
- 1从医疗数据到数学模型_医疗行为数字模型
- 2深度学习基础-基于Numpy的前馈神经网络(FFN)的构建和反向传播训练
- 3UNet深度学习模型在医学图像分割中的应用及其Python实现细节_unet医学图象分割
- 4OpenAI文档翻译——在不通的场景下如何更好的设计ChatGPT提示词_openai api翻译文件
- 5设计报告分享——基于Arduino的门禁系统_基于arduino的门禁系统设计
- 6text2sql:SQLCoder的简介、安装、使用方法之详细攻略_sqlcoder2
- 7安装thinkphp6并使用多应用模式,解决提示路由不存在解决办法_thinkphp6 多模块路由 控制器不存在
- 8使用 Elastic 作为全局数据网格:将数据访问与安全性、治理和策略统一起来
- 9开发者实战 | 自训练 Pytorch 模型使用 OpenVINO™ 优化并部署在 AI 爱克斯开发板...
- 10Spring Boot返回前端Long型丢失精度_springboot long类型精度丢失
使用SVM模型对京东评价进行情感分析---【大白话版】_svm情感分析
赞
踩
前言
没错,是我 还是熟悉的配方 还是熟悉的配料 新的一年我带着我的所见即所学回来了!!

今天所要讲的是针对京东某商品的评价进行情感分析,京东评价的爬虫在我以前的文章有具体描写,这边就不在重复了,感兴趣的网友可以从下面的链接获取,我们这一次主要讲怎么使用SVM模型实现情感分析!
对了!!本篇文章对于SVM模型的理解和使用只是机器学习最简单的应用,不参与到大佬们最优模型的厮杀中!

最后老规矩 不想听我唠嗑的可以直接跳到最后一步获取代码!
因为本人技术有限,假如有些地方说的不好或者错误,欢迎讨论并指出,谢谢支持!
以下为我往期爬取京东评价的文章:
京东评价爬取详细版
一丶原理
提问:那么到底什么是机器学习?什么又是情感分析?
以下我将使用生活的例子并用大白话的方式来帮助大家理解。

在理解机器学习之前,可以先回答我一个问题。
这是什么?
----回答:小猫

这个呢?
----回答:小狗

为什么哪个是修猫 那个是修狗?
----回答:因为猫的眼睛 狗的眼睛 体型大小等等
为什么你能分辨出?是特征
每个小猫小狗都有其特征 因为我们看的足够多并且经过长期的生活经验 大脑能迅速判断出猫的耳朵这是小猫 狗的体型这是小狗。
好了 现在我用这段话的方式来阐述一些机器学习
计算机获得每个图片中对应的特征并将其分类 经过多次的训练 形成一个模型,模型能迅速判断出这张图片是什么
这就是机器学习中的图像识别的基本原理,无论是加油站的车牌识别或者是疫情当下的人脸识别,这些都是在图像识别的基础上应用起来的。

