个分类的方法的再一次分类,以及属于机器学习还是深度学习,以及属于的base方法是该学习方法中的什么分类,全都清晰的展示。
Anomaly feature representation learning
这个方法主要由unsupervised representation learning得来,通过学习feature的embedding来区别异常与否,对于监督情况,通过可获得的部分监督信息来改善这个学习方法。
在这里可以将无监督表示学习的帮助视为对标签不完整性的补偿。比如XGBOD就是用几个无监督方法作为特征提取器,最终通过监督模型学习,而针对深度学习的方法,大多主要将特征提取部分换为神经网络,也有一些网络是端到端的结构,来学习异常和非异常的分布,带有标签的作为加强。
其中有一个蛮有意思的点: [Feng et al., 2021b] 提出了通过计算有标签和无标签样本的harmonious loss来提升效果。
Anomaly Score Learning
顾名思义,模型直接输出异常的分数,并随着分数的增加,异常情况越强。
主要的模型是DevNet,它首先假设正常数据的异常分数具有高斯先验,用正常的样本生成一些正常的分数分布,通过deviation loss使带有异常标签样本的分数在整体样本分数的分布下偏离(本意还是让异常样本得到的分数在正常样本分数分布中是一个离群点)。
后续的PReNet、DAGMM等都是在DevNet基础上优化,添加新的思想。
Graph learning via label propagation
对于图数据来说,考虑数据中的固有连接,以相应地传播部分标签信息。主要是GNN和GCN,以及和GAN的结合。
Active learning and reinforcement learning.
这个部分的方法,主要是想通过利用active learning方法,不断的循环往复的去更新模型。
比如 SLA-VAE是一种用于多变量时间序列异常检测的VAE方法。它首先使用半监督VAE来识别异常,然后使用主动学习来用一小组不确定样本更新现有模型。
对于强化学习,通常将异常检测器作为agent,将当前实例的特征作为状态,将标记决策作为动作,将采样策略作为状态转换,将异常作为奖励。
3.3 将来一些思考
最好还是来把没打标的打上标签,可以通过人力,或者active learning。
引入 few shot/meta leaning
从样本角度来解决问题,样本不平衡(这个不光是incomplete supervision, 其他都存在), loss参数学习:
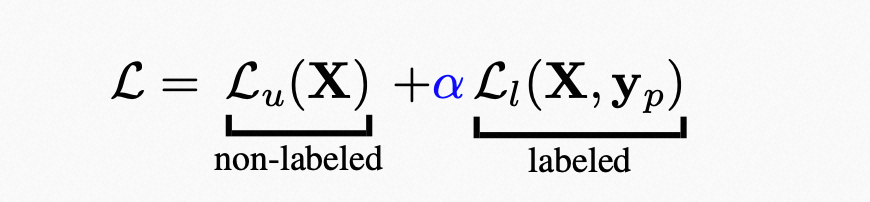 4. 模型选择和超参
4. 模型选择和超参
四、Inexact Supervision
4.1 场景
