
热门标签
热门文章
- 1git format-patch打补丁
- 2Java+Spring Boot +MySQL + MyBatis Plus一款数字化管理平台源码:云MES系统
- 3【微信小程序开发】小程序前后端交互--发送网络请求实战解析_微信小程序 后台请求
- 4路径规划的常用算法
- 52024最新Android开发者学习路线,金九银十_android应用开发学习路线
- 6大数据技术部分课后作业(第二版)_大数据技术原理与应用第二版课后答案
- 7Hadoop三种运行模式(单机模式、伪分布式模式、全分布式集群模式)_hadoop运行模式有哪三种
- 8AIGC:让传统农村小型作坊焕发新能量
- 9Laravel9+Vue+ElementUI框架使用搭建教程_laravel使用vue和elementplaus
- 10全面解析Spring Boot拦截器:自定义设计与实现的深入指南_springboot请求拦截器
当前位置: article > 正文
【YOLOV8 轻量化改进】 使用高效网络EfficientNetV2替换backbone
作者:小蓝xlanll | 2024-05-24 00:56:49
赞
踩
yolov8 轻量化
一、EfficientNetV2论文
论文地址:https://arxiv.org/abs/2104.00298

二、EfficientNet v2
作者将该效率网络与 ImageNet 上其他现有的 cnn 进行了比较。 一般来说,高效网络模型比现有的 cnn 具有更高的精度和更高的效率,减少了参数大小和 FLOPS 数量级。 在高精度体系中, EfficientNet-B7在 imagenet 上的精度达到了最高水平的84.4% ,而在 CPU 使用方面比以前的 Gpipe 小8.4倍,快6.1倍。 与广泛使用的 ResNet-50相比,作者提出的 net-b4使用了类似的 FLOPS,同时将准确率从 ResNet-50的76.3% 提高到82.6% (+ 6.3%)。尽管 EfficientNets 在 ImageNet 上表现良好,但为了更有用,它们也应该转移到其他数据集上。 为了评估这一点,作者在八个广泛使用的学习数据集上测试了 EfficientNets。 在8个数据集中,有5个数据集的精度达到了最高水平,比如 CIFAR-100(91.7%)和 Flowers (98.8%) ,而且参数减少了5个数量级(最多减少了21个参数) ,这表明该网络也能很好地传输数据。通过对模型效率的显著改进,预计 EfficientNets 可能成为未来计算机视觉任务的新基础。
三、 EfficientNetV2组件定义
3.1 在ultralytics/nn/modules文件夹下新建 efficientnetv2.py文件
3.2 在efficientnetv2.py中编写核心组件stem,MBConv,FuseMBConv等,efficientnetv2.py中代码如下:
################# efficientv2 ################
import torch
import torch.nn as nn
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
# kernel_size为3时,padding 为1,kernel为1时,padding为0
padding = (kernel_size - 1) // 2
# 由于要加bn层,所以不加偏置
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
# 先全局平均池化
x_se = self.avg_pool(x)
# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)
x_se = self.conv_reduce(x_se)
# ReLU激活
x_se = self.act1(x_se)
# 再全连接
x_se = self.conv_expand(x_se)
# sigmoid激活
x_se = self.gate_fn(x_se)
# 将x_se 维度扩展为和x一样的维度
x = x * (x_se.expand_as(x))
return x
# Fused-MBConv 将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3。
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
# shorcut 是指到残差结构 expansion是为了先升维,再卷积,再降维,再残差
self.has_shortcut = (s == 1 and c1 == c2) # 只要是步长为1并且输入输出特征图大小相等,就是True 就可以使用到残差结构连接
self.has_expansion = expansion != 1 # expansion==1 为false expansion不为1时,输出特征图维度就为expansion*c1,k倍的c1,扩展维度
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
self.expansion_conv = stem(c1, expanded_c, kernel_size=1, stride=1)
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(expanded_c, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# 先用1x1的卷积增加升维
