
- 1汽车电子相关术语_ivi和domain controller
- 2iOS技术之Xcode 15打包报错:Command PhaseScriptExecution failed with a nonzero exit code_xcode15.3 真机 command phasescriptexecution failed w
- 3socket编程一:socket是什么?套接字是什么?_socket编程 为什么是socket
- 4关于前端技术文章_前端写一个关于技术方面的文章
- 5C-Pack论文解读
- 6mysql忘记密码怎么解决_mysql 忘记密码,通宵都要看完这个大数据开发关键技术点_进入mysql 密码
- 7vscode配置c++11_vscode c++11
- 8YOLOv8算法改进【NO.100】引入最新发布AKConv_改进yolov8
- 9Flink 内容分享(六):Fink原理、实战与性能优化(六)_flinkvalue.f0
- 10uniapp导入导出Excel_uniapp 导出导入
DLRover:蚂蚁集团开源的AI训练革命
赞
踩
在当前的深度学习领域,大规模训练作业面临着一系列挑战。首先,硬件故障或软件错误导致的停机时间会严重影响训练效率和进度。其次,传统的检查点机制在大规模训练中效率低下,耗时长且容易降低训练的有效时间。资源管理的复杂性也给训练作业带来了瓶颈,包括节点落后、工作负载不均衡、CPU核心不足以及节点数量不足等问题。最后,数据管理的效率也直接影响到训练的弹性和稳定性。近日,蚂蚁集团AI创新研发部门NextEvo开源了一项名为DLRover的AI Infra技术,为这些问题提供了突破性的解决方案。
DLRover通过其创新的容错性、Flash Checkpoint、自动扩展资源、动态数据分片以及离线和在线学习的集成能力,解决了大规模分布式深度学习训练中的多个关键问题,为深度学习研究和开发提供了强有力的支持。
DLRover 的核心优势之一是其出色的容错能力。当训练过程中出现故障时,DLRover 能够在不停止整个训练作业的情况下恢复训练。它通过自动诊断故障原因,并根据错误的类型采取相应的恢复措施,如针对软件错误重启进程,或因硬件故障重启节点。这种容错机制显著减少了大规模训练作业的停机时间,如GLM-65B在数千GPU上的训练,其有效计算时间(goodput)从69%提升至95%。