公司可以获得用户级异常标签。这些用户级别标签仅表明用户是否参与了欺诈等非法活动,而我们应该更感兴趣的是用户的哪些交易是异常的。(用户是否异常是粗粒度, 哪个交易异常是细粒度)
4.2 方法
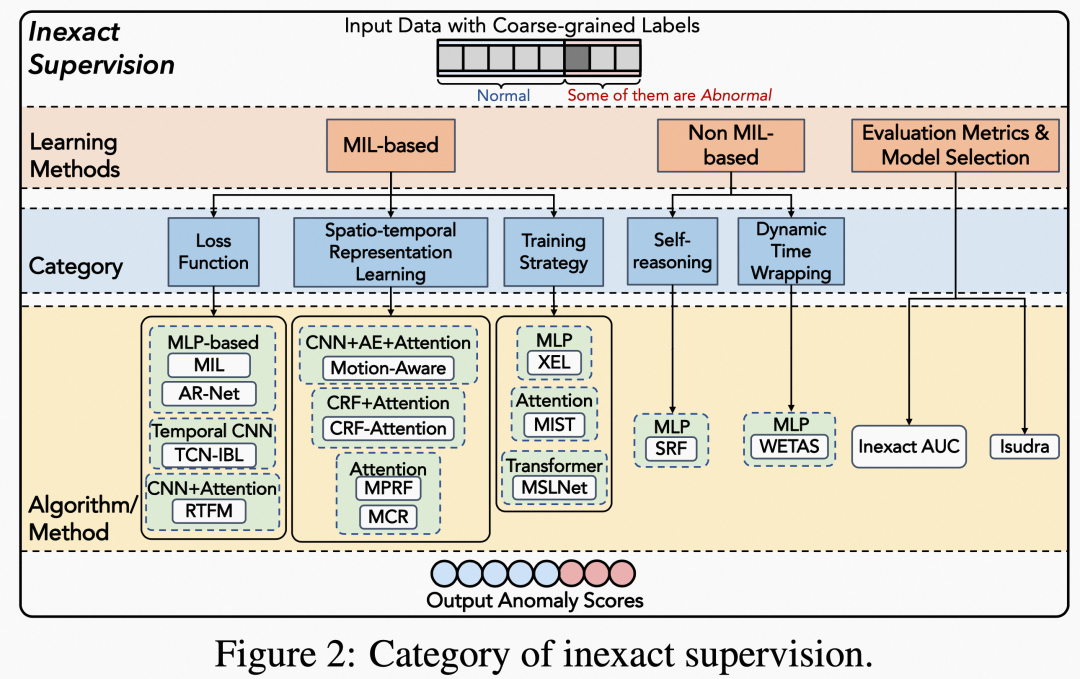
主要都是基于multi-instance learning (MIL)的方法,除此之外:提出了新的评估指标或模型选择策略来解决这个问题。
1. multi-instance learning (MIL)
多实例学习(MIL)最初设计用于预测一组(group)实例的标签,而不是单个实例的标签。
[Sultani et al., 2018] 提出的方法还是比较好理解的,简单来说,视频代表着一个组,而视频片段是一个instance,每个视频的分数由视频中片段的最大异常分数所代表,通过仅对两个实例进行排名,实现了组级别的异常分数排名。模型训练过程中只使用视频级别(组级别)的粗粒度标签。(简单理解,虽然模型输出的是instance的分数,但训练过程中用的是视频维度的标签即可,因为instance的分数映射到了视频维度)
对于MIL主要是损失函数、时空特征学习、训练策略等,因为这章总体以视频异常检测为例,主要针对时空信息。
2. non MIL
文中举例非MIL方法,主要是从不同角度来处理问题,比如通过聚类,或者把问题转换为分割问题。
3. evalution metric & model selection
通过提出inexact AUC来训练现有模型。
indirectly supervised AD
4.3 将来一些思考
上述文献主要针对视频的,而对于表格、时间序列和图表数据的不精确监管尚未得到广泛研究,这方面有一定的潜力
不同的数据格式具有相同的特征模式,例如,时间序列和视频都具有时间戳和时间关系。因此,我们可以将主导技术从时间序列转移到视频广告,反之亦然。 技术可以迁移。
五、Inaccurate Supervision
5.1 场景
标签存在有噪音和损坏的情况,这是十分是常见的。
以网络入侵检测为例,由于数据的敏感性和打标本身的费用,很难获得准确的标签。
5.2 方法
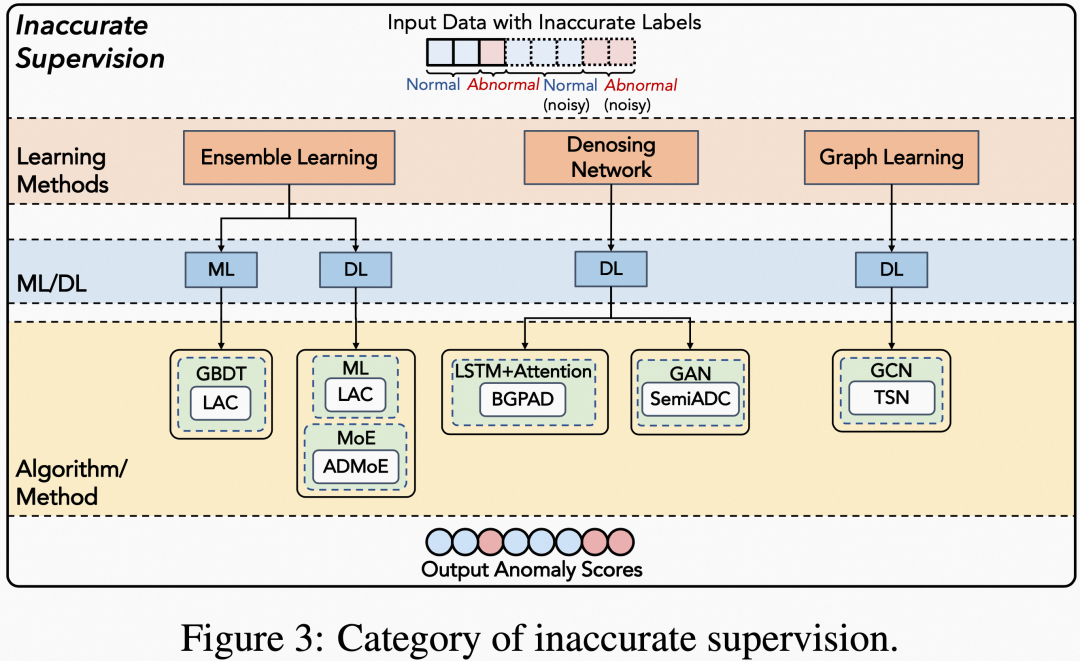
1. ensemble learning
主要通过利用集成学习,或设计降噪的网络,将标签噪声在模型训练过程中的影响降至最低,设法从多个噪声源中提取有用的标签信息。
可以通过标签聚合,通过加权投票将多源的噪声标签整合为聚合标签,然后借助一些精确类别的实例校正聚合标签。
2. denoising network
通过attention来过滤类别的噪声,来通过去噪系统,解决这类问题。
这里比较有趣的事用GAN去解决。具体可以看:Semi- supervised anomaly detection in dynamic communication networks.
