
- 1微信小程序使用wx.request()函数发送get和post请求到onenet平台_微信小程序下发命令到onenet
- 2互联网,大数据和人工智能对我们的生活带来的影响_简述互联网/大数据/人工智能技术对日常生活的影响
- 3超简单的个人简历(精选7篇)
- 4腾讯开源再登央视!助力提效增产和节能减排
- 5知识图谱需要解决的问题_知识图谱的建立需要解决以下哪些问题
- 6Xcode调试 之 内存泄露_xcode tauri 内存泄露
- 7Kafka2.8无Zookeeper模式下集群部署_linux安装kafka2.8集群无需zookeeper配置
- 85分钟搞定OKR工作法
- 9【Linux杂货铺】文件系统
- 10《HCIP-openEuler实验指导手册》1.2Apache主页面配置
Unity常见面试题型和日常问题总结,附有详解,强烈建议收藏(持续更新中)_unity 面试
赞
踩
前情提要:
会收集自己遇到的问题、在网上碰到的问题、大家分享的问题,尽量用不那么程序化的语言去描述,让大家都可以明白的更快(由于工作量有点大,可能更新的有点慢,不过我会尽力去更新完善的)

文章目录
- C#
- 1. 什么是面向对象,和面向过程的区别
- 2. 五大基本原则
- 3. 面向对象的特征?如何设计和实现面向对象?
- 4. 重载、重写
- 5. 不安全代码
- 6. 值类型、引用类型
- 7. 接口、抽象类
- 8. 字段、属性、索引器
- 9. 什么是lambda表达式
- 10. Func和Action
- 11. foreach迭代器循环遍历和for循环遍历的区别
- 12. is和as
- 13. Async和Await的用法
- 14. string和stringBuilder和stringBuffer的区别
- 15. 什么是GC垃圾管理器?产生的原因?如何避免?
- 16. 反射的实现原理
- 17. 虚方法
- 18. 什么是泛型?好处是什么?
- 20. Ref和Out关键字有什么区别?Ref的深层原理是什么?
- 21. Using的作用
- 22. 引用和指针的区别
- 23. 结构体和类的区别
- 24. 栈和堆的区别
- 25.什么是解耦、内聚
- 26.委托和事件
- 27. 异常捕获
- 28.如何对大量数据进行高效处理?
- 29.多线程编程
- 30.什么是LINQ?
- 31.C#修饰符有哪些?有什么区别?
- 32.程序集
- Unity
- 1. 函数生命周期
- 2. 什么是万向锁?如何避免?四元数相对于欧拉角的优点?
- 3. 什么是进程、线程、协程?区别是什么
- 4. 物体发生碰撞的必要条件
- 5. 碰撞器和触发器之间的区别
- 6. 有几种施加力的方式?
- 7. 动画分层
- 8. 什么是IK?
- 9. 游戏动画有哪几种类型,以及其原理?
- 10. 什么是FSM有限状态机?
- 11. 在场景中放置多个摄像机且同时处于活动状态会发生什么?
- 12. unity中摄像机的Clipping Planes的作用是什么?调整Near、Far的值时要注意些什么?
- 13. 有几种光源?分别是什么?
- 14. 什么是LightMap?
- 15. 两种阴影的判断方法以及工作原理
- 16. unity中的基类是什么?
- 17. 当一个细小的高速物体撞向另一个较大的物体时,会出现什么情况?如何避免?
- 18. 向量的点乘、 叉乘以及归一化
- 19. 什么是LOD?优缺点是?
- 20. 什么是MipMap?优缺点是?
- 21. 什么是DrawCall?如何降低DrawCall
- 22. 当游戏中需要频繁的创建一个物体对象时,该怎么做去节省内存?
- 23. MeshRender中Material和SharedMaterial的区别
- 24. 如何优化内存
- 25. Unity资源加载的方式
- 26. 如何优化资源加载
- 27. 什么是AssetBundle?有什么好处?和Resource的加载的区别
- 28. 什么是渲染管道?
- 29. GPU的工作原理?
- 30. 在编辑场景时将GameObject设置为Static有何作用?
- 31. 有两个物体,如何让一个物体永远比另一个物体先渲染?
- 32. 客户端和服务器交互方式有哪几种?
- 33. UnityEditor
- 34.
- 35. 常用的特性和技术
- 36. 当场景中有大量的碰撞或复杂物理场景时,该怎么去优化?
- 37.假如有几百个排行榜item要显示,你该怎么去做?
- 38. UGUI的画布有几种模式?分别是什么?
- 39. unity中有一个保存读取数据的类,是什么?其中保存读取整形数据的函数是什么?
- 40. 如何检测物体是否被其他对象遮挡?
- 41.敌人的寻路逻辑如何进行设计?
- 设计模式
- 计算机网络
- 操作系统
- 数据结构
- 常见算法
- 热更新(暂时以Lua为基础)
- SDK相关
- 渲染和图形学
C#
1. 什么是面向对象,和面向过程的区别
面向对象:当解决一个问题时,把事物抽象成对象的概念,看这个问题中有哪些对象,给这些对象赋一些属性和方法,让每个对象去执行自己的方法,最终解决问题
面向过程:当解决一个问题时,把事件拆封成一个个函数和数据,然后按照一定的顺序,依次执行完这些方法(过程),等方法执行完毕,事情也解决。
面向过程性能比面向对象要高,但是没有面向对象易于维护、易于复用、易于扩展
2. 五大基本原则
- 单一职责原则:一个类的功能要单一,不能太复杂。就像一个人一样,分配的工作不能多,不然虽然很忙碌,但是效率并不高
- 开放封闭原则:一个模块在扩展性方面应该是开放的,而在更改性方面应该是封闭的。例如一个模块,原先只有服务端功能,但是现在要加入客户端功能,那么在设计之初,就应当把服务端和客户端分开,公用的部分抽象出来,从而在不修改服务端的代码前提下,添加客户端代码。
- 里式替换原则:子类应当可以替换父类并出现在父类能出现的任何地方。例如参加年会,公司所有的员工应该都要可以参加抽奖,而不是只让一部分员工是参加抽奖。
- 依赖倒置原则:具体依赖抽象,上层依赖下层。例如B是较A低的模块,但B需要使用A的功能,这时B不能直接使用A中的具体类,而是应当由B来定义一个抽象接口,由A来实现这个抽象接口,B只使用这个抽象接口,从而达到依赖倒置,B也接触了对A的依赖,反过来是A依赖于B定义的抽象接口。
- 接口分离原则:模块之间要通过抽象接口隔离开,而不是通过具体的类强耦合起来
3. 面向对象的特征?如何设计和实现面向对象?
- 封装:将数据和行为相结合,通过行为来进行约束代码,从而增加数据的安全性
- 继承:用来扩展一个类,子类可以继承父类的部分行为和属性,从而便于管理、提高代码的复用
- 多态:一个对象,在不同情形有不同表现形式;子类对象可以赋值给父类型的变量
将不同的功能模块封装成不同的类,通过继承和多态等特性来实现代码的复用和扩展
4. 重载、重写
- 两者定义的方式不同 ;重载方法名相同参数列表不同,重写方法名和参数列表都相同
- 封装、继承、多态所处的位置不同;重载是在同类中,而重写是在父子类中
- 多态的时机不同,重载是在编译时多态,而重写是在运行时多态
5. 不安全代码
当一个代码使用unsafe修饰符标记时,c#允许在函数中使用指针变量。
6. 值类型、引用类型
- 值类型存储在内存栈中,超过作用域自动清理,在作用域结束后会被清理,而引用类型存储在内存堆中,由GC来自动释放,
- 值类型转换成引用类型(装箱)要经历分配内存和拷贝数据
- 引用类型转换成值类型(拆箱)要首先找到属于值类型的地址,再把引用对象的值拷贝到内存栈中的值实例中
- 值类型存取速度快,引用类型存取速度慢
- 值类型表示实际的数据,引用类型表示存储在内存堆中的数据的指针和引用
- 值类型的基类是ValueType,引用类型的基类是Object
- 值类型在内存管理方面有更好的效率,且不支持多态,适合用作存储数据的载体
引用类型支持多态,适合用于定义应用程序的行为- 值类型有:byte、short、int、long、double、decimal、char、bool、struct
引用类型有:array、class、interface、delegate、Object、string
7. 接口、抽象类
接口:
- 契约式设计,是开发的,谁都可以去实现,但是必须要遵守接口的约定;例如所有游戏都必须会有主角给玩家进行操作,这种必须规范
- 是约束类应该具有的功能集合,从而便于类的扩展和管理
- 接口不能实例化
- 接口关注于行为,可以多继承
- 接口的设计目的,是对类的行为进行约束,接口隔离(提供一种机制,可以强制要求不同的类具有相同的行为,只约束了行为的有无,但是不对如何去实现行为进行约束)
- 类可以实现一个或多个接口,从而拥有接口中定义的所有方法。
public interface IShape { double Area(); // 接口方法,类必须实现 } public class Circle : IShape { private double radius; public Circle(double r) { radius = r; } public double Area() // 实现接口方法 { return Math.PI * radius * radius; } } public class Rectangle : IShape { private double width; private double height; public Rectangle(double w, double h) { width = w; height = h; } public double Area() // 实现接口方法 { return width * height; } } class Program { static void Main(string[] args) { Circle circle = new Circle(5); Console.WriteLine("Circle area: " + circle.Area()); Rectangle rectangle = new Rectangle(4, 6); Console.WriteLine("Rectangle area: " + rectangle.Area()); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
抽象类:
- 对同类事物相对具体的抽象,例如我会玩游戏,你如果继承了我,你也必须会玩游戏,但是我不管你玩什么类型游戏;
- 不能实例化,它只能被用作其他类的基类
- 是概念的抽象,只能单继承
- 可以包含抽象方法和具体方法,子类必须实现抽象方法
- 用于实现共享行为和属性,以及定义子类必须实现的方法
- 设计目的,是代码复用(当不同的类具有某些相同的行为,且其中一部分行为的实现方法一致时,可以让这些类都派生于一个抽象类。在这个抽象类中实现了公用的行为,从而可以避免让所有的子类来实现该行为,从而让子类可以自己去实现抽象类中没有的部分)
- 一个类可以有多个接口,但是只能继承一个父类
public abstract class Shape { public abstract double Area(); // 抽象方法,子类必须实现 public virtual void Draw() // 虚方法,子类可以选择性地重写 { Console.WriteLine("Drawing shape"); } } public class Circle : Shape { private double radius; public Circle(double r) { radius = r; } public override double Area() // 实现抽象方法 { return Math.PI * radius * radius; } public override void Draw() // 重写虚方法 { Console.WriteLine("Drawing circle"); } } public class Rectangle : Shape { private double width; private double height; public Rectangle(double w, double h) { width = w; height = h; } public override double Area() // 实现抽象方法 { return width * height; } } class Program { static void Main(string[] args) { Circle circle = new Circle(5); Console.WriteLine("Circle area: " + circle.Area()); circle.Draw(); Rectangle rectangle = new Rectangle(4, 6); Console.WriteLine("Rectangle area: " + rectangle.Area()); rectangle.Draw(); // 使用父类的虚方法实现 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
8. 字段、属性、索引器
字段: 是一种表示与对象或类相关联的变量的成员,字段的声明用于引入一个或多个给定类型的字段。
属性: 是对字段的封装,将字段和访问字段的方法组合在一起,提供灵活的机制来读取、编写或计算私有字段的值。并且属性通过Get访问器和set访问器来控制对字段的访问;
索引器:类似数组的访问方式,通过索引来访问对象中的特定元素,而不必暴露对象的内部结构。
例如:
pulic class User
{
private string _name;//_name为字段
public string Name //Name为属性,它含有代码块
{
get
{
return _name;//读取(返回_name值)
}
set
{
_name = value;//为_name赋值
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如上,属性以灵活的方式实现了对私有字段的访问,是字段的自然扩展,一个属性总是与某个字段相关联,字段能干的,属性一定能干,属性能干的,字段不一定干的了;为了实现对字段的封装,保证字段的安全性,产生了属性,其本质是方法,暴露在外,可以对私有字段进行读写,以此提供对类中字段的保护,字段中存储数据更安全。
------参考原文链接:字段和属性
9. 什么是lambda表达式
一个用来代替委托实例的匿名方法(本质是一个方法,只是没有名字,任何使用委托变量的地方都可以使用匿名方法赋值),从而让代码更加简洁。被Lambda表达式引用的外部变量叫做被捕获的变量;捕获了外部变量的Lambda表达式叫做闭包;被捕获的变量是在委托被实际调用的时候才被计算,而不是在捕获的时候
//不使用Lambda表达式时的一个点击事件 public class button : MonoBehaviour { public Button btn; void Start () { btn.onClick.AddListener(btnClick); } void btnClick() { Debug.Log("按钮被点击了!"); } } ------------------------------------------------------------------- ------------------------------------------------------------------- //使用Lambda表达式时的一个点击事件 public class button : MonoBehaviour { public Button btn; void Start () { //无参匿名函数 btn.onClick.AddListener(()=> { Debug.Log("按钮被点击了"); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
public class LambdaTest : MonoBehaviour { public delegate int MyDelegate(int t); [ContextMenu("Exe")] private void Start() { /** 实际上,编译器会通过编写一个私有方法来解析这个lambda表达式 * 然后把表达式的代码移动到这个方法里 **/ MyDelegate my = (x) => { return x * x; };//在只有一个可推测类型的参数时,可以省略小括号 MyDelegate my1 = (x) => x * x; int num = my(2); int num1=my1(2); Debug.Log(num); //4 Debug.Log(num1); //4 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
10. Func和Action
Func:是一个泛型委托类型,它表示一个具有指定返回类型的方法。Func 委托可以接受 0 到 16 个输入参数,并返回一个指定类型的结果。例如,Func<int, string> 表示一个接受一个整数参数并返回一个字符串结果的方法。
Func<int, int, int> add = (x, y) => x + y; //前两个为传的参数,最后一个为返回值
int result = add(3, 5); // 结果为 8
- 1
- 2
Action: 也是一个委托类型,但它表示一个没有返回值的方法。与 Func 不同,Action 委托可以接受 0 到 16 个输入参数,但不返回任何值。
Action<string> logMessage = message => Console.WriteLine(message);
logMessage("Hello, world!"); // 打印 "Hello, world!"
