
- 1K-SVD的理解_svdokgk
- 2uniapp中位置授权提示_uni.authorize
- 3面试文章 转发_面试文章功能:可发布文章
- 4mysql自带的information_schema.tables是什么?_information.schema.tables
- 5Tensorflow问题_tensorflow生成的v2文件是啥
- 6深度学习之FPN和PAN
- 7蓝桥杯练习||洛谷练习【算法1-2】排序
- 8Go语言高级特性_go高级特性
- 9分享9个好用的ai智能写作工具-轻松完成写作任务 #科技#学习方法#AI写作_ai 写公众号文章的工具
- 10JedisDataException: ERR Client sent AUTH, but no password is set
开源开放 | 糖尿病知识图谱DiaKG(CCKS2021)
赞
踩
OpenKG地址:http://openkg.cn/dataset/diakg
阿里云天池:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=88836
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:妙健康(常德杰、刘朝振、刘利平、李栋栋、李伟),阿里云(陈漠沙),清华大学(许斌)

DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction
论文来源:CCKS 2021
论文链接:https://arxiv.org/pdf/2105.15033.pdf
1. 摘要
为了加速医学领域知识的研究,精准化健康管理平台妙健康联合阿里云天池平台、 清华大学合作提出了一个高质量的中文糖尿病知识图谱数据集DiaKG,该数据集共包含22050个实体和6890个关系,目前是中文领域首个糖尿病相关的标注数据集。
2. 背景
