
- 1python生成excel文件的三种方式_python 生成excel
- 22021Java高级面试题汇总解答,附面试题_java高级面试题附答案解析(2021年java高级面试题大汇总)
- 3SourceTree 提交报错 闪退_sourcetree打开马上被关闭
- 4KNN最近邻分类算法的简单过程_knn分类算法的计算过程
- 5MyBatis update语句 set标签的使用(xml形式)_mybatis update xml
- 6我用numpy实现了VIT,手写vision transformer, 可在树莓派上运行,在hugging face上训练模型保存参数成numpy格式,纯numpy实现...
- 7SpringAI如何集成Ollama开发AI应用_spring ai + ollama
- 8互联网公司社招还会问算法题么?_驱动开发社招考查算法题吗
- 9协同过滤算法深入解析:构建智能推荐系统的核心技术_协同过滤算法数据集
- 10fastadmin离线安装插件提示”请从官网渠道下载插件压缩包(code:1)(code:0)“
分布式与一致性协议之CAP(二)
赞
踩
CAP
CAP不可能三角

CAP不可能三角是指对于一个分布式系统而言,一致性、可用性、分区容错性指标不可兼得,只能从中选择两个,
如图所示。CAP不可能三角最初是埃里克·布鲁尔(Eric Brewer)基于自己的工程实践提出的一个猜想,后被塞斯·吉尔伯特(Seth Gilbert)
和南希·林奇(Nancy Lynch)证明,(https://dl.acm.org/citation.cfm?id=564601)基于证明的严谨性的考虑,塞斯吉尔伯特和南希林奇对指标的含义做了预设和限制,比如,将一致性限制为原子一致性。
那么如何使用CAP理论来思考和涉及分区容错一致性模型呢?
如何使用CAP理论?
我们都直到,只要有网络交互就一定会有延迟和数据丢失,这种状况我们必须接受,还必须保证系统不能挂掉。就像上面提到的,节点间的分区故障时必然发生的。也就是说,分区容错性§是前提,是必须要保证的。
现在就只剩下一致性©和可用性(A)可以选择了:要么选择一致性,保证数据正确,要么选择可用性,保证服务可用。那么CP和AP的含义是什么呢?
- 1.当选择了一致性©的时候,系统一定会读到最新的数据,不会读到旧数据,但如果因为消息丢失、延迟过高发生了网络分区,那么当集群节点接收到来自客户端的读请求时,为了不破坏一致性,可能会因为无法响应最新数据,而返回出错信息。
- 2.当选择了可用性(A)的时候,系统将始终处理客户端的查询,返回特定信息,如果发生了网络分区,一些节点将无法返回最新的特点信息,而是返回自己当前的相对新的信息。
这里需要强调一点,大部分人对CAP理论有一个误解,认为无论在什么情况下,分布式系统都只能在C和A中选择1个。其实,在不存在网络分区的情况下,也就是在分布式系统正常运行时(这也是系统在绝大部分时候所处的状态),即在不需要P时,C和A能够同时保证。只有当发生分区故障的时候,即需要P时,系统才会在C和A之间做出选择。而且如果读操作
会读到旧数据,影响到了系统运行或业务运行(也就是说会有负面的影响),则推荐选择C,否则推荐选择A.
