
- 1[原创](Modern C++)现代C++的std::bind花式绑定,使用方式大全.
- 2路径规划:基于kinodynamic的路径搜索
- 3YOLOV5 onnxruntime预测不用pytorch_onnxruntime替代pytorch
- 4初识C语言——第十一天
- 5IDEA部署MyEclipse的WebRoot项目
- 6AI跟踪报道第32期-新加坡内哥谈技术-本周AI新闻:超越GPT4的Claude
- 7OpenCL
- 8Kotlin中的字符串基本操作_kotlin字符串搜索
- 9C++模板编程之变长参数模板_使用c语言实现 c++变长参数模板
- 10苹果ios上架appstore审核被拒驳回之4.3design_guideline 4.3 - design we noticed your app shares
[AIGC] Stable Diffusion中的角色一致性(第1部分)_stable diffusion保持角色一致
赞
踩
英文原文:https://cobaltexplorer.com/2023/06/character-sheets-for-stable-diffusion/

关于 Stable Diffusion 经常出现的大问题之一是,如果我们想要创建多个图像,如何创建角色一致性。面部特征是最重要的,其次是体型、服装风格、背景等等……在人工智能图像/视频领域,它是目前(23 年中)备受追捧的圣杯。
实现这一目标的一个途径是使用 LoRA(低秩适应),这是一种将权重插入现有人工智能模型层的训练方法,使其偏向于定义的结果。但是,大多数 LoRA 都是针对现实生活中的人物(著名演员图像、个人照片)和风格进行训练,而不是针对人工智能生成/创建的角色输出进行训练。因此,问题来了,如果我想根据模型本身的输出创建一个角色,这样我就有一个 100% 独特的虚构角色来开发一个角色,使用我自己的角色描述,我该如何实现那?