- 1
- 2
11. foreach迭代器循环遍历和for循环遍历的区别
For循环通过下标,对循环中的代码反复执行,功能强大,可以通过Index(索引)去取得元素。
Foreach循环从头到尾,对集合中的对象进行遍历。在遍历的时候,会锁定集合的对象,期间是只读的,不能对其中的元素进行修改。
Foreach相对于For循环,其运行时的效率要低于For循环,内存开销也比For循环要高些。但是,在处理一些不确定循环次数的循环或者循环次数需要计算的情况时,使用Foreach更方便些。
12. is和as
两者都是用于类型检查和类型转换用的关键字
is:用于检查一个对象是否是某个特定类型的实例。它返回一个bool值,如果对象是指定类型的实例,则返回true,否则为false
object obj = "Hello";
if (obj is string)
{
Console.WriteLine("obj is a string");
}
- 1
- 2
- 3
- 4
- 5
as:用于将一个对象强制转换为指定类型,如果转换成功则返回转换后的对象,如果失败则返回null
object obj = "Hello";
string str = obj as string;
if (str != null)
{
Console.WriteLine("Successfully cast to string: " + str);
}
- 1
- 2
- 3
- 4
- 5
- 6
13. Async和Await的用法
两者都是用于异步编程的关键字
Async:用于声明一个异步方法,异步方法可以包含“await” 表达式,该关键字告诉编译器在等待异步操作完成时暂停当前玩法的执行(返回Task对象,对象可带结果可不带)
async Task<string> DownloadDataAsync()
{
HttpClient client = new HttpClient();
string result = await client.GetStringAsync("https://example.com");
return result;
}
- 1
- 2
- 3
- 4
- 5
- 6
Await:用于等待异步操作完成,并获取其结果。在异步方法中,"await"会将执行控制权返回给调用方,直到异步操作完成为止。通常情况下,"await"表达式会应用于返回"Task"或"Task< TResult >"对象的异步方法调用上
string data = await DownloadDataAsync();
Console.WriteLine("Downloaded data: " + data);
- 1
- 2
14. string和stringBuilder和stringBuffer的区别
都是用来处理字符串的类,但是有些重要的区别
string:
- 是不可变的,一旦创建就不能被修改
- 对string进行的修改实际上是创建了一个新的string对象,也就是引用类型
- 因为每次对string的操作都是创建新的对象,这样会产生额外的内存开销
stringBuilder:
- 是可变的,可以动态修改字符串的内容
- 性能比string要好,特别是在需要多次修改字符串时
- 使用“Append”的方法来追加字符串,而不是创建新的字符串
stringBuffer
- 和stringBuilder类似,都是可变的字符串类,只不过stringBuffer是线程安全的,而stringBuilder不是。因此在多线程情况下,推荐使用stringBuffer,而在单线程情况下,使用stringBuilder会更高效,当然,前提是有较多的动态修改字符串内容的需求下,否则还是建议使用string
15. 什么是GC垃圾管理器?产生的原因?如何避免?
GC垃圾回收是一种自动内存管理机制,用于在程序运行时自动检测和释放不再使用的内存对象,以避免内存泄漏和减少内存碎片。
其产生的原因主要是为了解决手动管理内存的问题,例如忘记释放内存或释放了仍在使用的内存,从而导致内存泄漏和错误
如何避免可以遵循以下原则
- 合理使用对象生命周期:尽量在不需要使用对象时手动释放对象引用,避免对象长时间存活于内存中
- 避免创建过多临时对象:在循环或频繁调用的方法中,应尽量避免创建大量临时对象,可以通过对象池等技术来复用对象,减少GC压力
- 使用合适的数据结构和算法
- 减少频繁的创建或销毁对象操作,尽量复用已有对象
16. 反射的实现原理
是指在程序运行时动态的获取类的信息以及操作类的成员和属性的机制。它允许程序在运行时检查和修改对象的结构、行为和属性,而不是在编译时确定这些信息。但是这样会带来一定的性能开销,通常比静态代码更慢,因为涉及到动态解析和调用,因此在性能需求较高的情况下,应该尽量避免过度使用反射。
原理主要涉及以下方面
- 元数据:在.NET平台下,每个程序集都包含元数据,其中包含了有关程序集、类型、成员和其他信息的描述。这些元数据可以在运行时被反射机制所访问和利用
- 类型加载和装载:当程序需要使用某个类型时,CLR(通用语言执行平台(Common Language Runtime,简称CLR)是微软为他们的.NET的虚拟机所选用的名称。它是微软对通用语言架构(CLI)的实现版本,它定义了一个代码执行的环境。CLR执行一种称为通用中间语言的字节码,这个是微软的通用中间语言实现版本)会负责加载和装载该类型的元数据信息。这些元数据包含了类型的结果、成员和方法等信息。
- Type类和MemberInfo类:在.Net中,Type类和MemberInfo类是反射的核心,它们提供了许多方法和属性,可以用于动态的获取和操作类型信息和成员信息。通过这些类,可以获取类的名称、属性、方法、字段等信息,也可以调用对象的方法和属性
- 动态调用:反射允许程序在运行时动态的调用方法、属性和构造函数,而不需要在编译时确定调用哪个方法或属性
17. 虚方法
- 在基类中声明的可重写的方法,子类可以选择性地重写虚方法
- 如果在派生类中未重写虚方法,则调用基类中的方法
- 用于实现方法的重写和多态性
class Animal
{
public virtual void MakeSound()
{
Console.WriteLine("Animal makes a sound");
}
}
class Dog : Animal
{
public override void MakeSound()
{
Console.WriteLine("Dog barks");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
18. 什么是泛型?好处是什么?
是一种编程机制,允许在编写代码时使用参数化类型,从而实现代码的灵活性和重用性。在定义类、结构、接口和方法时使用类型参数,这些类型参数在使用时可以被替换为具体的数据类型,从而使得代码可以处理各种不同类型的数据,而无需针对每种数据类型编写单独的代码。
- 代码复用:可以让代码变得更加通用,可以处理多种不同类型的数据
- 类型安全:泛型在编译时会进行类型检查,可以提前发现类型错误,从而避免在运行时出现类型不匹配
- 性能优化:泛型在编译时会生成特定类型的代码,避免了装箱拆箱,从而提高了执行效率
- 抽象数据结构:泛型使得可以定义抽象的数据结构,例如列表、栈、队列等,可以适用各种不同类型的数据,提高了数据结构的通用性和灵活性
- 更好的API设计:可以提供更加抽象和通用的接口,满足不同场景的需求
20. Ref和Out关键字有什么区别?Ref的深层原理是什么?
两者都用于参数传递
ref:
- 用于将参数按引用传递给方法,这意味着对参数的任何更改都会影响到原始变量;
- 在调用方法前,必须初始化ref参数
out:
- 也用于按引用传递参数,但通常用于从方法返回多个值
- 在调用方法前,不需要初始化out参数,因为它们被视为为赋值的输出参数,但必须在退出之前为out参数赋值
ref的深层原理涉及到C#中的参数传递机制->即按值传递和引用传递
- 值传递:对于值类型,如int、double等,传递的是参数的副本,方法内对参数的修改并不会影响到原始变量
- 引用传递:对于引用类型参数,如类、数组等,传递的是地址,方法内对参数的修改会影响到原始变量,而ref关键字实际上是一种引用传递
21. Using的作用
- 声明命名空间:以便于在代码中使用该命名空间中的类型而无需使用完全限定名
using System;
// 在代码中可以直接使用 System 中的类型,而无需完全限定名
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello, world!");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 声明资源的使用范围:通常用于确保在代码块结束时释放资源,即使发生异常也能够安全的释放资源。这种用法通常用于处理需要显示释放的资源,如文件、数据库连接等
using (var stream = File.Open("example.txt", FileMode.Open))
{
// 使用文件流进行读取或写入操作
} // 在此处,文件流会被自动释放
- 1
- 2
- 3
- 4
22. 引用和指针的区别
引用:
- 是一种对对象的间接访问方式,它提供了一种安全且易于使用的方式来访问内存中的对象
- 在C#中,大多数情况下,我们使用引用来操作对象,而不是直接操作内存地址。
- 引用不直接暴露内存地址,而是提供了一种更高级别的抽象,使得对象的创建、销毁和操作更加简单和安全
- 引用在编译时就已经确定了对象的类型,因此是类型安全的
指针:
- 是一种直接访问内存地址的方式,在C#中,使用指针通常需要使用不安全代码块,并且要谨慎的处理以避免内存错误
- 指针提供了对内存中特定位置的直接访问能力,允许我们绕过编译时类型检查和安全检查
- 使用指针可以在一些特殊情况下提供更高效的内存操作,但是也增加了代码的复杂性和风险
综上,引用是一种更安全和更高级别的对象访问方式,而指针则是一种更底层、更危险的内存访问方式,需要谨慎使用。因此在C#中,通常情况下都去使用引用来操作对象,而避免直接使用指针
23. 结构体和类的区别
- 定义方式:
- 类是引用类型,使用‘class’关键字定义
- 结构体是值类型,使用‘struct’关键字定义
- 存储位置:
- 类的实例存储在堆内存中,而在栈内存中存储的是对堆中实例的引用
- 结构体的实例通常存储在栈内存中,除非作为字段嵌入在类中或者显式地使用‘new’进行堆分配
- 性能和内存开销:
- 类的实例分配和释放通常需要在堆上进行内存分配和垃圾回收,因此在性能和内存开销上可能更高
- 结构体的实例通常被分配在栈上,因此在内存分配和访问上可能更加高效
- 继承和多态:
- 类支持继承和多态,可以通过继承现有类来扩展和修改行为
- 结构体不支持继承,因为是密封的,并且无法作为基类来派生新的类型
- 拷贝行为:
- 类的实例在赋值或传递给方法时,实际上是传递引用,多个变量指向同一个对象
- 结构体的实例在赋值或传递给方法时,会进行值拷贝,每个变量都有自己的独立副本
- 默认构造函数
- 类可以有默认构造函数,也可以自定义构造函数
- 结构体默认具有无参构造函数,但是也可以定义自定义构造函数
综上,当需要表示较复杂的数据结构、支持继承和多态、以及希望共享对象实例时,通常会选择类。而当需要表示简单的数据类型、避免堆分配、或者需要频繁的值拷贝时,可以考虑使用结构体
24. 栈和堆的区别
- 存储方式:
- 栈是一种先进后出的数据结构,数据项也按照先进后出的顺序存储和访问
- 堆是一种树状数据结构,主要用来动态分配内存,存储的数据项没有固定的顺序,可以根据需要动态分配和释放
- 分配方式:
- 栈的分配是静态的,由编译器或运行时系统进行管理,通常在程序运行时就已经确定了变量的生命周期和内存需求
- 堆的分配是动态的,由程序员在运行时根据需要显性地请求内存分配,并负责在不再需要时释放内存
- 速度和效率:
- 栈的访问速度比堆更快,因为栈上的数据项是按照固定的顺序存储,可以直接通过指针进行访问。
- 堆的访问速度相对较慢,因为堆上的数据项存储在不同的位置,需要通过指针来定位和访问
- 生命周期:
- 栈上的数据项的生命周期是由其所在的作用域决定的,当作用域结束时,栈上的数据会自动销毁
- 堆上的数据项的生命周期由程序员管理,需要手动的分配和释放内存,否则可能导致内存泄漏或者内存溢出
- 内存管理
- 栈的内存管理的自动的,由编译器或运行时系统进行管理
- 堆的内存管理的手动的,需要程序员手动的分配和释放
综上,栈适合存储局部变量和函数调用等临时数据,而堆更适合存储动态分配的对象和数据结构
25.什么是解耦、内聚
解耦是将系统中的各个组件或模块之间的耦合度降到最小程度,使其相互之间的依赖关系减弱或消除。就像积木一样,各个积木可以组合在一起从而形成一个形状,又可以拆分,又可以替换,因为在理想状态下,每个模块就像积木一样,都是独立的个体,只要他们之间的接口相匹配,就可以灵活的搭配在一起,而解耦,就是朝这个理想状态而做的事情
解耦通常可以以下操作来实现:
- 接口抽象:定义接口来描述模块之间的通信和交互方式,而不是直接依赖于具体的实现类
- 依赖注入:通过依赖注入的方式将组件之前的依赖关系交给外部管理,使得组件之间解耦合
- 事件驱动:使用事件机制来实现模块之前的通信和解耦,一个模块产生事件,而其他模块监听并响应这些事件
- 消息队列:通过消息队列来实现模块之间的异步通信,降低模块之间的耦合度
- 中介者模式:引入中介者来管理模块之间的通信,将复杂的交互逻辑集中到中介者中,从而减少模块之前的直接依赖关系
内聚是指一个模块或类中的各个成员之间相互联系的紧密程度。高内聚表示模块内部的各个成员彼此之间紧密联系,共同完成一个特定的功能或目标,而低内聚则表示模块内部的各个成员之间联系较少功能分散,没有明确的目标
内聚度通常分为以下类型
- 功能内聚:模块内的各个成员都在完成同一个功能或任务。这种内聚度是最高的,模块的功能非常集中和明确,易于理解和维护。
- 顺序内聚:模块内的各个成员按照执行顺序相关联,一个成员的输出作为下一个成员的输入。虽然各个成员之间有联系,但是功能没有集中,模块的职责较为模糊
- 通信内聚:模块中的各个成员之间通过传递数据进行通信,彼此之间交流频繁。这种内聚度较高,但是模块的功能可能较为松散。
- 过程内聚:模块内的各个成员都在完成某个过程或算法,但彼此之间关联不强。这种内聚度较低,模块的职责分散。
- 时间内聚:模块内的各个成员在某个时间段内一起执行,但彼此之间关联不强。这种内聚度也较低,模块的功能和职责不够集中
综上,高内聚低耦合,是良好的设计原则。这样可以提高模块的可理解性、可维护性和可扩展性,同时降低代码的复杂度。
26.委托和事件
委托是一个类,它定义了方法的类型,使得可以将多个方法赋给同一个委托变量,当调用这个变量时,将依次调用其绑定的方法
一般调用方法,我们称为直接调用方法,而委托可以间接调用方法,也就是委托封装了一个或多个方法,方法的类型必须与委托的类型兼容;同时委托也可以当做方法的参数,传递到某个方法中去,当使用这个传进来的委托时,就会间接的去调用委托封装的方法,从而形成动态的调用方法的代码,并且降低了代码的耦合性。
可以理解为是一种类型安全的函数指针,用于引用具有相同签名的方法。
using UnityEngine; //声明委托,可以在类的外面,也可以在类的内部 public delegate X ADelegate<in T, out X>(T t);//有返回值的委托 对应Func委托 in为输入 out输出 public delegate void BDelegate<in T>(T t);//无返回值的委托 对应Action委托 public class DelegateTest : MonoBehaviour { public ADelegate<int, string> MyTest; [ContextMenu("Exe")] private void Start() { MyTest = IntNumber; TestDelegate(MyTest);//输出 返回值:100 //目标实例(当目方法为静态时,目标实例为null) Debug.Log(MyTest.Target); //输出 DelegateTest //实例方法 Debug.Log(MyTest.Method); //输出 System.String IntNumber(Int32) //(返回值类型)(目标方法)(方法参数) } public string IntNumber(int a) => (a * a).ToString(); public void TestDelegate(ADelegate<int, string> aDelegate) => Debug.LogFormat("返回值:{0}", aDelegate?.Invoke(10)); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