result = self.expansion_conv(x)
# 再用一般的卷积特征提取
result = self.dw_conv(result)
# 添加se模块
result = self.se(result)
# 再用1x1的卷积降维
result = self.project_conv(result)
# 如果使用shortcut连接,则加入dropout操作
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
# shortcut就是到残差结构,输入输入的channel大小相等,这样就能相加了
result += x
return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
四、 EfficientNetV2组件注册
4.1 在ultralytics/nn/modules/block.py中修改:
from .efficientnetv2 import stem, FusedMBConv, MBConv
__all__ = ( ..., "stem","FusedMBConv","MBConv",)
- 1
- 2
4.2 在ultralytics/nn/modules/init.py中修改:
from .block import (..., stem,FusedMBConv,MBConv,)
- 1
4.3 在ultralytics/nn/tasks.py中修改:
from ultralytics.nn.modules import (..., stem,MBConv,FusedMBConv,)
在parse_model函数中修改:if m in (..., stem,FusedMBConv,MBConv,)
- 1
- 2
五、 结构搭建(以yolov8-pose为例)
5.1 打开ultralytics/cfg/models/v8/yolov8-pose.yaml文件
5.2 修改backbone如下:
backbone:
# [from, repeats, module, args]
- [-1, 1, stem, [24, 3, 2]] # 0-P1/2
- [-1, 2, FusedMBConv, [24, 3, 1, 1, 0]] # 1-P2/4
- [-1, 1, FusedMBConv, [48, 3, 2, 4, 0]]
- [-1, 3, FusedMBConv, [48, 3, 1, 4, 0]] # 3-P3/8
- [-1, 1, FusedMBConv, [64, 3, 2, 4, 0]]
- [-1, 3, FusedMBConv, [64, 3, 1, 4, 0]] # 5-P4/16
- [-1, 1, MBConv, [128, 3, 2, 4, 0.25]]
- [-1, 5, MBConv, [128, 3, 1, 4, 0.25]] # 7-P5/32
- [-1, 1, MBConv, [160, 3, 2, 6, 0.25]]
- [-1, 8, MBConv, [160, 3, 1, 6, 0.25]] #9
- [-1, 1, MBConv, [272, 3, 2, 4, 0.25]]
- [-1, 14, MBConv, [272, 3, 1, 4, 0.25]] #11
- [-1, 1, SPPF, [1024, 5]] # 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5.3 修改head如下:
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 9], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 15
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 7], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 18 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 15], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 21 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 24 (P5/32-large)
- [[18, 21, 24], 1, Pose, [nc, kpt_shape]] # Pose(P3, P4, P5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
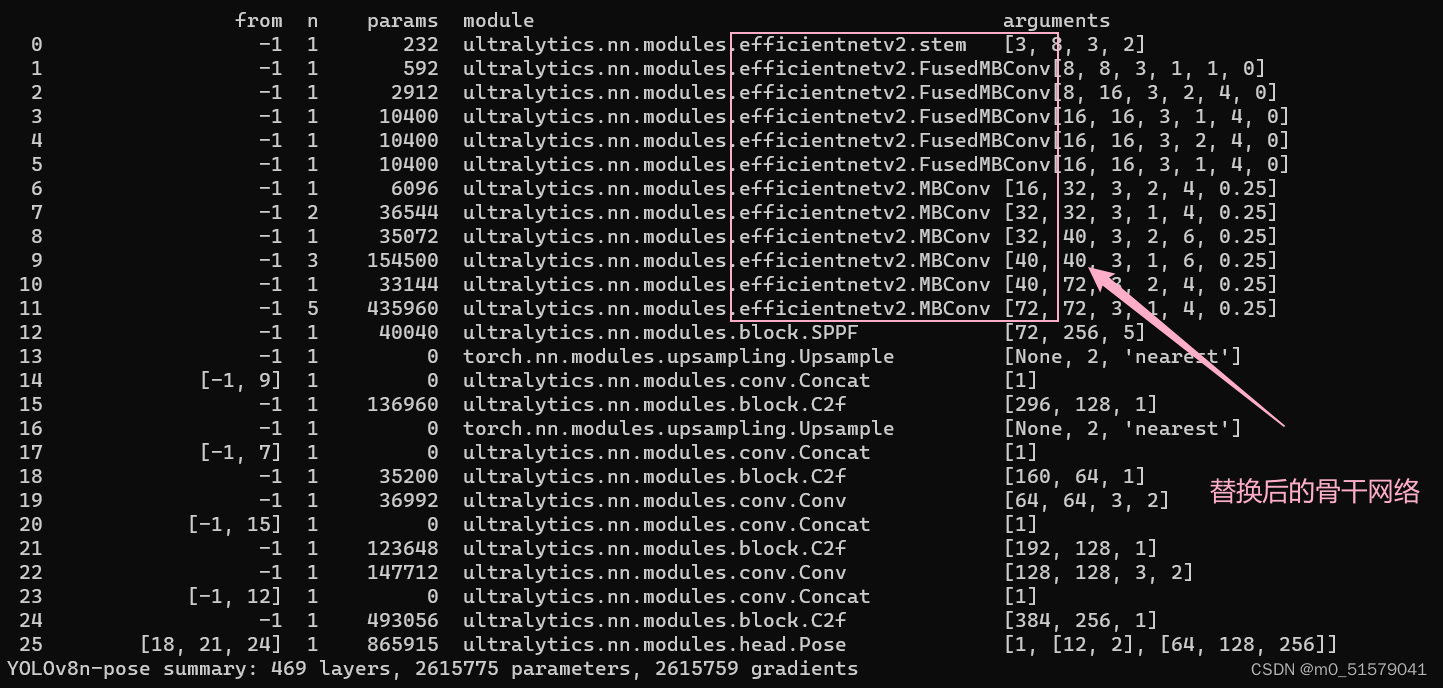
六、 查看
6.1 运行下面代码查看模型
from ultralytics import YOLO
model = YOLO('yolov8n-pose.yaml')
results = model.train(data='data/tiger-pose.yaml', epochs=100, imgsz=640)
- 1
- 2
- 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/615068
推荐阅读
相关标签