我认为这分为三个阶段:
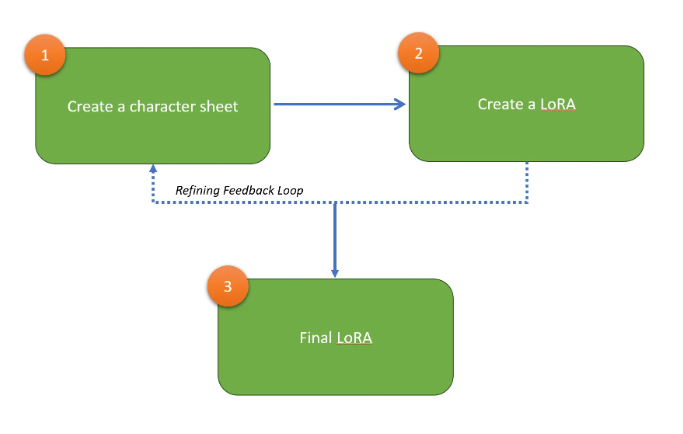
这里的概念是迭代 LoRA 几次以实现我们想要的模型。第一次迭代将侧重于完善面部特征和第二个身体特征,然后形成我们设计/概念人形机器人的最终“人”LoRA。
在第 1 部分中,我们将重点关注面部特征,这是一个人最 "容易辨认 "的元素–要实现这一点,我们需要创建一个角色表,这是一组由 15 张图像组成的表,这些图像的相似度足以代表一个角色。角色表是实现一致的角色输出的主要基础。首先要获得面部特征,然后再完善身体特征。
要实现这一目标需要一些实验,从根本上说,需要使用 LoRA 模型进行迭代。如何建立、完善和包含角色的其他部分将在本系列的第二部分中介绍,我将使用 kohya_ss 来训练 LoRA,以实现我们需要的结果。
现在进行角色表的开发,这应该相当简单。
设置:
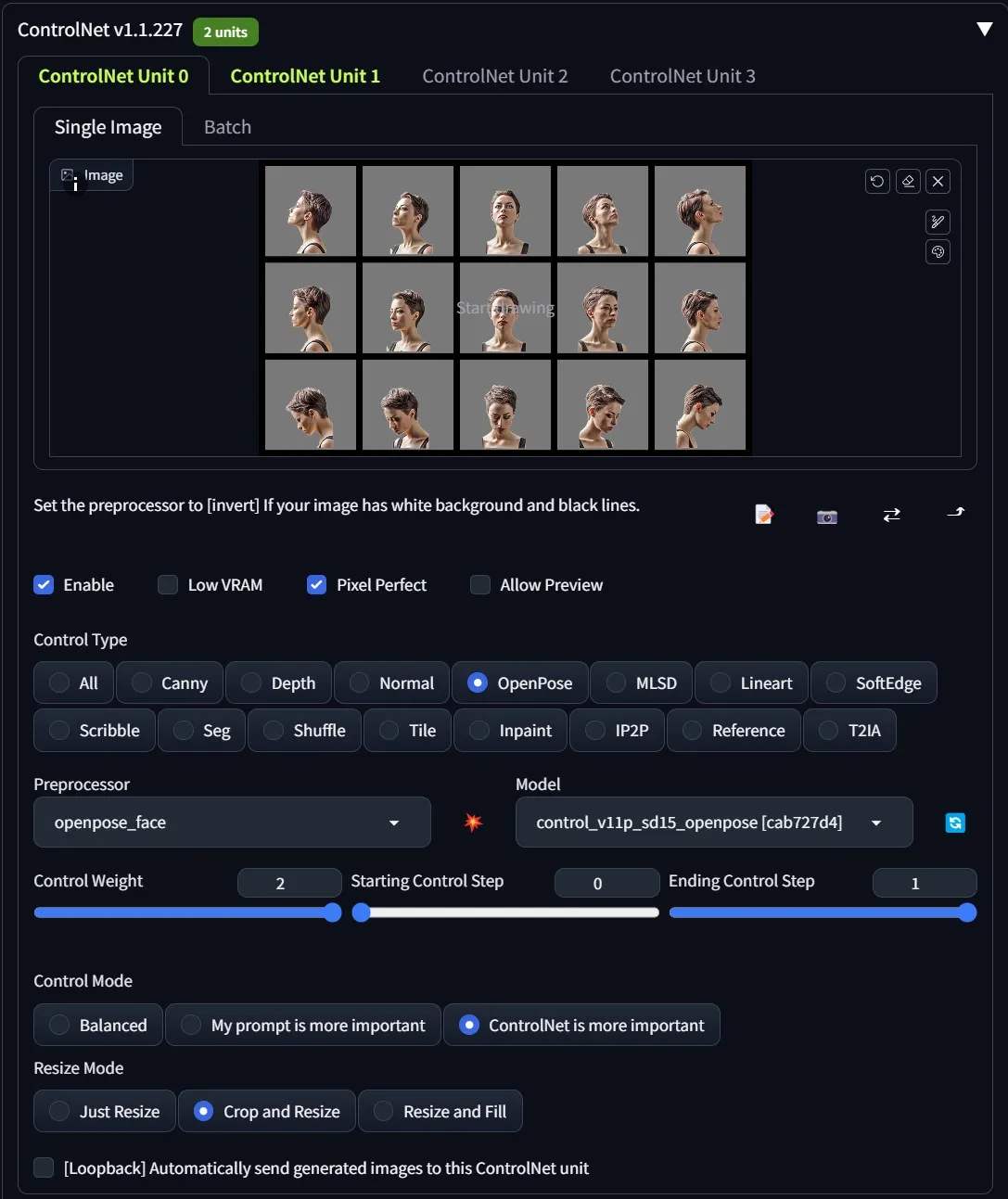
在初始阶段,我们将重点关注面部特征。首先,为了让 Stable Diffusion 输出高质量的角色表,我需要创建两个资产。(1) 用于 Controlnet OpenPose [提供面部的 15 种视图] (2) 用于 Controlnet Lineart [引导 SD 将渲染保持在特定的框/空间内]。要下载这些文件,只需右击并 "另存为… "即可。
注意:模板已于 7 月 1 日更新,现在为 1328×800