using System; using UnityEngine; public class DelegateTest : MonoBehaviour { [ContextMenu("Exe")] private void Start() { TestDelegate(Add); TestDelegate(Sub); //-----------委托与接口类似,委托能实现的,接口也能实现,但又有所不同 TestInterface(new Add()); TestInterface(new Sub()); /* * 对于这个例子这种情况,更适合使用委托,因为接口而言,要多次实现接口,过于麻烦。 */ } public int Add(int num) => num + num; public int Sub(int num) => num - num; public void TestDelegate(Func<int ,int> _func) => Debug.LogFormat("返回值:{0}", _func?.Invoke(10)); public void TestInterface(ICalcNumber calc) => Debug.LogFormat("返回值:{0}", calc.Calc(10)); } public interface ICalcNumber { public int Calc(int num); } class Add : ICalcNumber { public int Calc(int num) => num + num; } class Sub : ICalcNumber { public int Calc(int num) => num - num; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
事件,他可以让一个类或对象去通知其他类、对象,并做出相应的反应;是封装了委托类型的变量,使得在类的内部,不管是public和protected,总是private的。在类的外部,注册"+=“和注销”-="的访问限制符和在声明事件时使用的访问符一致。其主要目的就是为了防止订阅者之间相互干扰。
是委托的一种特殊用法,用来通知其他对象发生了特定的事件
using System; using UnityEngine; /// <summary> /// /// * Writer:June /// * /// * Data:2021.5.12 /// * /// * Function:事件例子=====>顾客点单 /// * /// * Remarks: /// /// /// 事件模型的五个组成部分 /// 事件的拥有者: 类 /// 事件: event关键字修饰 /// 事件的响应者: 类 /// 事件处理器: 方法-受到约束的方法 /// 事件的订阅关系: += /// /// </summary> /* 用于事件约束的委托类型,签名应该遵循:事件名+EventHandler * (当别人看到这个后缀之后,就知道,这个委托是用来约束事件处理器的,不会用于做别的事!!!) */ public delegate void OrderEventHandler(Customer _customer, OrderEventArgs _oe); public class EventEx : MonoBehaviour { //顾客类实例化 Customer customer = new Customer(); //服务员类实例化 Waiter waiter = new Waiter(); private void Start() { customer.OnOrder += waiter.TakeAction; customer.Order(); customer.PayTheBill(); } } public class Customer { public float Bill { get; set; } public void PayTheBill() => Debug.Log("我应该支付:" + Bill); #region 事件的完整声明格式 //private OrderEventHandler orderEventHandler; //public event OrderEventHandler OnOrder //{ // add { orderEventHandler += value; }//事件添加器 // remove { orderEventHandler -= value; }//事件移除器 //} //public void Order() //{ // if (orderEventHandler != null) // { // OrderEventArgs orderEventArgs = new OrderEventArgs // { // CoffeeName = "摩卡", // CoffeeSize = "小", // CoffeePrice = 28 // }; // orderEventHandler(this, orderEventArgs); // OrderEventArgs orderEventArgs1 = new OrderEventArgs // { // CoffeeName = "摩卡", // CoffeeSize = "小", // CoffeePrice = 28 // }; // orderEventHandler(this, orderEventArgs1); // } //} #endregion #region 事件的简略声明格式 public event OrderEventHandler OnOrder; public void Order() { //语法糖衣 if (OnOrder != null) { OrderEventArgs orderEventArgs = new OrderEventArgs { CoffeeName = "摩卡", CoffeeSize = "小", CoffeePrice = 28 }; OnOrder(this, orderEventArgs); OrderEventArgs orderEventArgs1 = new OrderEventArgs { CoffeeName = "摩卡", CoffeeSize = "小", CoffeePrice = 28 }; OnOrder(this, orderEventArgs1); } } #endregion } public class OrderEventArgs : EventArgs { public string CoffeeName { get; set; } public string CoffeeSize { get; set; } public float CoffeePrice { get; set; } } public class Waiter { //事件处理器 internal void TakeAction(Customer _customer, OrderEventArgs _oe) { float finaPrice = 0; switch (_oe.CoffeeSize) { case "小": finaPrice = _oe.CoffeePrice; break; case "中": finaPrice = _oe.CoffeePrice + 3; break; case "大": finaPrice = _oe.CoffeePrice + 6; break; default: break; } _customer.Bill += finaPrice; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
简而言之,委托是事件的底层基础,事件是委托的上层建筑,类似于字段和属性之间的关系,属性包装着字段,通过一系列的逻辑来保护字段。事件也是如此,起到保护委托类型,以免被外界滥用。他只能通过+=、-=来添加和移除事件处理器,不能直接的外部进行访问和调用
------参考原文链接:事件和委托详解_1
------参考原文链接:事件和委托详解_2
27. 异常捕获
允许程序员识别、捕获和处理出现的异常,保证程序在出现异常时仍能够以一种较合理的方式进行处理,而不会导致程序崩溃或不可预测的行为
当程序出现错误或意外情况时,可以使用’throw‘关键字手动抛出一个异常对象(通常是某个异常类的实例,用于描述异常的类型和信息)
在代码中使用‘try-catch’来捕获可能抛出的异常,‘try’块用于包裹可能抛出异常的代码块,而‘catch’块用于处理捕获到的异常
28.如何对大量数据进行高效处理?
- 使用适当的数据结构:例如需要频繁地执行插入、删除和查找操作,可以使用哈希表(dictionary)或平衡树(红黑树)等高效的数据结构
- 将大量数据分割成较小的数据块,然后分别处理每个数据块,最后合并结果
- 选择合适的算法对数据进行处理,以减少时间复杂度和空间复杂度。例如需要对大量数据进行排序,可以使用快速排序或归并排序,而不是简单的冒泡排序和插入排序(详情可见下面的算法)
- 并行化处理,利用多线程或并行计算技术来同时处理多个数据
- 使用数据流(以连续、增量方式大量发送的数据,目标是低延迟处理)处理技术来处理大量数据
29.多线程编程
通常使用Thread类、Task类或线程池来实现。并且在过程中可能会遇到线程安全、死锁、资源竞争等问题,那么为了解决这些问题,可以使用锁、信号量、互斥量等同步机制,以及采用适当的线程安全数据结构来确保多线程的正确性和性能
30.什么是LINQ?
是C#中的语言集成查询功能,可以让开发人员使用类似SQL的语法来进行数据查询和操作
// 指定数据源 int[] scores = [97, 92, 81, 60]; // 定义查询表达式 IEnumerable<int> scoreQuery = from score in scores where score > 80 select score; // 执行查询 foreach (var i in scoreQuery) { Console.Write(i + " "); } // 输出: 97 92 81
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
31.C#修饰符有哪些?有什么区别?
- 访问修饰符:类、属性和方法的定义分级制度;一个成员只能有一个访问修饰符,使用 protected internal组合时除外。
- Public:公有的,访问无限制
- Internal:内部的,仅同一个程序集中可访问
- Private:私有的,只有在声明它的类和结构中可访问
- Protected:受保护的,仅在该类和其派生类中可访问
- 类修饰符:
- abstract: 抽象类,可以被指示一个类只能作为其它类的基类.
- sealed: 表示一个类不能被继承.
- static:修饰类时表示该类是静态类,不能够实例化该类的对象,该类的成员为静态.
- 成员修饰符:
- abstract:指示该方法或属性没有实现.
- const:指定域或局部变量的值不能被改动.
- event:声明一个事件.
- extern:指示方法在外部实现.
- override:对由基类继承成员的新实现.
- readonly:指示一个域只能在声明时以及相同类的内部被赋值.
- Partial:在整个同一程序集中定义分部类和结构
- Virtual:用于修饰方法、属性、索引器或事件声明,并且允许在派生类中重写这些对象
- New:作修饰符,隐藏从基类成员继承的成员,在不使用 new 修饰符的情况下隐藏成员是允许的,但会生成警告。作运算符,用于创建对象和调用构造函数。
32.程序集
Unity
1. 函数生命周期
Awake->OnEnable->Start->FixedUpdate->Update->LateUpdate->OnDisable->OnDestory
- Awake 一般用来实现单例,场景开始时每个对象调用一次,如果对象处于非活动状态,则在激活状态后才会调用Awake
- OnEnable 在启用对象后立即调用此函数,在场景中有可能会重复调用(反复隐藏和激活)
- Start在对象第一次被启用时调用,用于初始化。与Awake类似,但Start在Awake之后调用。
- FixedUpdate通常用来进行物理逻辑的更新,其频率常常超过Update。在里面进行应用运动计算时,无需将值乘以Time.deltaTime.因为FixedUpdate的调用基于可靠的计时器(独立于帧率)
- Update 每帧调用一次。用于帧更新的主要函数
- LateUpdate通常用来进行摄像机的位置更新,以确保角色在摄像机跟踪其位置之前已经完全移动
- OnDisable 在隐藏对象后立即调用此函数,在场景中有可能会重复调用(反复隐藏和激活)
- OnDestroy在对象被销毁时调用,用于进行最终的清理工作和资源释放。
2. 什么是万向锁?如何避免?四元数相对于欧拉角的优点?
一旦选择±90°作为Picth(倾斜)角,就会导致第一次旋转和第三次旋转等价,从而表示系统被限制在只能绕竖直轴去旋转,丢失了一个表现维度;
解决方法:用四元数可以避免万向锁的产生,缺点是耗费一定的内存,但是目标可以任意旋转,自由度高
无万向锁问题;计算效率更高;插值效果更好
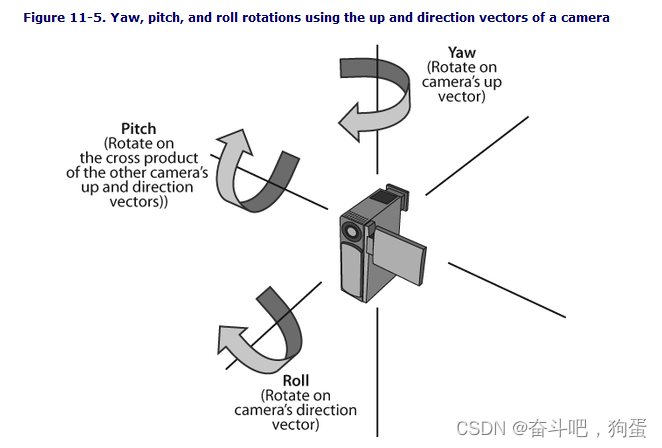
3. 什么是进程、线程、协程?区别是什么
- 进程:
- 是操作系统中一个独立的执行单位,每个进程都有自己独立的内存空间和系统资源
- 进程之间相互独立,无法直接共享内存,进程间通信需要特殊的机制,如管道、消息队列等
- 每个进程都有自己的地址空间,因此进程间的数据隔离性较好
- 进程启动、切换和销毁都需要较大的开销,因此进程的创建和切换相对较慢
- 线程:
- 是进程中的一个执行单元,多个线程共享同一个进程的内存空间和系统资源
- 线程之间可以直接访问共享内存,因此线程间通信较为简单,但是要注意线程安全
- 线程共享进程的地址空间,因此线程间的数据共享和通信较为方便
- 线程的创建、切换和销毁开销相对较小,因此线程的创建和切换相对较快
- 协程:
- 是一种轻量级的线程,可以在程序中实现多个执行流程,但不同于线程,协程由程序员自己管理,不依赖于操作系统的线程调度
- 可以在同一个线程内实现多个执行流程的切换,不需要进行线程切换,因此开销较小
- 通常用于实现异步操作、事件处理等场景,可以有效的提高程序的并发性和响应性
综上,进程是操作系统分配资源的基本单位,线程是操作系统调度执行的最小单位,而协程是程序员自己管理的一种轻量级执行流程。它们的主要区别在于资源分配、通信方式、数据隔离和开销等方面
4. 物体发生碰撞的必要条件
两者必须要有碰撞体,其中一个物体必须要有刚体,且在检测层级中两者是能产生碰撞检测的
5. 碰撞器和触发器之间的区别
碰撞器是用于检测物体之间碰撞的组件,当两个碰撞体接触时,会相互作用,产生物理效果,从而改变物体的运动状态
触发器也是一种碰撞器,但是不会产生物理效果,而是用于检测物体之间的进入和离开
6. 有几种施加力的方式?
Rigidbody.Addforce() //这种力可以是持续性的,也可以是瞬时的
Rigidbody rb = GetComponent<Rigidbody>();
rb.AddForce(Vector3.forward * forceAmount);
- 1
- 2
Rigidbody.AddTorque() //在物体上施加扭矩(旋转力)
Rigidbody rb = GetComponent<Rigidbody>();
rb.AddTorque(Vector3.up * torqueAmount);
- 1
- 2
直接改变Rigidbody的velocity属性可以施加速度,但是不会产生物理效果,而是改变物理的速度
Rigidbody rb = GetComponent<Rigidbody>();
rb.velocity = new Vector3(velocityX, velocityY, velocityZ);
- 1
- 2
Rigidbody.MovePosition() //直接设置物体的位置,会受到物理引擎的影响,可以直接穿过碰撞器
Rigidbody rb = GetComponent<Rigidbody>();
rb.MovePosition(rb.position + Vector3.forward * speed * Time.deltaTime);
- 1
- 2
7. 动画分层
用来管理不同身体部位的复杂状态机。可以将不同的动画逻辑分组处理。从而可以分离动画组、规范动画制作、提供更丰富的动画制作
8. 什么是IK?
根据目标位置和约束条件来计算物体的关节角度,以使其末端达到预定的目标位置。并且,通过计算关节的位置和旋转来实现目标末端的位置约束,而不是直接控制关节的每个运动,这样使得目标位置变化时,系统可以自动调节关节的角度以保持末端的位置不变。
9. 游戏动画有哪几种类型,以及其原理?