注意
CA模型,在分布式系统中不存在。因为舍弃P,意味着舍弃分布式系统,就比如单机版关系型数据库MySQL,如果MySQL要考虑主备或集群部署,它就必须考虑P.CP模型,采用CP模型的分布式系统,舍弃了可用性,一定会读到最新数据,不会读到旧数据。一旦消息丢失、延迟过高
发生了网络分区,就会影响用户的体验和业务的可用性(比如基于Raft的强一致系统,此时可能无法执行读操作和写操作)典型的应用有ETCD、Consul和HBaseAP模型,采用AP模型的分布式系统,舍弃了一致性,实现了服务器的高可用。用户访问系统时能得到响应数据,不会出现
响应错误,但会读取到旧数据。典型应用有Cassandra和DynamoDB
例子
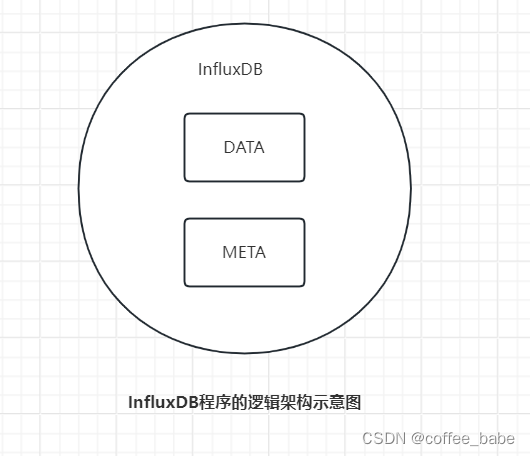
以开源版的InfluxDB为例,InfluxDB是由节点和META和DATA节点两个逻辑单元组成的(如图所示),这两个节点的功能和数据特点
不同,需要我们分别为它们涉及分区容错一致性模型。
具体涉及如下:
-
1.作为分布式系统,分区容错性时必须要实现的,不能因为节点间出现了分区故障,而出现整个系统不工作的情况
-
2.考虑到META节点保存的是系统运行的关键元信息,比如数据库名、表名、保留策略信息等,所以必须实现一致性。也就是说,每次读都要能读到最新数据,这样才能避免因为查询不到指定的元信息,而导致时序数据记录写入失败或者系统没办法正常运行。比如创建数据库telegraf之后,如果系统不能立刻读取到这条新的元信息,那么相关的时序数据记录就会因为找不到指定数据库信息而写入失败,所以,应该选择CAP理论中的C和P,采用CP架构
-
3.DATA节点保存的是具体的时序数据记录,比如一条记录CPU负载的时序数据"cpu_usage,host=server0,localtion=cn-sz,user=23,system=57.0".
虽然这些数据不是系统运行相关的元信息,但服务器会被频繁访问,水平扩展、性能、可用性等是关键,所以,应该选择CAP理论中的A和P,采用AP架构。 -
综上,基于CAP理论分别设计了InfluxDB的META节点和DATA节点的分区容错一致性模型,我们也可以采用类似的思考方法,设计出符合自己业务场景的分区容错一致性模型。
如果在上述例子中没有应用CAP理论,或者对CAP理论理解不深入,在设计DATA节点的分区容错一致性模型是不采用AP架构,而是之解使用现在
比较流行的共识算法,比如Raft算法,会有什么问题呢?
-
1.受限于Raft的强领导者模型。所有写请求都在领导者节点上处理,整个集群的写性能等于单机性能。这样会造成集群接入性能低下,无法支撑海量或大数据量的时序数据
-
2.受限于强领导者模型,以及Raft的节点和副本一一对应的限制,无法实现水平扩展。分布式集群扩展了读性能,但并没有提升写性能
-
在多年的开发实践中,埃里克布鲁尔的猜想将会起到一个关键的作用,不是因为它是CAP理论的本源,意义重大,而是因为它源自高可用、高扩展的大型互联网系统的实践,强调在数据一致性(ACID)和服务可用性(BASE)之间权衡取舍。
注意
在当前分布式系统开发中,延迟是非常重要的一个指标。比如,在QQ后台的名字路由系统中,通过延迟评估服务可用性进行负载均衡和容灾;
再比如再Hashicorp Raft实现中,通过延迟评估领导者节点的服务可用性,以及是否发起领导者选举,所以,希望大家在分布式系统的开发中,
也能意识到延迟的重要性,能通过延迟来衡量服务的可用性
- 小标题: 优点:重点提醒1重点提醒2[详细] -->
赞
踩