下载完这些后,我们希望使用以下 Controlnet 设置将它们引入稳定扩散 text2image。
艺术线条是为了向人工智能提供更好的指导,告诉我们如何分割纸张。我发现使用黄色而不是 100% 黑色可以比纯黑/白提供更好的分割效果。对于此线条蒙版,我们将使用以下设置:
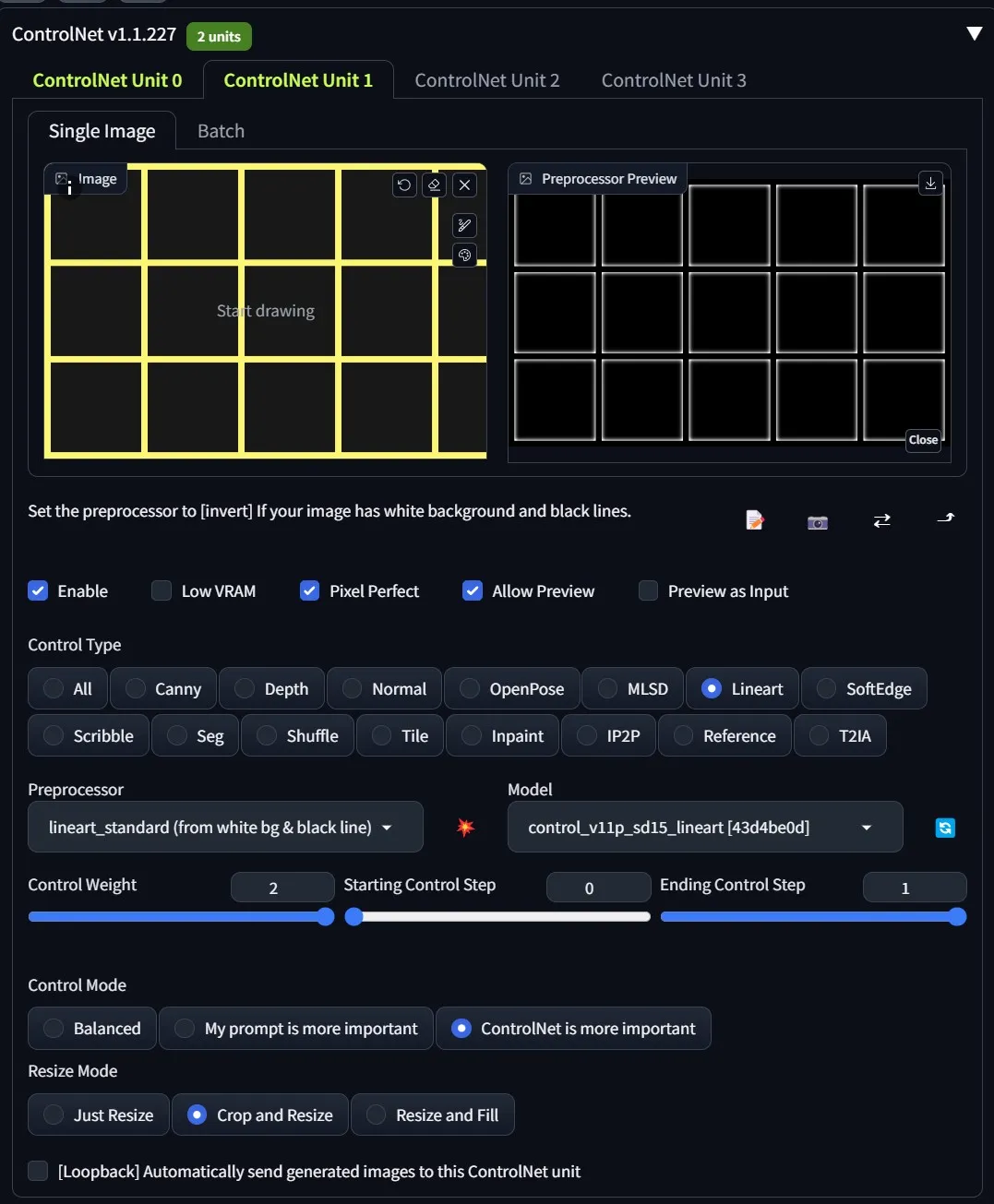
第一张图片将配置 OpenPose,使其具有角色表所需的正确面部方向。第二张图片将使用线描为稳定扩散提供 "指引 "边界,以便在其范围内绘制。请记住,我们是在与人工智能打交道,因此输出结果会有所不同,但通过上述方法,我们可以告诉它我们想要什么,并为它提供最好的保护,以获得最接近我们想要的结果。
OpenPose 和遮罩的大小经过专门设置,以通过稳定扩散获得最大的渲染精度。一个不太为人所知的事实是,稳定扩散输出尺寸必须能被 8 整除。这些工作表的设置方式是具有 8 个像素分隔符和 256×256 图像。考虑到 VRAM 的要求,这是我能找到的质量和尺寸的最佳折衷方案。
TXT2IMG 设置:
提示词:
(a character sheet of a woman from different angles with a grey background:1.4) , auburn hair, eyes open, cinematic lighting, Hyperrealism, depth of field, photography, ultra highres, photorealistic, 8k, hyperrealism, studio lighting, photography
负面提示词:
easynegative, canvasframe, canvas frame, eyes shut, wink, blurry, hands, closed eyes, (easynegative), ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), out of frame, extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), ((bad art)), blurry, (((mutation))), (((deformed))), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), ((floating limbs)), ((disconnected limbs)), ((malformed hands)), ((missing fingers)), worst quality, ((disappearing arms)), ((disappearing legs)), (((extra arms))), (((extra legs))), (fused fingers), (too many fingers), (((long neck))), canvas frame, ((worst quality)), ((low quality)), lowres, sig, signature, watermark, username, bad, immature, cartoon, anime, 3d, painting, b&w
面板设置:
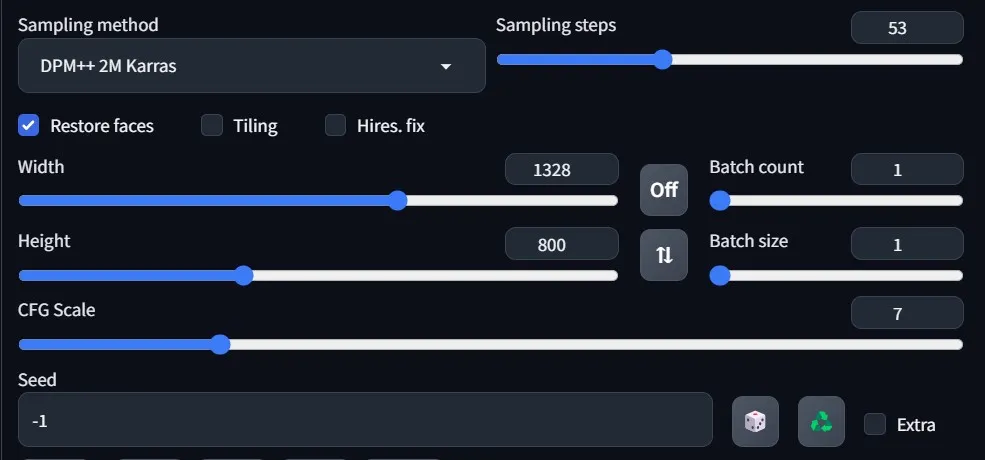
使用 img2img 缩放