- 关键帧动画: 在动画序列的关键帧中记录各个顶点的原位置及其改变量,然后通过插值运算实现动画效果
- 骨骼动画: 骨骼按照角色的特点组合成一定的层次结构,有关节相连,通过对骨骼的变换来实现动画效果,而皮肤作为单一的网格蒙在骨骼之外,用来决定角色的外观
- 关节动画: 将角色分为若干部分,每一部分对应一个网格模型,部分的动画连接成一个整体的动画,通过改变模型顶点的变化来进行插值播放,从而实现动画效果
10. 什么是FSM有限状态机?
将对象的行为抽象为一系列状态,对象在不同的状态之间转换,从而实现不同的行为和动作
通常一个FSM由以下要素组成
- 状态:对象可能处于的各种状态,每个状态都有对应的行为和过渡条件
- 转换:状态之间的转换条件
- 行为:对象在特定状态下执行的行为或动作
- 状态机:管理状态和状态之间的转换
11. 在场景中放置多个摄像机且同时处于活动状态会发生什么?
多个相机的图像叠加在一起
12. unity中摄像机的Clipping Planes的作用是什么?调整Near、Far的值时要注意些什么?
用于定义摄像机能够渲染的场景空间的范围
Near:指定摄像机能够渲染的最近距离的平面。任何距离摄像机近于此平面的对象都将被裁剪不会被渲染
Far:指定摄像机能够渲染的最远距离的平面。任何距离摄像机远于此平面的对象统一也会被裁剪。
过小的Near值会导致渲染不完整或产生Z-fighting(z缓冲冲突)现象。过大也会影响渲染精度
过小的Far值会导致远处的景物不会被渲染,过大的Far值会导致渲染性能下降
13. 有几种光源?分别是什么?
区域光源:在实时光照模式下是无效的,仅在烘培光照模式下有用
点光源:模拟电灯泡的照射效果
平行光源:模拟太阳光效果
聚光灯:模拟聚光灯效果
14. 什么是LightMap?
在三维软件中打好灯光,然后渲染把场景中各表面的光照输出到贴图上,最后通过引擎贴到场景中,从而使得物体有了光照的效果
共有两种:实时光照贴图和烘培光照贴图。前者根据实时的光照变换动态更新,适用于需要动态光照效果的场景,性能开销大,后者是预先计算好的光照贴图,但是只适用于静态的场景或光照不发生变换的情况下
15. 两种阴影的判断方法以及工作原理
本影:物体表面上那些没有被光源直接照射的区域(表现上是全黑的轮廓分明的区域)
半影:物体表面上那些被某些特定光源直接照射但并非被所有特定光源直接照射的区域(表现上是半明半暗区域)
从光源处向物体的所有可见面投射光纤,将这些面投影到场景中得到投影面,再将这些投影面与场景中的其他平面求交得出阴影多边形,保存这些阴影多边形信息,然后再按视点位置对场景进行相应处理得到所要求的试图(利用空间换时间,每次只需依据试点位置进行一次阴影计算即可,省去了一次消隐过程)
16. unity中的基类是什么?
Object类,是所有对象的基类
17. 当一个细小的高速物体撞向另一个较大的物体时,会出现什么情况?如何避免?
可能会直接穿透过去,并且不会产生碰撞效果
- 使用合适的碰撞体
- 尽量限制高速运动或增加约束
- 使用连续碰撞检测,将Rigidbody中的Collider Detection改成Continuous
- Discrete:这是默认的选项。在此模式下,Unity会在物体的每一帧中检测碰撞器之间的碰撞。这种方法可以确保对碰撞的检测是准确的,但是可能会牺牲性能。
- Continuous:在此模式下,Unity会在物体的运动路径上进行连续的碰撞检测,以便更准确地检测到高速移动的物体之间的碰撞。这种方法能够减少物体之间的穿透,但是会消耗更多的计算资源。
- Continuous Dynamic:与Continuous相似,但是只有在动态(运动中)的物体之间才进行连续碰撞检测。静态(不运动)物体之间的碰撞仍然使用离散检测。
- Continuous Speculative:这是最低开销的选项,同时也是最不准确的选项。它使用一种更快速但不太准确的碰撞检测方法,可以用于大量物体之间的碰撞检测。这种方法的结果可能不太精确,尤其是在高速运动和物体之间的接触点。
18. 向量的点乘、 叉乘以及归一化
点乘:两个向量的点乘是它们对应分量的乘积之和,可以用来衡量两个向量的相似程度或在同一方向上的投影,例如计算两个向量之间的夹角、得到投影长度、判读目标物体相对于自己的前后
叉乘:两个向量的叉乘是一个新的向量,其方向垂直于原始向量构成的平面,可以用来描述原始向量构成的平面的法线方向和大小,例如在转向时判断最优转向角,根据敌人的方位判断哪个方向转向速度最快、判读目标物体相对于自己的左右或内外
归一化:将其长度缩放为1,使其变成单位向量,从而方便计算中使用,且保留了原始向量的方向信息,例如只关心物体的朝向而不关系其速度时,纹理坐标的生成
19. 什么是LOD?优缺点是?
根据摄像机和物体之间的距离,动态的调整物体模型的细节级别,从而在保持视觉质量的前提下降低渲染负载
- 优点:提高性能、节省资源、提高视觉一致性
- 缺点:需要额外的开发工作(需要不同细节层次的模型)、可能会产生肉眼可见的模型过渡效果、占用内存
20. 什么是MipMap?优缺点是?
类似LOD,只不过LOD针对的是模型,MipMap针对的纹理贴图资源。使用MipMap后,摄像机会根据距离的远近,选择不同精度的贴图
- 优点 :减少纹理锯齿现象、节省显存和带宽、提高渲染性能
- 缺点:增加内存占用、增加了纹理文件的大小
21. 什么是DrawCall?如何降低DrawCall
CPU向GPU发送指令来渲染一个或多个物体的过程。每个DrawCall都会触发GPU执行一次绘制操作,包括设置渲染状态、传递顶点数据和纹理等。DrawCall的增加会导致渲染性能下降
- 合批:将多个物体合并为一个批次进行渲染。其中分为静态合批和动态合批。
- 静态合批:是在构建时完成的。将具有相同材质和渲染模式的静态物体合并到一个批次中。适用于不会发生变换的静态物体,且合并后不能再进行移动和缩放了
- 动态合批:在运行时根据将共享同一材质的物体合并到一个批次中进行渲染。这种合批方式支持物体的移动和缩放
- 使用纹理集:将多个小纹理合并到一个大纹理图集中,减少纹理切换
- 使用GPU Instancing:允许使用相同的网格和材质实例化多个物体
- 减少透明物体:透明物体需要进行深度排序和透明度混合
- 优化UI渲染:尽量保持在只有一个画布,因为一个canvas就会增加一个DrawCall;使用图集;一个界面最好统一一个字库;
22. 当游戏中需要频繁的创建一个物体对象时,该怎么做去节省内存?
可以使用对象池,那什么是对象池呢?
- 对象池中,存放着需要被反复调用资源的一个空间,例如射击游戏中的子弹,大量的Instantiate()来创建新的对象和Destory()销毁对象,对内存消耗极大。
- 原理:一开始创建一些物体,并将其隐藏起来,对象池就是这些物体的集合,可以是UI中的无限循环列表元素,也可以是物体,当需要使用时,再将其激活使用,超过使用范围时再将其隐藏起来,通常来说,一个对象池存储的都是一类对象(也可以用字典来创建对象池,这样能指定每个对象池存储对象的类型,同时也可以用tag去访问相应的对象池)
public class BulletsPool : MonoBehaviour { //单例,提供全局访问节点,并且保证只有一个子弹对象池存在 public static BulletsPool bulletsPoolInstance; public GameObject bulletObj;//子弹实例 public int pooledAmount = 50;//预存储对象池的大小 public bool lockPoolSize = false;//是否可以动态扩容 private List<GameObject> pooledObjects;//用一个列表来存储对象,即对象池 private int currentIndex = 0;//当前的索引 void Awake() { bulletsPoolInstance = this; } void Start() { pooledObjects = new List<GameObject>();//实例化 for (int i = 0; i < pooledAmount; ++i)//生成对象池并填充 { GameObject obj = Instantiate(bulletObj); obj.transform.SetParent(gameObject.transform); obj.SetActive(false); pooledObjects.Add(obj); } } public GameObject GetPooledObject() { for (int i = 0; i < pooledObjects.Count; ++i) { //这里其实是一个贪心算法,当一个对象被激活时, //如要激活下一个对象,索引是从上一个对象开始,而不是从头开始查找 int temI = (currentIndex + i) % pooledObjects.Count; if (!pooledObjects[temI].activeInHierarchy) { currentIndex = (temI + 1) % pooledObjects.Count; return pooledObjects[temI]; } } //如果没有固定对象池大小,则往列表中添加预制件 //(因为列表是可以动态扩容的,所以不用担心会出现越界) if (!lockPoolSize) { GameObject obj = Instantiate(bulletObj); pooledObjects.Add(obj); return obj; } return null; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
/*用法也很简单,获取对象池中的预制件,如果不为空,则将其激活,并将其的坐标放到开火点,并发射出去,
当其撞到敌人或者墙时,播放相应的粒子特效,然后将其隐藏起来,用来下次激活(这里没有列出代码,原理和激活相同)*/
GameObject bullet=BulletsPool.bulletsPoolInstance.GetPooledObject();
if (bullet != null)
{
bullet.SetActive(true);
bullet.transform.position = firePoint.position;
bullet.transform.rotation = Quaternion.Euler(new Vector3(0, 0, Random.Range(-15, 20)));
bullet.GetComponent<Bullet>().SetDirection(Mathf.Sign(transform.localScale.x));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
23. MeshRender中Material和SharedMaterial的区别
修改Material会重新生成一个新的Material到内存中,然后修改后的物体就使用这个新的材质,但是,在销毁物体时,需要手动去销毁该Material,不然会一种存在于内存中。
修改SharedMaterial将改变所有使用这个材质的物体的外观,并且也会改变存储在工程中的材质设置
24. 如何优化内存
- 资源压缩
- 合理使用资源
- 动态管理资源
- 使用对象池
- 避免频发的GC
- 减少不必要的数据调用
- 避免内存泄漏
25. Unity资源加载的方式
- 直接引用资源:
- 将资源直接拖拽到代码中的公共字段上,Unity 编辑器会自动关联资源。
- 这种方式适用于那些在编辑器中已经确定的资源,并且在代码中不需要动态加载的情况。
- Resources 文件夹:
- 将资源放置在项目中的 “Resources” 文件夹下,然后使用 Resources.Load 方法动态加载。
- 这种方式适用于需要在运行时动态加载资源,但是资源需要打包在应用程序中的情况。
- AssetBundle:
- 使用 AssetBundle 来打包和加载资源,可以将资源打包成独立的文件,并在运行时动态加载。
- 这种方式适用于需要动态下载或更新资源、需要异步加载资源、或者需要优化应用程序包大小的情况。
- Addressable Assets:
- 使用 Unity 的 Addressable Assets System 进行资源管理,可以更灵活地管理和加载资源,支持远程加载、版本控制、按需加载等功能。
- 这种方式适用于需要高度灵活性和扩展性的项目,特别是对于大型项目或需要频繁更新的项目。
26. 如何优化资源加载
- 资源打包和压缩:可以使用AssetBundle,将资源打包成独立的文件,并且通过同步或异步加载的方式加载加载带游戏中,从而减少初始加载时间和内存占用
- 异步加载资源,从而避免堵塞主线程
- 资源的缓存和复用,例如使用对象池
- 优化资源的格式,例如对于纹理资源,可以使用压缩格式(ETC、ASTC、PVRTC)来减少文件大小,并且可以使用MipMap来提高渲染性能
- 动态加载和卸载资源
27. 什么是AssetBundle?有什么好处?和Resource的加载的区别
是unity中一种用于打包和加载资源的机制。它允许将游戏中的资源文件(如模型、纹理、音频、动画等)打包成独立的文件,并且在运行时动态加载到游戏中,但是,代码是无法动态加载进入的,如果有需要可以使用热更新。
- 资源的分离和管理,并且其中共有三种压缩方式,分别是
- Uncompressed 压缩:不进行任何压缩,直接打包原始资源。这种方式适用于资源本身已经经过了压缩(如 JPEG、PNG 图片),再次压缩反而会增加负担的情况。
- ChunkBasedCompression 压缩:这种方式是根据资源的类型和特性,分块进行压缩,适用于需要根据不同资源采用不同的压缩策略的情况。
- LZMA 压缩:LZMA 是一种高效的压缩算法,能够在保证较高压缩率的同时,保持加载速度相对合理。这种压缩方式适用于需要较小体积的 AssetBundle,但加载速度相对较慢的情况。
- 资源的异步加载
- 资源的更新和热更新
- 资源的加密和安全性
- 资源的共享和重用
- Resource只能加载放置在“Resources”文件夹的资源,而AssetBundle可以将多个资源打包成一个独立的文件(或多个文件)
- Resource加载的资源会在打包时将放置在“Resources”文件夹的资源全部被打入应用程序包中,无论是否使用到,这样会徒增包体的大小,而AssetBundle可以有选择性的使用需要的文件
- Resource加载只适用于简单的、固定的资源加载,AssetBundle更适合于有较多迭代需求、需要热更新或需要优化包体大小的游戏
28. 什么是渲染管道?
是指在图形渲染过程中,图形数据从输入到最终输出的一系列处理步骤和阶段,即将场景中的模型、材质、光照等信息转换成最终的图像输出到屏幕上
共分为四个阶段
- 应用阶段:在这个阶段,cpu将决定传递GPU什么样的数据,并告诉GPU这些数据的渲染状态
- 几何阶段:又分为几个常见的渲染阶段
- 放入显存和DrawCall
- 顶点着色器
- 曲面细分着色器
- 几何着色器
- 投影
- 裁剪
- 屏幕映射
- 光栅化阶段:因为在前面几个阶段只是得到了顶点信息,还不能被显示在屏幕上的像素,所以还要进行处理
- 图元组装
- 三角形遍历
- 片元着色器
- 逐片元操作
- 输出到屏幕
参考图:
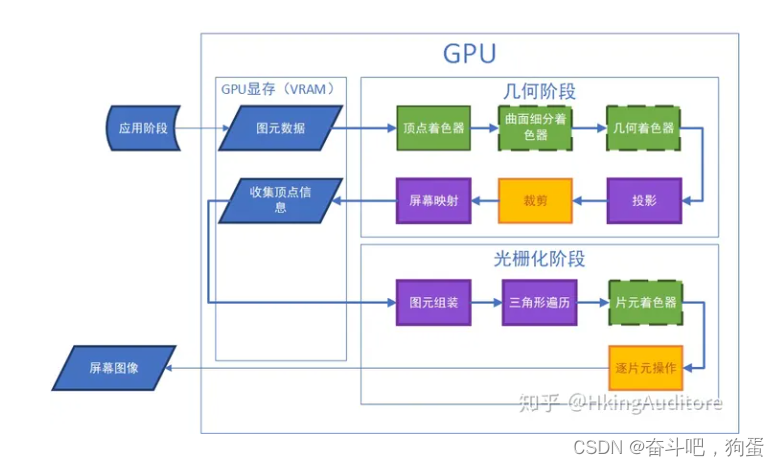
参考链接:猴子也能看懂的渲染管线
29. GPU的工作原理?
通过并行处理、流水线架构、高效的内存访问和着色器编程等技术,实现对图形和图像处理任务的高效执行
30. 在编辑场景时将GameObject设置为Static有何作用?