糖尿病(Diabetes)是代谢性疾病,也是慢性疾病,中国是世界上糖尿病患者最多的国家,病人达到1.1亿,每年有130万人死于糖尿病及其相关疾病。糖尿病病因复杂,表现出的症状多种多样,这为糖尿病的诊断和治疗带来了很大的困难。国务院颁布的《“健康中国2030”规划纲要》中,也将糖尿病列入到重点监控的慢性病中。知识图谱在构造信息和概念知识的建模中已经被证明是有效的,特别是在医学领域,为了促进医学自然语言处理技术在糖尿病文本领域的应用以及糖尿病知识图谱的构建,我们推出了DiaKG。
3. 数据集
3.1 数据来源
该数据集来源于公开发表的41篇糖尿病指南和共识,涵盖了近年来最广泛的研究内容和热点领域,包括基础研究、临床研究、药物使用、临床病例、诊疗方法等等,是构建糖尿病知识库的权威资源。
3.2 标注规范
本数据集标注由两位经验丰富的内分泌专家设计了标注指南。本指南侧重于“实体”和“关系”,因为这两种类型是知识图谱的基本元素。共定义了18类实体类型和15类医学关系。实体关系类型定义和示例如表1和表2:
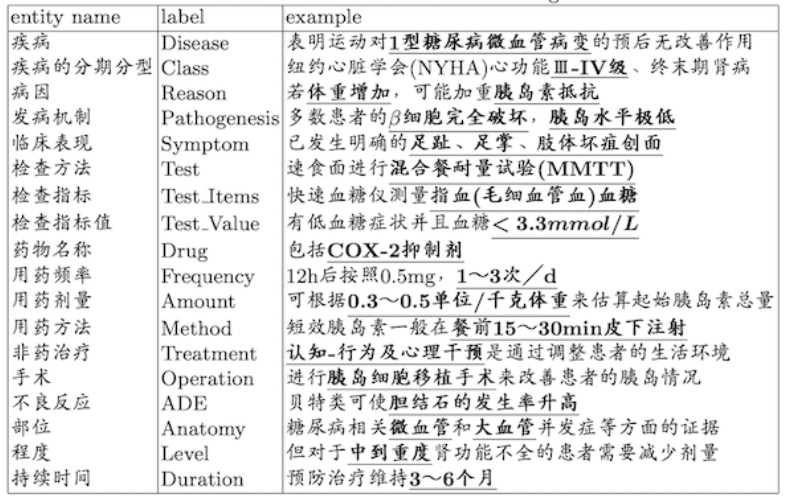
表1: 实体类型定义和示例

表2: 关系类型定义和示例
3.3 标注过程
首先通过OCR工具将原始的PDF专家指南文件转换为纯文本格式,之后由标注人员对OCR识别结果进行校正,诸如“β细胞”被识别为“B细胞”,确保识别出来的文字和符号都是正确的。因为本数据集是侧重文本的,因此原始PDF中出现的表格、图表等信息均做了过滤,仅留下文本信息作标注。
标注人员由制定标注规范的2名内分泌科专家和6名医学院研究生来完成。此外为了提高标注数据的可用性,1名AI专家也参与标注过程,算法专家会从模型的视角给给予标注人员直接的反馈。
标注过程分为试标注(Trail Annotation)、正式标注和质检三步。试标注阶段的反馈信息会汇总给两名医学专家用于优化标注规范,通过多轮标注最终得到了人工标注的高质量表糖尿病知识图谱数据集。标注规范见下图:
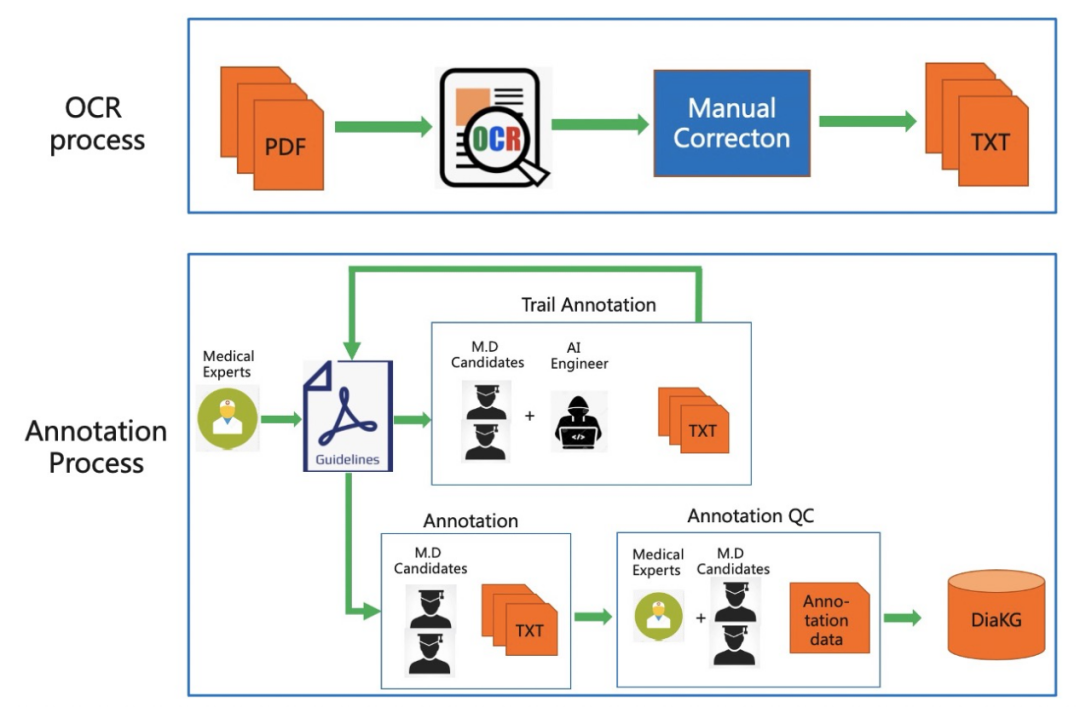