完成后,我们点击 “发送到 img2img”。在 img2img 中进行 upscale 时,你可以使用任何你觉得合适的upscaler ,我自己使用的是 ultimate SD upscale,它可以通过扩展选项卡安装(ultimate-upscale-for-automatic1111)。以下是我的设置。对于噪点级别,我建议在 0.4 - 0.6 之间,您需要进行试验,但这将有助于消除变形,尤其是侧面角度的变形。不过噪点水平越高,也意味着你的角色也会发生一些变化。
这是我用于 img2img 的主要面板设置:
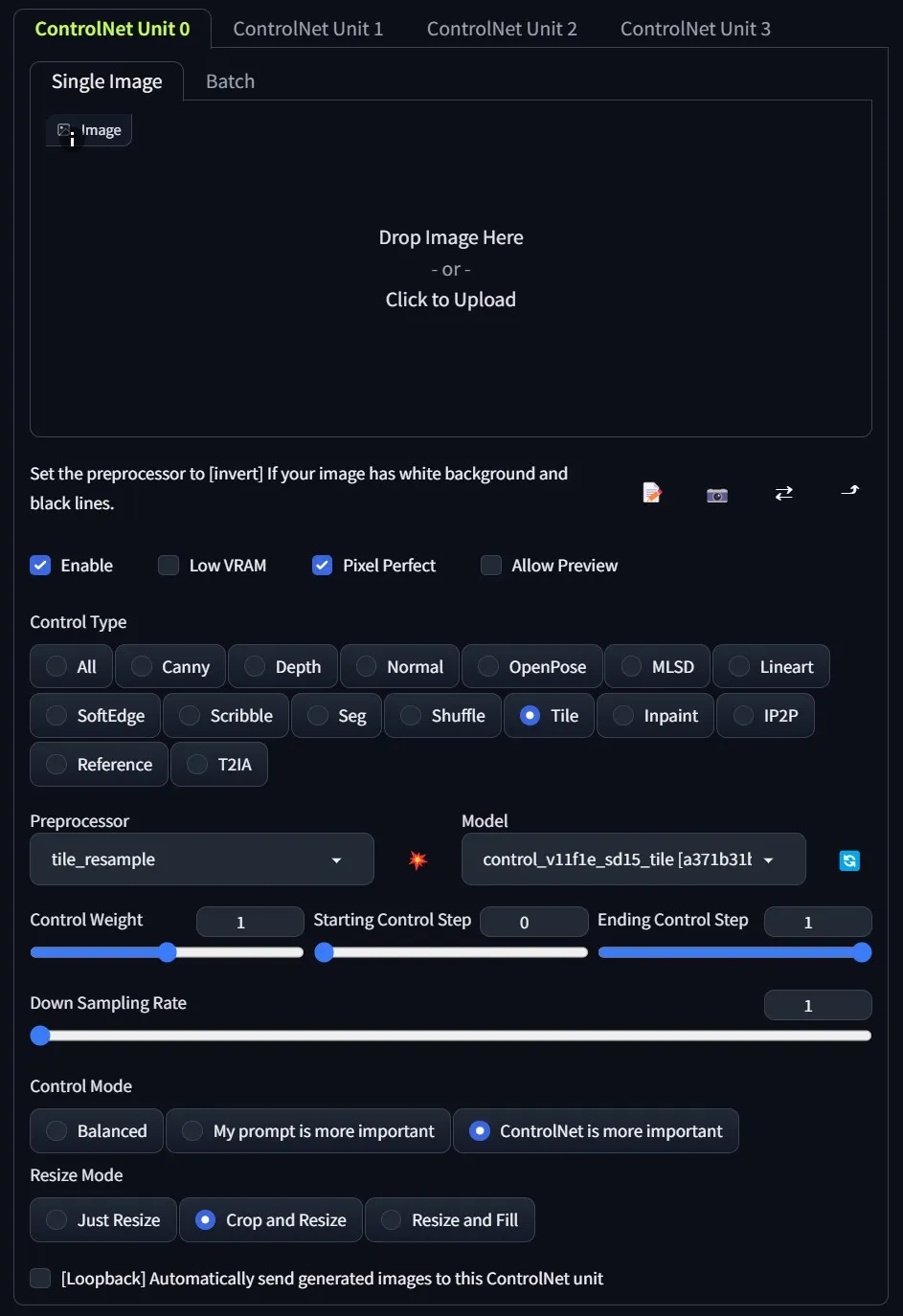
对于 Controlnet 来说,它非常简单直接:
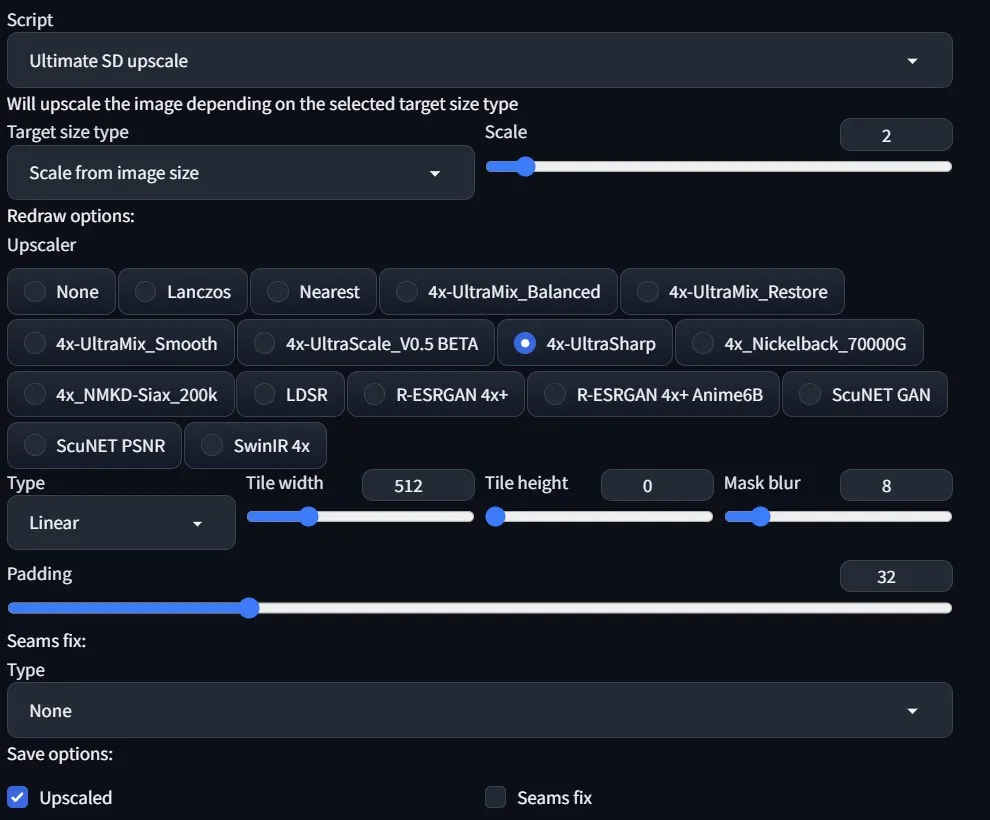
最后,终极 SD 选项
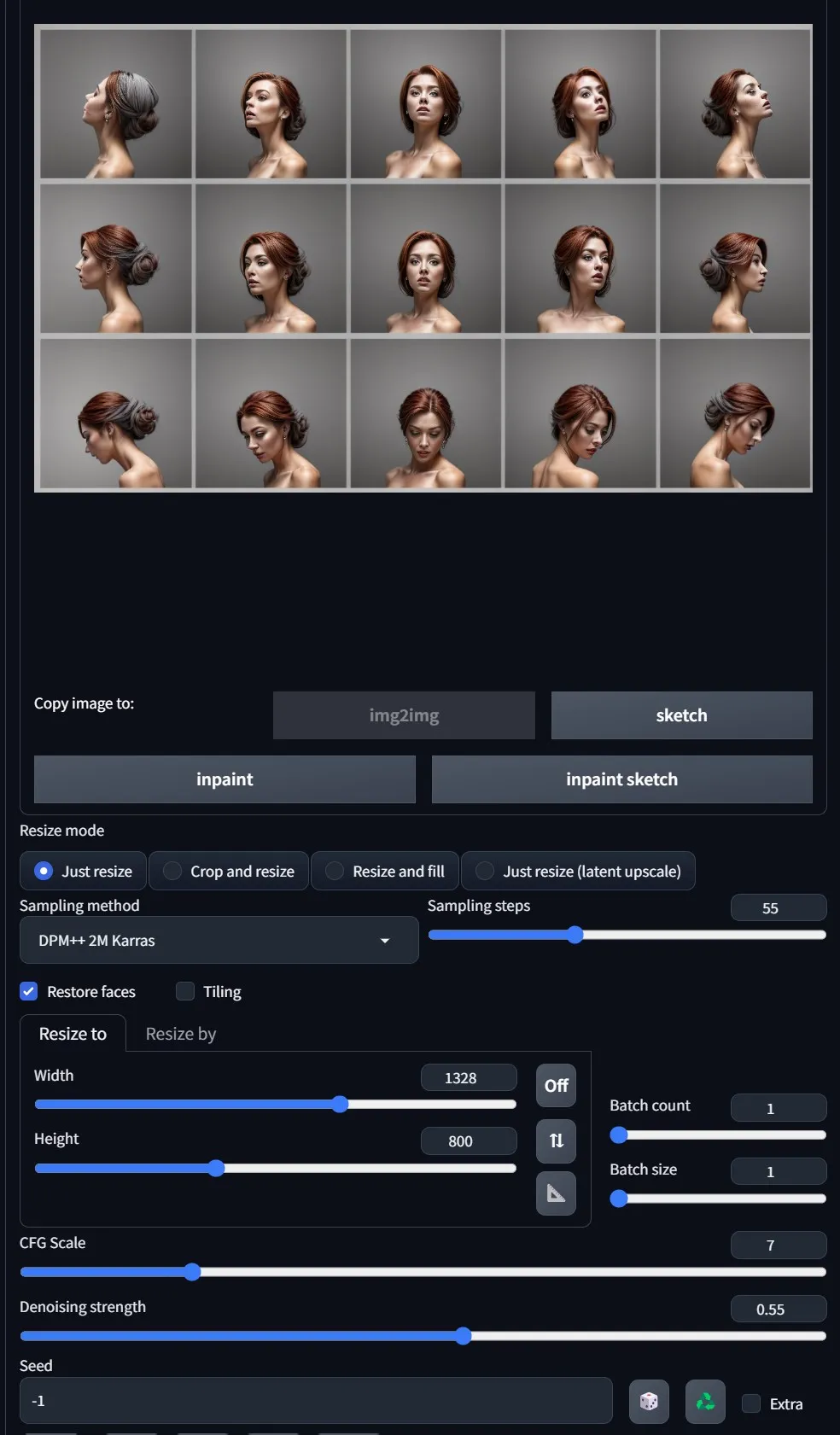
结果:

使用略有不同的提示和模型的其他一些输出示例:

模型:disneyPixarCartoon_v10
(a character sheet of a woman from different angles with a grey background:1.4), auburn hair, eyes open, cinematic lighting, Hyperrealism, depth of field, photography, ultra highres, photorealistic, 8k, hyperrealism, studio lighting, photography

模型:henmixReal_v40