前提是在运行时不会移动和形变
- 静态合批
- 静态对象可以参与光照贴图的计算,让光照效果更加真实和高效
- 碰撞检测的优化
31. 有两个物体,如何让一个物体永远比另一个物体先渲染?
- 调整物体的渲染顺序(Sorting Layer)
- 调整物体距离相机的距离,越近的越先渲染
32. 客户端和服务器交互方式有哪几种?
- Http :适用于简单的数据交换,如获取或提交数据
- WebSocket: 允许客户端和服务器之间建立持久连接,并通过双向通信进行数据交换,常用于实时性较高的应用,如聊天、在线游戏等
- TCP/IP(Socket):使用TCP/IP协议的套接字进行通信,客户端和服务器之间建立连接后,可以通过套接字进行双向数据传输。适用于需要高度定制化的网络通信,如实时视频流、文件传输等
- RPC:远程过程调用是一种编程模型,允许客户端调用服务器上的远程方法,并获取返回结果。常用于分布式系统中的模块化通信
- 消息队列 :是一种异步通信机制,客户端将消息发送到消息队列中,服务器从队列中接收消息并进行处理。常用于解耦客户端和服务器之间的通信,实现高可靠性和高可扩展性。
33. UnityEditor
用于编辑器扩展和自定义的命名空间。可以编写自定义的编辑器工具、窗口、菜单项等,从而增强开发效率
34.
35. 常用的特性和技术
- 物理引擎(Physics Engine):Unity内置了强大的物理引擎,可以模拟物体之间的碰撞、重力、摩擦等物理效果。
- 图形渲染(Graphics Rendering):Unity提供了先进的图形渲染功能,包括基于物理的渲染(Physically Based Rendering,PBR)、光照和阴影、后处理效果等,可以创建高质量的视觉效果。
- 动画系统(Animation System):Unity的动画系统支持骨骼动画、顶点动画、物理动画等多种动画类型,可以创建生动的角色和物体动画。
- 粒子系统(Particle System):Unity的粒子系统可以创建各种特效,如火焰、烟雾、爆炸等,丰富游戏场景的表现力。
- 碰撞检测(Collision Detection):Unity提供了灵活的碰撞检测功能,可以检测物体之间的碰撞,并触发相应的事件。
- 脚本编程(Scripting):Unity支持使用C#、JavaScript等编程语言编写脚本,可以控制游戏对象的行为、交互和逻辑。
- UI系统(UI System):Unity的UI系统提供了丰富的UI元素和控件,可以创建用户界面、菜单、按钮等,方便构建用户友好的游戏界面。
- 音频系统(Audio System):Unity可以处理游戏中的音频效果和音乐,包括声音的播放、混音和空间化等功能。
- 网络功能(Networking):Unity提供了多种网络功能,包括实现本地多人游戏和在线多人游戏的功能。
- 资源管理(Asset Management):Unity的资源管理功能可以管理游戏中的各种资源,包括模型、纹理、声音、动画等。
36. 当场景中有大量的碰撞或复杂物理场景时,该怎么去优化?
- 如有可能的话,减少刚体数量
- 优化碰撞体,让碰撞体的形状尽可能的简单,避免使用过于复杂的MeshCollider,而是使用更简单的形状
- 批量处理,如有多个相似的物体需要进行模拟,可以尝试合并成一个复合刚体
- 使用不同的层级,避免不必要的碰撞检测
- 利用物理引擎设置,可以通过更改物理迭代次数和时间步长
- 避免频繁的状态改变,例如频繁的启用/禁用,切换成动/静态
- 使用空间分割算法,如四叉树和八叉树(详情可见下面的算法介绍),来进行碰撞检测。这些算法可以将空间切割成更小的区域,每个区域包含一定数量的物体。这样,在进行碰撞检测时,可以只对相邻区域中的物体进行检测,从而减少计算量。
37.假如有几百个排行榜item要显示,你该怎么去做?
可以使用无限循环滚动列表,这样做的话就不用全部生成出来了,性能开销小
- 核心思想就是当滑动框滑动时,判断第一个和最后一个item距离显示框边缘的距离,如果大于item间隔*0.5+item的高或宽度,则把这个item放到最后或最前的位置,每向上或向下就自增自减索引值,并且根据当前索引值来从数据列表中读取item中要更新的数据
38. UGUI的画布有几种模式?分别是什么?
- Screen Space-Overlay:画布位于屏幕空间的最上方,覆盖在其他所有内容之上。这种模式常用于UI元素不需要与场景中的3D物体交互的情况,例如游戏菜单、提示信息等。
- Screen Space-Camera:画布位于相机的前方,但不与3D场景中的其他物体交互。可以通过设置画布的Render Camera属性来指定相机。这种模式通常用于需要与3D场景中的物体进行交互,但仍然在屏幕空间内的UI,比如角色头顶的血条、NPC对话框等。
- WorldCamera:画布位于3D世界中的某个位置,可以与3D场景中的其他物体进行交互。这种模式允许UI元素随着场景中的物体移动、旋转和缩放,适用于需要与3D环境完全融合的UI,比如游戏中的虚拟现实界面、HUD(头顶显示)等。
39. unity中有一个保存读取数据的类,是什么?其中保存读取整形数据的函数是什么?
PlayerPrefs。它可以存储和检索整数、浮点数、字符串和其他数据类型
要保存整数数据,可以使用 PlayerPrefs.SetInt(string key, int value) 函数,其中参数 key 是数据的键,value 是要保存的整数值。例如:
PlayerPrefs.SetInt("Score", 100);
- 1
要读取保存的整数数据,可以使用 PlayerPrefs.GetInt(string key) 函数,传入要读取的数据的键,并返回相应的整数值。例如:
int score = PlayerPrefs.GetInt("Score");
- 1
40. 如何检测物体是否被其他对象遮挡?
射线投射: 发射一条射线,然后检查射线是否与其他物体相交。如果相交,说明物体被遮挡了。这种方法适用于2D和3D场景。
RaycastHit hit;
if (Physics.Raycast(transform.position, transform.forward, out hit, maxDistance))
{
// 检测到了遮挡物体,hit 中包含了被遮挡物体的信息
Debug.Log("Object is occluded by: " + hit.collider.name);
}
- 1
- 2
- 3
- 4
- 5
- 6
41.敌人的寻路逻辑如何进行设计?
设计模式
1. 什么是设计模式
设计模式是一套被反复使用、多数人知晓、经过分类编目、代码设计经验的总结。
2. 设计模式的七大原则
- 开闭原则:对扩展开放,对修改封闭
- 单一职责原则:一个类只负责一个功能领域中的相应职责
- 里氏转换原则:所有引用基类的地方必须能透明的去使用其子类的对象
- 依赖倒转原则:依赖于抽象,不能依赖于具体实现
- 接口依赖原则:类之间的依赖关系应该建立在最小的接口上
- 合成/聚合复用原则:尽量使用合成/聚成,而不是通过继承来达到复用的目的
- 最少知识原则(迪米特法则):一个软件应当尽可能少的和其他实体发生相互作用
3. 工厂模式
总结:方便创建同种产品类型的复杂参数对象;重点就是适用于构建同产品类型(同一个接口 基类)的不同对象时,这些对象new很复杂,需要很多的参数,而这些参数中大部分都是固定的,这时用工厂模式就很方便。
简单工厂模式:通过一个工厂类来创建对象,根据传入的参数来决定创建出的对象。
优点是简单易用,只需要传递一个正确的参数就能获取所需对象而无需知道其创建细节
缺点是扩展性差,当要增加新的产品时还需要去修改工厂类的逻辑,违反开闭原则
大致实现:
- 抽象产品类:提供抽象方法供具体产品类实现
public abstract class Phone
{
abstract void produce();
}
- 1
- 2
- 3
- 4
- 具体产品类:提供具体的产品
public class ApplePhoneImpl : Phone
{
public override void produce()
{
Debug.Log("生产苹果手机");
}
}
public class RedmiPhoneImpl : Phone
{
public override void produce()
{
Debug.Log("生产了红米手机");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 工厂:根据内部逻辑返回相应的产品
public class Factory { public Phone getPhone(String type) { Phone phone = null; if ("红米"==type) { phone = new RedmiPhoneImpl(); } else if ("苹果" == type) { phone = new ApplePhoneImpl(); }//..... return phone; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 具体使用:
public void Test()
{
Factory factory = new Factory();
Phone redmiPhone = factory.getPhone("红米");
Debug.Log(redmiPhone);
redmiPhone.produce();
Phone applePhone = factory.getPhone("苹果");
Debug.Log(applePhone);
applePhone.produce();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
工厂方法:定义一个创建对象的接口,让子类决定实例化哪个类。
优点是符合开闭原则,当需要增加新的产品时,只需要增加一个具体的产品类和与之对应的工厂即可,无需修改原系统。
缺点是复杂度会增加,因为新加一个产品需要创建两个类
大致实现:
- 抽象产品类:提供抽象方法供具体产品类实现
public abstract class Phone
{
abstract void produce();
}
- 1
- 2
- 3
- 4
- 具体产品类:提供具体的产品
public class ApplePhoneImpl : Phone
{
public override void produce()
{
Debug.Log("生产苹果手机");
}
}
public class RedmiPhoneImpl : Phone
{
public override void produce()
{
Debug.Log("生产了红米手机");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 抽象工厂:提供抽象方法供具体工厂实现
public abstract class Factory
{
public abstract Phone getPhone();
}
- 1
- 2
- 3
- 4
- 具体工厂:提供具体的工厂
public class AppleFactoryImpl:Factory
{
public override Phone getPhone()
{
return new ApplePhoneImpl();
}
}
public class RedmiFactoryImpl:Factory
{
public override Phone getPhone()
{
return new RedmiPhoneImpl();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 具体实现:
public void Test()
{
Factory applePhoneFactory = new AppleFactoryImpl();
Factory redmiPhoneFactory = new RedmiFactoryImpl();
Phone applePhone = applePhoneFactory.getPhone();
Phone redmiPhone = redmiPhoneFactory.getPhone();
Debug.Log(applePhone);
Debug.Log(redmiPhone);
applePhone.produce();
redmiPhone.produce();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
抽象工厂:创建相关或依赖对象的家族,而无需明确指定具体类。
优点:隔离了具体类的生成,无需关系创建细节;对于新增产品,很好的支持了开闭原则;将一个系列产品统一到一起创建
缺点:新增新的行为比较麻烦,因为当添加一个新的产品对象时,需要更改接口及其下所有子类;增加了系统的抽象度
大致实现:
- 抽象产品类:为每种具体产品声明接口
public abstract class Phone
{
public abstract void produce();
}
public abstract class Charger
{
public abstract void produce();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 具体产品类:定义了工厂生产的具体产品对象,实现抽象产品接口声明的业务方法
/************苹果具体的产品**************/ public class AppleChargerImpl : Charger { public override void produce() { Debug.Log("生产苹果充电器"); } } public class ApplePhoneImpl:Phone { public override void produce() { Debug.Log("生产苹果手机"); } } /************红米具体的产品**************/ public class RedmiChargerImpl: Charger { public override void produce() { Debug.Log("生产红米充电器"); } } public class RedmiPhoneImpl : Phone { public override void produce() { Debug.Log("生产了红米手机"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 抽象工厂:声明了一组用于创建一种产品的方法,每一个方法对应一种产品
public abstract class Factory
{
public abstract Phone getPhone();
public abstract Charger getCharger();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 具体工厂:实现了在抽象工厂中定义的创建产品的方法,生成一组具体产品,这组产品构建成一个产品种类,每个产品都位于某个产品等级结构中。
public class AppleFactoryImpl : Factory { public override Phone getPhone() { return new ApplePhoneImpl(); } public override Charger getCharger() { return new AppleChargerImpl(); } } public class RedmiFactoryImpl : Factory { public override Phone getPhone() { return new RedmiPhoneImpl(); } public override Charger getCharger() { return new RedmiChargerImpl(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 大致实现:
public void test1() { Factory appleFactory = new AppleFactoryImpl(); Phone applePhone = appleFactory.getPhone(); Charger appleCharger = appleFactory.getCharger(); Debug.Log(appleFactory); applePhone.produce(); appleCharger.produce(); Factory redmiFactory = new RedmiFactoryImpl(); Phone redmiPhone = redmiFactory.getPhone(); Charger redmiCharger = redmiFactory.getCharger(); Debug.Log(redmiFactory); redmiPhone.produce(); redmiCharger.produce(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.单例模式
在整个游戏生命周期中,有很多对象从始至终有且只有一个,而这唯一的实例也只需要生成一次,并提供了一种访问其唯一的对象的方法,可以直接访问,不需要实例化该类的对象,直到游戏结束才会被销毁。所以,单例模式一般应用于管理器类或者是一些需要持久化存在的对象。
public sealed class Singleton
{
private static Singleton instance;
public static Singleton Instance()
{
get
{
if(instance==null)
instance=new Singleton();
return instance;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
------参考原文链接:单例模式的使用
单例模式也分为两种模式
- 饿汉模式:在类加载时就生成该单例对象
优点:简单方便;线程安全,调用时反应速度快
缺点:会降低启动速度;不关程序是否使用,都会创建该单例对象
应用场景:单例对象功能简单,占用内存小,需要频繁使用的时候
public class HungrySingLeton
{
private static HungrySingLeton instance;
private HungrySingLeton()
{
instance = new HungrySingLeton();
}
public static HungrySingLeton Instace
{
get{return instance;}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 懒汉模式:第一次调用时才创建该单例对象
优点:在需要时创建,利用率高;提高启动速度
缺点:多线程不安全,可能会创建多个实例
应用场景:单例对象功能复杂,内存占用大,需要快速启动
public class LazySingleton { private static LazySingleton _instance; public static LazySingleton Instace { get { if (_instance == null) { _instance = new LazySingleton(); } return _instance; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
------参考原文链接:引用代码链接
5.观察者模式
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
优点:
观察者和被观察者是抽象耦合的;有一套触发机制;支持广播通信
缺点:
如果一个被观察者有很多直接和间接的观察者时,通知所有关联的观察者会花费很多时间;
如果在观察者和被观察者之前有循环依赖的话,会进行循环调用,可能导致系统崩溃;
观察者是不知道观察目标是怎么发生变化的,只知道发生了变化
大致实现:(有一个微信公众号,不定时发布信息,关注公众号就可以获得推送,取消关注就不会再推送)
- 抽象被观察者:把所有观察者对象的引用保存在一个集合中,每个主题都可以有任意数量的观察者。
public interface ISubject
{
public void registerObserver(IObserver o);
public void removeObserver(IObserver o);
public void notifyObserver();
}
- 1
- 2
- 3
- 4
- 5
- 6
-具体被观察者:一个具体的主题,在具体主题的状态发生改变时,向所有关联的观察者发出通知
public class WechatServer: ISubject { private List<IObserver> list; private String message; public WechatServer() { list = new List<IObserver>(); } public void registerObserver(IObserver o) { // TODO Auto-generated method stub list.Add(o); } public void removeObserver(IObserver o) { // TODO Auto-generated method stub if (list.Count>0) { list.Remove(o); } } public void notifyObserver() { // TODO Auto-generated method stub foreach (var item in list) { item.update(message); } } public void setInfomation(String s) { this.message = s; Debug.Log("微信服务更新消息: " + s); // 消息更新,通知所有观察者 notifyObserver(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 抽象观察者:为所有的具体观察者定义一个接口,在得到改变通知时更新自己
public interface IObserver
{
public void update(String message);
}
- 1
- 2
- 3
- 4
- 具体观察者:实现抽象观察者角色的更新接口
public class User: IObserver { private String name; private String message; public User(String name) { this.name = name; } public void update(String message) { this.message = message; read(); } public void read() { Debug.Log(name + " 收到推送消息: " + message); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 具体使用:
public class Test { public static void main(String[] args) { WechatServer server = new WechatServer(); IObserver userZhang = new User("ZhangSan"); IObserver userLi = new User("LiSi"); IObserver userWang = new User("WangWu"); server.registerObserver(userZhang); server.registerObserver(userLi); server.registerObserver(userWang); server.setInfomation("PHP是世界上最好用的语言!"); Debug.Log("----------------------------------------------"); server.removeObserver(userZhang); server.setInfomation("C#是世界上最好用的语言!"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
计算机网络
1.计算机网络体系结构
- OSI七层模型
- 应用层:网络服务与最终用户的一个接口,常见的协议有:HTTP FTP SMTP SNMP DNS.