DLRover 还提供了 Flash Checkpoint 功能,能够在几秒钟内保存和加载检查点。与传统的检查点操作相比,Flash Checkpoint 允许训练过程更频繁地保存检查点,并且在发生故障时,可以减少从最新检查点恢复训练所需的回滚步骤。这一功能包括异步将检查点持久化到存储、在训练进程失败时将检查点持久化到存储,以及在训练进程重启后从主机内存加载检查点。这使得从故障中恢复的速度大大加快,提高了训练的连续性和效率。
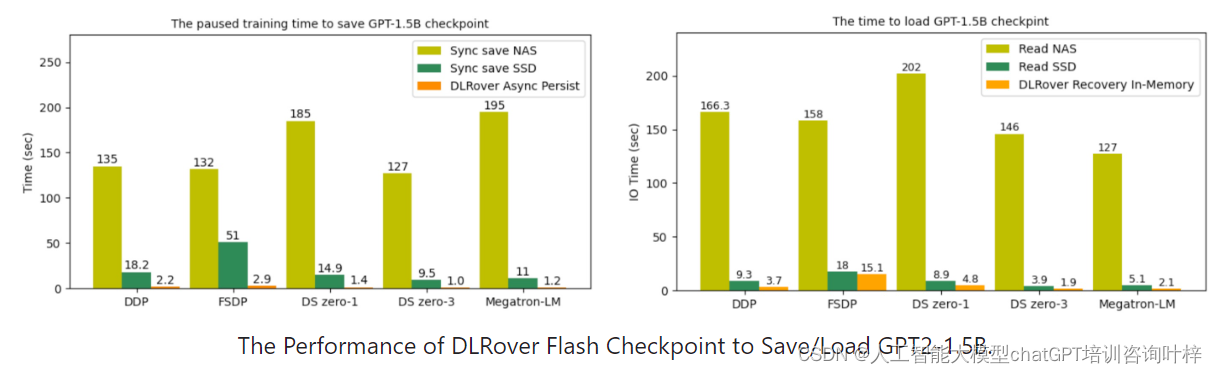
DLRover 在 TensorFlow 参数服务器(PS)架构下也展现了其故障容忍能力。它能够恢复失败的参数服务器和工作节点,自动启动具有更多内存的Pod以恢复内存不足的节点,重新分配失败工作节点的训练数据给其他工作节点,并根据模型大小自动扩展参数服务器。在蚂蚁集团的实践中,DLRover 管理着每天数百个深度学习训练作业,除代码错误导致的失败作业外,作业完成率从使用 KubeFlow 中的 tf-operator 的89%提高到了95%。
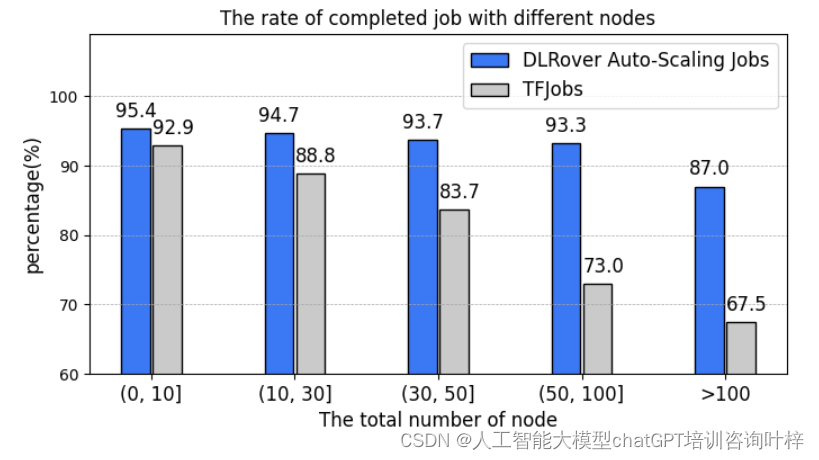
DLRover 能够根据训练作业的运行时需求自动扩展或缩减资源,如参数服务器或工作节点。通过监控节点的工作负载和吞吐量,DLRover 能够诊断资源配置的瓶颈,并进行动态资源调整以提高训练性能。这种自动扩展功能不仅提高了训练作业的稳定性和吞吐量,还通过按需分配资源减少了资源浪费。
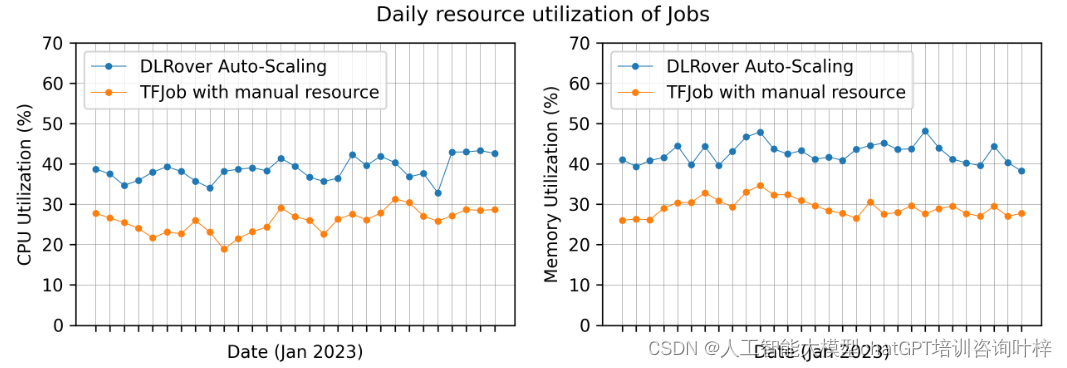
DLRover 的动态数据分片功能将数据集分割成许多小的数据片段,每个片段仅包含少量的训练样本批次。当工作节点用完上一个片段的样本后,才会获取新的片段。这种动态分片机制使得DLRover 能够在工作节点失败之前恢复片段,并通过给快速工作节点分配更多片段来减轻工作节点的落后问题。
DLRover 通过动态数据分片提供的透明数据源,可以与批量数据处理的离线训练集成,并支持实时流数据处理的在线学习。这种灵活性使得DLRover 成为构建端到端工业在线学习系统的理想组件,能够与消息队列(如RocketMQ、Kafka、Pulsar等)集成,或作为 Flink、Spark、Ray 等平台内的训练汇聚节点执行。
GitHub 地址:https://github.com/intelligent-machine-learning/dlrover