(a character sheet of a beautiful woman from different angles with a grey background:1.4) , blonde hair, eyes open, cinematic lighting, Hyperrealism, depth of field, photography, ultra highres, photorealistic, 8k, hyperrealism, studio lighting, photography

模型:darkSushiMixMix_225D
(a character sheet of a beautiful woman from different angles with a grey background:1.4) , black hair, eyes open, cinematic lighting, Hyperrealism, depth of field, photography, ultra highres, 8k, studio lighting

模型:reliberate_v10
(a character sheet of a woman from different angles with a grey background:1.4) , black hair, eyes open, cinematic lighting, Hyperrealism, depth of field, photography, ultra highres, photorealistic, 8k, hyperrealism, studio lighting, photography
表情
由于我们希望在这项工作的基础上进行构建并确保我们的角色在表达方面具有灵活性,因此我建议创建一些替代面板来定义提示中的表达。比如微笑、悲伤、愤怒,其实有很多。例如,使用提示:
(a character sheet of a woman smiling from different angles with a grey background:1.4) , auburn hair, eyes open, cinematic lighting, Hyperrealism, depth of field, photography, ultra highres, photorealistic, 8k, hyperrealism, studio lighting, photography
保留所有其他设置相同。


分割图像(更新脚本 7/1):
一旦获得了所需的字符表和输出,下一部分就是分割每个主图像。为了实现这一目标,我有一个简单的 Python 脚本 (v1.1) – 您可以通过此 GitHub 链接获取它。
此时脚本非常简单,需要 Pillow (PIL) (pip install Pillow) 进行图像处理,但会将主图像分割。您应该期望图像上显示一些帧边缘,因为 SD 是 AI 并且输出是不可预测的,它不会是像素完美的,但您应该在下一阶段的分割过程中获得“足够接近”的输出,以便根据我们的内容创建 LoRA有。
总结
这样我们就完成了第一部分,创建了角色表的基础线。在这里,我们将选择分割图像的一个子集。接下来,创建 LoRA,这样我们就可以在稳定扩散输出中实例化一个一致的角色。由于我每天都会收到很多关于这个过程的问题,我很有可能会制作其他附录,而且这有可能是一个 3 部分的系列,这样我就可以在训练之前覆盖另一个领域。