二丶代码实现
回到我们的重点上 什么是情感分析?
其实和图像识别类似,不仅仅在图像里 语句中也包含着特征值,我给你一句话“我很喜欢你” 提取这句话的关键词 你会选什么?
是的 “喜欢” 假如把这句话分解成【“我”, “”很“,”“喜欢”, “你”】每一个分词代表着一个数值,核心关键词数值最大,其他较小,数值依次相加得到最终结果,根据这个结果判断为正面或者负面 这个就是情感分析的核心原理!!!
所以 我们要做的是什么!!
1.计算每个分词的向量
2.计算每个句子的向量
3.判断
over!!是的 你没听错 就是这么简单!
步骤如下:
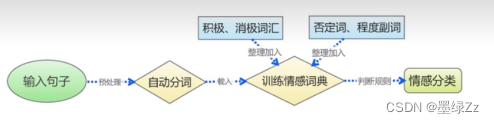
计算分词向量使用的word2Vec
什么是word2Vec我就不用官方的语言回答了 大家去网上找可以找得到很多。你可以直接理解为一个函数 将文本套入能映射出这个文本的高维空间向量
2.1 导入情感词典
情感词典就是一段文本 他有很多种 比如针对于新闻的 针对于商品评价的 或者范围更大一点的直接包含消极与积极所以文本的。情感词典能提供一个参考来告诉你这个分词是多少的权重。本文使用的是针对商品评价的情感词典。(情感词典大家可以自行在github或者网上查找)
我们要做的第一步是导入情感词典,并且将其分词 为后面的模型的训练做准备
#导入正面和负面文本为后续训练模型做准备
neg = pd.read_excel('data/neg.xls',header=None)#差评---总共0分
pos = pd.read_excel('data/pos.xls',header=None)#好评---总共1分
#因为word2vec只接受分词结果 这一步将文本进行分词
neg['words'] = neg[0].apply(lambda x: jieba.lcut(x))
pos['words'] = pos[0].apply(lambda x: jieba.lcut(x))
x = np.concatenate((pos['words'],neg['words']))#合并分词结果
#np.ones/np.zeros 产生指定个数的1和0
y = np.concatenate((np.ones(len(pos)),np.zeros(len(neg))))#建立x轴与y轴 让正面与负面文本可以相互匹配
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2计算单个词语的高维向量
使用word2Vec 在使用之前需要初始化 并将维度设置为300 少于5次出现的词语并且抛弃不再使用
w2v = Word2Vec(vector_size=300, min_count=5)#初始化w2v的向量空间
#min_count = 5 出现次数少于5次就丢弃
w2v.build_vocab(x)
w2v.train(x, total_examples=w2v.corpus_count,epochs=5)#训练数据集 训练5次
#训练完成结束后得到每一个词的高维向量
#打印“我”这个高维向量的数值
# print(w2v.wv['我'])#则可打印出这个词语的向量数值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3计算句子高维向量
现在已经知道全部分词的高维向量了 只要带入句子 调用w2v则可以得到句子的高维向量
#计算句子的这个向量
def total_vec(words): #这里后面会传入单个句子
vec = np.zeros(300).reshape(1, 300)#初始化一个特别的数组 这里能存放空间向量的数据 后面会传入个svm模型 判断是否积极消极
for word in words:#words为句子 word为其中的分词
try:
vec += w2v.wv[word].reshape((1,300))#如果这个词存在就放进特殊的数组中
except KeyError:#try的作用为排除丢弃下的词
continue
return vec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.4训练模型
#训练SVM模型
#将所有句子的向量合并为一个数组 得到训练集
train_vec = np.concatenate([total_vec(words) for words in x])
model = SVC(kernel= 'rbf', verbose= True)#初始化SVM模型
model.fit(train_vec, y)#传入y空间向量 数据 开始构建模型
#joblib为保存模型的一个函数
joblib.dump(model,'data/svm_model.pkl')#保存模型
print('sucessful')#保存成功
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.5预测
读取模型 实现京东情感评价的预测
df = pd.read_csv("分词.csv", encoding="gbk", index_col=0)
print(df)
for index, row in df.iterrows():
i = row["内容"]
words_vec = total_vec(i)
result = model.predict(words_vec)
# 运用模型中的函数 对句子空间向量进行预测?预测什么?返回一个结果 1 或者0
coment_total.append('积极' if int(result[0]) else '消极')
# 如果result[0]的结果为1 积极 否则消极
if int(result[0]) == 1:
print(i, '[积极]')
else:
print(i, '[消极]')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
三丶完整代码
import jieba import numpy as np import pandas as pd from gensim.models.word2vec import Word2Vec import joblib from sklearn.model_selection import cross_val_score from sklearn.svm import SVC #导入正面和负面文本为后续训练模型做准备 neg = pd.read_excel('data/neg.xls',header=None)#差评---0 pos = pd.read_excel('data/pos.xls',header=None)#好评---1 #因为word2vec只接受分词结果 这一步将文本进行分词 neg['words'] = neg[0].apply(lambda x: jieba.lcut(x)) pos['words'] = pos[0].apply(lambda x: jieba.lcut(x)) x = np.concatenate((pos['words'],neg['words']))#合并分词结果 #np.ones 产生指定个数的1和0 y = np.concatenate((np.ones(len(pos)),np.zeros(len(neg))))#建立x轴与y轴 让正面与负面文本可以相互匹配 # print(x) # print(y) #计算单个词的向量 w2v = Word2Vec(vector_size=300, min_count=5)#初始化w2v的向量空间 #size原本是指300个维度 变成了vector_sieze = 300 为什么是300? #min_count = 5 出现次数少于5次就丢弃 w2v.build_vocab(x) w2v.train(x, total_examples=w2v.corpus_count,epochs=5)#训练数据集 训练5次 #训练完成结束后得到每一个词的高维向量 #打印“我”这个高维向量的数值 # print(w2v.wv['我']) #计算句子的这个向量 def total_vec(words): #这里后面会传入单个句子 vec = np.zeros(300).reshape(1, 300)#初始化一个特别的数组 这里能存放空间向量的数据 后面会传入个svm模型 判断是否积极消极 for word in words:#words为句子 word为其中的分词 try: vec += w2v.wv[word].reshape((1,300))#如果这个词存在就放进特殊的数组中 except KeyError:#try的作用为排除丢弃下的词 continue return vec #训练SVM模型 #将所有句子的向量合并为一个数组 得到训练集 # train_vec = np.concatenate([total_vec(words) for words in x]) # # model = SVC(kernel= 'rbf', verbose= True)#初始化SVM模型 # model.fit(train_vec, y)#传入y空间向量 数据 开始构建模型 # # #joblib为保存模型的一个函数 # joblib.dump(model,'data/svm_model.pkl')#保存模型 # print('sucessful')#保存成功 model = joblib.load('data/svm_model.pkl')#读取模型 #主函数: def svm_predict(): coment_total = [] df = pd.read_csv("分词.csv", encoding="gbk", index_col=0) print(df) for index, row in df.iterrows(): i = row["内容"] words_vec = total_vec(i) result = model.predict(words_vec) # 运用模型中的函数 对句子空间向量进行预测?预测什么?返回一个结果 1 或者0 coment_total.append('积极' if int(result[0]) else '消极') # 如果result[0]的结果为1 积极 否则消极 if int(result[0]) == 1: print(i, '[积极]') else: print(i, '[消极]') svm_predict()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
结果展示:
四丶总结:
本次的文章只是SVM模型最简单的使用 代码中肯定还有很多不足 以后有机会会继续完善补充 感谢大家这次的观看!!!下次见!