- 表示层:数据的表示、安全、压缩。,确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。
- 会话层:建立、管理、终止会话,对应主机进程,指本地主机与远程主机正在进行的会话.
- 传输层:定义传输数据的协议端口号,以及流控和差错校验,协议有TCP UDP.
- 网络层:进行逻辑地址寻址,实现不同网络之间的路径选择,协议有ICMP IGMP IP等.
- 数据链路层:在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路。
- 物理层:建立、维护、断开物理连接。
- TCP/IP四层结构
- 应用层:对应于OSI参考模型的(应用层、表示层、会话层)。
- 传输层: 对应OSI的传输层,为应用层实体提供端到端的通信功能,保证了数据包的顺序传送及数据的完整性。
- 网际层:对应于OSI参考模型的网络层,主要解决主机到主机的通信问题。
- 网络接口层:与OSI参考模型的数据链路层、物理层对应。
- 五层体系结构
- 应用层:对应于OSI参考模型的(应用层、表示层、会话层)。
- 传输层:对应OSI参考模型的的传输层
- 网络层:对应OSI参考模型的的网络层
- 数据链路层:对应OSI参考模型的的数据链路层
- 物理层:对应OSI参考模型的的物理层。
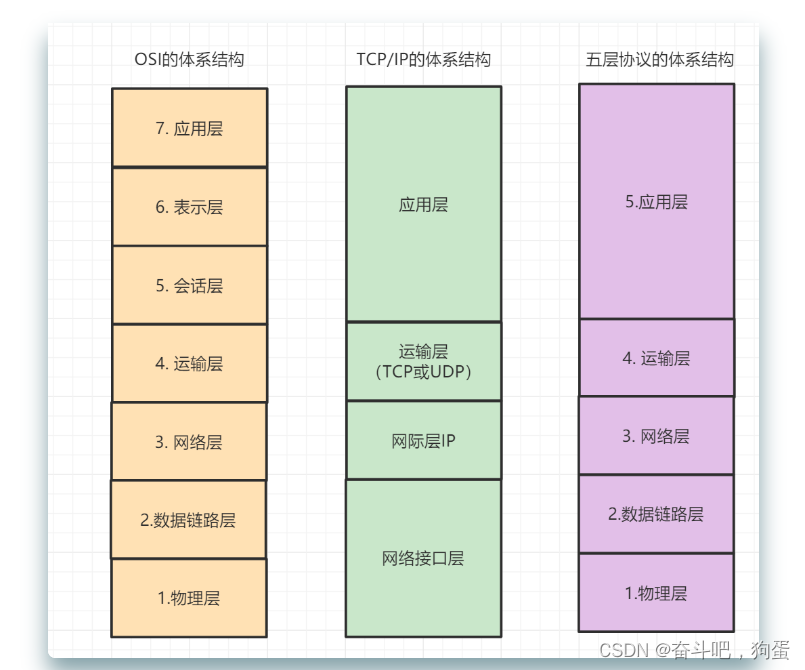
2.每一层对应的网络协议有哪些?
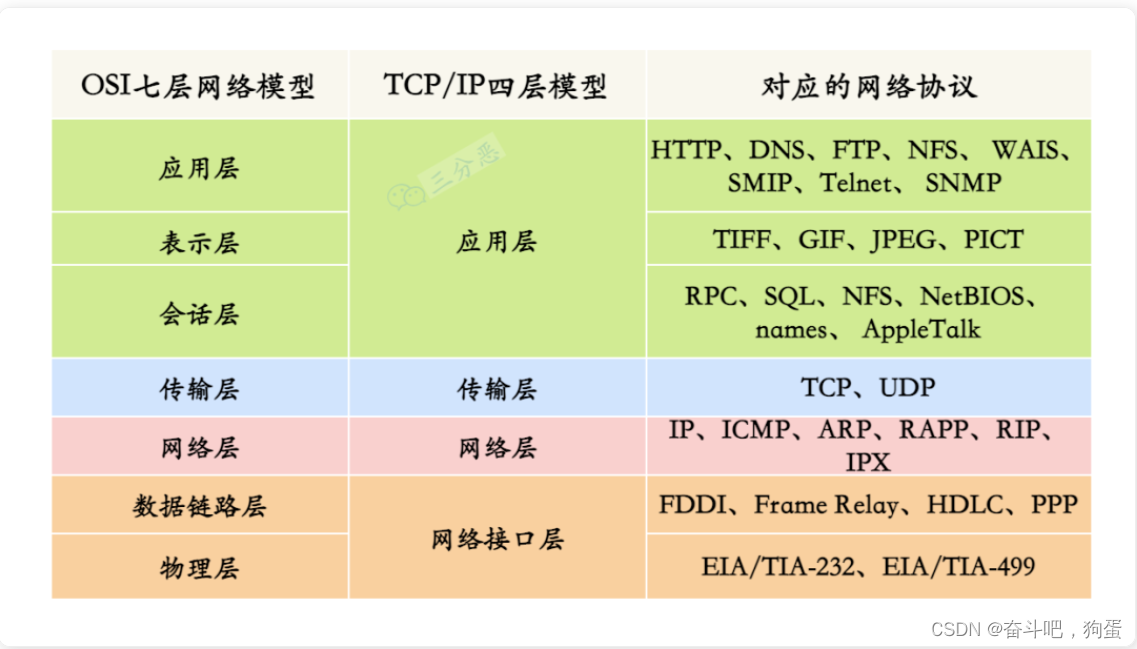
3. UDP、TCP、IP
UDP(用户数据报协议)
- 是一种简单的面向无连接的协议,它不保证数据的可靠性和顺序传输。
- 通过数据包的形式传输数据,每个数据包是独立的,不依赖于之前的数据包
- 提供了一种快速的数据传输方式,适用于实时性要求较高、对数据完整性要求不严格的场景,例如视频流传输等
- 优点:传输速度快,开销小
- 缺点:不可靠,容易丢数据包
TCP(传输控制协议)
- 是一种面向连接的、可靠、基于字节流的协议,通过建立连接、数据传输和连接释放等步骤来确保数据的可靠性和顺序传输
- 提供了一种流式的数据传输方式,数据在发送和接受之间建立的虚拟的连接,确保了数据的顺序和完整性,适合例如在文件传输、网页游览等场景下使用
- 优点:数据可靠、顺序传输
- 缺点:传输开销大、实时性较差
IP(互联网协议)
- 是一种网络层协议,用于在计算机网络中传输数据包
- 负责确定数据包的传输路径,并将数据包从源主机传输到目标主机
- 使用IP地址来唯一标识每个网络设备,以便正确的路由数据包
其中TCP/IP协议集合中还包含其他的一些协议,如UDP、HTTP、FTP等
4. 为什么网络要分层?
为了提高网络的可扩展性、灵活性和可维护性,以及降低系统的复杂度,原因如下
- 模块化设计:将网络功能划分为不同的层级可以将整个系统拆分为相对独立的模块,每个模块只需关注特定的功能,降低了系统的复杂度,便于设计、开发和维护。
- 标准化:分层设计使得每个层级的功能更加清晰和明确,便于标准化和规范化。每个层级的功能和接口都可以定义明确的标准,不同厂商或组织之间可以基于相同的标准进行交互和协作。
- 易于替换和升级:由于每个层级都相对独立,可以针对特定的需求或技术变化对网络中的某一层进行替换或升级,而不会影响到其他层级的正常运行。
- 性能优化:分层设计可以使得网络的优化更加容易。通过在不同层级进行优化,可以针对特定的需求和场景进行性能调优,提高网络的效率和响应速度。
- 隔离故障:每个层级都相对独立,网络中的故障往往只会影响到同一层级或相邻层级,不会影响到整个网络的正常运行。这种隔离性有助于快速定位和解决故障,提高了网络的可靠性和稳定性。
5.数据在各层之间是怎么传输的呢?
对于发送方而言,从上层到下层层层包装,对于接收方而言,从下层到上层,层层解开包装。
- 发送方的应用进程向接收方的应用进程传送数据
- AP 先将数据交给本主机的应用层,应用层加上本层的控制信息 H5 就变成了下一层的数据单元
- 传输层收到这个数据单元后,加上本层的控制信息 H4,再交给网络层,成为网络层的数据单元
- 到了数据链路层,控制信息被分成两部分,分别加到本层数据单元的首部(H2)和尾部(T2)
- 最后的物理层,进行比特流的传输
类似写信,每到一层,就加一个信封,写一些地址的信息,到达目标的后,又一层层的解封,传向下一个目的地
6. 如何优化网络性能
- 减少网络请求次数
- 压缩数据
- 缓存数据
- 使用CDN
- 使用性能更高的网络协议
- 减少数据传输量,避免非必要数据
7. 简述下三次握手和四次挥手
三次握手:
- 最开始,客户端和服务端都处于 CLOSE 状态,服务端监听客户端的请求,进入 LISTEN 状态
- 客户端端发送连接请求,第一次握手 (SYN=1, seq=x),发送完毕后,客户端就进入 SYN_SENT 状态(第一次握手服务端未收到 SYN 报文:服务端不会进行任何的动作,而客户端由于一段时间内没有收到服务端发来的确认报文,等待一段时间后会重新发送 SYN 报文,如果仍然没有回应,会重复这个过程,直到发送次数超过最大重传次数限制,就会返回连接建立失败。
- 服务端确认连接,第二次握手 (SYN=1, ACK=1, seq=y, ACKnum=x+1), 发送完毕后,服务器端就进入 SYN_RCV 状态。(第二次握手客户端未收到服务端响应等待ACK 报文:客户端会继续重传,直到次数限制;而服务端此时会阻塞在 accept()处,等待客户端发送 ACK 报文)
- 客户端收到服务端的确认之后,再次向服务端确认,这就是第三次握手(ACK=1,ACKnum=y+1),发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态。(第三次握手服务端为收到客户端发送过来的 ACK 报文:服务端同样会采用类似客户端的超时重传机制,如果重试次数超过限制,则 accept()调用返回-1,服务端建立连接失败;而此时客户端认为自己已经建立连接成功,因此开始向服务端发送数据,但是服务端的 accept()系统调用已经返回,此时不在监听状态,因此服务端接收到客户端发送来的数据时会发送 RST 报文给客户端,消除客户端单方面建立连接的状态)
简而言之就是:
二狗和老王是领居,你听到领居家的狗生孩子了,你要让耳背的老王知道狗生了,于是:
- 二狗:老王,我是二狗,你能听到吗?(第一次握手,进入等待发送状态,等待服务器确认)
- 老王一听,是二狗在叫他,于是出来回应说,二狗二狗,我是老王,你能听到我说话吗?(第二次握手,服务器确认无误,然后发送给客户端,并且服务器进入等待接收状态)
- 二狗听到是老王的声音没错,就说,我听到了,你家的狗生孩子了,赶紧把毯子给狗盖着。(第三次握手,客户端收到服务器的确认接受消息,再发送一条确认接受消息给服务器,然后客户端进入数据传输状态,当服务器接收到了这条消息后,也进入了数据传输状态)
- 老王听到了二狗说的话,就去拿了条毯子给狗盖着了
四次挥手:
- 数据传输结束之后,通信双方都可以主动发起断开连接请求,这里假定客户端发起
客户端发送释放连接报文,第一次挥手 (FIN=1,seq=u),发送完毕后,客户端进入 FIN_WAIT_1 状态。- 服务端发送确认报文,第二次挥手 (ACK=1,ack=u+1,seq =v),发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态。
- 服务端发送释放连接报文,第三次挥手 (FIN=1,ACK1,seq=w,ack=u+1),发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个 ACK。
- 客户端发送确认报文,第四次挥手 (ACK=1,seq=u+1,ack=w+1),客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT 状态,等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
简而言之就是:
单身汉二狗终于有了一个女朋友大花,但是由于二狗是程序员,996,没有时间陪大花,导致大花忍无可忍(由于双方都可以主动发起断开链接请求,所以这里假定大花=>服务器提的分手)
- 女朋友:二狗,最近你都不理我,是不是不爱我了?是不是在外面有别的狗了?我要和你分手(服务器发送释放链接报文第一次挥手,完成后,服务器进入等待状态-1)
- 二狗:分手就分手,不陪你闹了,等我把东西先收拾收拾(此时客户端答应了释放的请求,发送确认报文第二次挥手,发送完毕后,客户端进入了关闭等待-1状态,服务器接收确认包后,进入等待状态-2)
二狗收拾好了自己的行李(客户端进入了关闭等待-1状态)- 二狗:哼,我收拾好了,我先滚为敬,撒悠啦啦!(客户端发送释放链接报文第三次挥手,发送完毕后,进入LAST_ACK状态,等待服务器的最后一个ACK)
- 大花:滚,滚的远远的,越远越好,我一辈子都不行再看到你(服务器发送确认报文第四次挥手,服务器收到来自客户端的关闭请求,发送一个确认包,然后进入等待关闭状态,等待某个固定时间(2MSL)(为了保证客户端发送的最后一个 ACK 报文段能够到达服务端)后,没有收到客户端的ACK,就可以认为客户端已经关闭链接,于是自己也关闭链接。客户端收到这个确认包后,也关闭链接。
为啥需要四次挥手呢
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务端收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接。
从上面过程可知,服务端通常需要等待完成数据的发送和处理,所以服务端的 ACK 和 FIN 一般都会分开发送,从而比三次握手导致多了一次。
8. 为啥TCP握手不能是两次或四次呢?