3. graph learning
针对视频数据,引入graph learning。
六、实验
用6个基准算法在47个公开数据上做测试,结果如下:
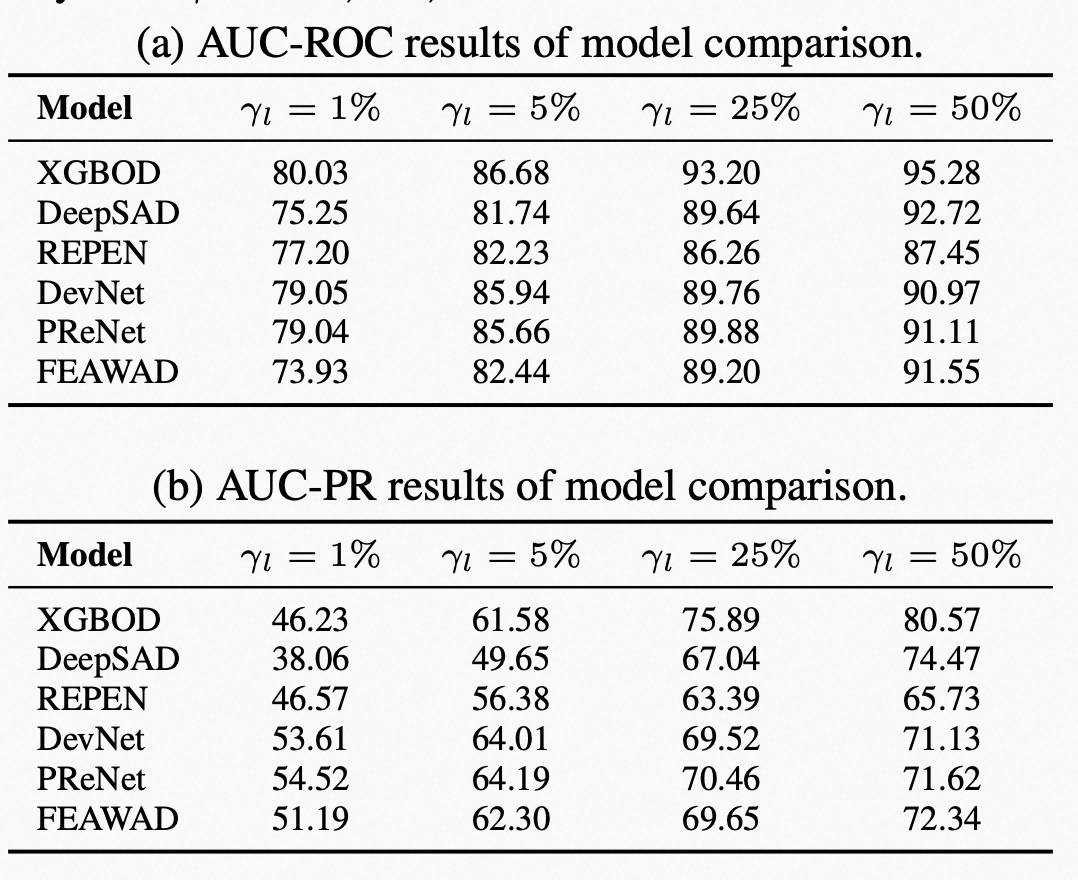
具体实验部分见:https://github.com/yzhao062/wsad
- 推荐阅读:
-
- 我的2022届互联网校招分享
-
- 我的2021总结
-
- 浅谈算法岗和开发岗的区别
-
- 互联网校招研发薪资汇总
- 2022届互联网求职现状,金9银10快变成铜9铁10!!
-
- 公众号:AI蜗牛车
-
- 保持谦逊、保持自律、保持进步
-
- 发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
- 发送【1222】获取一份不错的leetcode刷题笔记
-
- 发送【AI四大名著】获取四本经典AI电子书