图1:DigKG标注流程示意图
3.4 数据集统计信息
该数据集共包含22050个实体和6890个关系。具体类别统计信息如表3和表4:
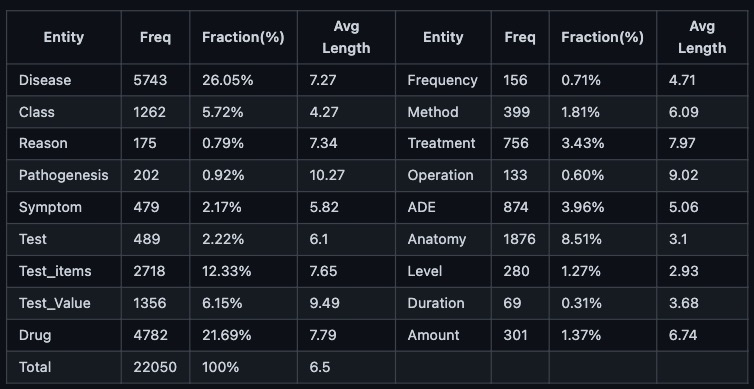
表3: DiaKG实体信息统计
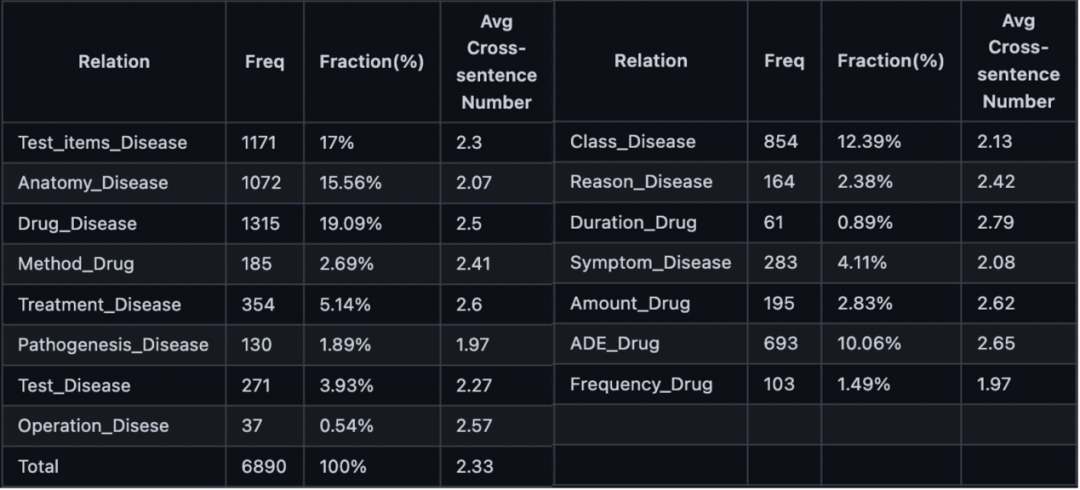
表4: DiaKG关系信息统计
注:Avg Cross-sentence Number表示组成关系的头、尾实体所分布句子的跨句长度。
3.5 数据集特点
相比其他医疗数据集,DiaKG有以下两个特点:
1. 实体数据可能由很长的序列span组成,如表3所示,“发病机理(pathogenesis)”平均长度是10.3个中文字符,对常规的NER模型是个挑战;
2. 组成关系的两个实体跨句子分布,平均跨句长度为2.3,头尾实体跨句子分布是关系抽取任务的难点,也是近年来的关系抽取的研究热点。
希望DiaKG的推出能进一步推动中文医学文本信息抽取技术的发展。有关DiaKG更详细的信息,请读者们参考CCKS 2021上录用发表的论文“DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction”。
4. 结语
知识图谱技术的研究和应用具有重要意义。在医疗健康领域的AI应用,事关人的生命健康,更依赖于专业、准确的知识图谱来响应用户的自然语言请求,实现反馈。比如,智能问诊应用可依据医药健康领域的知识库对患者的情况进行初步诊断。我们希望该数据集的发布能够帮助构建糖尿病知识图谱,促进基于人工智能的应用的发展。
5. 致谢
本论文由妙健康常德杰负责论文撰写,刘朝振提供算法实验指导,刘利平、李栋栋和李伟负责模型实验以及部分论文章节的撰写。特别感谢阿里云高级算法专家陈漠沙提供数据集构建思路和写作指导,清华许斌教授最终论文的审核。最后感谢标注专家的辛勤细致的付出!
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