为什么不能是两次?
- 为了防止服务器端开启一些无用的连接增加服务器开销
- 防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
为什么不是四次?
- 简单说,就是三次挥手已经足够创建可靠的连接,没有必要再多一次握手导致花费更多的时间建立连接。
9.WebSocket、Socket、HTTP
WebSocket、Socket 和 Http 都是网络通信中常用的协议,它们有着不同的特点和用途。
- WebSocket 是一种实现实时通信的协议,它可以在单个 TCP 连接上进行全双工通信。
- Socket 是一种用于进程间通信和网络通信的编程接口,它提供了一种底层的 API,使得开发人员可以根据自己的需要设计和实现各种网络协议。
- Http 是一种用于在 Web 浏览器和 Web 服务器之间传输数据的协议,它使用 TCP 作为传输协议,每个请求和响应之间是相互独立的。
WebSocket 和 Socket 相比,WebSocket 协议在实现实时通信方面更为方便和高效。WebSocket 可以在建立连接后保持持久连接,并通过服务器端推送实现即时通信,而 Socket 需要在应用层自行处理数据的发送和接收,相对来说比较复杂。
Http 和 WebSocket、Socket 相比,Http 协议更为常用和简单,但它不能实现实时通信。每次请求和响应之间需要重新建立连接,因此在实时通信场景下会产生较大的延迟。WebSocket 和 Socket 可以更好地应对实时通信场景的需求,但相对来说需要更多的开发和维护成本。
在实时通信场景下,WebSocket 和 Socket 是更好的选择,而在普通的 Web 应用中,Http 是更为常用的协议。
10.TCP 和 UDP 分别对应的常见应用层协议有哪些?
基于TCP的应用层协议有:HTTP、FTP、SMTP、TELNET、SSH
- HTTP:HyperText Transfer Protocol(超文本传输协议),默认端口80
- FTP: File Transfer Protocol (文件传输协议), 默认端口(20用于传输数据,21用于传输控制信息)
- SMTP: Simple Mail Transfer Protocol (简单邮件传输协议) ,默认端口25
- TELNET: Teletype over the Network (网络电传), 默认端口23
- SSH:Secure Shell(安全外壳协议),默认端口 22
基于UDP的应用层协议:DNS、TFTP、SNMP
- DNS : Domain Name Service (域名服务),默认端口 53
- TFTP: Trivial File Transfer Protocol (简单文件传输协议),默认端口69
- SNMP:Simple Network Management Protocol(简单网络管理协议),通过UDP>- 端口161接收,只有Trap信息采用UDP端口162。
11.Get和Post的区别
- Get请求把信息放在URL,Post把请求信息放在请求体中,这点使得Get请求携带的数据量有限,因为URL的长度是有限的,而Post是没有限制的
- Get符合幂等性和安全性,而Post不符合。因为Get只请求不改变,而Post会改变服务器上的信息。
- Get能被缓存到记录中,但是Post不能
12.Http和Https的区别
超文本传输协议(HTTP)
即超文本传输协议,是一个基于TCP/IP通信协议来传递明文数据的协议。HTTP会存在这几个问题:
- 请求信息是明文传输,容易被窃听截取。
- 没有验证对方身份,存在被冒充的风险
- 数据的完整性未校验,容易被中间人篡改(请求过程)
(请求流程)- 客户端进行DNS域名解析,得到对应的IP地址
- 根据这个IP,找到对应的服务器建立连接(三次握手)
- 建立TCP连接后发起HTTP请求(一个完整的http请求报文)
- 服务器响应HTTP请求,客户端得到html代码
- 客户端解析html代码,用html代码中的资源(如js,css,图片等等)渲染页面。
- 服务器关闭TCP连接(四次挥手)
安全超文本传输协议(HTTPS)
是 HTTP 的一种更安全的版本或扩展。在 HTTPS 中,浏览器与服务器会在传输数据之前建立安全的加密连接。(请求流程)
- 客户端发起Https请求,连接到服务器的443端口。
- 服务器必须要有一套数字证书(证书内容有公钥、证书颁发机构、失效日期等)。
- 服务器将自己的数字证书发送给客户端(公钥在证书里面,私钥由服务器持有)。
- 客户端收到数字证书之后,会验证证书的合法性。如果证书验证通过,就会生成一个随机的对称密钥,用证书的公钥加密。
- 客户端将公钥加密后的密钥发送到服务器。
- 服务器接收到客户端发来的密文密钥之后,用自己之前保留的私钥对其进行非对称解密,解密之后就得到客户端的密钥,然后用客户端密钥对返回数据进行对称加密,酱紫传输的数据都是密文啦。
- 服务器将加密后的密文返回到客户端。
- 客户端收到后,用自己的密钥对其进行对称解密,得到服务器返回的数据。
操作系统
1.什么是操作系统?有哪些功能?
本质是一个运行在计算机上的软件程序,用来管理计算机硬件和软件资源的程序,是计算机的基石。
- 进程和线程的管理:进程的创建、撤销、阻塞、唤醒,进程间的通信等。
- 存储管理:内存的分配和管理、外存(磁盘等)的分配和管理等。
- 文件管理:文件的读、写、创建及删除等。
- 设备管理:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
- 网络管理:操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
- 安全管理:用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
2.进程、线程、协程
进程(Process) 是指计算机中正在运行的一个程序实例。举例:你打开的微信就是一个进程。
- 每个进程都有自己独立的内存空间、代码段、数据段和堆栈,进程之间彼此独立,相互不影响。
- 进程是系统分配资源和调度执行的基本单位,可以包含一个或多个线程。
线程(Thread) 也被称为轻量级进程,更加轻量,是操作系统中能够独立执行的最小单位。多个线程可以在同一个进程中同时执行,并且共享进程的资源比如内存空间、文件句柄、网络连接等。举例:你打开的微信里就有一个线程专门用来拉取别人发你的最新的消息
协程是一种用户态的轻量级线程,可以在同一个线程中实现多个程序段的交替执行。
总的来说,进程是系统资源分配的基本单位,线程是操作系统能够进行运算调度的最小单位,而协程则是一种更加灵活的用户态线程,用于编写异步、非阻塞的代码。
3.并发和并行的区别
并发就是在一段时间内,多个任务都会被处理;但在某一时刻,只有一个任务在执行。
并行就是在同一时刻,有多个任务在执行。
4.进程间的通信方式有哪些?
- 管道:管道这种通讯方式有两种限制,一是半双工的通信,数据只能单向流动,二是只能在具有亲缘关系的进程间使用
- 信号 : 信号是一种比较复杂的通信方式,信号可以在任何时候发给某一进程,而无需知道该进程的状态。
- 信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段
- 消息队列:消息队列是消息的链接表,包括Posix消息队列和System V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- Socket:与其他通信机制不同的是,它可用于不同机器间的进程通信。
优缺点:
- 管道:速度慢,容量有限;
- Socket:任何进程间都能通讯,但速度慢;
- 消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题;
- 信号量:不能传递复杂消息,只能用来同步;
- 共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存。
5. 什么是死锁?死锁产生的条件?
在两个或者多个并发进程中,如果每个进程持有某种资源而又等待其它进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗的讲就是两个或多个进程无限期的阻塞、相互等待的一种状态。
死锁产生的四个必要条件:(有一个条件不成立,则不会产生死锁)
- 互斥条件:一个资源一次只能被一个进程使用
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得资源保持不放
- 不剥夺条件:进程获得的资源,在未完全使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾相接的环形等待资源关系
常用的处理死锁的方法有:
- 死锁预防:确保死锁发生的四个必要条件中至少有一个不成立:
- 死锁避免:允许前三个必要条件,但是通过动态地检测资源分配状态,以确保循环等待条件不成立,从而确保系统处于安全状态
- 死锁检测:通过资源分配图来检测是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有存在环,也就是检测到死锁的发生。
- 死锁解除:终止进程和资源抢占,回滚
- 鸵鸟策略:把头埋在沙子里,假装根本没发生问题。
6.进程有哪些状态?
- 创建
- 就绪
- 运行(执行)
- 终止
- 阻塞。
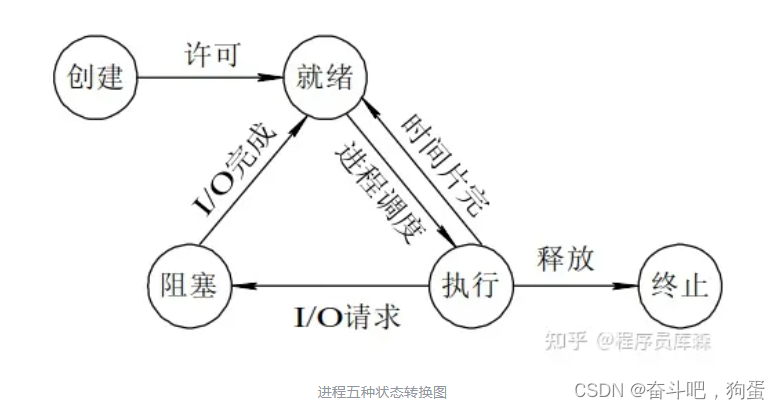
7.进程调度策略有哪几种?
- 先来先服务:非抢占式的调度算法,按照请求的顺序进行调度。有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。另外,对I/O密集型进程也不利,因为这种进程每次进行I/O操作之后又得重新排队。
- 短作业优先:非抢占式的调度算法,按估计运行时间最短的顺序进行调度。长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
- 最短剩余时间优先:最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
- 时间片轮转:将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。 而如果时间片过长,那么实时性就不能得到保证。- 优先级调度:为每个进程分配一个优先级,按优先级进行调度。为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
8.分页、分段
分页:把内存空间划分为大小相等且固定的块,作为主存的基本单位。因为程序数据存储在不同的页面中,而页面又离散的分布在内存中,因此需要一个页表来记录映射关系,以实现从页号到物理块号的映射。
分段:为了满足程序员在编写代码的时候的一些逻辑需求(比如数据共享,数据保护,动态链接等)。分段内存管理当中,地址是二维的,一维是段号,二维是段内地址;其中每个段的长度是不一样的,而且每个段内部都是从0开始编址的。由于分段管理中,每个段内部是连续内存分配,但是段和段之间是离散分配的,因此也存在一个逻辑地址到物理地址的映射关系,相应的就是段表机制。
区别
- 分页对程序员是透明的,但是分段需要程序员显式划分每个段。
- 分页的地址空间是一维地址空间,分段是二维的。
- 页的大小不可变,段的大小可以动态改变。
- 分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
数据结构
1. 常用数据容器
- 线性表:
一种基本的数据结构,它包含了一组按照线性顺序排列的元素。在线性表中,每个元素都有一个确定的位置,称为索引,索引从零开始逐个递增- 栈:
先进后出,特殊的线性表,只能在表的一个固定端去进行插入和删除- 堆:
特殊的树形数据结构- 队列:
先进先出,特殊的线性表,只能在一端进行插入,另一端进行删除- 数组:
线性表数据结构,使用前需声明长度,不安全,是个存储在连续内存位置的相同类型数据项的集合- 列表
动态数组,可动态扩容,泛型安全,在内存中也是连续存储的- 链表
数据元素按照链式存储结构进行存储的数据结构,内存位置是不连续的。内部有数据元素为节点,每个节点包含两个字段,分别是数据字段和链接字段,通过一个指针链接到它的相邻节点。- 字典
内部使用哈希表作为存储结构,是包含键和值集合的抽象数据类型,每个键都有一个相关联的值;如果试图找到一个不存在的值,则会抛出异常。- 哈希表
不定长的二进制数据通过哈希函数印射到一个较短的二进制数集- 树
包含一个和多个数据节点的集合,其中一个节点被指定为树的根,其余节点被称为根的子节点- 图
可以把图视为循环树,其中每个节点保持他们之间的任何复杂关系,而不是具有父子关系
2. 树的类型有哪些?
二叉树(Binary Tree):
- 二叉树是每个节点最多有两个子节点的树结构,通常称为左子树和右子树。
- 在二叉树中,每个节点最多有两个子节点,分别是左子节点和右子节点。
- 特殊的二叉树包括满二叉树、完全二叉树、二叉搜索树等。
二叉搜索树(Binary Search Tree,BST):
- 二叉搜索树是一种特殊的二叉树,具有以下性质:
- 对于任意节点 n,其左子树中的所有节点的值都小于节点 n 的值。
- 对于任意节点 n,其右子树中的所有节点的值都大于节点 n 的值。
- 左右子树也分别是二叉搜索树。
- 二叉搜索树常用于实现插入、删除、查找等操作。
平衡二叉树(Balanced Binary Tree):
- 平衡二叉树是一种特殊的二叉搜索树,具有较为平衡的高度,可以有效地提高查找、插入和删除等操作的性能。
- 常见的平衡二叉树包括红黑树、AVL 树等。
多路查找树(Multiway Search Tree):
- 多路查找树是一种每个节点可以拥有多个子节点的树结构,相比于二叉树,可以提供更高的查找效率。
- 常见的多路查找树包括 B 树、B+ 树、Trie 树等。
树状数组(Binary Indexed Tree,BIT):
- 树状数组是一种用于高效处理数列前缀和查询的数据结构,通常用于解决一些数组或区间操作问题。
哈夫曼树(Huffman Tree):
- 哈夫曼树是一种用于数据压缩的树结构,根据字符出现频率构建树形结构,以实现数据的高效压缩和解压缩
3. 循环、路径和回路有什么区别?
循环(Cycle):
- 循环是指图中至少有一条边构成一个环路的情况,也就是从某个顶点出发,沿着图的边可以回到该顶点的情况。
- 如果图中存在循环,则称该图是一个循环图(Cyclic Graph);反之,如果图中不存在循环,则称该图是一个无环图(Acyclic Graph)。
路径(Path):
- 路径是指图中从一个顶点到另一个顶点的顶点序列,顶点之间通过边相连。
- 路径的长度是指路径上边的数量,如果路径上的所有顶点都不相同,则称该路径是简单路径;反之,如果允许路径上存在重复的顶点,则称该路径是非简单路径。
回路(Circuit):
- 回路是指图中至少有一条边构成一个环路,并且环路上的所有顶点除了起点和终点外都不相同的情况。
- 回路也可以理解为是一种特殊的路径,它是一条从一个顶点出发,经过若干条边最终回到起点的路径,但是在回路中除了起点和终点可以相同,其余顶点都不相同。
总的来说,循环是图中形成环路的情况,路径是从一个顶点到另一个顶点的顶点序列,回路是一种特殊的路径,它是从一个顶点出发,经过若干条边最终回到起点的路径,但是在回路中除了起点和终点可以相同,其余顶点都不相同。
4. 二维数组如何存储在内存中?
二维数组在内存中存储的方式取决于编程语言和编译器的实现。一般来说,二维数组在内存中是按行存储的,也就是说数组的每一行会依次存储在内存中的连续位置。具体来说,如果二维数组是一个 m × n 大小的数组,那么在内存中存储时,会按照以下方式进行排列:
- 按行存储:首先存储第一行的所有元素,然后存储第二行的所有元素,依次类推,直到存储完所有行。
- 内存地址计算:假设数组的每个元素占据 sizeof(type) 个字节的内存空间(其中 type 是数组元素的数据类型),那么数组中的第 (i, j) 个元素的内存地址可以通过以下公式计算得到:
address[i][j] = base_address + (i * n + j) * sizeof(type)
其中 base_address 是数组的起始地址,i 表示行数(从0开始),j 表示列数(从0开始),n 是数组的列数。这种按行存储的方式使得访问数组元素时可以通过简单的内存地址计算来实现,提高了访问效率。同时,也保证了相邻元素在内存中的地址是连续的,有利于缓存的利用。
5. 时间复杂度、空间复杂度
时间复杂度:
- 时间复杂度描述了算法执行所需的时间与问题规模之间的关系。通常用大 O 符号(O)来表示,例如 O(n)、O(nlogn)、O(n^2) 等。
- 时间复杂度可以分为最坏情况时间复杂度、平均情况时间复杂度和最好情况时间复杂度。通常情况下,我们更关注最坏情况时间复杂度,因为它表示了算法在最差的情况下执行的时间。
常见的时间复杂度包括:
- O(1):常数时间复杂度,表示算法的执行时间不随问题规模的增大而增加。
- O(logn):对数时间复杂度,通常出现在二分查找等算法中。
- O(n):线性时间复杂度,表示算法的执行时间与问题规模成正比。
- O(nlogn):线性对数时间复杂度,通常出现在快速排序、归并排序等排序算法中。
- O(n^2):平方时间复杂度,通常出现在冒泡排序、插入排序等简单排序算法中。
空间复杂度:
- 空间复杂度描述了算法执行所需的额外空间(除输入数据之外)与问题规模之间的关系。同样使用大 O 符号表示。
- 空间复杂度可以分为额外空间复杂度和原地复杂度。额外空间复杂度指的是算法执行时所需的额外空间,而原地复杂度指的是算法在执行过程中只需要常数级别的额外空间。
常见的空间复杂度包括:
- O(1):常数空间复杂度,表示算法执行过程中只需要常数级别的额外空间。
- O(n):线性空间复杂度,表示算法执行过程中需要额外的空间与问题规模成正比。
- O(n^2):平方空间复杂度,表示算法执行过程中需要额外的空间与问题规模的平方成正比。
6. 什么是浅拷贝?什么是深拷贝?
浅拷贝(Shallow Copy):
- 浅拷贝是将一个对象的值复制到另一个对象,但对于对象内部包含的引用类型数据(如数组、对象等),只复制引用而不复制实际数据。
- 因此,对于浅拷贝后的对象和原始对象来说,它们的内部引用类型数据仍然指向同一个实际数据对象,修改其中一个对象的内部引用类型数据会影响到另一个对象。
深拷贝(Deep Copy):
- 深拷贝是将一个对象的值以及其内部包含的所有引用类型数据都复制到另一个对象,包括引用类型数据指向的实际数据。
- 深拷贝后的对象和原始对象完全独立,它们的内部引用类型数据指向的是不同的实际数据对象,因此对一个对象的修改不会影响另一个对象。
总的来说,浅拷贝只复制了对象的值和内部引用,而深拷贝则会递归地复制对象的所有内容,包括内部引用类型数据指向的实际数据。
7. 文件结构和存储结构有什么区别?
文件结构:
- 文件结构是指数据在外存储介质上的组织方式,描述了文件中数据之间的逻辑关系。
- 文件结构通常包括顺序结构、链式结构、索引结构和散列结构等不同类型,每种类型都有其特定的组织方式和适用场景。
- 例如,顺序文件结构中的数据按顺序存储在文件中,可以快速顺序访问;链式文件结构使用链表连接数据块,适合频繁的插入和删除操作。
存储结构:
- 存储结构是指数据在内存或其他存储介质上的表示形式,描述了数据在计算机中的物理存储方式。
- 存储结构包括了数据的布局方式、数据类型的表示方法、数据的存储地址等信息。
- 例如,存储结构可以是数组、链表、树等不同的数据结构形式,每种结构都有其独特的特点和适用场景。
总的来说,文件结构强调数据之间的逻辑关系和组织方式,而存储结构则描述了数据在存储介质上的实际表示形式和存储方式。文件结构和存储结构密切相关,文件中的数据通常以某种存储结构的形式存储在存储介质上。
8. 深度优先遍历和广度优先遍历
深度优先遍历(DFS):
- DFS 从图或树的某个节点开始,沿着路径直到不能继续前进,然后回溯到前一个节点,继续搜索未遍历的路径。
- 在具体实现中,DFS 通常使用递归或栈来实现。递归版本的 DFS 可能更简洁易懂,而基于栈的迭代版本可以更好地控制内存消耗。
- DFS 对于深度优先搜索和寻找路径问题非常有效,但可能会陷入无限循环,因此在使用时需要注意。
广度优先遍历(BFS):
- BFS 从图或树的某个节点开始,首先遍历该节点的所有邻居节点,然后再逐层遍历其邻居节点的邻居节点,直到所有节点都被访问过。
- 在具体实现中,BFS 通常使用队列来实现。队列保证了节点的访问顺序是先进先出,从而实现了逐层遍历的效果。
- BFS 适用于寻找最短路径、搜索最短距离等问题,它能够保证找到的路径是最短的。
比较:
- DFS 适用于寻找路径、查找连通分量等问题,它的搜索深度可能很大,因此在某些情况下可能会更快地找到解决方案。
- BFS 适用于寻找最短路径、搜索最短距离等问题,它的搜索速度可能会比 DFS 慢,但能够保证找到的路径是最短的。
9. 什么是前、中、后序遍历
前序遍历(Preorder Traversal):
- 在前序遍历中,首先访问根节点,然后递归地对左子树进行前序遍历,最后递归地对右子树进行前序遍历。
- 根节点的访问顺序在左右子树之前。
中序遍历(Inorder Traversal):
- 在中序遍历中,先递归地对左子树进行中序遍历,然后访问根节点,最后递归地对右子树进行中序遍历。
- 根节点的访问顺序在左右子树中间。
后序遍历(Postorder Traversal):
- 在后序遍历中,先递归地对左子树进行后序遍历,然后递归地对右子树进行后序遍历,最后访问根节点。
- 根节点的访问顺序在左右子树之后。
这三种遍历方式可以用递归或迭代的方式实现。它们在树的节点访问顺序上有所不同,适用于不同的场景。例如,中序遍历对于二叉搜索树可以按照升序遍历节点,前序遍历适用于树的创建和复制,后序遍历适用于释放树节点的内存。
10.什么是平衡树?
平衡树是一种特殊的树结构,它保持着左右子树的高度差在一定范围内,以确保树的高度不会过高,从而提高检索、插入和删除等操作的效率。平衡树的目标是使得树的高度保持较低的水平,从而保持其操作的时间复杂度在较低的水平。
平衡树最常见的例子是平衡二叉树(Balanced Binary Tree),其中最著名的实现是 AVL 树和红黑树。这些平衡树的特点是通过在插入或删除节点时进行自平衡操作,如旋转、颜色调整等,来维持树的平衡性。
平衡树的特点包括:
- 每个节点的左右子树的高度差不超过某个固定的值(通常为1)。
- 对于插入或删除操作,会通过旋转等方式调整树的结构,以保持树的平衡性。
- 平衡树的操作(插入、删除、查找等)的时间复杂度通常为 O(log n),其中 n 是树中节点的数量。
平衡树在数据库索引、编译器实现、操作系统等领域有着广泛的应用,以提高数据的检索和修改效率。
常见算法
1. 常见排序算法
- 冒泡排序
- 重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来
- 时间复杂度:平均情况和最坏情况下均为 O(n^2)。
- 空间复杂度:O(1)。
- 选择排序
- 每次从未排序的部分选择最小(或最大)的元素,放到已排序部分的末尾
- 时间复杂度:平均情况和最坏情况下均为 O(n^2)。
- 空间复杂度:O(1)。
- 插入排序
- 将未排序的元素逐个插入到已排序部分的合适位置。
- 时间复杂度:平均情况和最坏情况下均为 O(n^2)。
- 空间复杂度:O(1)。
- 快速排序
- 选择一个基准元素,将小于基准的元素放到左侧,大于基准的元素放到右侧,再对左右两部分递归进行快排。
- 时间复杂度:平均情况下为 O(nlogn),最坏情况下为 O(n^2)。
- 空间复杂度:O(logn)。
- 归并排序
- 将数组分成两半,对每一半进行递归归并排序,然后将两个有序的子数组合并成一个有序数组。
- 时间复杂度:平均情况下为 O(nlogn)。
- 空间复杂度:O(n)。
- 希尔排序
- 将待排序数组划分成若干个间隔相等的子序列,对每个子序列进行插入排序,随着间隔的逐步缩小,直至间隔为1,最终对整个数组进行插入排序,使得整个数组基本有序。
- 时间复杂度:在 O(n^2) 和 O(n^1.5) 之间
- 空间复杂度:O(n)。
- 堆排序:
- 将待排序数组构建成最大堆,然后将堆顶元素与最后一个元素交换并重新调整堆,直到所有元素都排好序。
- 时间复杂度:平均情况下为 O(nlogn)。
- 空间复杂度:O(1)。
- 桶排序:
- 将元素分配到有限数量的桶中,对每个桶中的元素进行排序,然后按照顺序将桶中的元素输出。
- 时间复杂度:平均情况下为 O(n + k),其中 k 表示桶的数量。
- 空间复杂度:O(n + k)。
2. 常见查找算法
- 线性查找:逐个遍历数组或列表,查找目标元素,时间复杂度为 O(n)。
- 二分查找:对于有序数组或列表,通过比较中间元素与目标元素的大小关系来确定目标元素所在的区间,不断缩小查找范围,直到找到目标元素或查找范围为空,时间复杂度为 O(log n)。
- 哈希查找:通过哈希函数将关键字映射到哈希表的位置,快速定位目标元素,时间复杂度为 O(1),但需要额外的空间来存储哈希表。
- 二叉查找树:通过构建二叉搜索树,按照左子树小于根节点、右子树大于根节点的规则,进行查找操作,时间复杂度取决于树的高度,平均情况为 O(log n),最坏情况为 O(n)。
- 平衡二叉查找树:例如 AVL 树、红黑树等,保持树的平衡性,使得查找效率更高,时间复杂度稳定在 O(log n)。
- 跳表:一种类似于平衡二叉查找树的数据结构,通过构建多层索引,提高查找效率,平均情况下时间复杂度为 O(log n)。
- Trie 树:一种树形数据结构,用于处理字符串检索,时间复杂度与字符串的长度相关。
- Bloom Filter:一种高效的查找算法,用于判断一个元素是否属于一个集合,可能会存在一定的误判率,但具有空间效率和查询效率高的特点。
3. 空间切割算法
- 四叉树:将二维空间递归地划分为四个象限,每个象限又可以进一步划分为四个子象限,以此类推。四叉树常用于图像处理、碰撞检测等领域。
- 八叉树:类似于四叉树,但是将三维空间递归地划分为八个子立方体。八叉树常用于三维物体的空间索引和碰撞检测。
- kd 树:一种多维空间划分结构,将空间按照特定维度划分为两个子空间,可以是二维、三维或更高维。kd 树常用于高维空间的搜索和最近邻查找。
- R 树:一种多维空间索引结构,用于高效地存储和查询多维数据。R 树能够快速查找空间范围内的对象,并支持动态插入和删除操作。
- BVH:一种基于包围体的层次空间划分结构,用于加速碰撞检测和光线追踪等应用。BVH 将空间划分为层次结构,每个节点表示一个包围体,可以是球体、盒子等,以减少碰撞检测的计算量。
热更新(暂时以Lua为基础)
1.常见基础类型
- nil–空
- boolean–布尔
- number–数值
- string–字符串
- userdata–用户数据
- function–函数
- thread–线程(注意这里的线程和操作系统的线程完全不同,lua和c/c++进行交互的lua_Stack就是一种llua的线程类型)
- table–表。
SDK相关
—参考链接:谷歌排行榜SDK
![[Unity] 利用Mixamo进行人物骨骼绑定并导入Unity(搞定材质缺失+骨骼缺失)_unti](https://img-blog.csdnimg.cn/2955357d5caa48ad97238fdebbd1df1b.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

